Mostrar um Overview sobre como pode-se criar uma arquitetura (ou modificar uma já existente) para ganhar-se produtividade, diminuir custos de manutenção e preparar-se para escalar em situações de caos. (Versão com as notas do apresentador)
crescente de bugs 2. Pressão dos investidores e crescimento violento de usuários 3. Incapacidade de escalar com tranquilidade 4. Efeito castelo de cartas
prazo, aprender uma tecnologia que se adapta melhor às suas necessidades do que manter estruturas adaptadas para funcionar nas ferramentas em que você já domina.
NoSQL DocumentS Column Families CAP Theorem ACID transactions Sharding TimeSeries Historic Data Key Value Partitioning Existem muitos modelos de persistência hoje. Apesar de RDBMS ser o mais academicamente difundido, vale a pena verificar se outros modelos não atender melhor. Aqui entra um ponto de P&D que deve, no início do projeto, demorar no máximo 2 dias (MVP). Se for um projeto em curso, 5 dias de pesquisa, e a elaboração um “Plano de Descontinuidade” para migrar o antigo modelo para o novo.
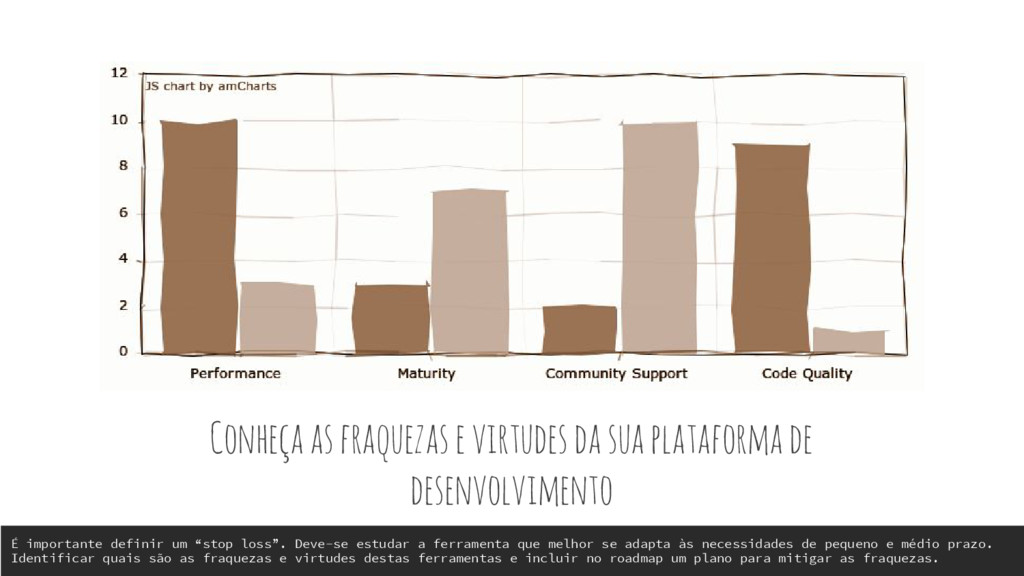
É importante definir um “stop loss”. Deve-se estudar a ferramenta que melhor se adapta às necessidades de pequeno e médio prazo. Identificar quais são as fraquezas e virtudes destas ferramentas e incluir no roadmap um plano para mitigar as fraquezas.
é contraditório pensar em escala primeiro! São tarefas simples e deve durar no máximo 1 ou 2 dias! Dentre outros fatores, as pessoas esquecem de rever seus modelos de autenticação para q a sessão pertença ao cluster, e não à aplicação. O mesmo se aplica a log, stacktraces, etc… Se estas tarefas tornarem-se demoradas, você está usando as ferramentas erradas...
for inevitável, que ele seja o menor possível” Evitar: Criar classes genéricas para tudo, criar abstrações desncessárias, módulos que nunca vieram a ser realmente usados por outros projetos. Ler “Regra da Excessão, Coincidência ou Tendência”: http://bit.ly/1syanOu
de arrumar! Deve-se entender que não existe código ruim, mas código com menos benefícios. Ler “Regra da Excessão, Coincidência ou Tendência”: http://bit.ly/1syanOu
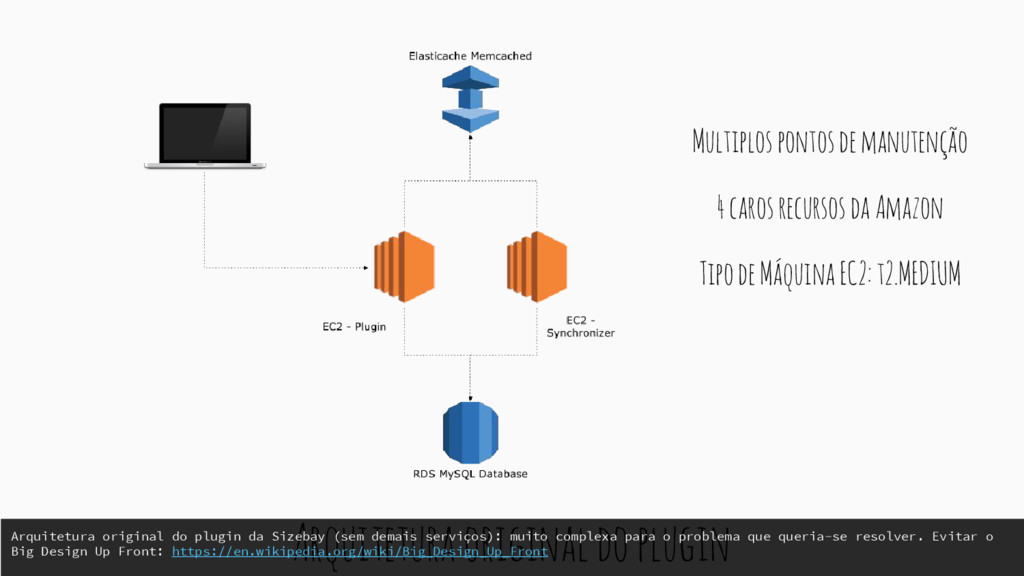
recursos da Amazon Tipo de Máquina EC2: t2.MEDIUM Arquitetura original do plugin da Sizebay (sem demais serviços): muito complexa para o problema que queria-se resolver. Evitar o Big Design Up Front: https://en.wikipedia.org/wiki/Big_Design_Up_Front
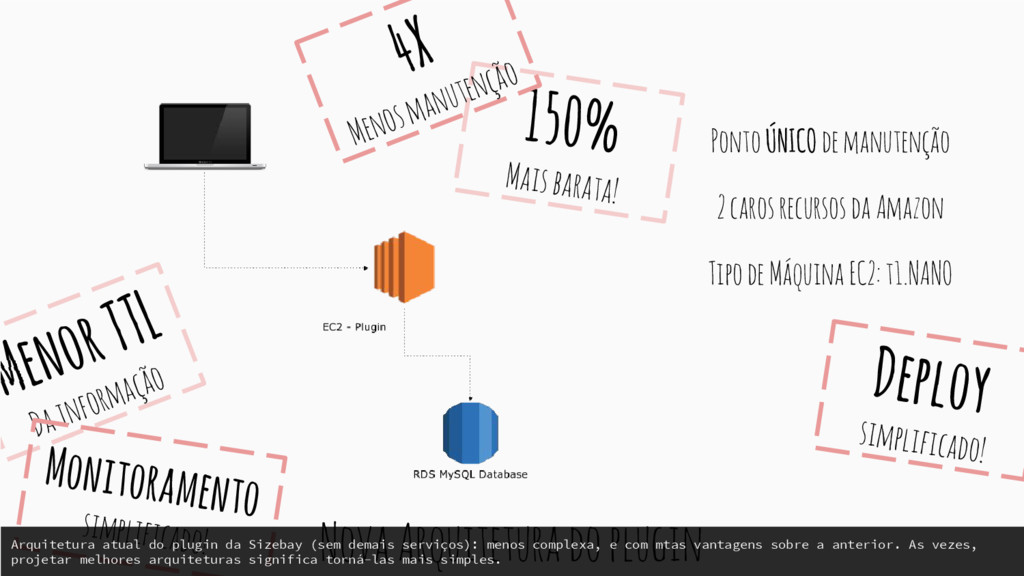
Ponto ÚNICO de manutenção 2 caros recursos da Amazon Tipo de Máquina EC2: t1.NANO Deploy simplificado! Menor TTL Da informação Monitoramento simplificado! Arquitetura atual do plugin da Sizebay (sem demais serviços): menos complexa, e com mtas vantagens sobre a anterior. As vezes, projetar melhores arquiteturas significa torná-las mais simples.
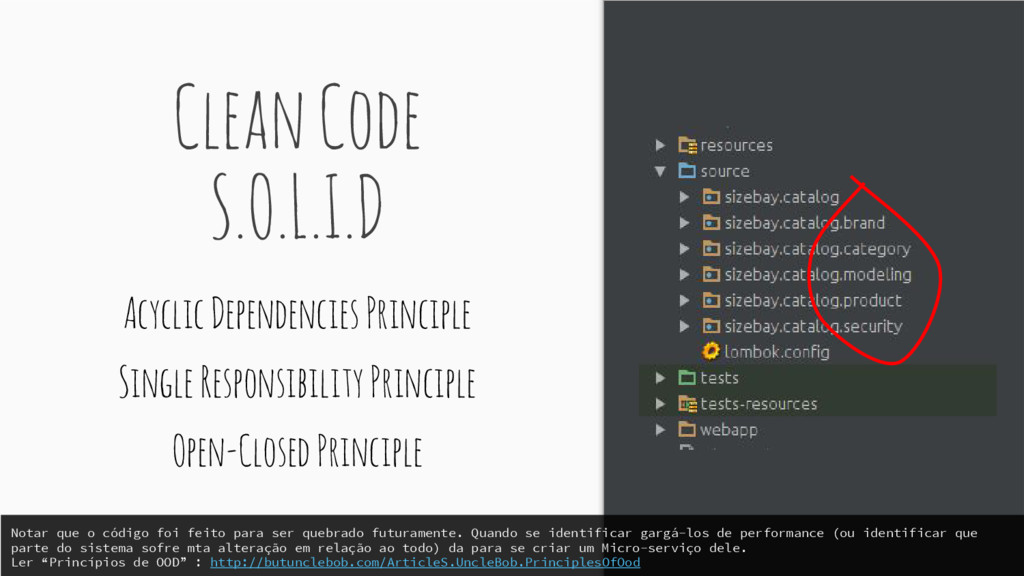
Principle Notar que o código foi feito para ser quebrado futuramente. Quando se identificar gargá-los de performance (ou identificar que parte do sistema sofre mta alteração em relação ao todo) da para se criar um Micro-serviço dele. Ler “Princípios de OOD” : http://butunclebob.com/ArticleS.UncleBob.PrinciplesOfOod
você é anti-ético!” Existem muitas ferramentas e abordagens para se testar código, já não dá pra dar desculpas. Se a forma que se codifica os testes gera muito retrabalho (ou manutenção nos testes), então o código testado não está bem feito: procure melhorar sua orientação a objetos. Respeite os seus cliente e colegas de trabalho e faça testes. Ler: “Refactoring” (Martin Fowler); “Princípios de OOD” : http://butunclebob.com/ArticleS.UncleBob.PrinciplesOfOod
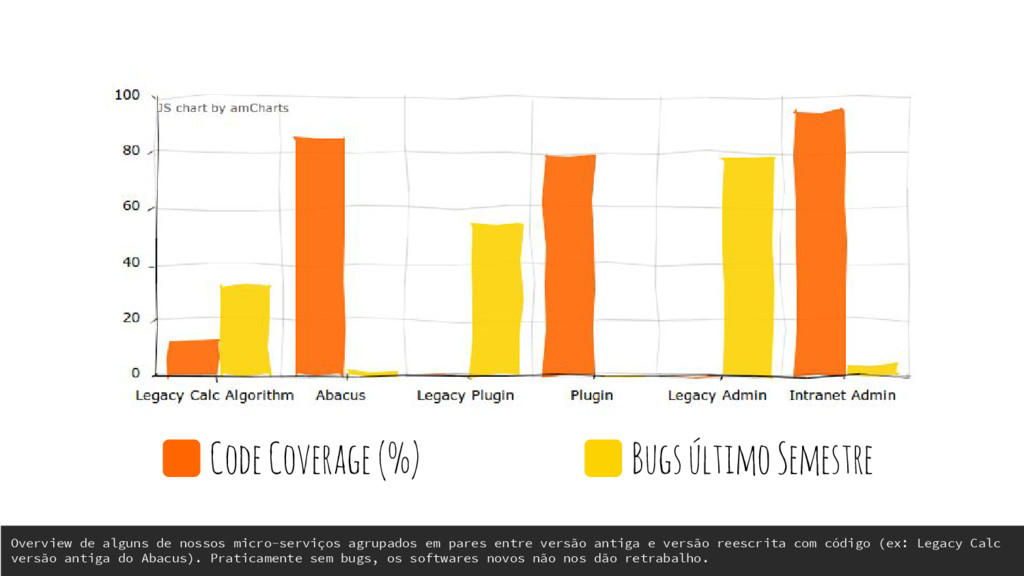
nossos micro-serviços agrupados em pares entre versão antiga e versão reescrita com código (ex: Legacy Calc versão antiga do Abacus). Praticamente sem bugs, os softwares novos não nos dão retrabalho.
Acoplamento entre objetos Erros básicos de lógica Toda linguagem de programação possui ferramentas que ajudam na análise estática de código, para identificar possíveis problemas. Maven e Gradle são compeões de plugins que ajudam nisso. Sugestões: CheckStyle e FindBugs. (PMD é mto Old School)
C Dia C == Dia do Caos. Este dia vai chegar, e se você estiver preparado, você será previamente notificado e terá tempo hábil de evitar uma catastrofe.
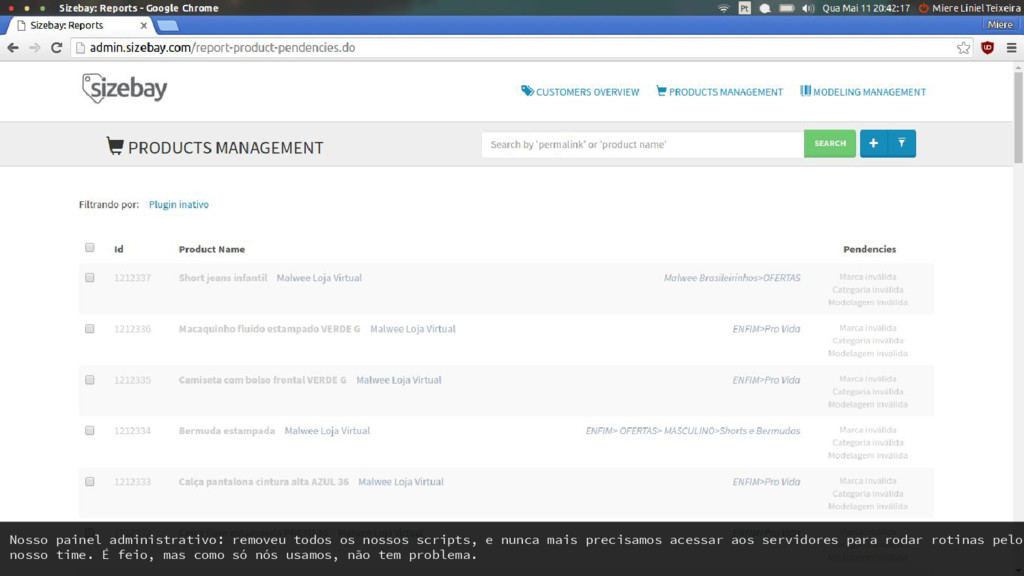
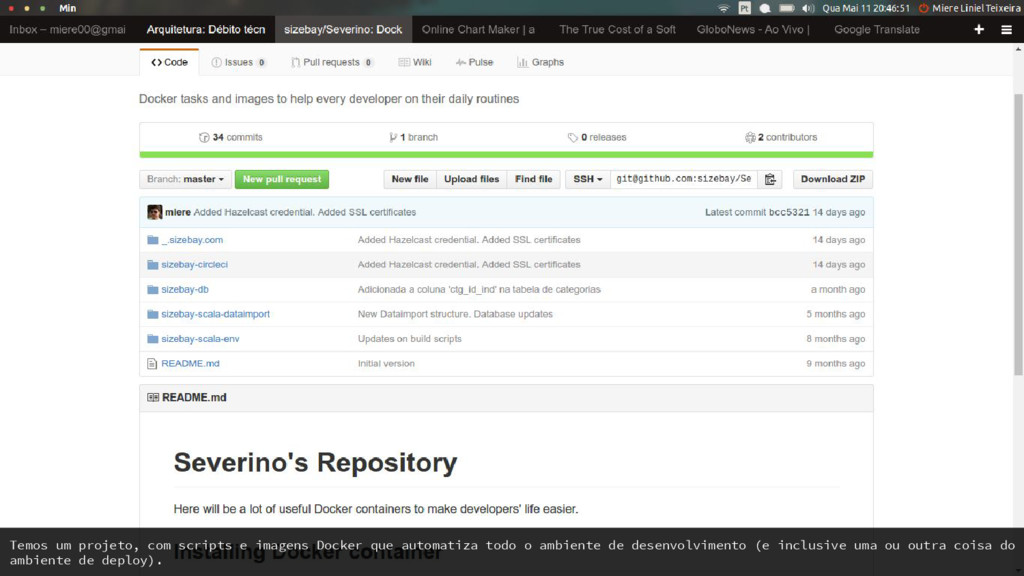
no notebook) Scripts costumam não ter testes, e por não fazer parte do ciclo de desenvolvimento acabam ficando desatualizados. Por isso não são confiáveis. Sem falar que, se forem rotinas que o resto do time poderia usar, você perde tempo executando-o pelo seu time… Automatize tudo e nunca mais se preocupe com isso!
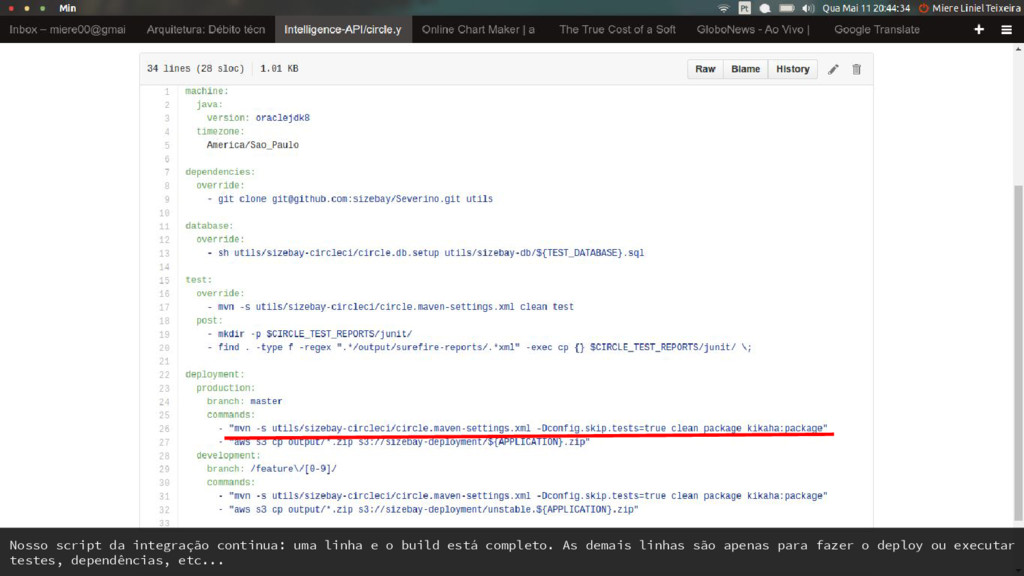
solto nas máquinas dos developers. Pode-se usar o Git Flow para garantir que commits nao quebrem builds importantes. Ler apresentação sobre Git Flow: http://bit.ly/1TZdXcW
torna-se a cereja do bolo. Ele segmenta o fluxo de commits e permite que sejam feitas liberações sem impactos de features inacabadas. Ler apresentação sobre Git Flow: http://bit.ly/1TZdXcW
MailTrack.io DripStat Librato Elastic Load Balancer StatusCake Slack Elastic Search Não se perde tempo entendendo as melhores práticas do MySQL, do ElasticSearch, MemCached, etc… Deixe que alguém faça isso por ti: Amazon Web Services, Google Cloud, RedShift, etc...
que é crítico para a empresa. Porém, se alguém puder ensinar os caminhos das pedras melhor… A longo prazo, conforme o time vai amadurecendo é necessário incentivar Pesquisa e Desenvolvimento, diminuindo aos poucos a terceirização...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![thanks! E-mail: [email protected] E-mail: [email protected] Skype: miere.teixeira Twitter: miere GitHub:](https://files.speakerdeck.com/presentations/53da57de8a54472bafe29eda5bf4406d/slide_48.jpg){kind=link}