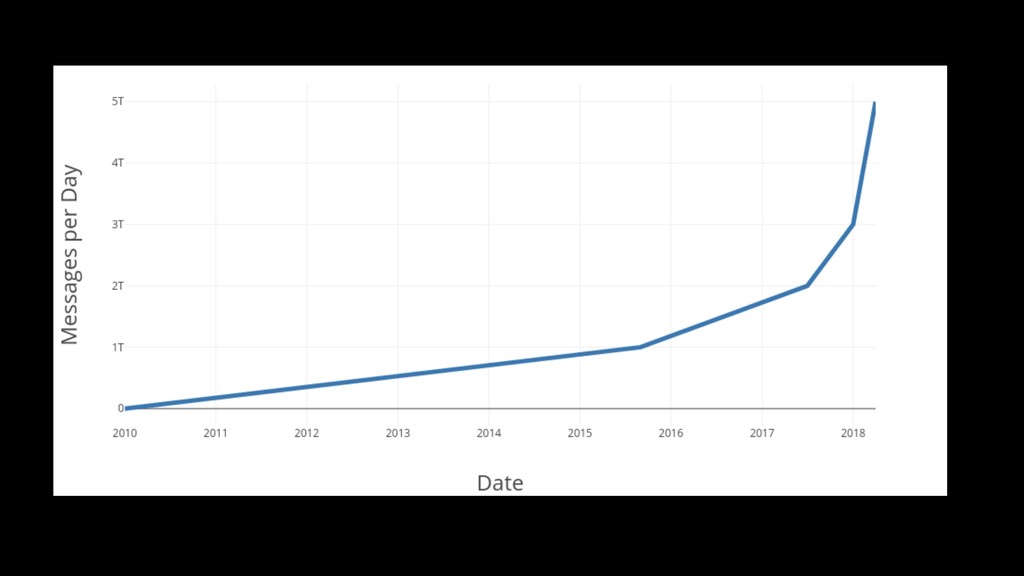
All engineering teams run into trouble from time to time. Alert fatigue, caused by technical debt or a failure to plan for growth, can quickly burn out SREs, overloading both development and operations with reactive work. Layer in the potential for communication problems between teams, and we can find ourselves in a place so troublesome we cannot easily see a path out. At times like this, our natural instinct as reliability engineers is to double down and fight through the issues. Often, however, we need to step back, assess the situation, and ask for help to put the team back on the road to success.
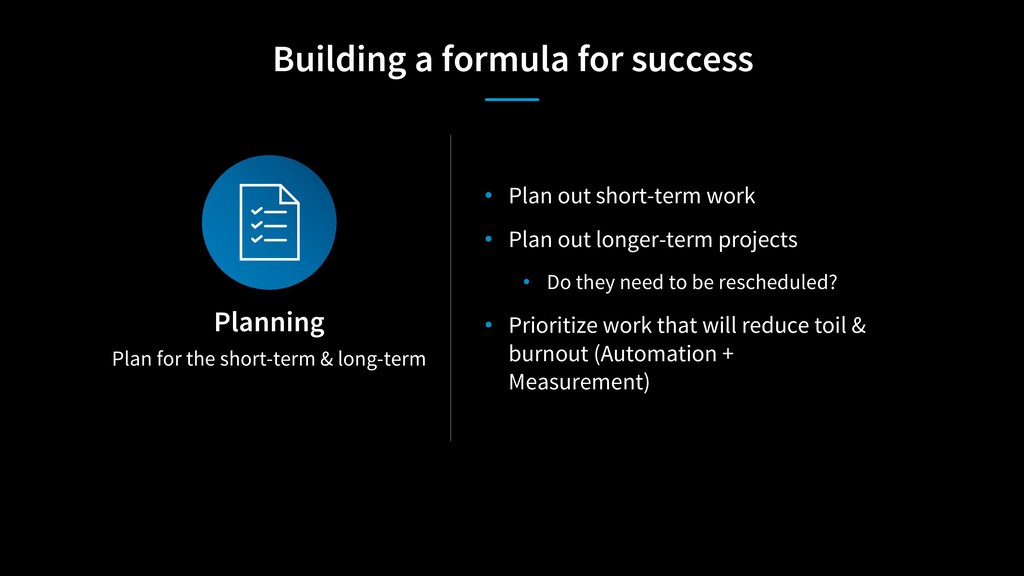
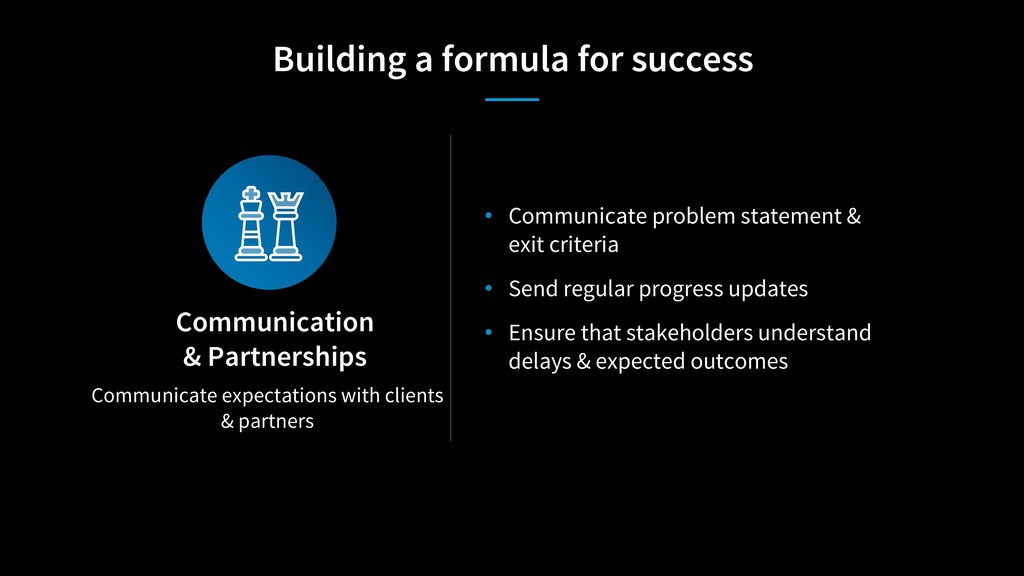
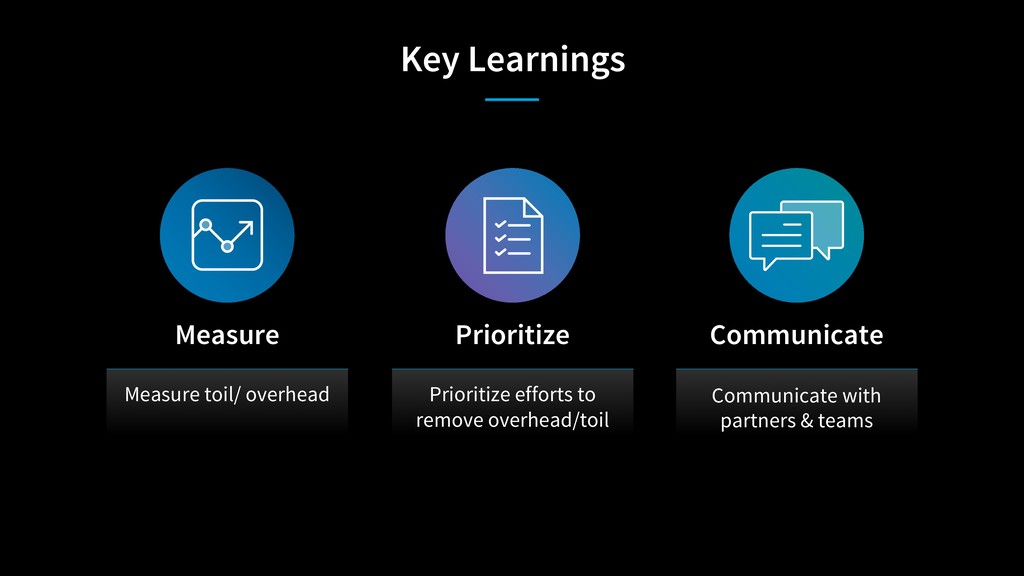
We will look at the process for Code Yellow, the term we use for this process of “righting the ship”, and discuss how to identify teams that are struggling. Through a look at three separate experiences, we will examine some of the root causes, what steps were taken, and how the engineering organization as a whole supports the process.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}