230 files of the PDB (protein 3-D coordinates) format data labeled as unbound. Experiment 1. • We computed the all-to-all docking for protein-protein pairs in the dataset • The number of total pairs was 52,900 (230 x 230). Experiment 2. • To validate the large-scale application performance, we simply amplified the set of docking pairs to 25 times larger than the whole of the original dataset and created a virtual large-scale benchmark dataset. • We computed 1,322,500 pairs (= 1.3 M) of protein-protein docking calculations in total. Dataset for Million-scale “Interactome” PPI predictions 22 [35] Vreven, T., Moal, I.H., Vangone, A., Pierce, B.G., Kastritis, P.L., Torchala, M., Chaleil, R., Jimenez-Garcia, B., Bates, P.A., Fernandez-Recio, J., Bonvin, A.M.J.J. Weng, Z.: Updates to the integrated protein-protein interaction benchmarks: docking benchmark version 5 and affinity benchmark version 2. Journal of Molecular Biology 427(19), pp. 3031-3041, (2015).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Second, if a process in a Singularity [10] container](https://files.speakerdeck.com/presentations/9ae73a3ab27545fa879f1328f6d12d2a/slide_9.jpg){kind=link}
![• MEGADOCK [5] is an all-to-all protein-protein docking application for](https://files.speakerdeck.com/presentations/9ae73a3ab27545fa879f1328f6d12d2a/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
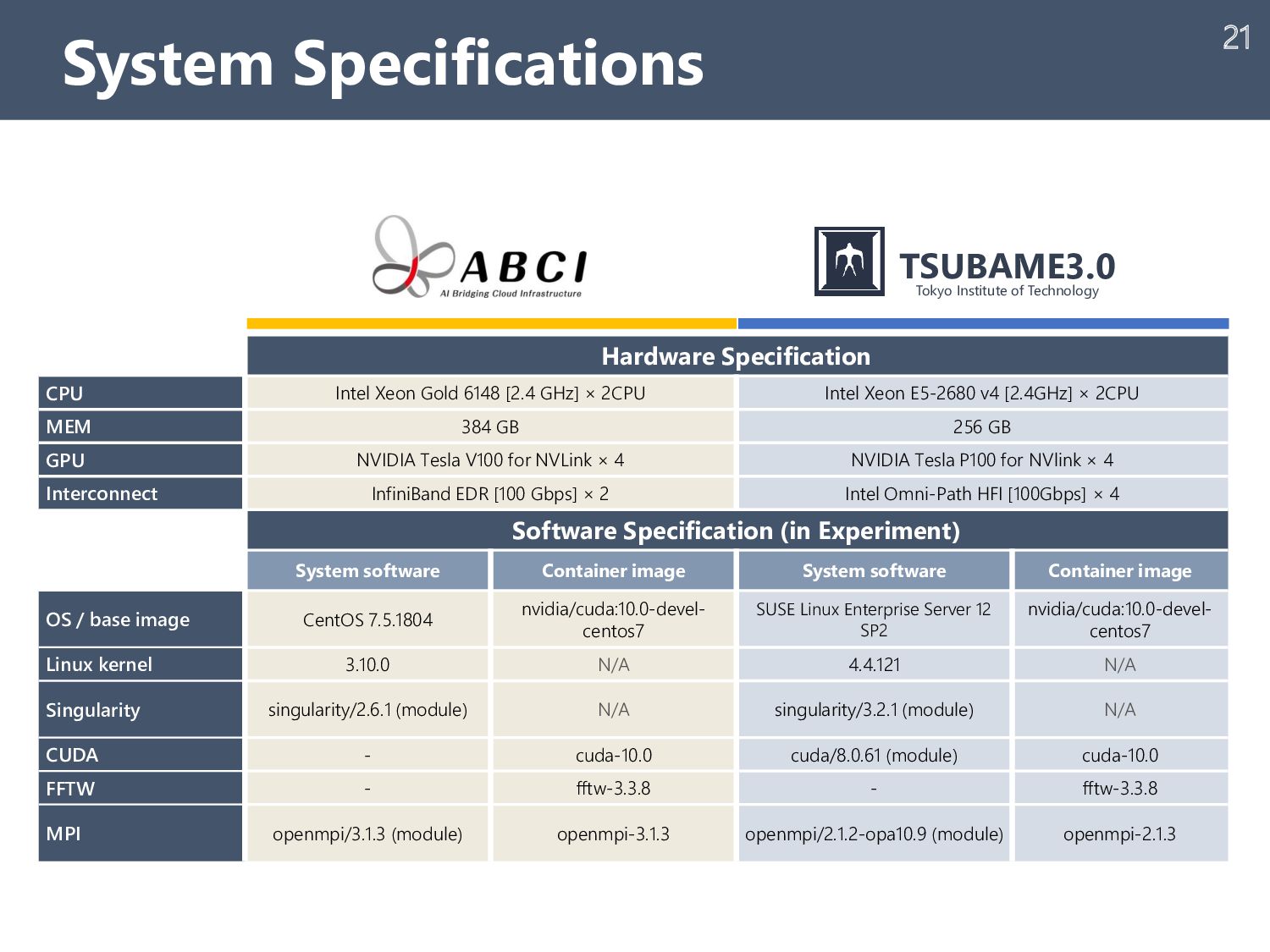{kind=link}
![Dataset • ZLab Docking Benchmark 5.0 [35] • We selected](https://files.speakerdeck.com/presentations/9ae73a3ab27545fa879f1328f6d12d2a/slide_21.jpg){kind=link}
{kind=link}
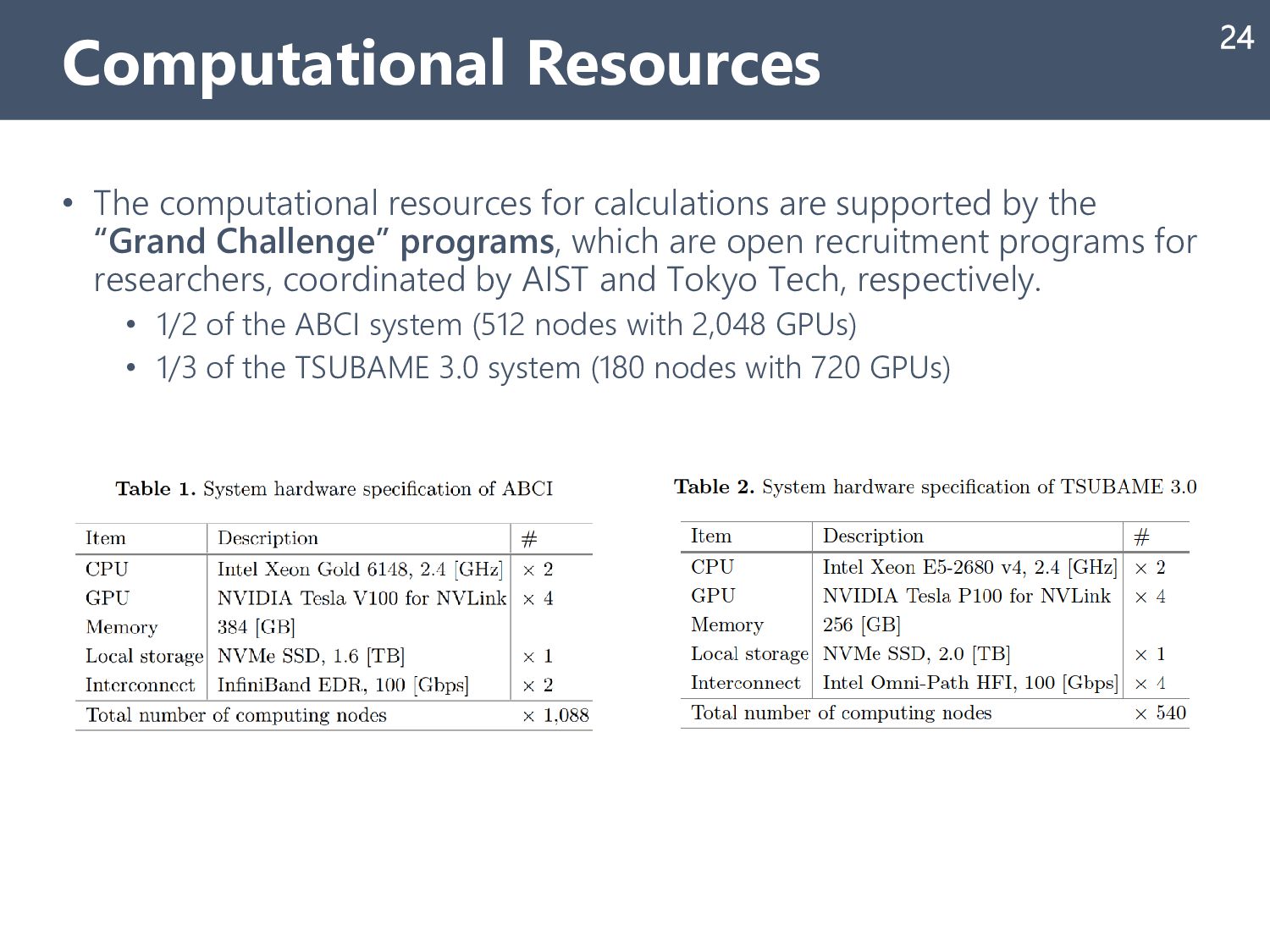{kind=link}
{kind=link}
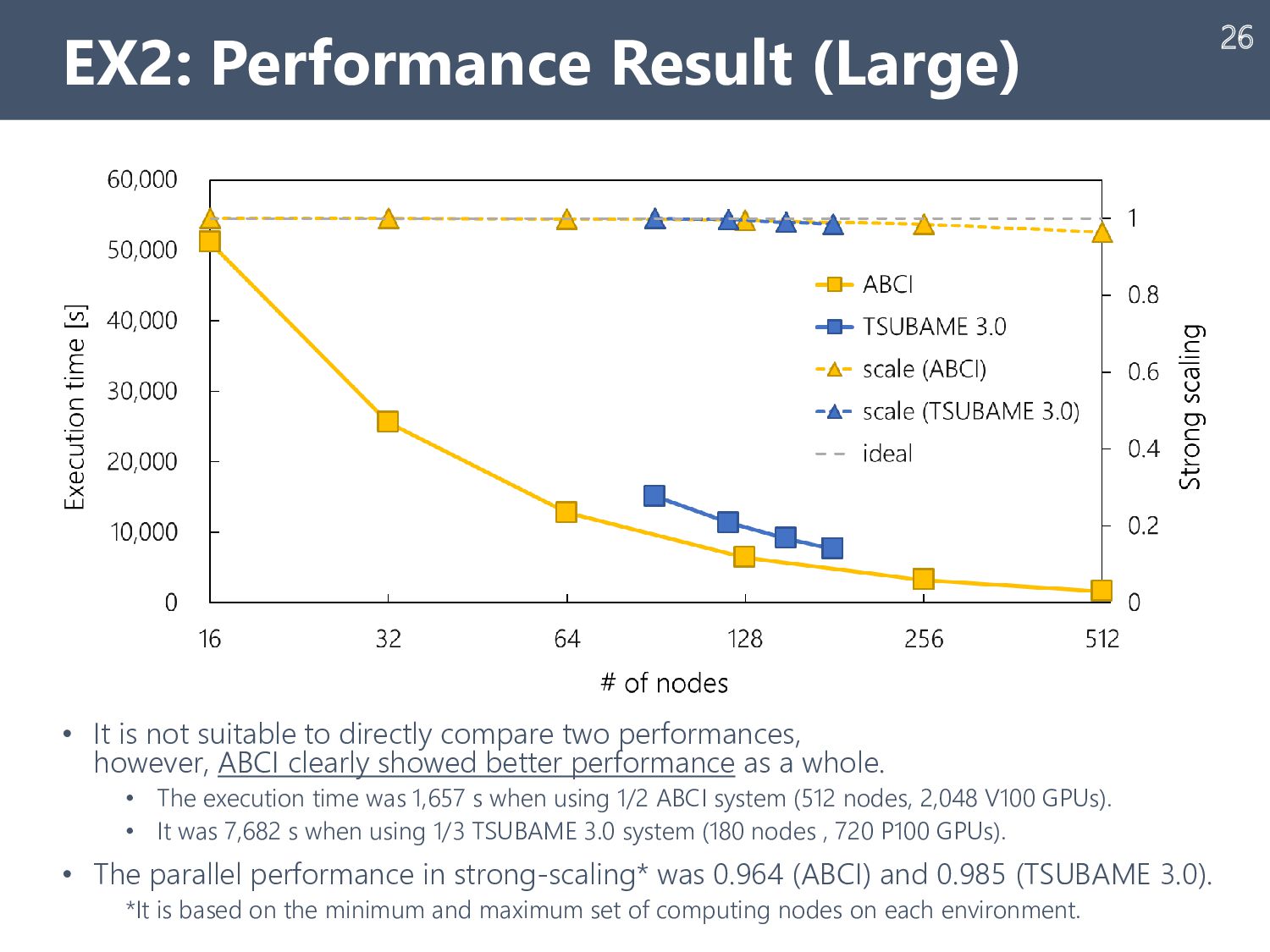{kind=link}
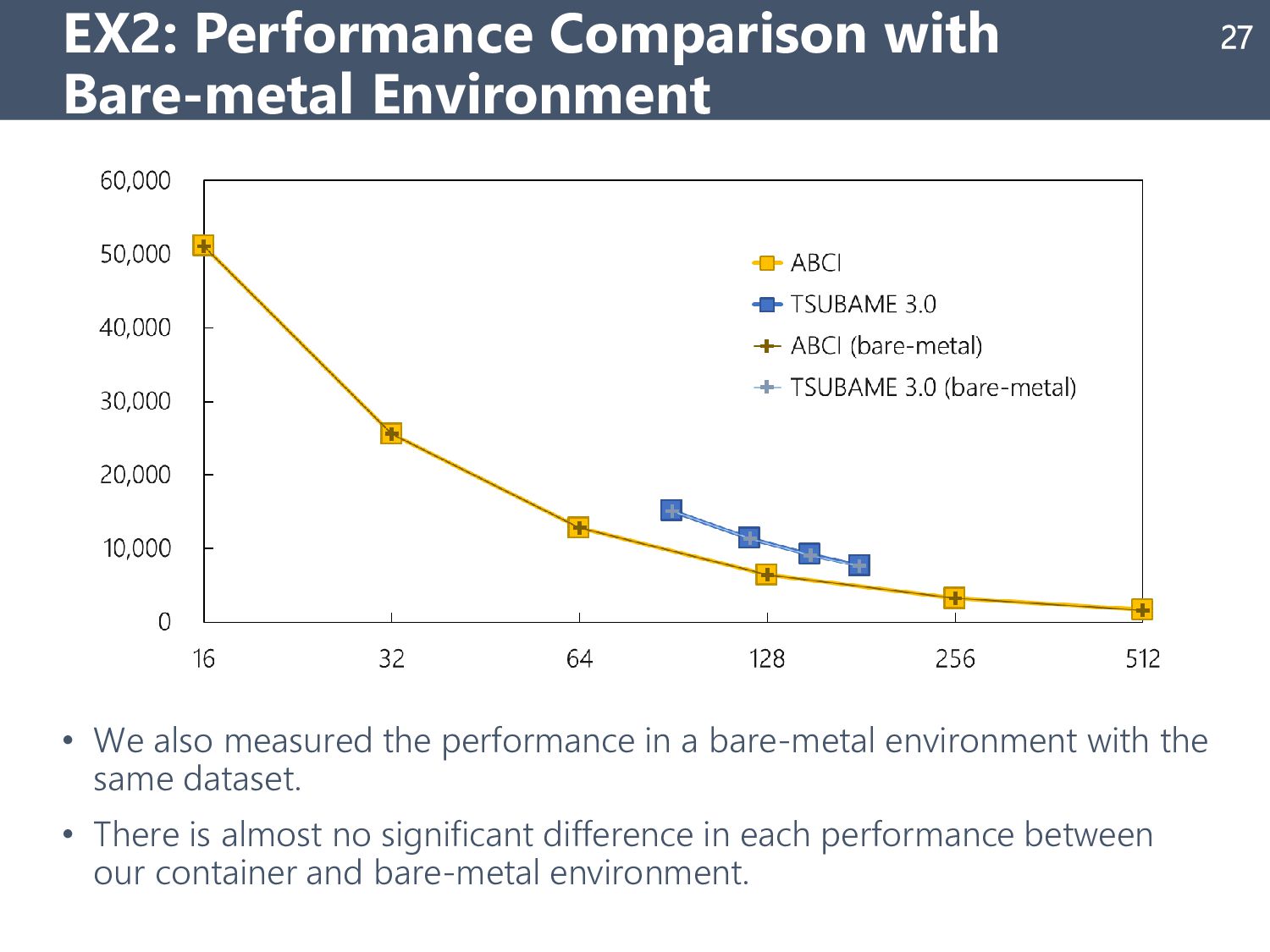{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}