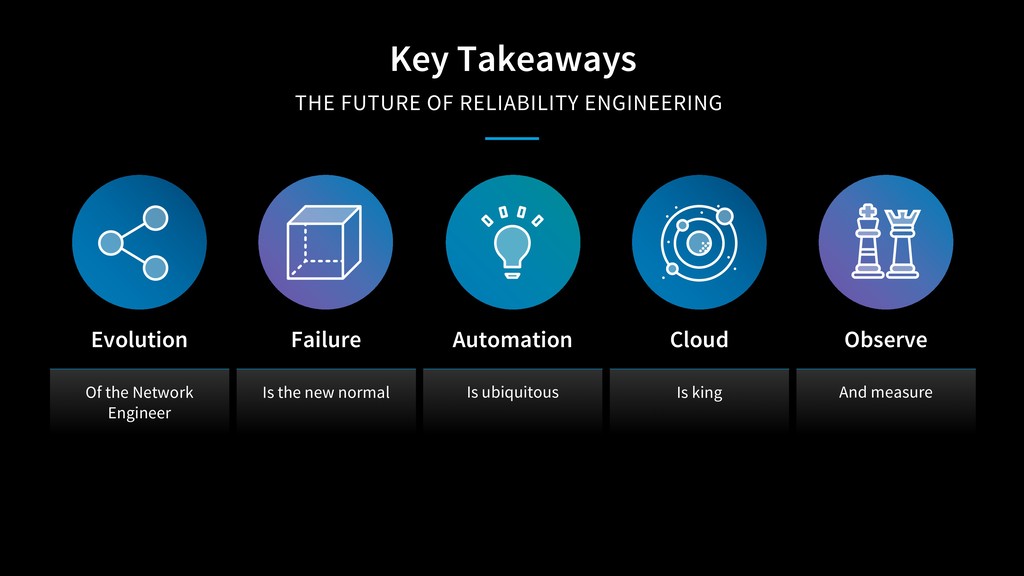
In 2018, Site Reliability Engineering (SRE) will turn 15 years old. Since Google's inception of the term SRE, companies across the world have adopted a new operations mindset along with automation, deployment and monitoring principals. Most of what SRE does now is well established throughout the industry, so what is the next-wave of reliability principals and automation frameworks?
This session will dive into what the future holds for reliability engineering as a field and what will be the next areas of investment and improvement for reliability teams.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
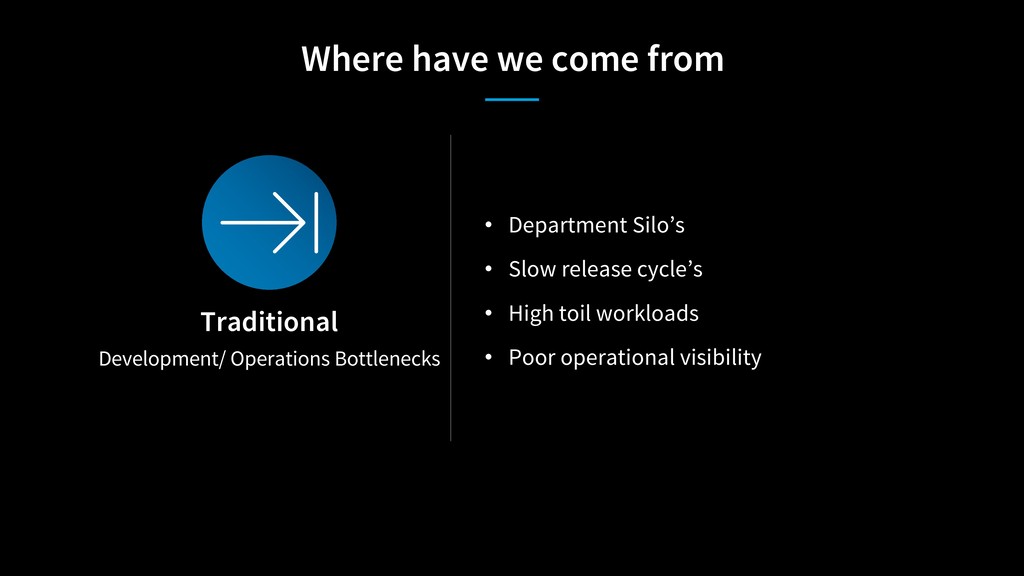{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
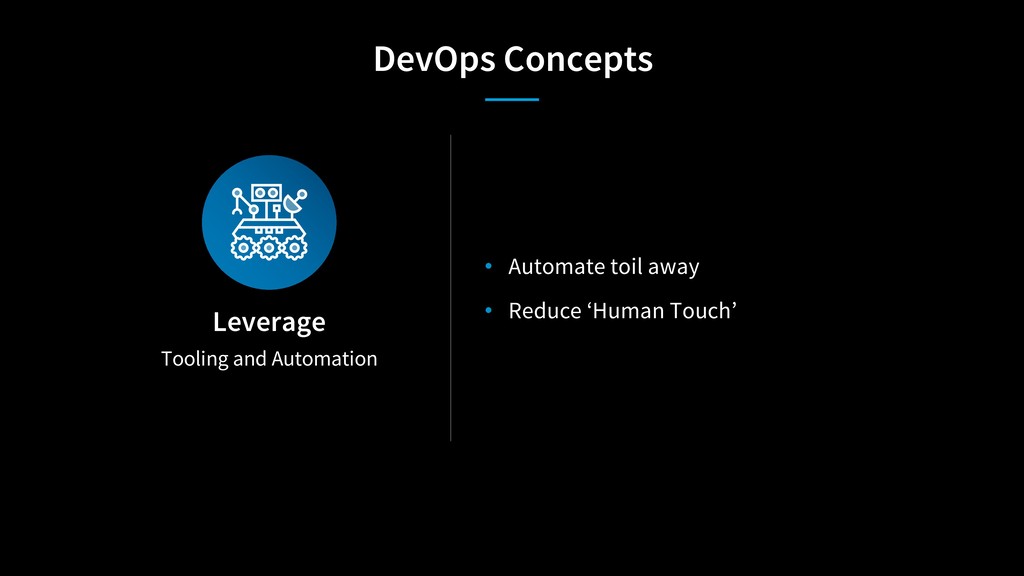{kind=link}
{kind=link}
{kind=link}
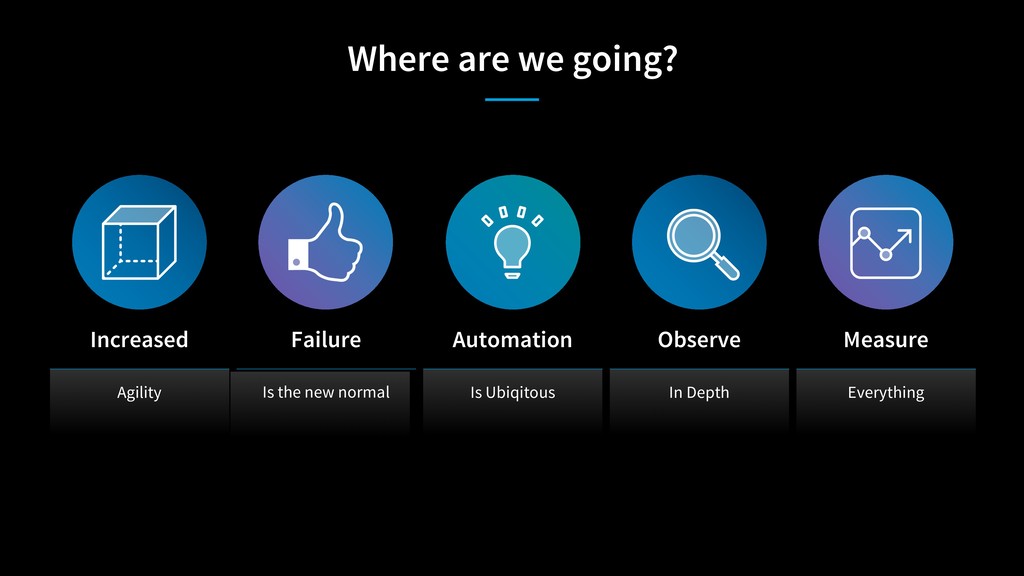{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
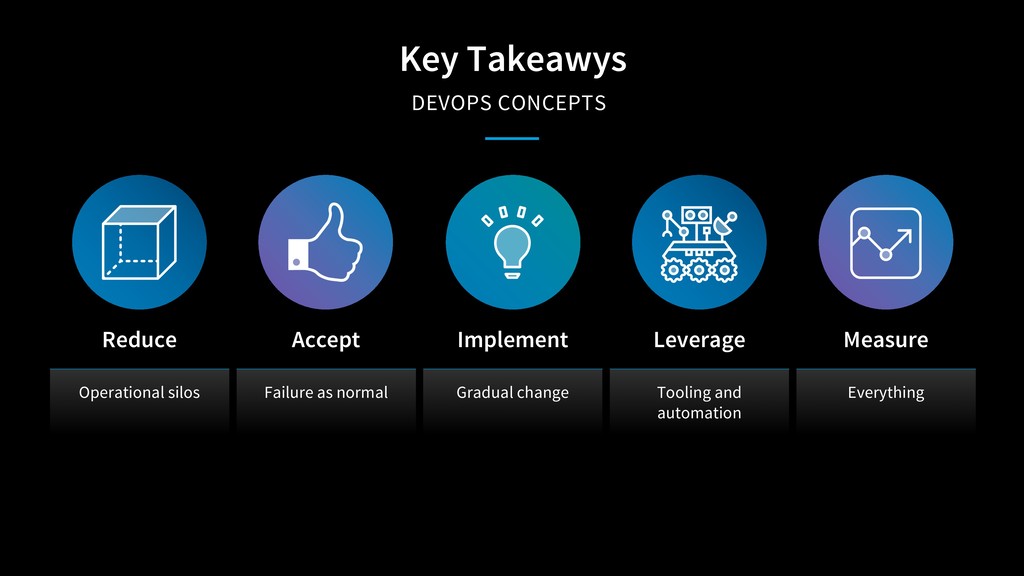{kind=link}
{kind=link}
{kind=link}
{kind=link}