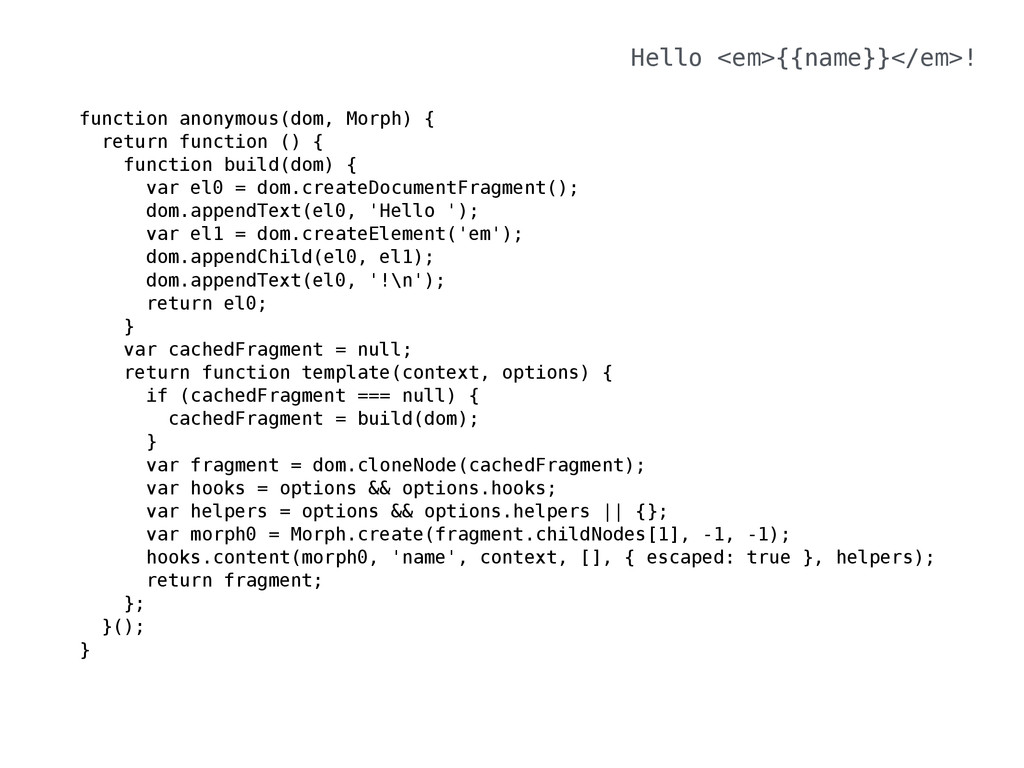
= function () { function build(dom) { var el0 = dom.createDocumentFragment( dom.appendText(el0, '\n Hello '); var el1 = dom.createElement('em'); dom.appendChild(el0, el1); dom.appendText(el0, '!\n'); return el0; } var cachedFragment = null; return function template(context, optio if (cachedFragment === null) { cachedFragment = build(dom); } var fragment = dom.cloneNode(cachedFr var hooks = options && options.hooks; var helpers = options && options.help var morph0 = Morph.create(fragment.ch hooks.content(morph0, 'name', context return fragment; }; }(); function build(dom) { var el0 = dom.createDocumentFragment(); dom.appendText(el0, ''); dom.appendText(el0, ''); return el0; } var cachedFragment = null; return function template(context, options) if (cachedFragment === null) { cachedFragment = build(dom); } var fragment = dom.cloneNode(cachedFragme var hooks = options && options.hooks; var helpers = options && options.helpers var morph0 = Morph.create(fragment, 0, 1) hooks.content(morph0, 'each', context, [' types: ['id'], hashTypes: {}, hash: {}, render: child0, escaped: true, data: typeof options !== 'undefined' && }, helpers); return fragment; }; }(); } function build(dom) { var el0 = dom.createDocumentFragment(); dom.appendText(el0, ''); dom.appendText(el0, ''); return el0; } var cachedFragment = null; return function template(context, options) { if (cachedFragment === null) { cachedFragment = build(dom); } var fragment = dom.cloneNode(cachedFragment); var hooks = options && options.hooks; var helpers = options && options.helpers || {}; var morph0 = Morph.create(fragment, 0, 1); hooks.content(morph0, 'each', context, ['people'], { types: ['id'], hashTypes: {}, hash: {}, render: child0, escaped: true, data: typeof options !== 'undefined' && options.data }, helpers); return fragment; }; }(); } dom.appendChild(el0, el1); dom.appendText(el0, '!\n'); return el0; } var cachedFragment = null; return function template(context, options) { if (cachedFragment === null) { cachedFragment = build(dom); } var fragment = dom.cloneNode(cachedFragment); var hooks = options && options.hooks; var helpers = options && options.helpers || {}; var morph0 = Morph.create(fragment.childNodes[1], -1, -1); hooks.content(morph0, 'name', context, [], { escaped: true } helpers); return fragment; }; }(); function build(dom) { var el0 = dom.createDocumentFragment(); dom.appendText(el0, ''); dom.appendText(el0, ''); return el0; } var cachedFragment = null; return function template(context, options) { if (cachedFragment === null) { cachedFragment = build(dom); dom.appendChild(el0, el1); dom.appendText(el0, '!\n'); return el0; } var cachedFragment = null; return function template(context, optio if (cachedFragment === null) { cachedFragment = build(dom); } var fragment = dom.cloneNode(cachedFr var hooks = options && options.hooks; var helpers = options && options.help var morph0 = Morph.create(fragment.ch hooks.content(morph0, 'name', context helpers); return fragment; }; }(); function build(dom) { var el0 = dom.createDocumentFragment(); dom.appendText(el0, ''); dom.appendText(el0, ''); return el0; } var hooks = options && options.hooks; var helpers = options && options.helpers || {}; var morph0 = Morph.create(fragment.childNodes[1], -1, -1); hooks.content(morph0, 'name', context, [], { escaped: true }, helpers); return fragment; }; }(); function build(dom) { var el0 = dom.createDocumentFragment(); dom.appendText(el0, ''); dom.appendText(el0, ''); return el0; } var cachedFragment = null; return function template(context, options
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Some of this stuff will change.]](https://files.speakerdeck.com/presentations/15f019e0cfb70131885232e863702d26/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![export function lookupHelper(name, context, options) { return options.helpers[name]; } lookupHelper](https://files.speakerdeck.com/presentations/15f019e0cfb70131885232e863702d26/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Sorry about all the code.]](https://files.speakerdeck.com/presentations/15f019e0cfb70131885232e863702d26/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![hooks.element(fragment, 'action', context, ['hi'], { types: ['string'], hashTypes: {}, hash:](https://files.speakerdeck.com/presentations/15f019e0cfb70131885232e863702d26/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}