concepts ◦ Class project design discussion • Remaining time ◦ Step-by-step development of the class project ◦ (Focus is on techniques more than on a particular implementation)
of Flack ◦ Flack is a chat server app I used in the “Flask at Scale” class I gave at PyCon 2016 • The application lives on 7 (yes, seven!) GitHub repositories • Runs on Python 3.4+ and Docker • Not tied to any specific cloud or container orchestration technology
(8GB recommended) ◦ Vagrant ◦ VirtualBox ◦ Everything is installed in an Ubuntu 16.04 VM (Windows, Mac, Linux laptops are all OK!) • Deployment commands: git clone https://github.com/miguelgrinberg/microflack_admin cd microflack_admin vagrant up # to create the VM or restart it after shutdown vagrant ssh # to open a shell session on the VM vagrant halt # to shutdown the VM (without destroying it) vagrant snapshot save clean # to save a snapshot with name “clean” vagrant snapshot restore clean --no-provision # to restore the snapshot vagrant destroy # to delete the VM
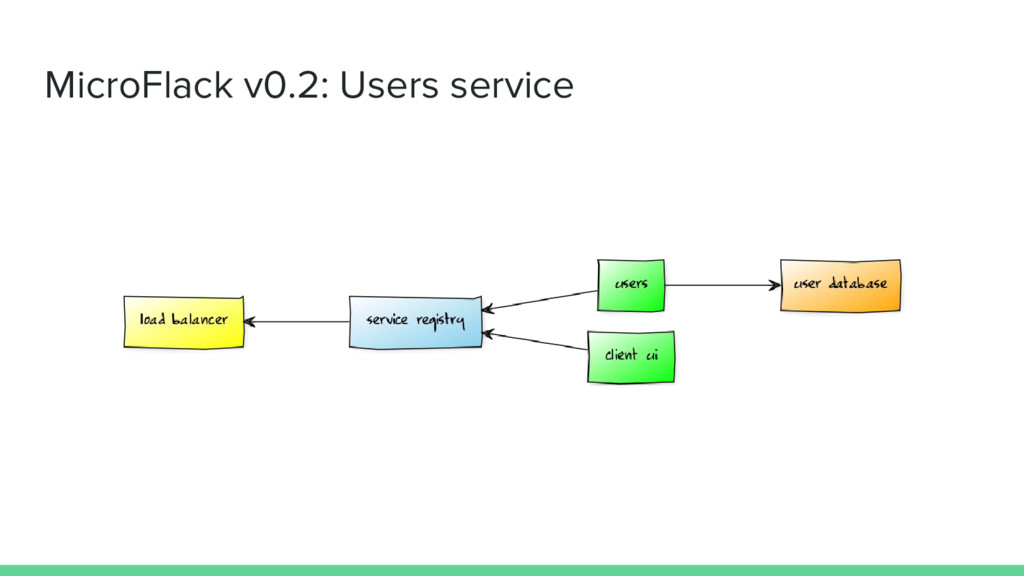
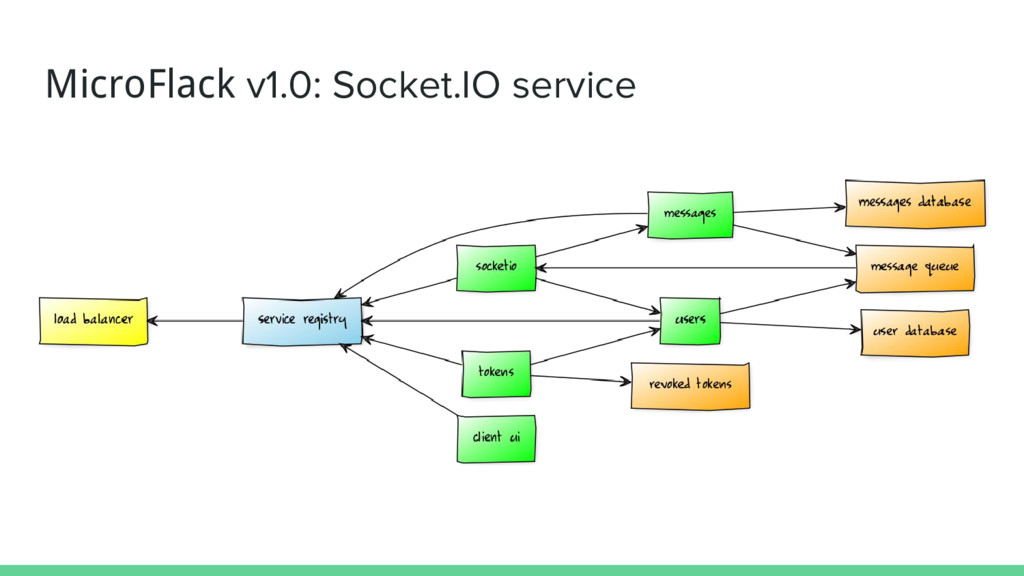
Each service is a standalone Flask app • Two of the services use MySQL databases • Services run in Docker containers • Services communicate over HTTP, message queue or service registry • All services are load balanced • Services scale independently of each other • Upgrades can be done without downtime
with varying degrees of experience • Scaling flexibility • More reliability • Less coupling • More choice • Deploy/upgrade while running So where is performance in this list?
is very hard • Several strategies ◦ Microservices only going forward ◦ Break pieces of functionality into microservices over time ◦ Refactor the entire monolith into microservices • In all cases, a base platform needs to be put in place before refactoring work begins • Good automated tests are crucial in avoiding bugs when refactoring functionality into a microservice
think you don’t need load balancing? ◦ Upgrades without downtime require a load balancer for a seamless transition ◦ Autoscaling, A/B testing, green/blue deployments, etc. become possible • Many options ◦ Open source: Nginx, HAProxy, Træfik ◦ As a service: AWS, OpenStack, Azure, Google Cloud, etc. ◦ Serverless: Load balancing and scaling are implicitly done by the cloud operator ▪ The Lambda and API Gateway services on AWS are by far the best in this category ◦ Hardware: F5
of running services • All running services maintain an entry in the service registry • The load balancer’s configuration is generated and updated from the registry contents • Many great open source projects to choose from: ◦ Etcd (CoreOS) ◦ Consul (HashiCorp) ◦ Zookeeper (Apache) ◦ Eureka (Netflix) ◦ SmartStack (Airbnb) ◦ and more!
to a single stream to avoid the complexity of maintaining lots of individual log files • Open source: ◦ ELK stack (elasticsearch + logstash + kibana) ◦ Logspout • Several commercial options: ◦ Papertrail ◦ Splunk ◦ Loggly ◦ and more!
• Each container runs a virtualized host ◦ You can have containers using different Linux distros on the same host ◦ Dependencies that would conflict if installed on the same host can be installed on containers ◦ Virtualized network ports • A container maps to one main process, but there can be additional tasks • Not a required component of the stack, but very convenient
No way to avoid them for service registry, databases, message queues, etc. • Stateless services are easily scalable, replaceable and disposable • Application-level services should ideally be stateless, and should use stateful services for storage • The state associated with a service should be private ◦ Each service must use its own database ◦ This prevents coupled services that are difficult to upgrade independently of each other ◦ Database joins across services must be done in the application
compatible ◦ Why? Because a distributed system cannot be updated atomically without downtime • Database migrations must not break any code that may still be deployed ◦ Phased micro-upgrades can help with column renames or deletes, constraints, etc. • API changes must not break any code that may still be deployed ◦ Why? Need a way to upgrade the API consumer and producer independently • Complex changes that span several services must be “orchestrated” so that they can be applied as micro-deployments without breaking the system
with the service registry, or is “discovered” by it • The load balancer watches the registry and updates itself to include the new microservice • The new service starts receiving traffic from the load balancer • If more than one instance of the service exist, the traffic is split among them • The service sends “keep-alive” signals, or responds to periodic health checks • When the service is stopped, or stops sending keep-alives, or fails a health check, it is removed from the registry, and in turn from the load balancer
VM • setup-host.sh, setup-all-in-one.sh, make-db-passwords.sh: deploy scripts • mfvars: common environment variables • mfclone: clone the repositories for all the services • mfbuild: build Docker images for services • mfrun: start services • mfkill: stop services • mflogs: consolidated log stream of all services • mfupgrade: upgrade services • mfenv: generate a .env file with environment needed for development • mfdev: attach a locally running service to a deployed system for debugging • etcd-dump: dump the contents of the service registry to the console
microservices need ◦ Service registration ◦ Unit testing helpers ◦ Inter-service communication ◦ Authentication handlers • We’ll use a Python package that services can install with pip • Easy option: install from pypi (if you don’t mind making it public) • Less easy option: private package installed from a local file ◦ We’ll use the Python wheel format for this (pip install wheel) ◦ The --find-links option in pip can install packages from a local file system directory ◦ The mkwheel script builds the wheel packages
database are inconvenient ◦ Services would need to send a request to the tokens service for verification • JSON Web Tokens (JWTs) can be verified just with cryptography ◦ A JWT token stores data inside it, such as a username or id ◦ When the token is generated, a cryptographic signature is added to it ◦ Signature can only be generated or verified if you have a secret key ◦ The data in a token can be trusted only if the token has a valid signature ◦ Not everything is great with JWTs: token revocations become harder • Since tokens are opaque, switching to JWT is not a breaking change • Beware of JWT exploits: always set and check signing algorithm
/ None Client HTML page GET /static/app.js None Main client application code GET /static/*.js None Client application code GET /static/*.css None Client application stylesheets
Ordinary Flask app that serves the index HTML page plus all the JavaScript and CSS files that make up the client application ◦ To ease the transition, at this stage we’ll use an older version of the UI that does not use Socket.IO (we’ll add Socket.IO later) • .env ◦ Environment variables ◦ This file should not be added to source control, as it can contain secrets • tests.py, tox.ini ◦ Unit tests, code coverage and linting • Dockerfile, boot.sh, build.sh ◦ Docker support
VM) • mfkill all (reset your VM to an initial state without any services) ◦ Watch the load balancer at http://192.168.33.10/stats • cd ~/microflack_ui • git checkout 1 (get version 1 of the UI service) • ./build.sh (build the service) • mfrun ui (run the service) • Connect to the application at http://192.168.33.10 ◦ Browser errors are expected, as no other services are yet running
simple tree structure (use etcd-dump to see it) • You can register the Flack monolith with the load balancer in the VM: ◦ curl -X PUT $ETCD/v2/keys/services/monolith/location -d value="/api" ◦ curl -X PUT $ETCD/v2/keys/services/monolith/upstream/server -d value="10.0.2.2:5000" ◦ Note: 10.0.2.2 is the IP address the host machine has inside a vagrant VM • Now the UI is served by the new microservice, while everything else comes from the old Flack+Celery application • To remove: ◦ curl -X DELETE $ETCD/v2/keys/services/monolith?recursive=true
Endpoint Authentication Description POST /api/users None Register a new user GET /api/users Token Optional Get list of users GET /api/users/:id Token Optional Get user by id PUT /api/users/:id Token Modify user by id GET /api/users/me Basic Authenticate user
microservice • Includes User model and all /api/users endpoints from original Flack • Token authentication imported from microflack_common • Ported existing unit tests and used them as a guide to fix everything up • Add database migration support (Flask-Migrate) ◦ Databases are created by mfrun if they don’t exist yet ◦ Migrations are executed in the container startup script • Add new /api/users/me endpoint to validate username and password and return user information
1 (select version 1 of the service) • ./build.sh (build the service) • mfrun users (run the service) ◦ The /api/users family of endpoints should now be working!
monolithic app: /api/tokens • Authentication is relayed to the users service /me endpoint • Generated JWT token contains the numeric user id • No token revocations for now
/api/messages Token Post a new message GET /api/messages Token Optional Get list of messages GET /api/messages/:id Token Optional Get message by id PUT /api/messages/:id Token Modify message by id
• Models and endpoints copied from original Flack code • Removed all asynchronous functions for now ◦ We want a basic app up and running from which we can build on • Ported unit tests to verify the code works
1 (select version 1 of the service) • ./build.sh (build the service) • mfrun messages (run the service) • The application should be fully functional (though not very performant yet)
for asynchronous message rendering ◦ Unfortunately, Celery workers are by design tightly coupled with the caller process • Instead of Celery, we will use background threads for rendering ◦ Our render task is not CPU intensive, so this works very well ◦ For CPU intensive tasks, the multiprocessing module can be used instead ◦ If a very high volume of tasks must be supported, an asynchronous server can be used
◦ cd microflack_admin; source mfvars; cd .. ◦ git clone https://github.com/miguelgrinberg/microflack_common ◦ cd microflack_common ◦ ./mkwheel all ◦ cd ..
code for the desired microservice: ◦ cd microflack_admin; source mfvars; cd .. ◦ git clone https://github.com/miguelgrinberg/microflack_messages ◦ cd microflack_messages ◦ python3 -m venv venv ◦ source venv/bin/activate ◦ pip install -r requirements.txt ◦ flask run • Test by sending requests with curl, httpie, postman, etc. • For integration testing with an actual system running in a VM: ◦ Create .env file (run mfenv inside VM to get the variables you need) ◦ mfdev start messages ◦ flask run
2 (select version 2 of the service) • ./build.sh (build the service) • mfupgrade try messages (start upgrade) ◦ After watching the log for a few seconds, hit Ctrl-C • mfupgrade roll (rolling upgrade)
Endpoint Authentication Description POST /api/tokens Basic Request a token GET /api/tokens Token Check if a token is revoked DELETE /api/tokens Token Revoke a token
revoked tokens ◦ The best place to implement this is the tokens service ◦ Revoked tokens need to be kept in a list only until they expire ◦ We can keep the list in etcd, and write all entries with the appropriate expiration • Services need to check tokens against that list ◦ We can encapsulate this inside the verify_token function in microflack_common ◦ Option 1 (more correct): send a request to the tokens service to check revocation status ◦ Option 2 (more performant): check the list in etcd directly ◦ Improvement for both options: cache calls to verify_token
2 (select version 2 of the service) • ./build.sh (build the service) • mfupgrade roll tokens (rolling upgrade, skipping the “try” step) • Upgrade the services that work with tokens: ◦ users to version 2 ◦ messages to version 3
Socket.IO server to client events (new in red) Event Authentication Description ping_user Token Mark a user as online post_message Token Post a message disconnect Token (from session) Mark the user as offline Event Description updated_model Render updated user or message expired_token Ask user to log in again
service ◦ Implement “ping_user”, “post_message” and “disconnect” events ◦ Push “expired_token” notifications to clients when appropriate • Task list for the common package ◦ Add support for setting sticky sessions in the load balancer • Task list for the UI service ◦ Add Socket.IO support ◦ Handle expired tokens in Socket.IO calls (bug in old version) • Task list for users service ◦ Add “ping” and “user offline” endpoints ◦ Push “updated_model” notifications to message queue • Task list for messages service ◦ Push “updated_model” notifications to message queue
• No HTTP endpoints, only the three Socket.IO events • Needs to be an async service due to the long term WebSocket connections ◦ Don’ t understand why? Come to my talk “Asynchronous Python” on Sunday! ◦ We have several options ▪ python-socketio supports WSGI-compatible async frameworks (eventlet, gevent) and also asyncio ▪ Flask-SocketIO builds on python-socketio, but drops asyncio support ◦ While we don’t need Flask for this service, having access to Flask’s user session is handy ◦ We’ll go with Flask-SocketIO and eventlet for this service
Endpoint Authentication Description POST /api/users None Register a new user GET /api/users Token Optional Get list of users GET /api/users/:id Token Optional Get user by id PUT /api/users/:id Token Modify user by id GET /api/users/me Basic Authenticate user PUT /api/users/me Token Set user online DELETE /api/users/me Token Set user offline
1 (select version 1 of the service) • ./build.sh (build the service) • mfrun socketio (run the service) • Upgrade the services that work with Socket.IO (order is important!): ◦ users to version 3 ◦ messages to version 4 ◦ ui to version 2
cluster of nodes (container hosts) transparently • Works with Docker images • Has its own service registry and load balancer • Gives each service a DNS name (i.e. http://users connects to the Users service) • Stores secrets securely • Handles service replication, and does rolling upgrades • microflack_admin includes example Kubernetes deployment scripts in install/kubernetes
EC2 instances • Access to the AWS ecosystem • MicroFlack platform and application containers can run without change • Some effort required in configuring roles and security groups (as with everything done on AWS)
only the application logic is uploaded to AWS ◦ No need for gunicorn, just the application code that handles the endpoints ◦ Tools like Zappa (or my own Slam) enable transparent support for WSGI apps • AWS Lambda provides automatic load balancing and auto-scaling • Access to the AWS ecosystem • Cons: ◦ No WebSocket support, since there is no server running all the time ◦ Response times are not great
Docker is possible • All the core components of the platform can be installed without Docker: ◦ etcd, haproxy, confd, mysql, redis • The MicroFlack application services can run as regular gunicorn processes ◦ But a network port assignment strategy needs to be implemented
revoke all tokens for everybody • Use multiple chat rooms instead of just one (this will require some client-side work as well) • Protect the /stats and /logs endpoints with authentication • Add SSL termination to (or in front of) the load balancer • Deploy the ELK stack and configure the logspout container to forward logs to it • Add a secrets store component (maybe HashiCorp’s Vault) • Create a multi-host deployment, possibly with redundant load balancers • Replace the single-node Redis deployment with a Redis or RabbitMQ cluster • Replace the single-node MySQL with a Galera cluster • Replace MySQL with NoSQL databases of your choice • With all services running 3+ instances, create a “chaos monkey” script • Implement a platform service that recycles application services that die or are unresponsive, and maybe even auto-scales them based on load
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}