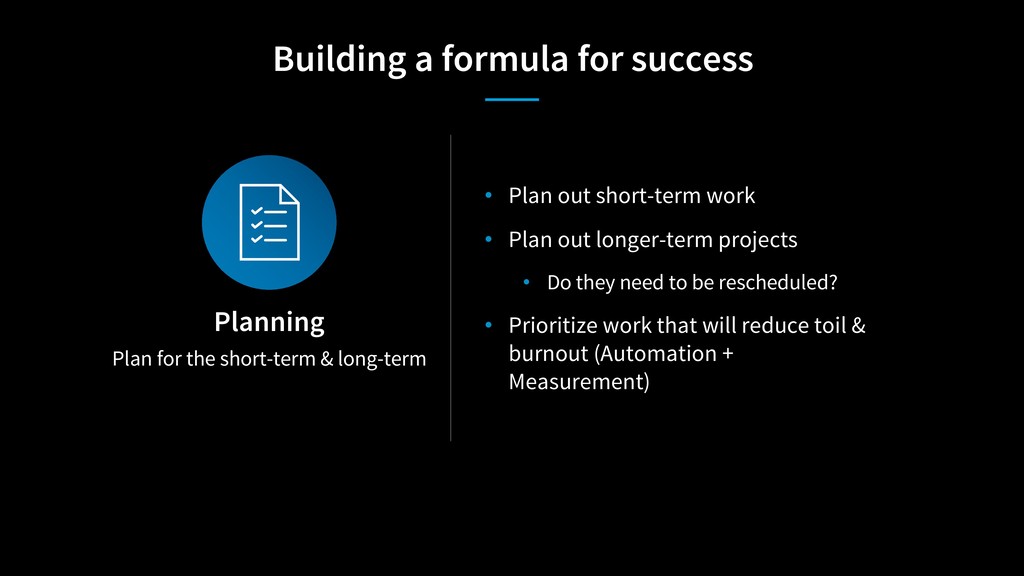
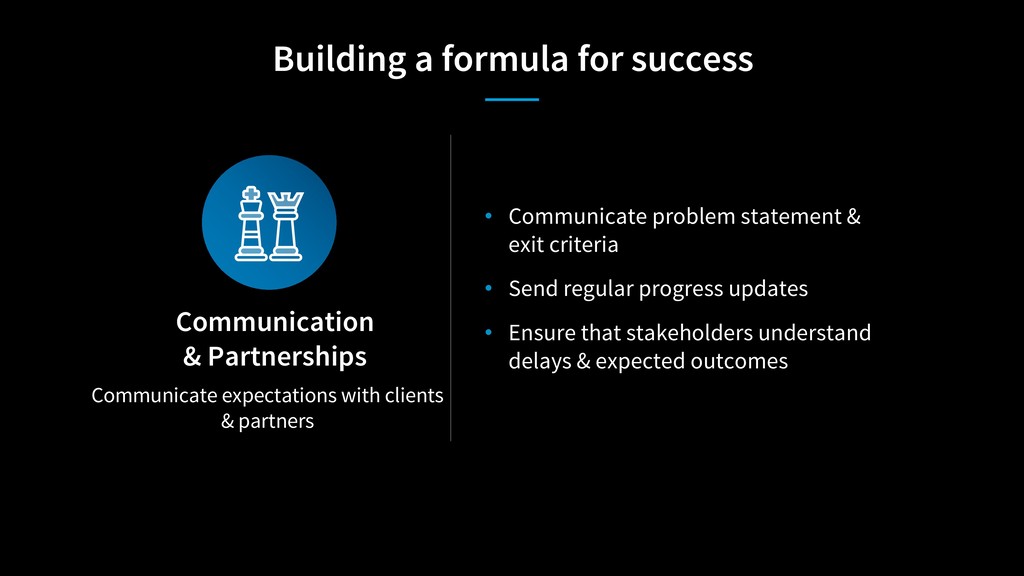
SRE teams can sometimes run into periods of time where they have staff burnout, technical debt or poor reliability. As SRE’s, we’re programmed to keep fighting through the issues, when sometimes it’s best to step back, assess the situation; and ask for help to put the team back on a successful pathway. This talk will discuss three separate experiences where teams needed some extra help to stabilize their services and oncall. We’ll discuss how to identify struggling teams; get the right assistance; and build a strategy for the team to succeed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}