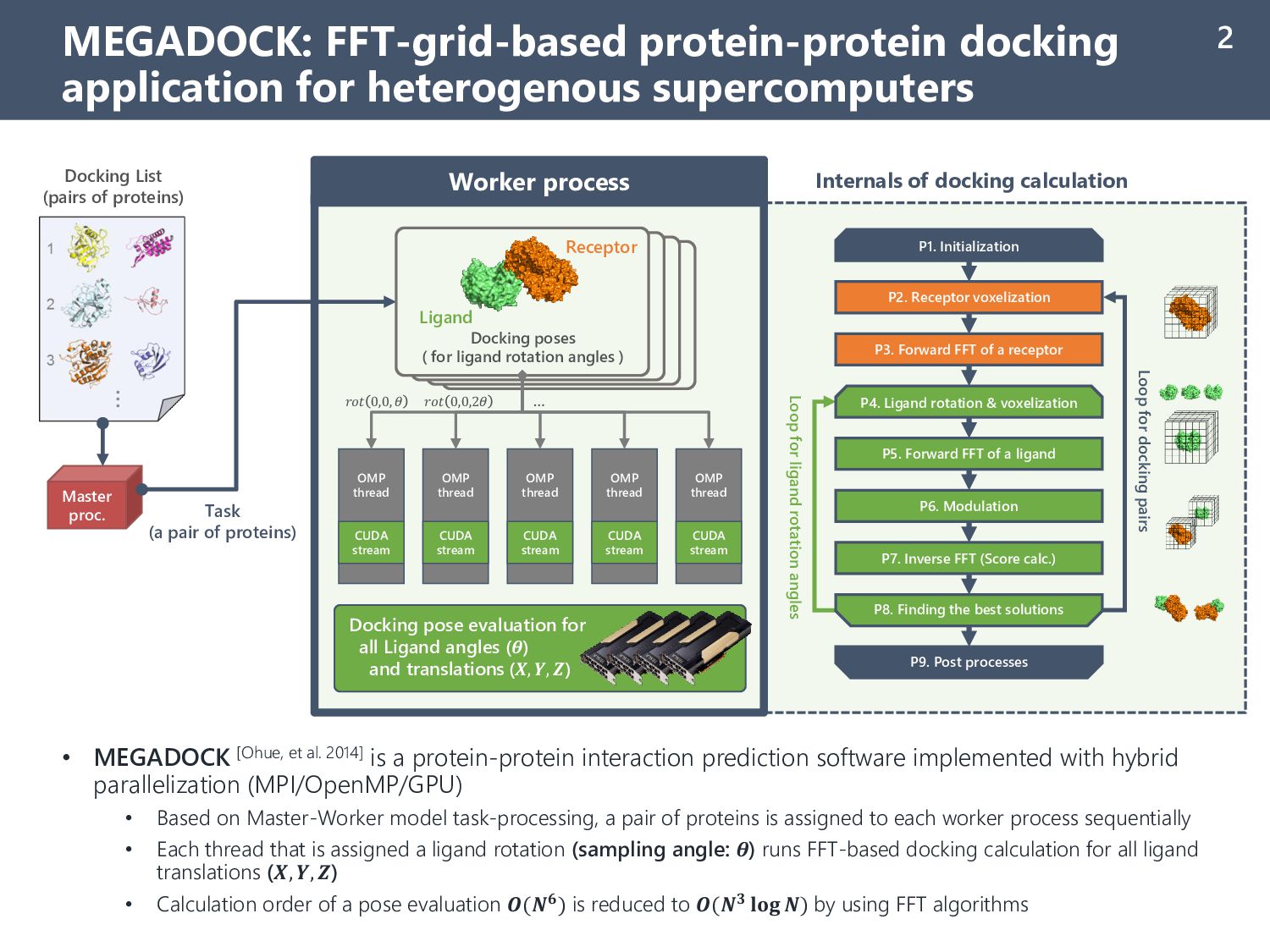
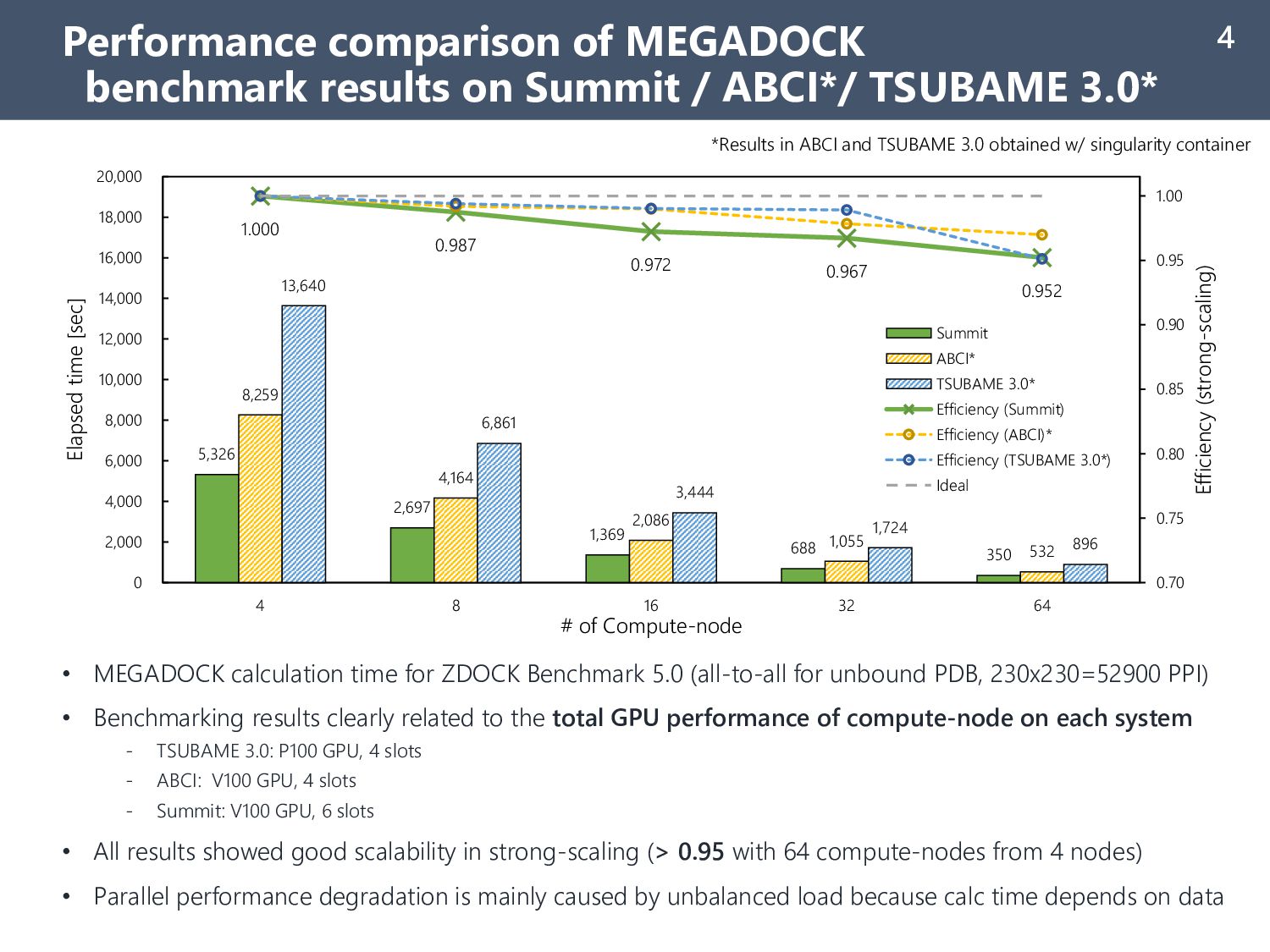
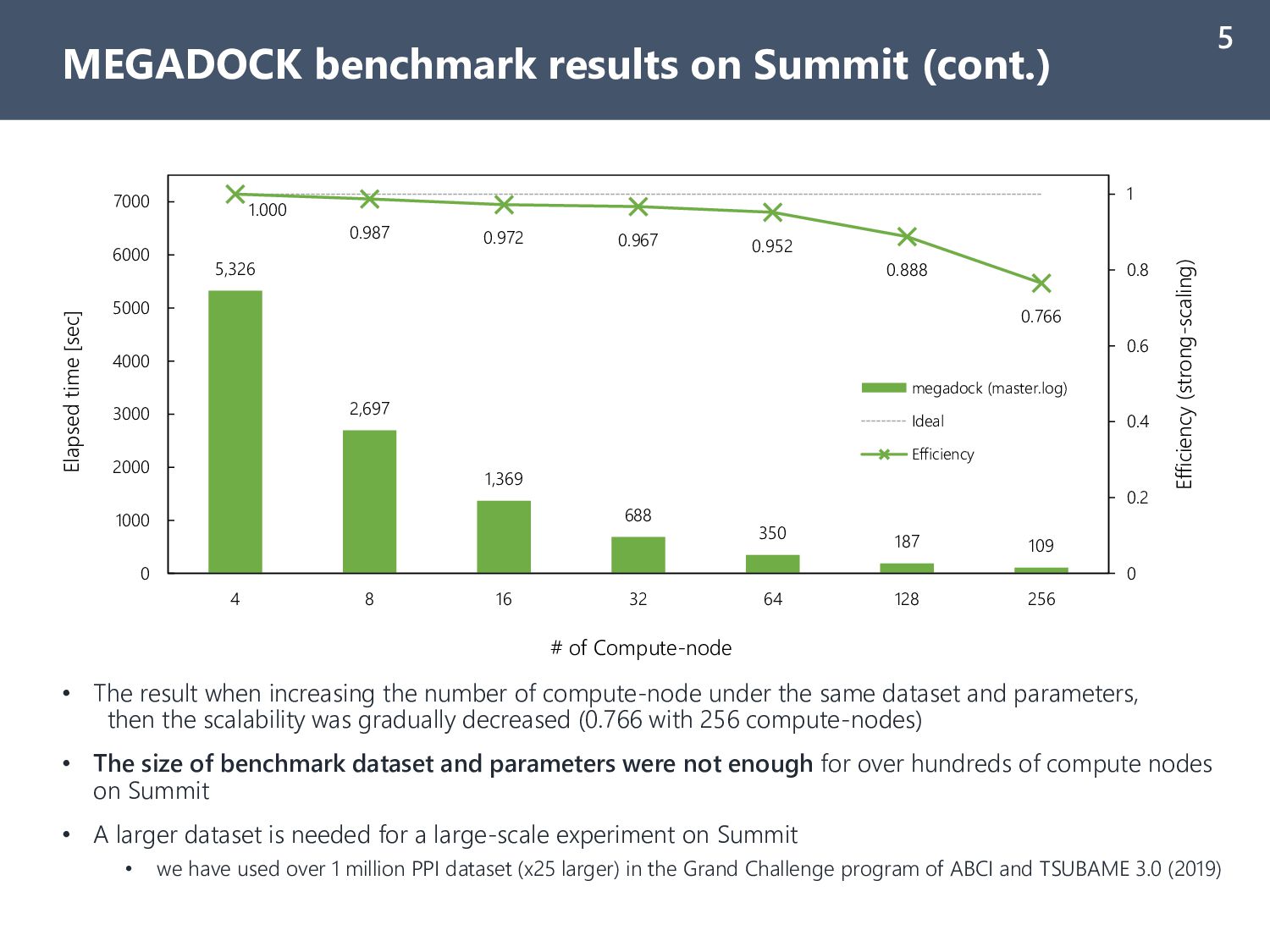
TSUBAME 3.0* 4 • MEGADOCK calculation time for ZDOCK Benchmark 5.0 (all-to-all for unbound PDB, 230x230=52900 PPI) • Benchmarking results clearly related to the total GPU performance of compute-node on each system - TSUBAME 3.0: P100 GPU, 4 slots - ABCI: V100 GPU, 4 slots - Summit: V100 GPU, 6 slots • All results showed good scalability in strong-scaling (> 0.95 with 64 compute-nodes from 4 nodes) • Parallel performance degradation is mainly caused by unbalanced load because calc time depends on data *Results in ABCI and TSUBAME 3.0 obtained w/ singularity container 5,326 2,697 1,369 688 350 8,259 4,164 2,086 1,055 532 13,640 6,861 3,444 1,724 896 1.000 0.987 0.972 0.967 0.952 0.70 0.75 0.80 0.85 0.90 0.95 1.00 0 2,000 4,000 6,000 8,000 10,000 12,000 14,000 16,000 18,000 20,000 4 8 16 32 64 Efficiency (strong-scaling) Elapsed time [sec] # of Compute-node Summit ABCI* TSUBAME 3.0* Efficiency (Summit) Efficiency (ABCI)* Efficiency (TSUBAME 3.0*) Ideal
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}