Talk about Apache Drill at Hive London. Besides the explanation of how Drill works and where we are at the moment I contrast Drill with Hive and show how they differ and where they overlap.
• Queries – Shipments from supplier ‘ACM’ in last 24h – Shipments in region ‘US’ not from ‘ACM’ SUPPLIER_ID NAME REGION ACM ACME Corp US GAL GotALot Inc US BAP Bits and Pieces Ltd Europe ZUP Zu Pli Asia { "shipment": 100123, "supplier": "ACM", “timestamp": "2013-02-01", "description": ”first delivery today” }, { "shipment": 100124, "supplier": "BAP", "timestamp": "2013-02-02", "description": "hope you enjoy it” } …
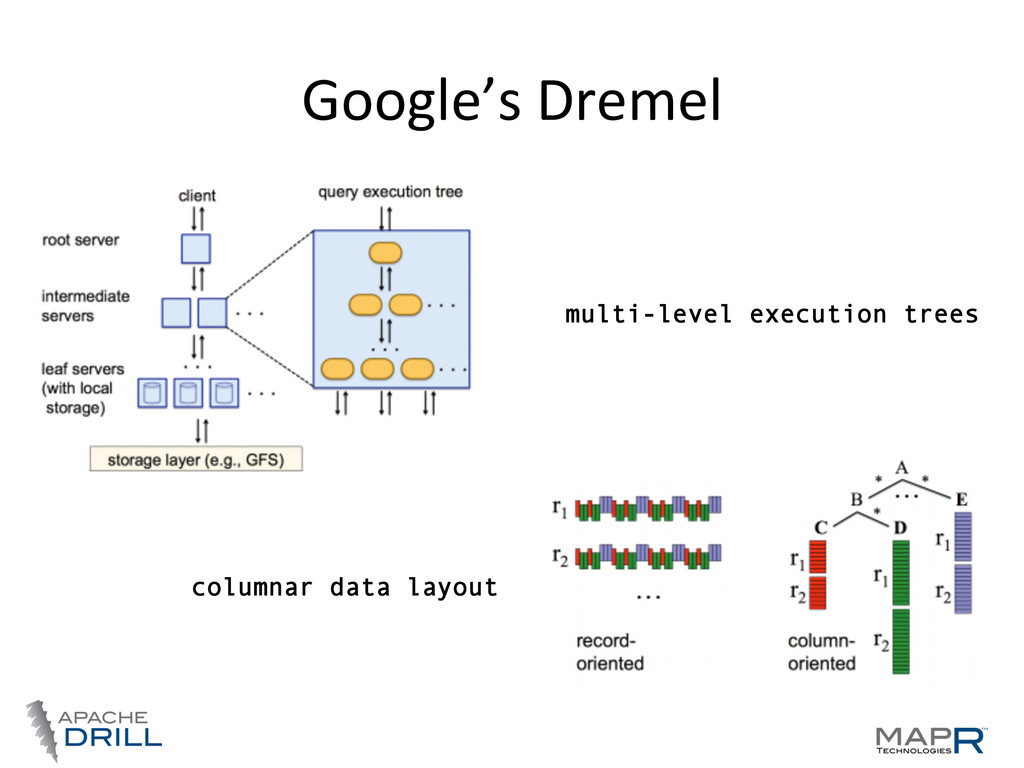
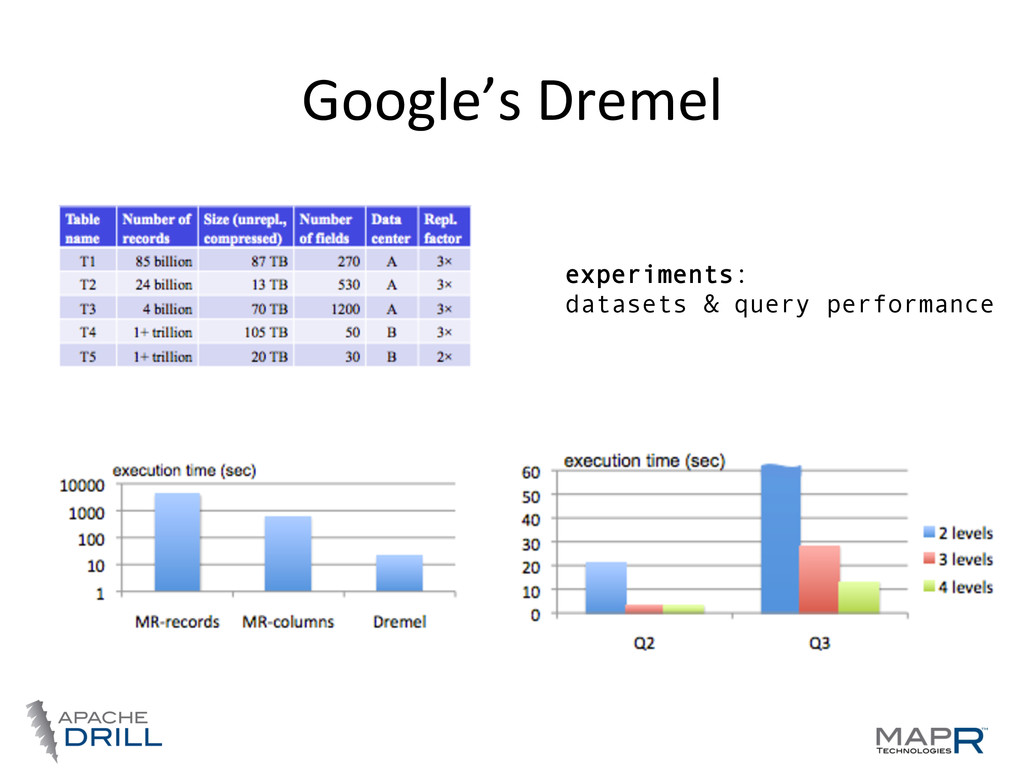
Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Ma@ Tolton, Theo Vassilakis, Proc. of the 36th Int'l Conf on Very Large Data Bases (2010), pp. 330-‐339 Dremel is a scalable, interactive ad-hoc query system for analysis of read-only nested data. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. The system scales to thousands of CPUs and petabytes of data, and has thousands of users at Google. … “ “ Dremel is a scalable, interactive ad-hoc query system for analysis of read-only nested data. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. The system scales to thousands of CPUs and petabytes of data, and has thousands of users at Google. …
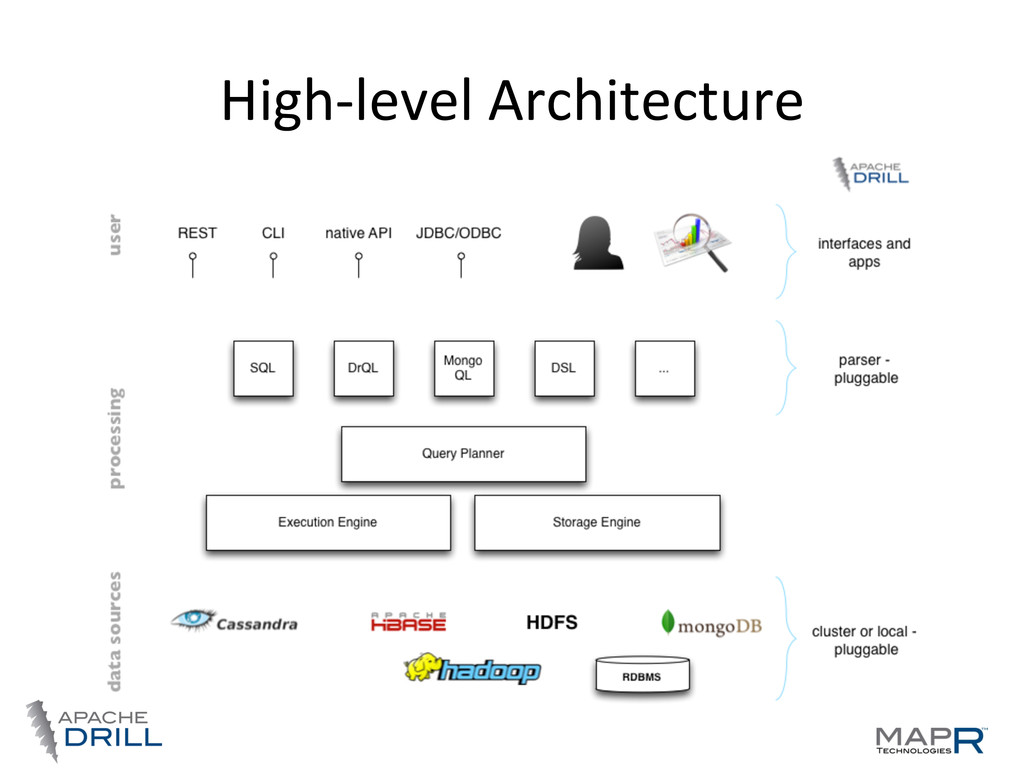
• Standard SQL 2003 support • Plug-‐able data sources • Nested data is a first-‐class ciWzen • Schema is op.onal • Community driven, open, 100’s involved
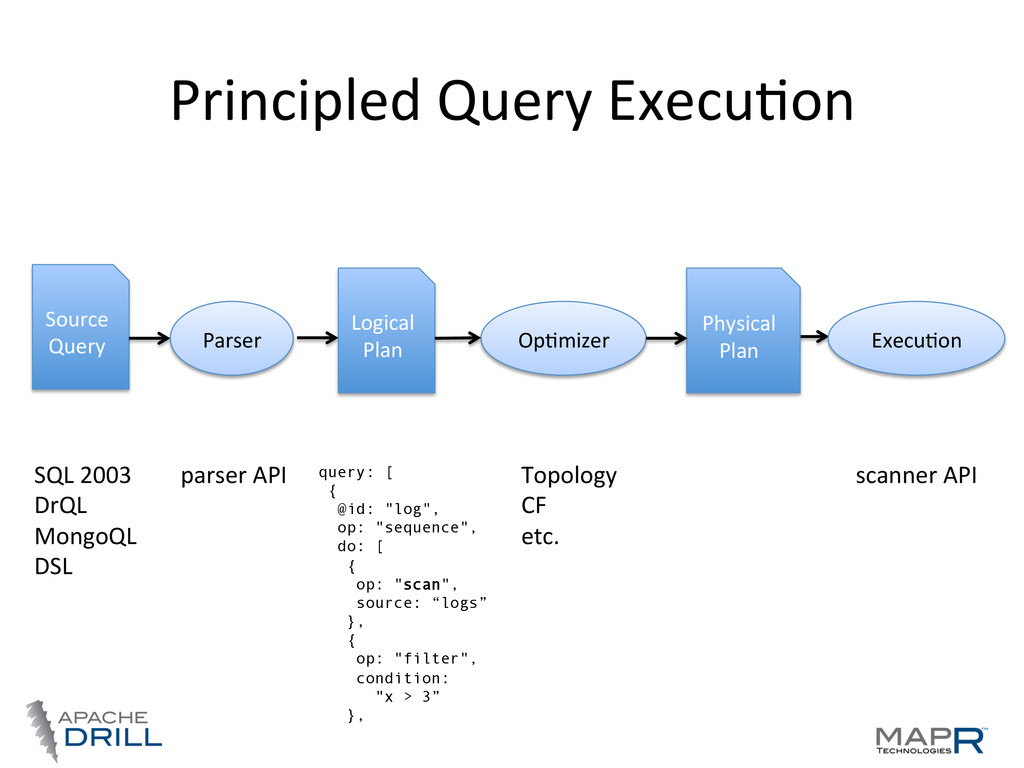
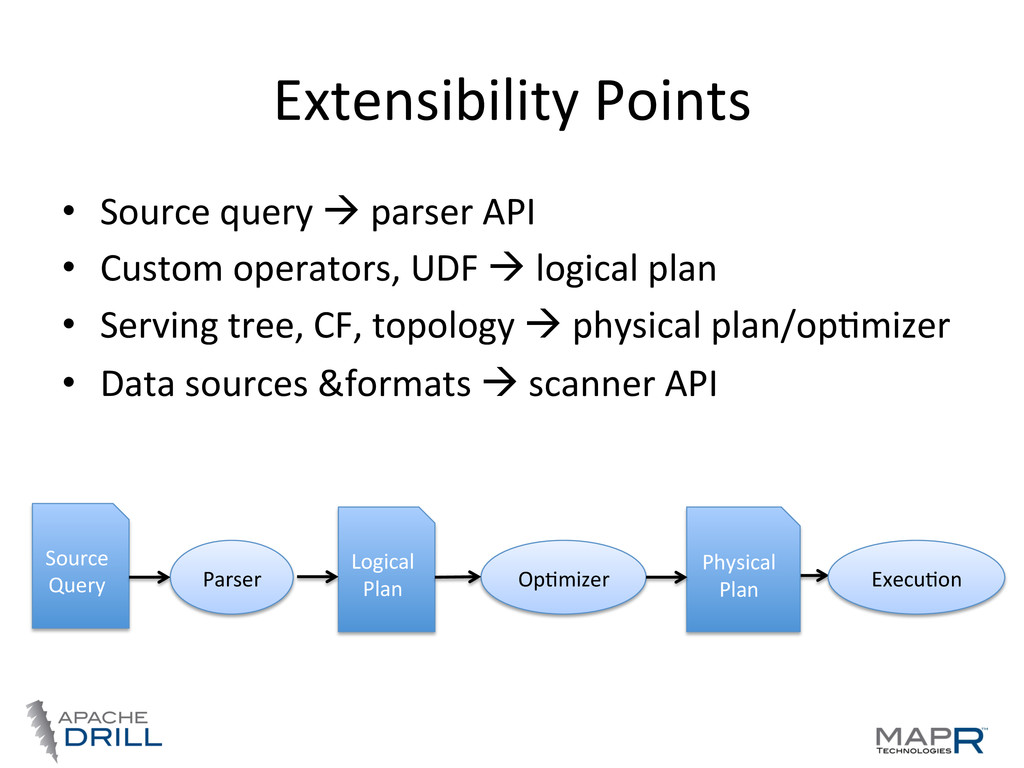
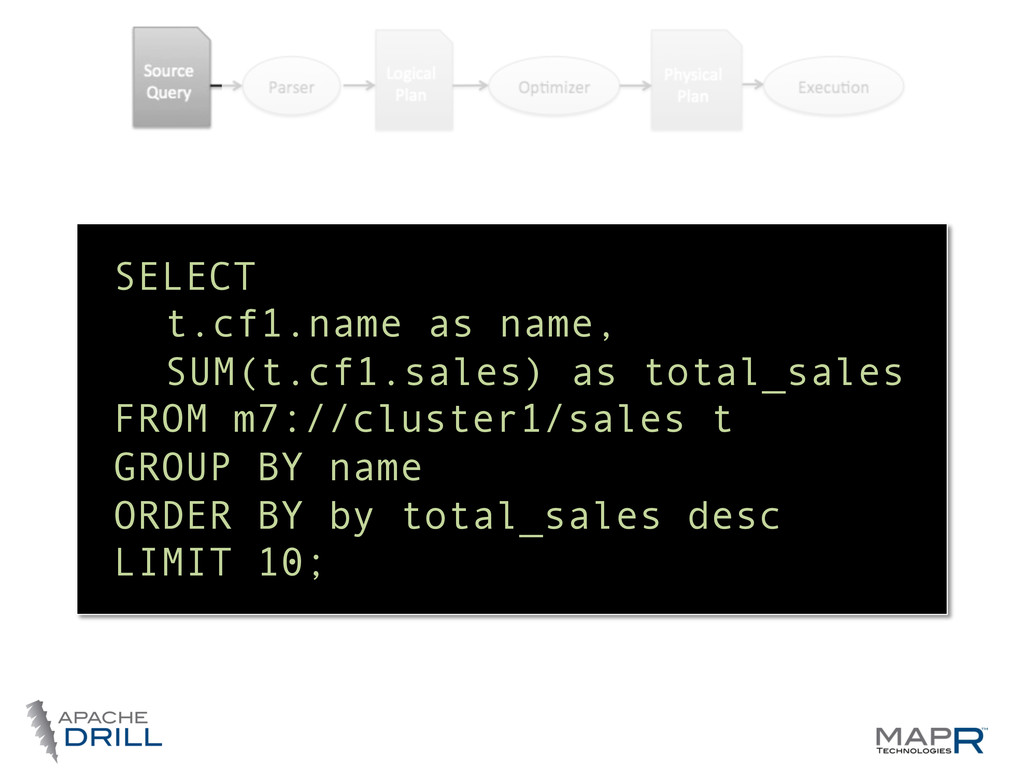
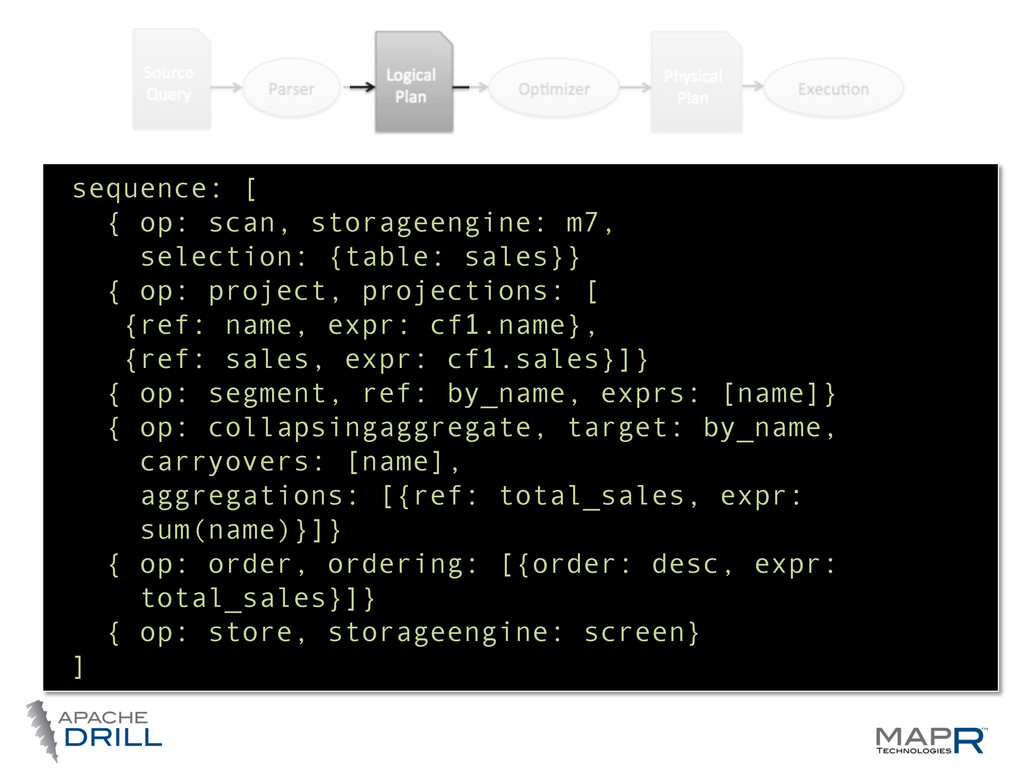
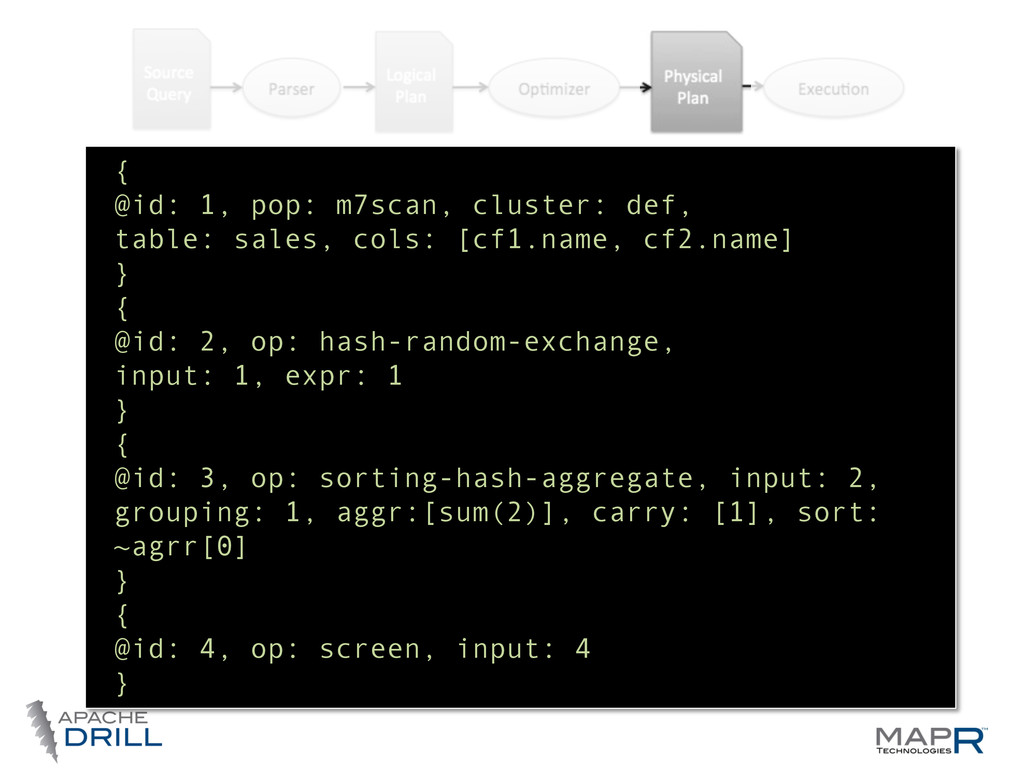
do (analyst friendly) • Logical Plan— what we want to do (language agnosWc, computer friendly) • Physical Plan—how we want to do it (the best way we can tell) • Execu.on Plan—where we want to do it
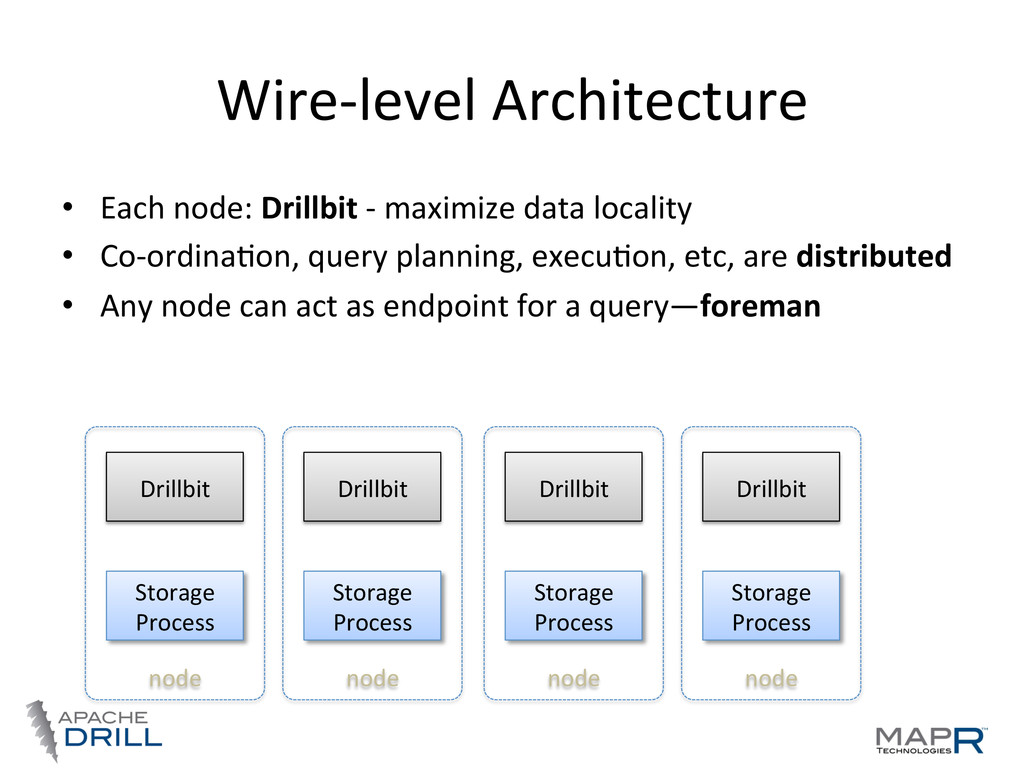
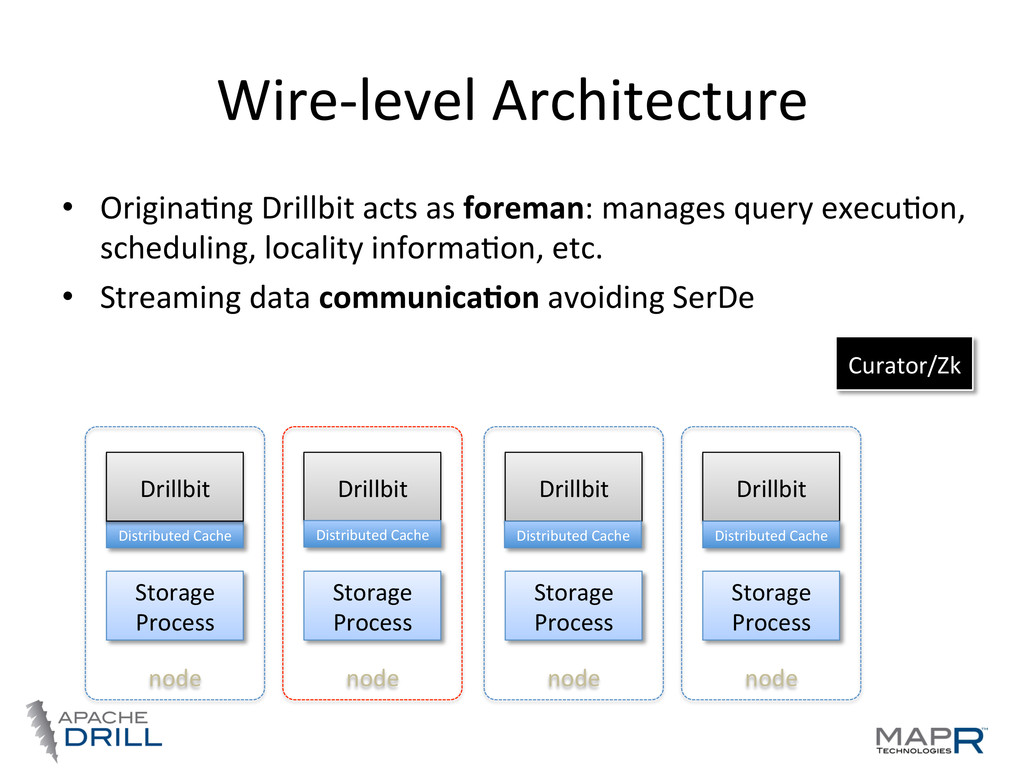
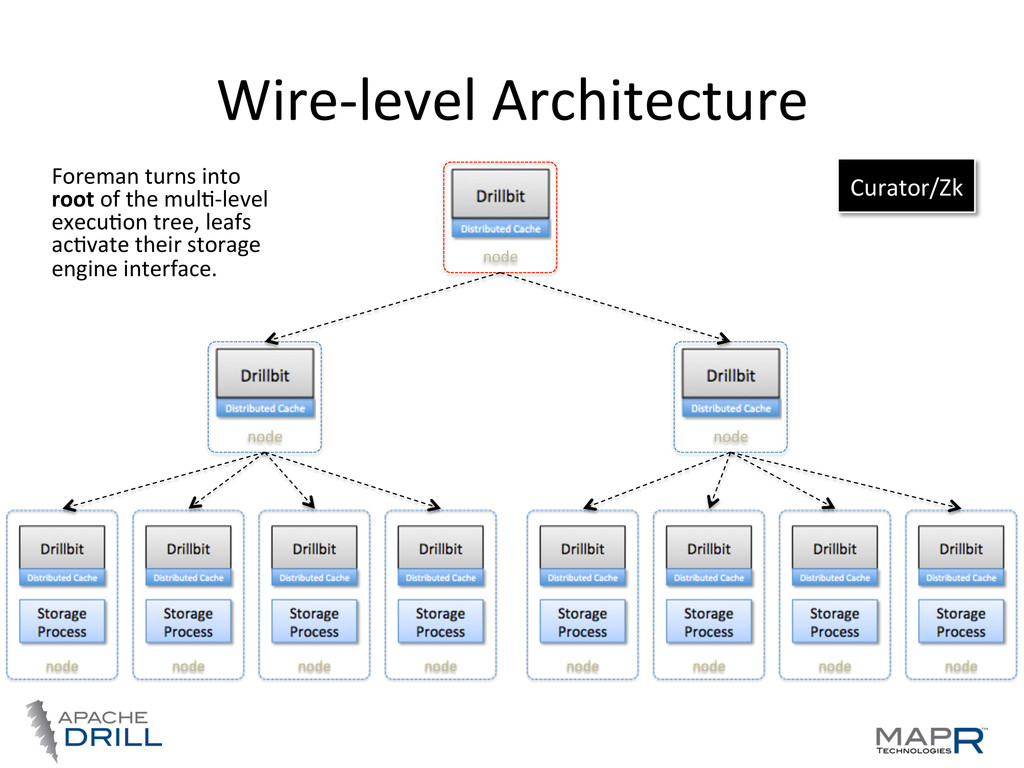
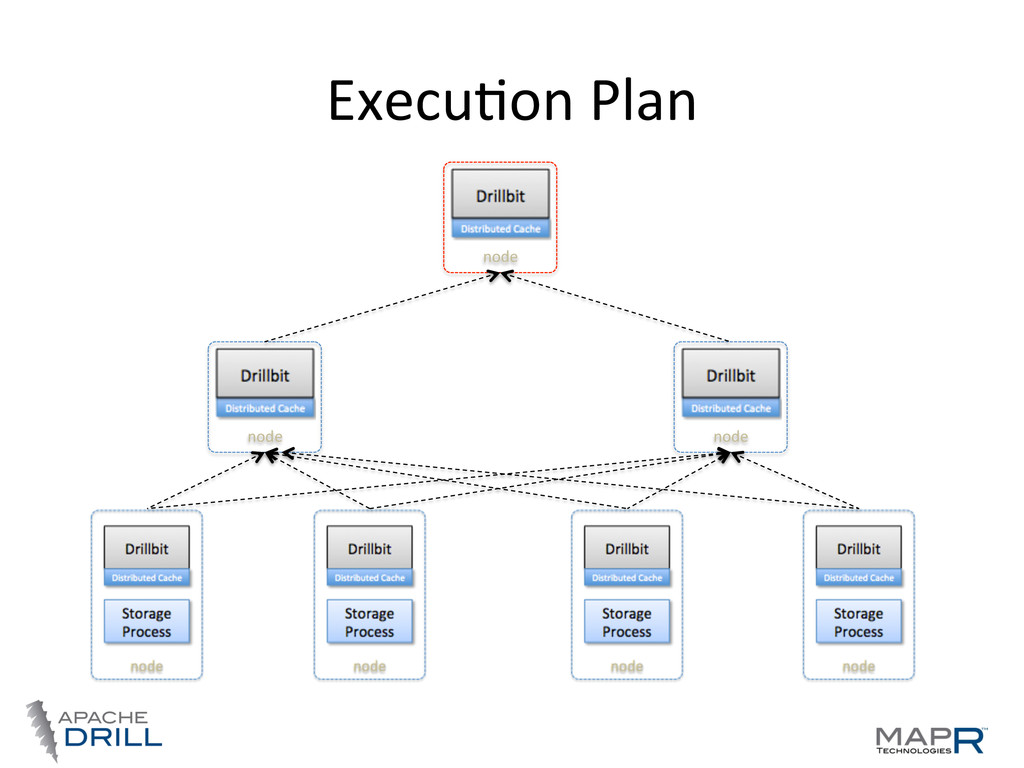
locality • Co-‐ordinaWon, query planning, execuWon, etc, are distributed • Any node can act as endpoint for a query—foreman Storage Process Drillbit node Storage Process Drillbit node Storage Process Drillbit node Storage Process Drillbit node
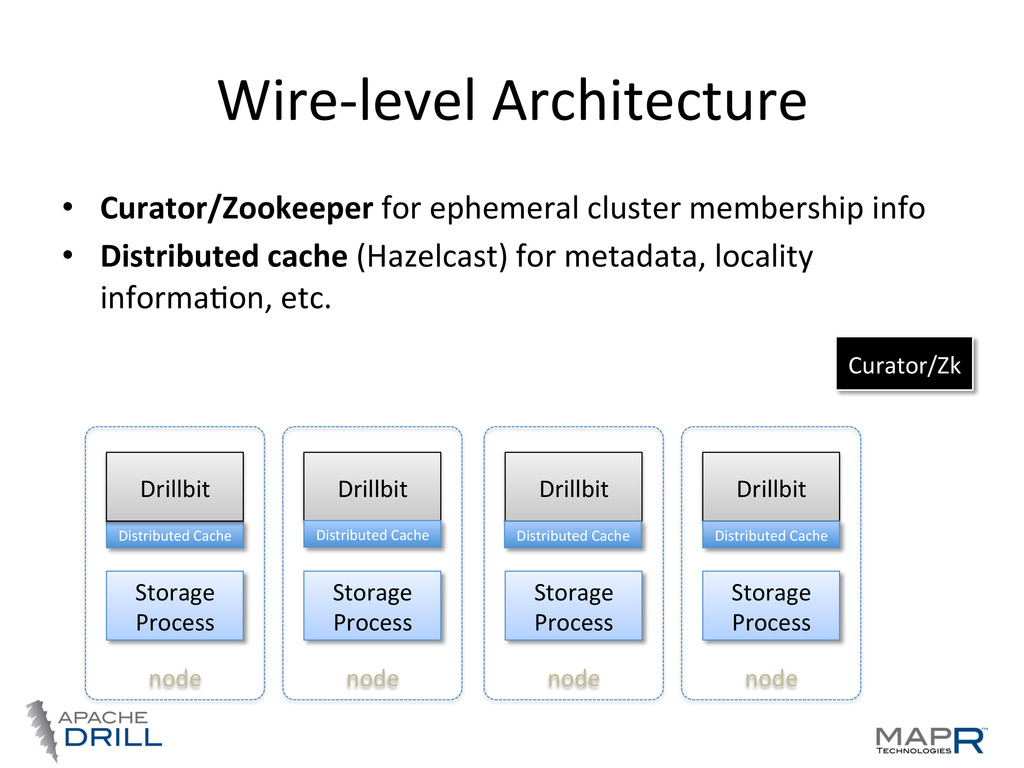
JSON SerDe for metadata • Typesafe HOCON for configuraWon and module management • NeWy4 as core RPC engine, protobuf for communicaWon • Vanilla Java, Larray and NeWy ByteBuf for off-‐heap large data structures • Hazelcast for distributed cache • Neqlix Curator on top of Zookeeper for service registry • Op.q for SQL parsing and cost opWmizaWon • Parquet (hIp://parquet.io)/ ORC • Janino for expression compilaWon • ASM for ByteCode manipulaWon • Yammer Metrics for metrics • Guava extensively • Carrot HPC for primiWve collecWons
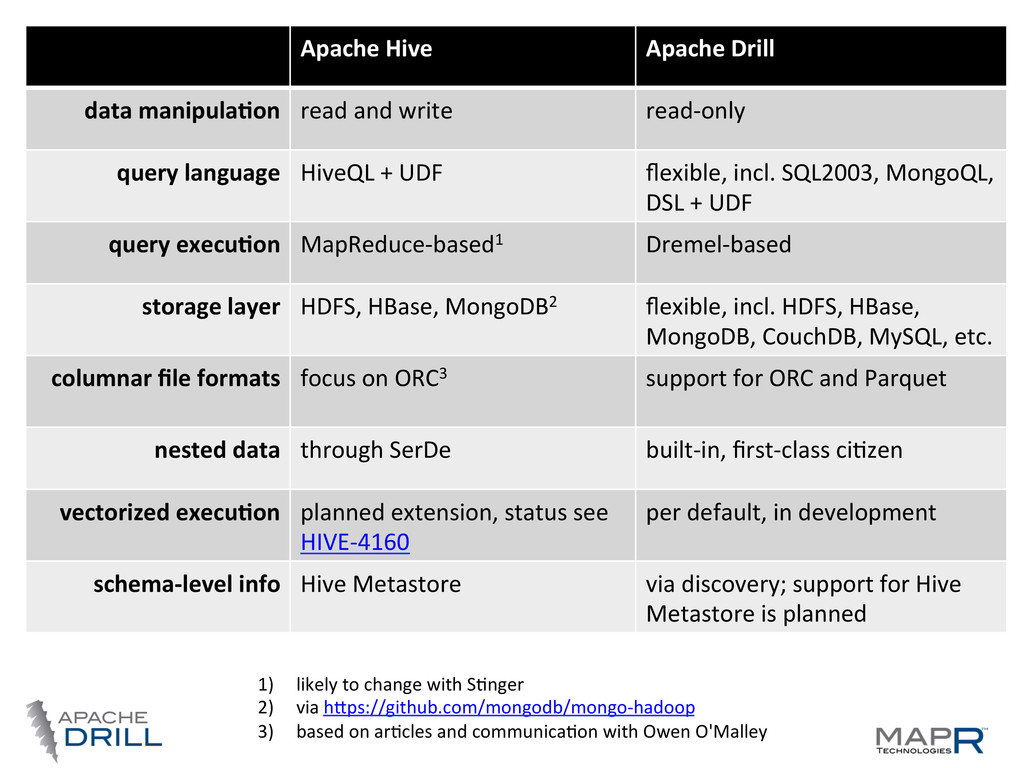
and write read-‐only query language HiveQL + UDF flexible, incl. SQL2003, MongoQL, DSL + UDF query execu.on MapReduce-‐based1 Dremel-‐based storage layer HDFS, HBase, MongoDB2 flexible, incl. HDFS, HBase, MongoDB, CouchDB, MySQL, etc. columnar file formats focus on ORC3 support for ORC and Parquet nested data through SerDe built-‐in, first-‐class ciWzen vectorized execu.on planned extension, status see HIVE-‐4160 per default, in development schema-‐level info Hive Metastore via discovery; support for Hive Metastore is planned 1) likely to change with SWnger 2) via hIps://github.com/mongodb/mongo-‐hadoop 3) based on arWcles and communicaWon with Owen O'Malley
up at mailing lists (user | dev) hIp://incubator.apache.org/drill/mailing-‐lists.html • Standing G+ hangouts every Tuesday at 5pm GMT hIp://j.mp/apache-‐drill-‐hangouts • Keep an eye on hIp://drill-‐user.org/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}