Short answer, it depends -- depends on the definition of "Intro Stats" and "Data Science". In this talk we discuss different approaches to introduction to statistics and data science how these approaches can fit into broader curricula. We will give examples from a new data science course offered at Duke University serving as both gateway to the statistics major as well as an introduction to quantitative reasoning for all students. We will discuss decisions that went into designing the course curriculum, emphasizing departures from and similarities to a more traditional introduction to statistics.
![mine-cetinkaya-rundel [email protected] @minebocek Intro Do we need both? Data Science](https://files.speakerdeck.com/presentations/f4ce413f765f4225a5113f1e8b0b9684/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
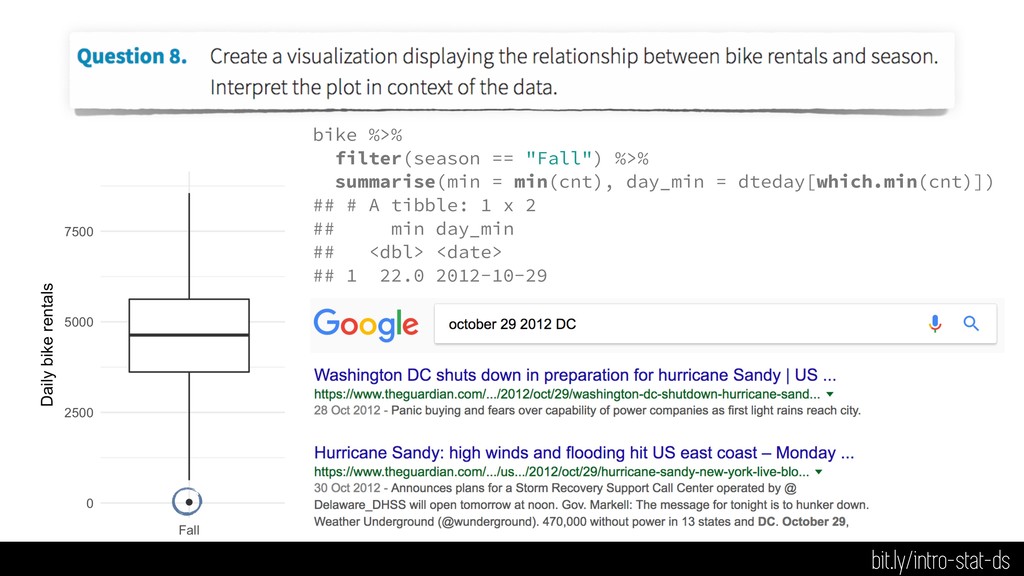{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![mine-cetinkaya-rundel [email protected] @minebocek Intro Do we need both? Data Science](https://files.speakerdeck.com/presentations/f4ce413f765f4225a5113f1e8b0b9684/slide_35.jpg){kind=link}