as a Service (GPUaaS) の上で各サービスを提供 Storage 機械学習ジョブ・推論 DGX A100 GPU Server 分散学習 GPUaaS(Kubernetes) Distributed AI Platform Training AI Platform Prediction GPU 環境提供基盤 親鳥
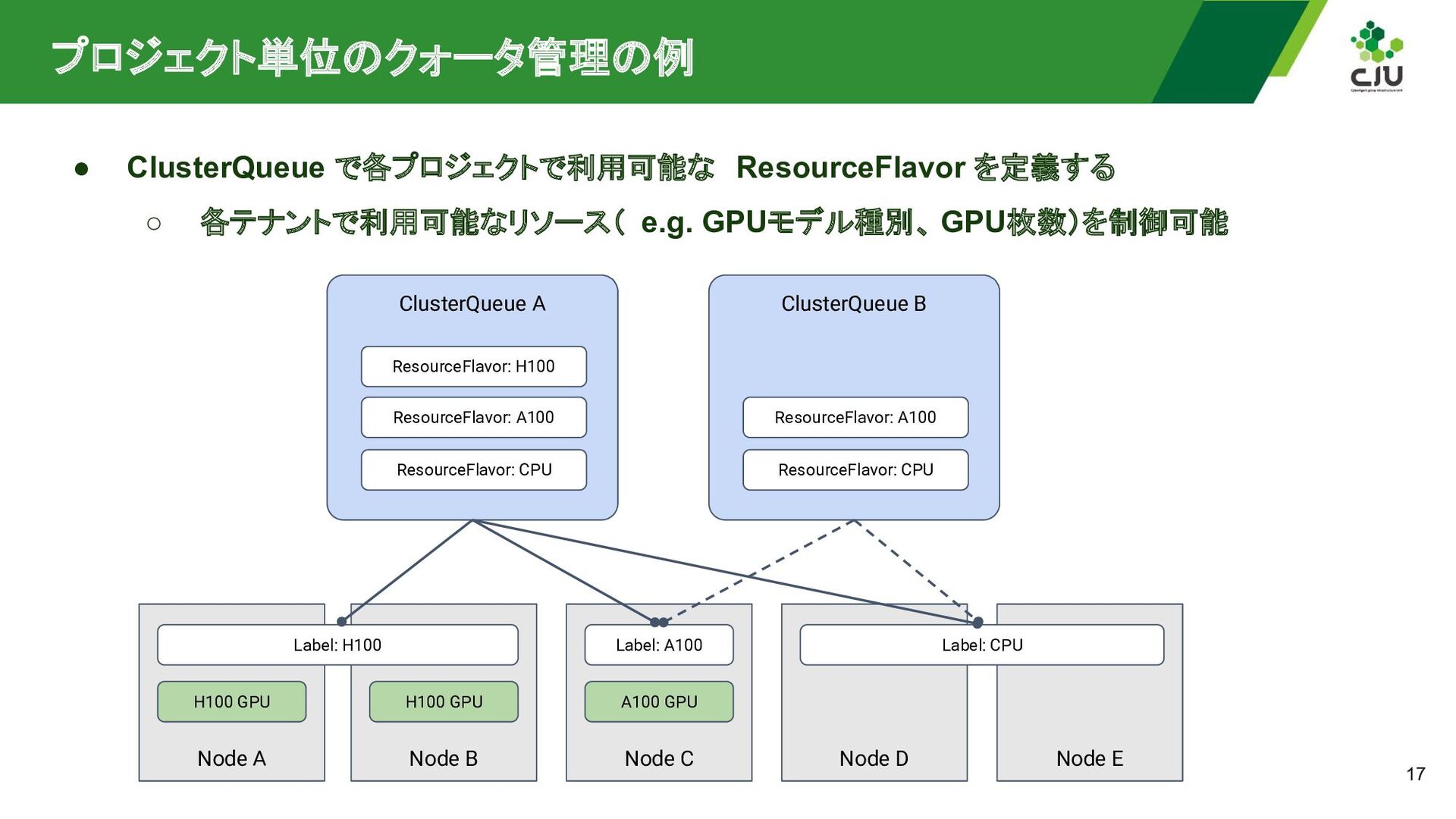
e.g. GPUモデル種別、 GPU枚数)を制御可能 ClusterQueue A ResourceFlavor: H100 ResourceFlavor: A100 ResourceFlavor: CPU ClusterQueue B ResourceFlavor: A100 ResourceFlavor: CPU Node A H100 GPU Node B H100 GPU Node C Label: A100 A100 GPU Node D Node E Label: H100 Label: CPU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
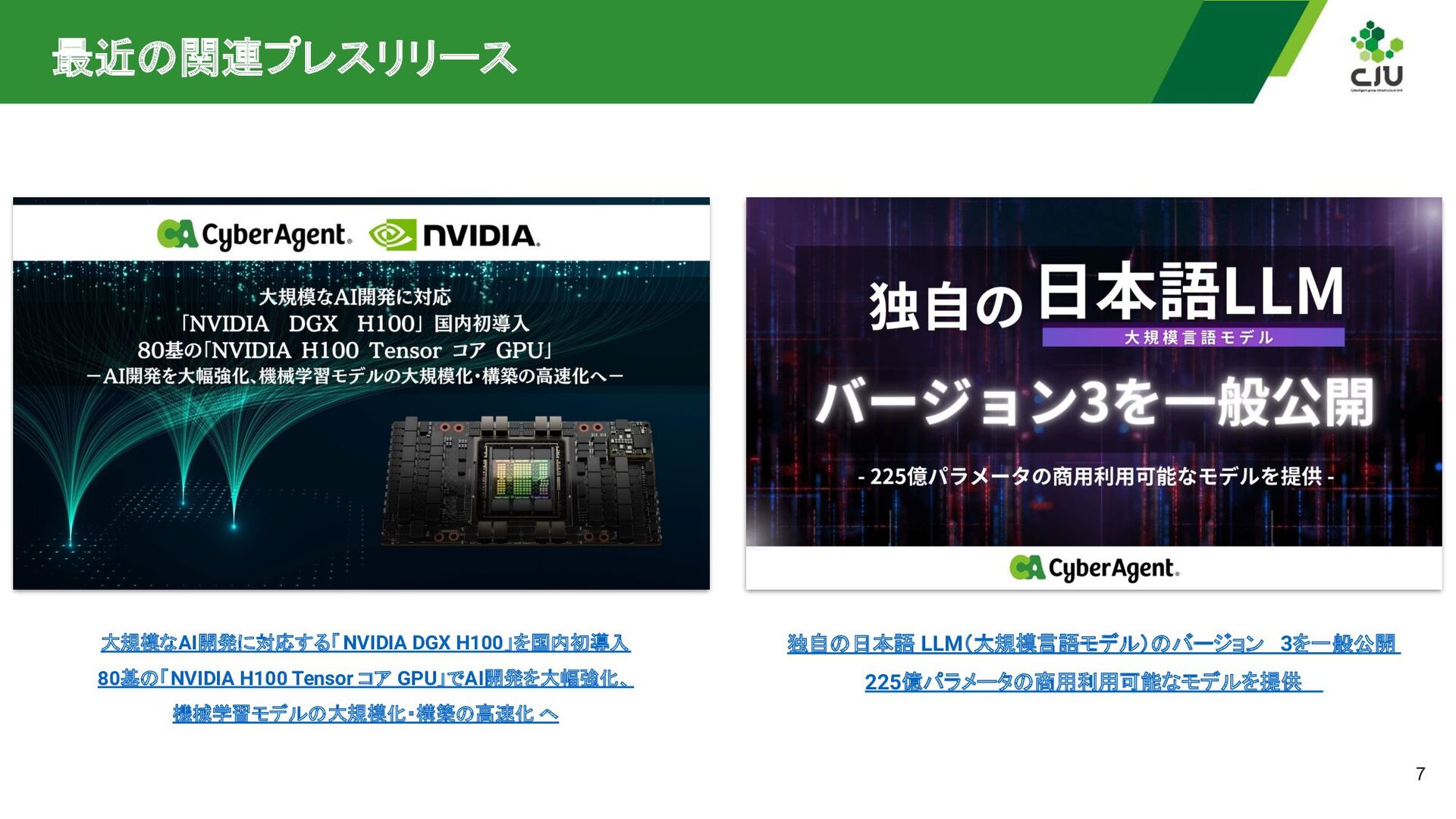{kind=link}
{kind=link}
{kind=link}
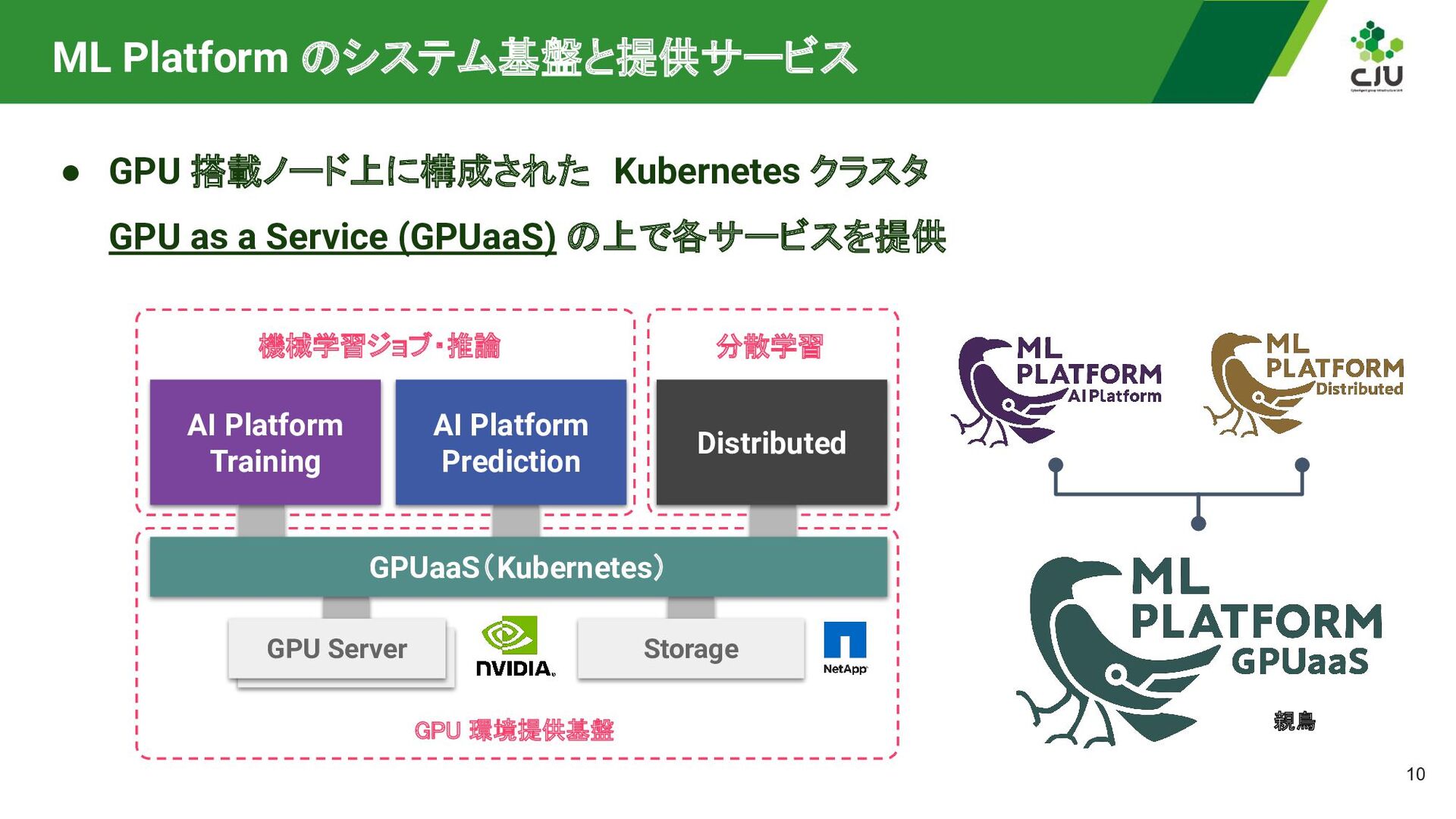{kind=link}
{kind=link}
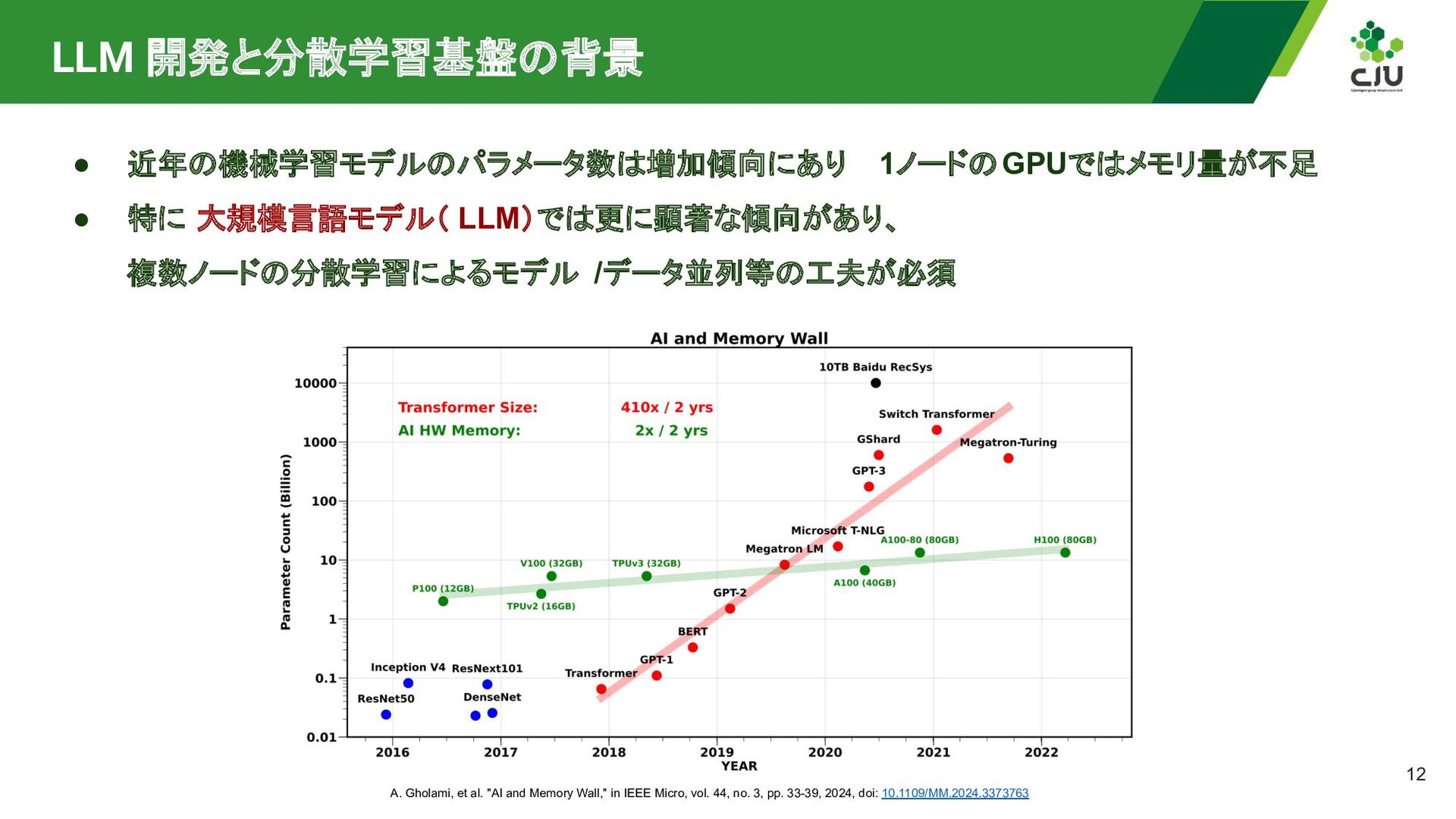{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
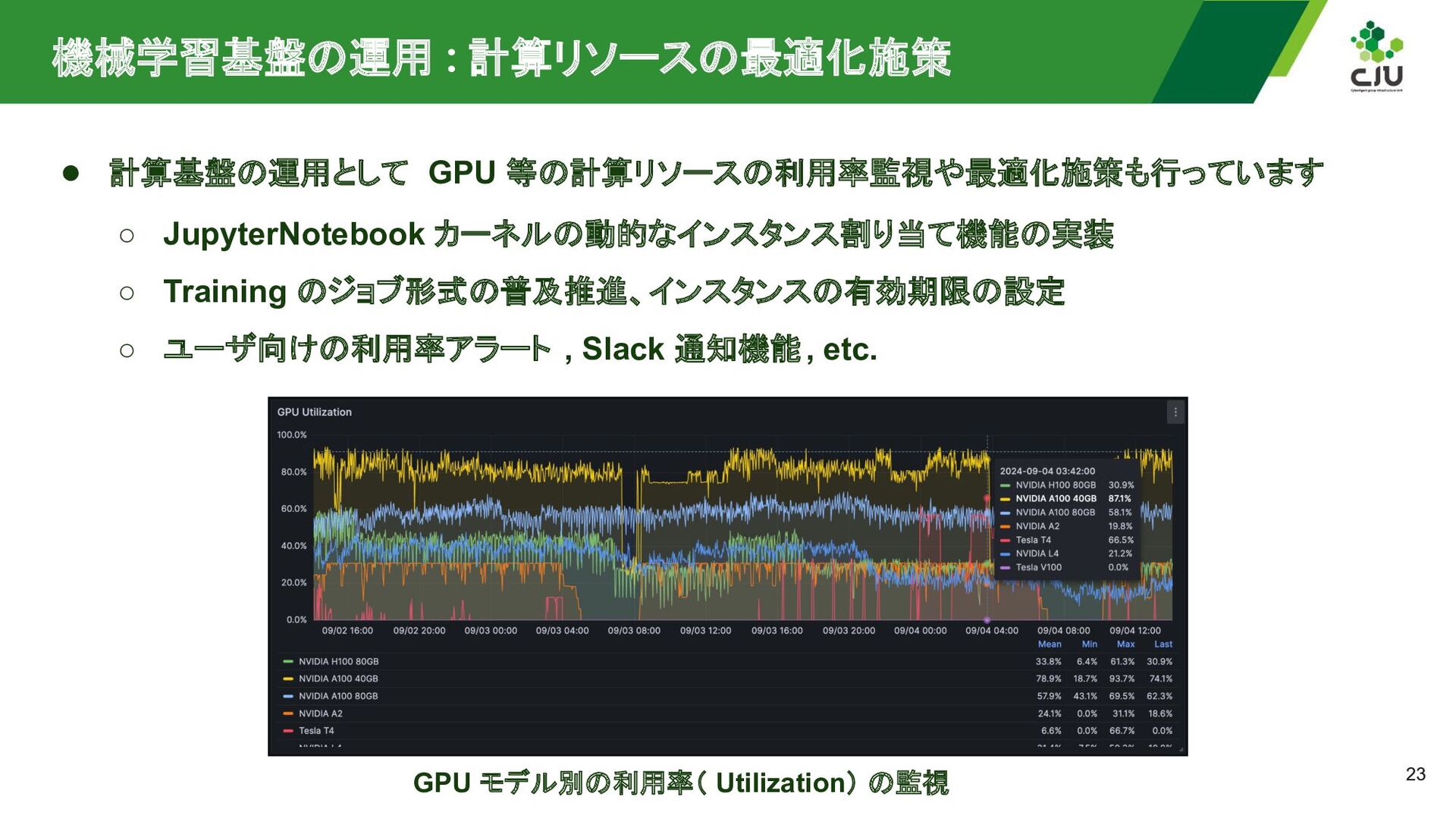{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
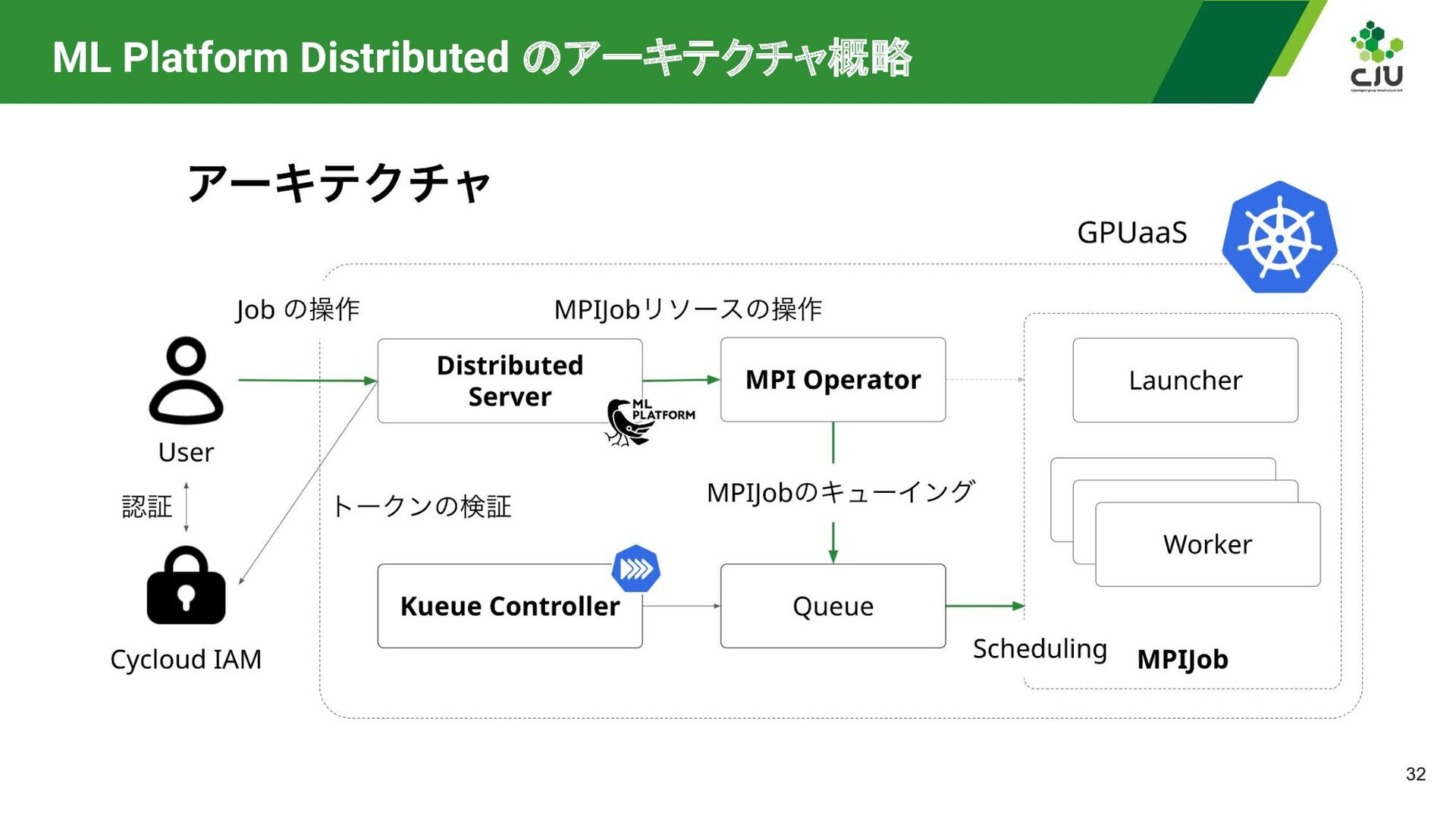{kind=link}
{kind=link}
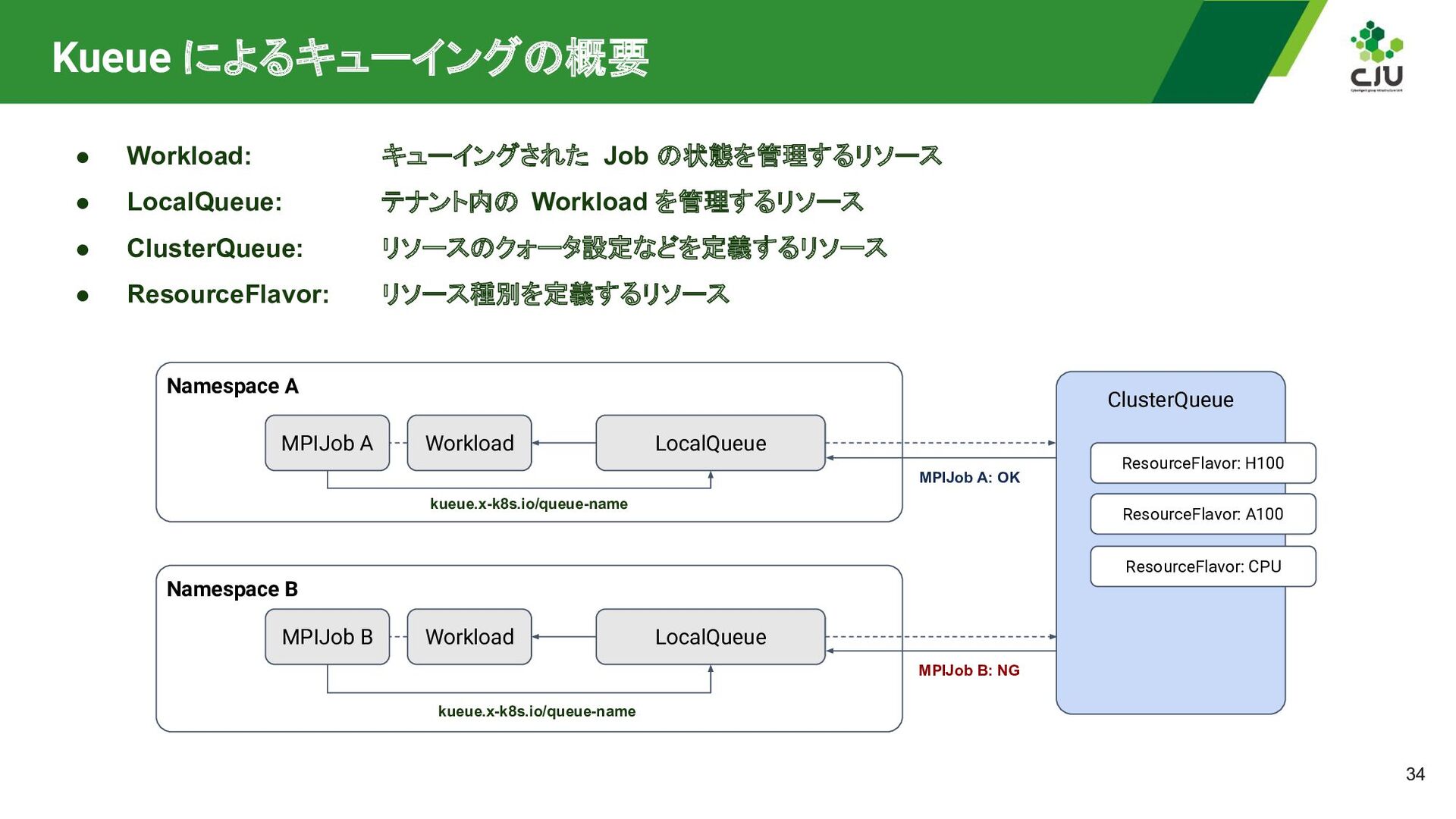{kind=link}