Presented in the Education Exhibit at RSNA 2025.
If you refer to the contents in this slide, please show this citation information:
Masahiro Oda, Hirotsugu Takabatake, Masaki Mori, Hiroshi Natori, Kensaku Mori, ``What Is Vision Foundation Model and How It Used to Develop CAD,'' RSNA2025, PHEE-17, McCormick Place, Chicago (conference: 2025/11/30-12/04)
{kind=link}
{kind=link}
{kind=link}
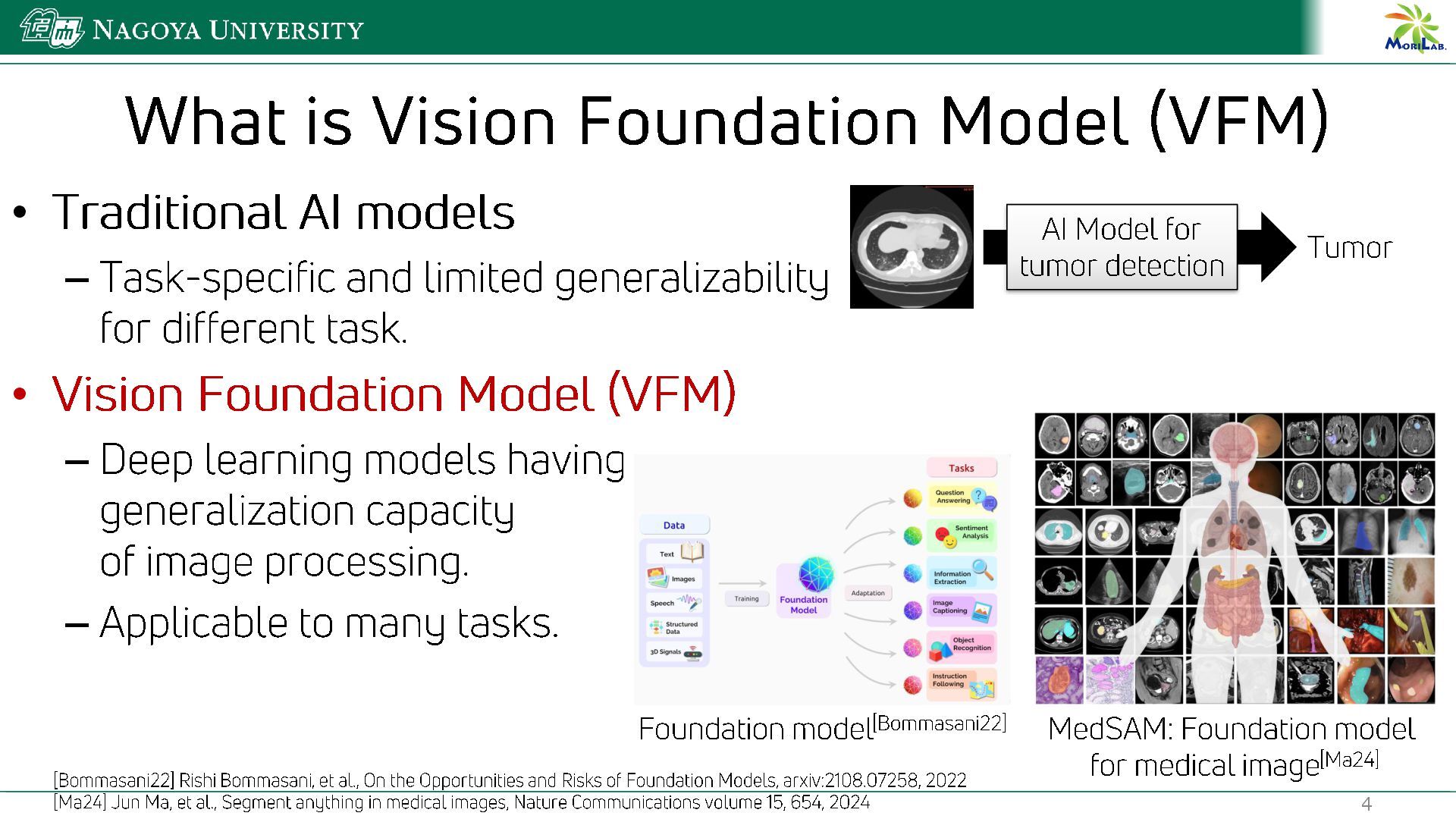{kind=link}
{kind=link}
{kind=link}
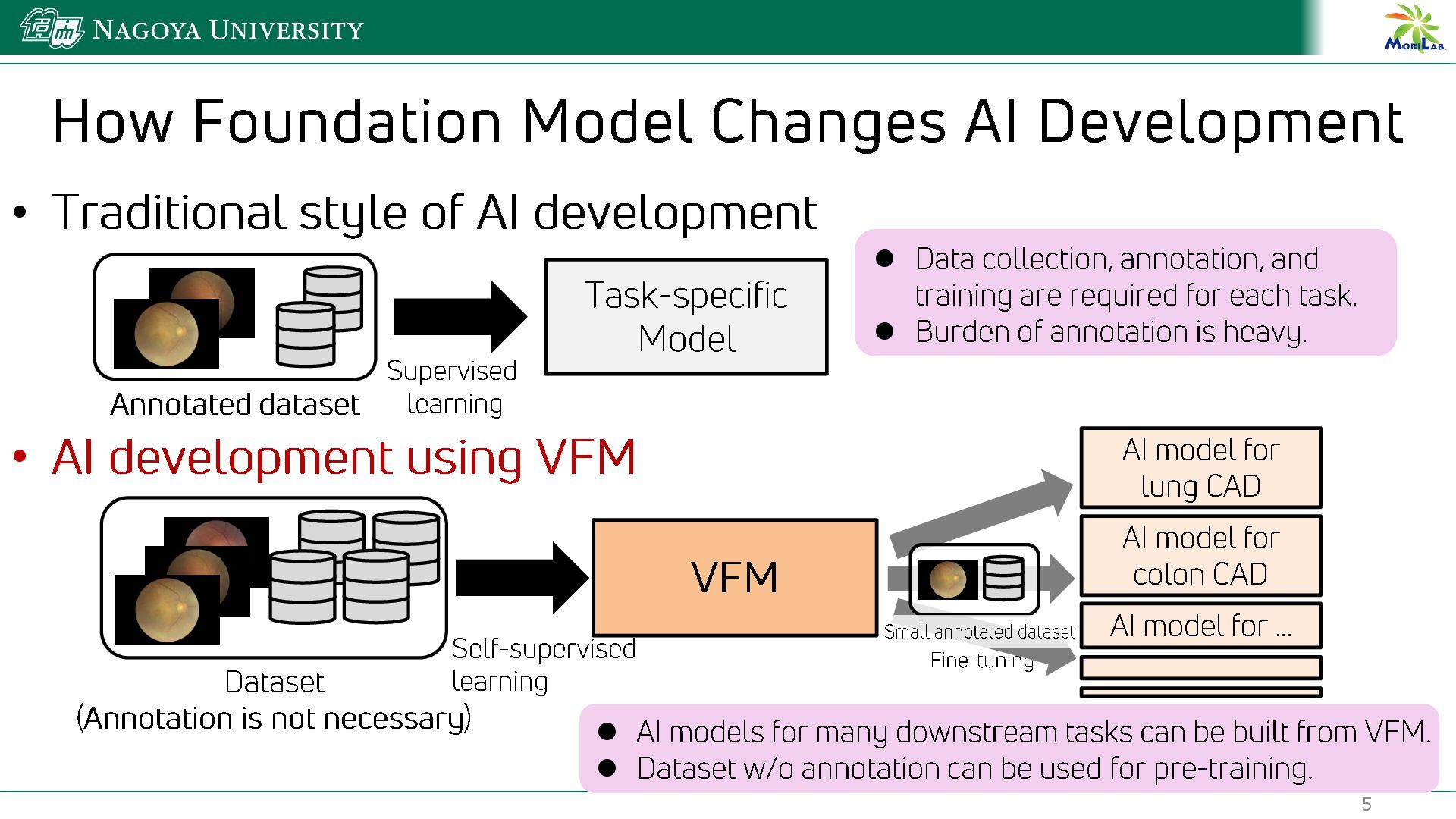
{kind=link}
![VFM for General Images: Segment Anything Model (SAM) [SAM] •](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_7.jpg){kind=link}
{kind=link}
![Medical VFMs for Multi -modal Image • MedSAM [Ma24] –](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_9.jpg){kind=link}
![Medical VFMs for Multi -modal Image • BiomedCLIP [Zhang24] –](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_10.jpg){kind=link}
![Medical VFMs for Single -modal Image • BioViL -T[Bannur23] –](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
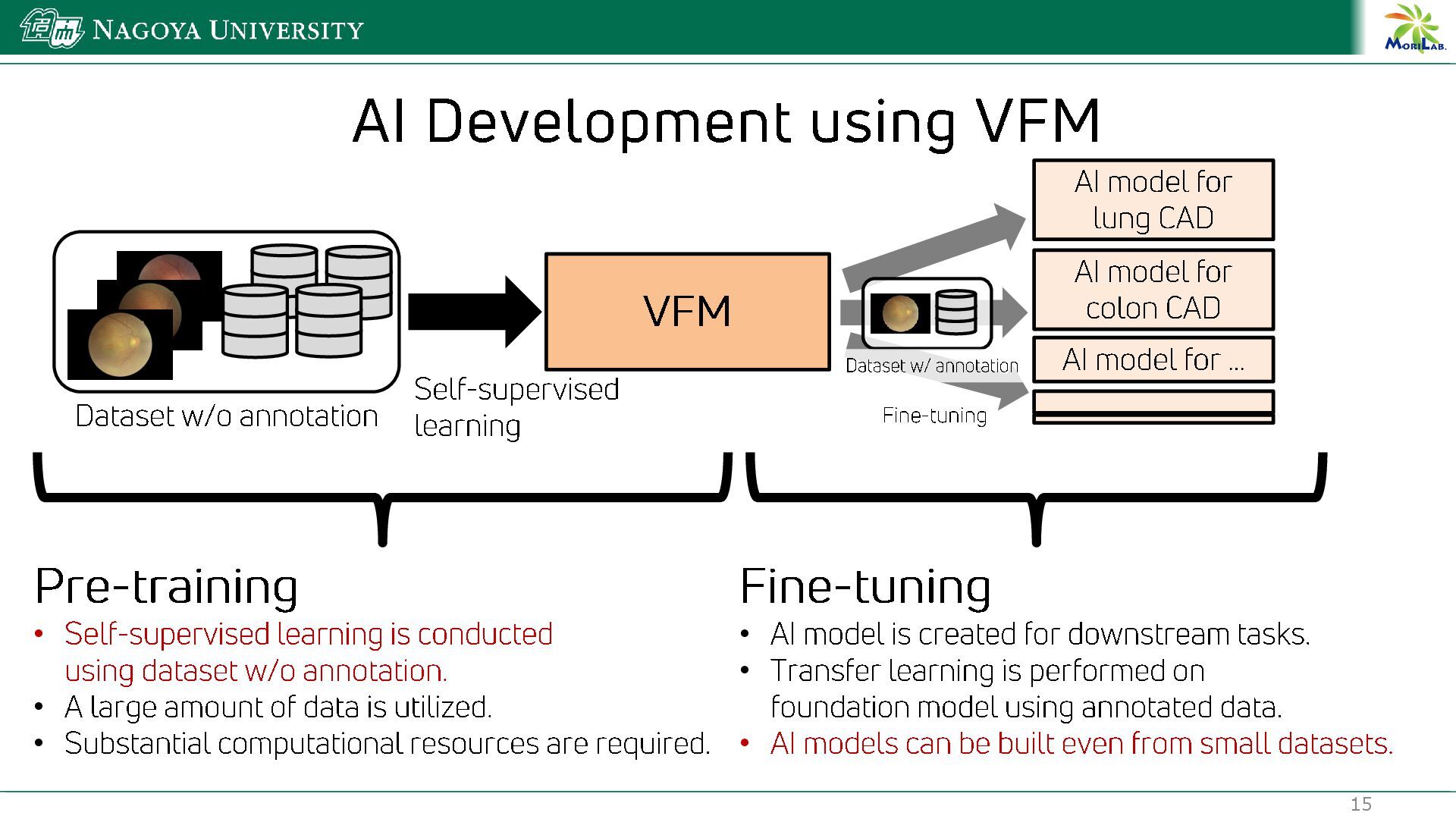{kind=link}
{kind=link}
{kind=link}
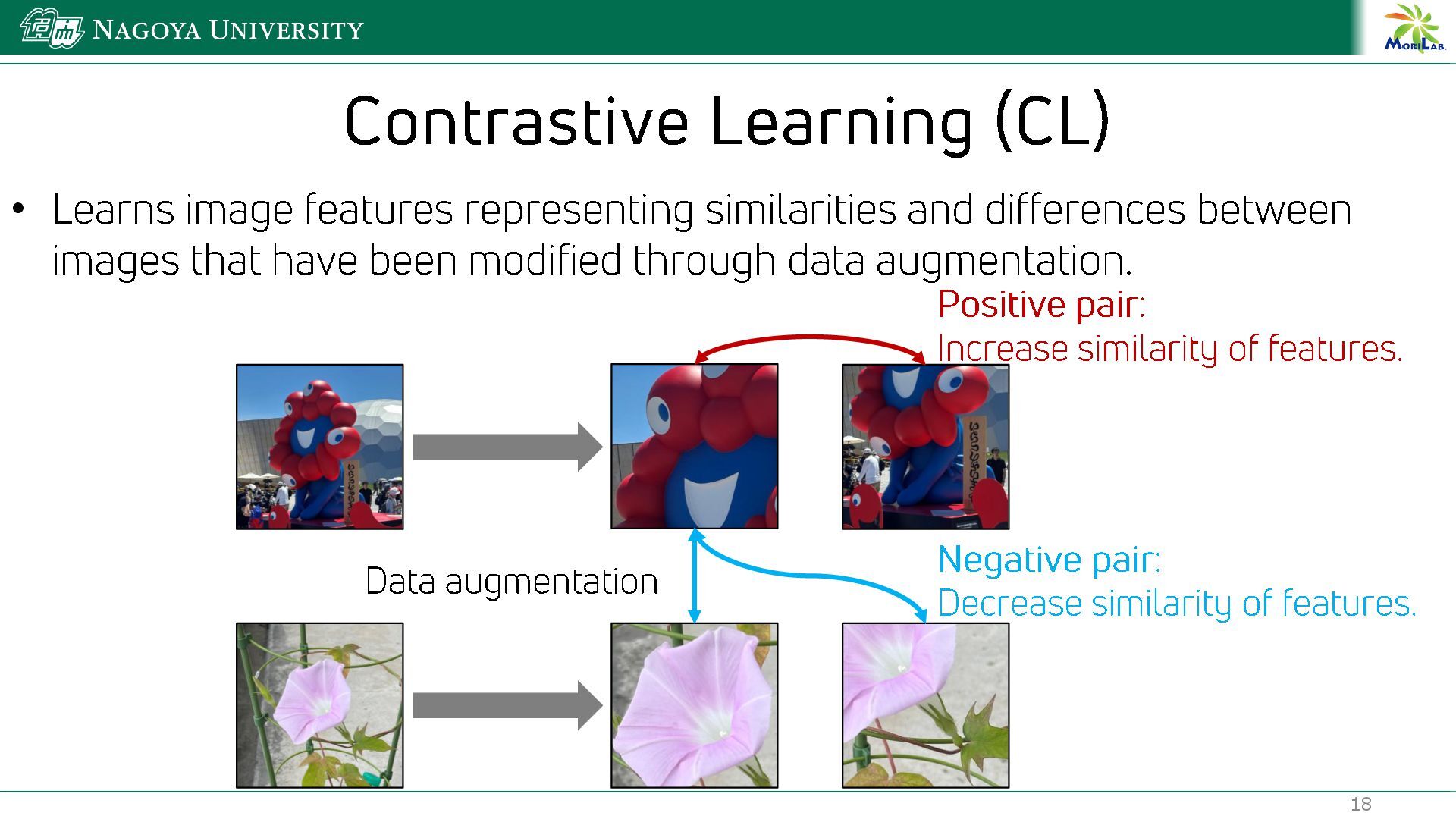{kind=link}
{kind=link}
![Example of CL: SimCLR [Chen20] • Images augmented through data](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_19.jpg){kind=link}
![CL: Relationship Between SimCLR Pre -training Settings and Performance [Chen20]](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_20.jpg){kind=link}
{kind=link}
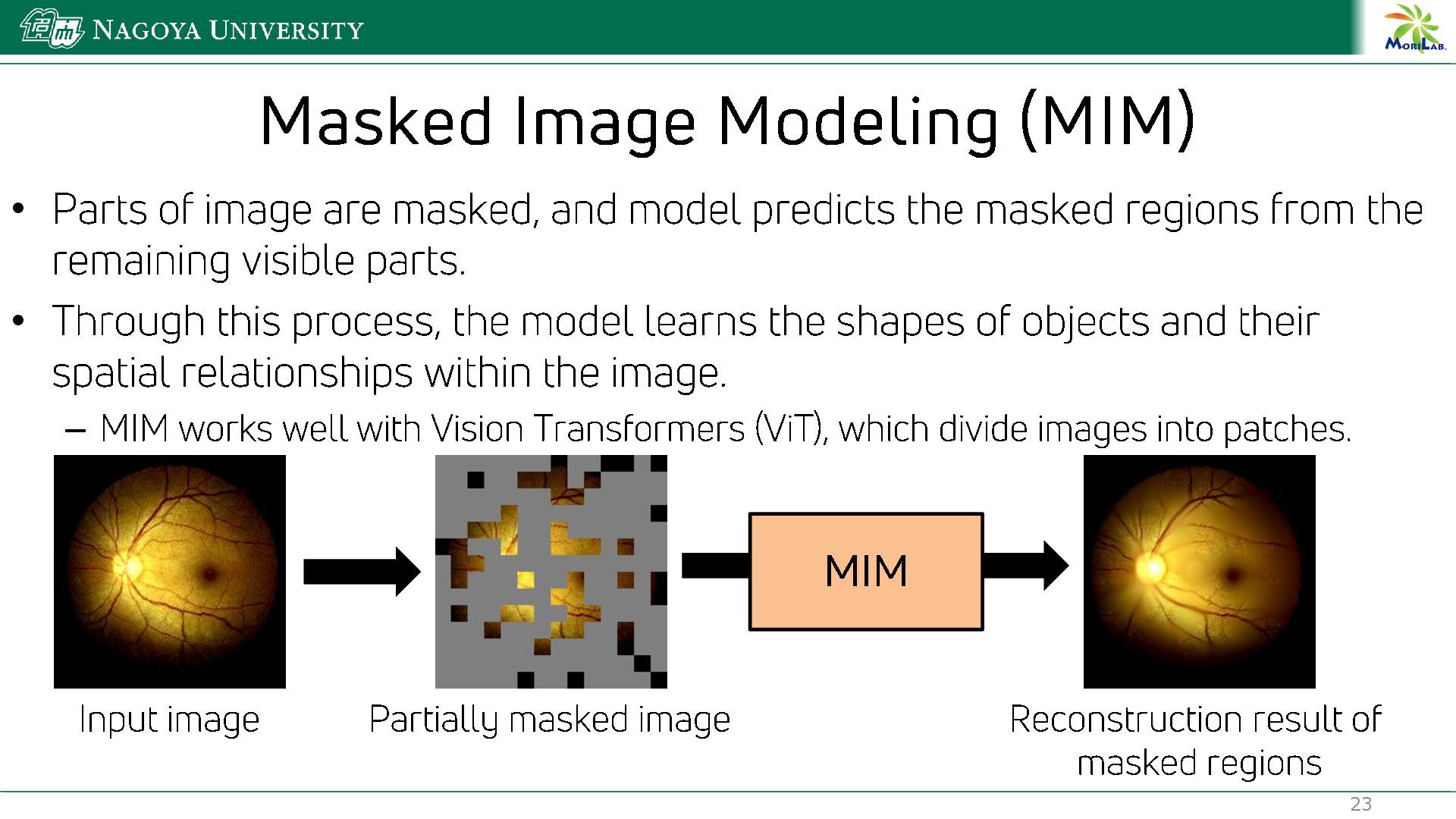{kind=link}
![Patch Division in Vision Transformer ( ViT )[Dosovitskiy21] • Image](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_23.jpg){kind=link}
![MIM: Masked Autoencoder (MAE) [He22] • Learning with encoder -decoder](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_24.jpg){kind=link}
![MIM: Relationship Between MAE Pre -training Settings and Performance [He22]](https://files.speakerdeck.com/presentations/cafd2567b7564ae99abc862ea3642147/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
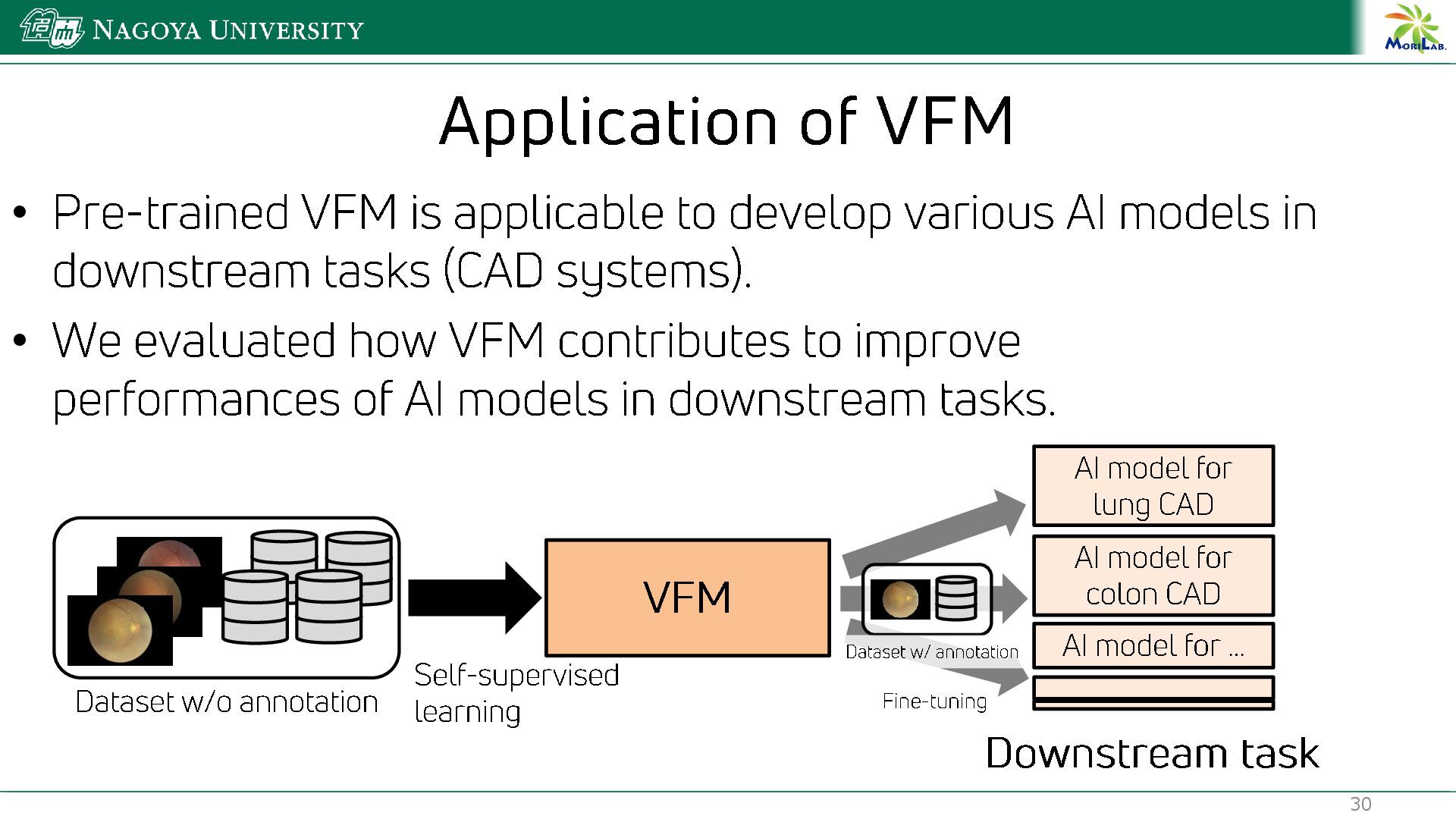{kind=link}
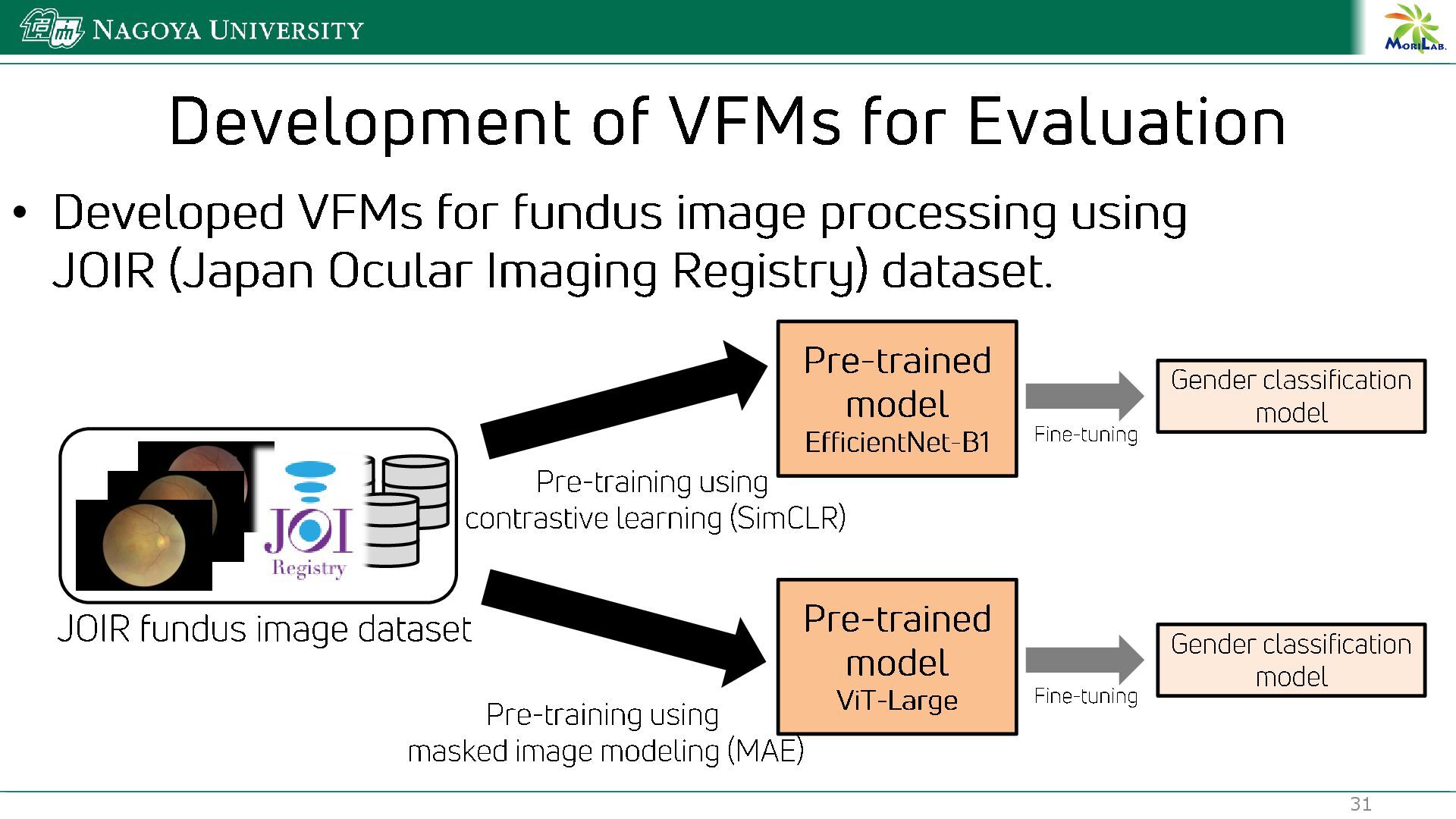{kind=link}
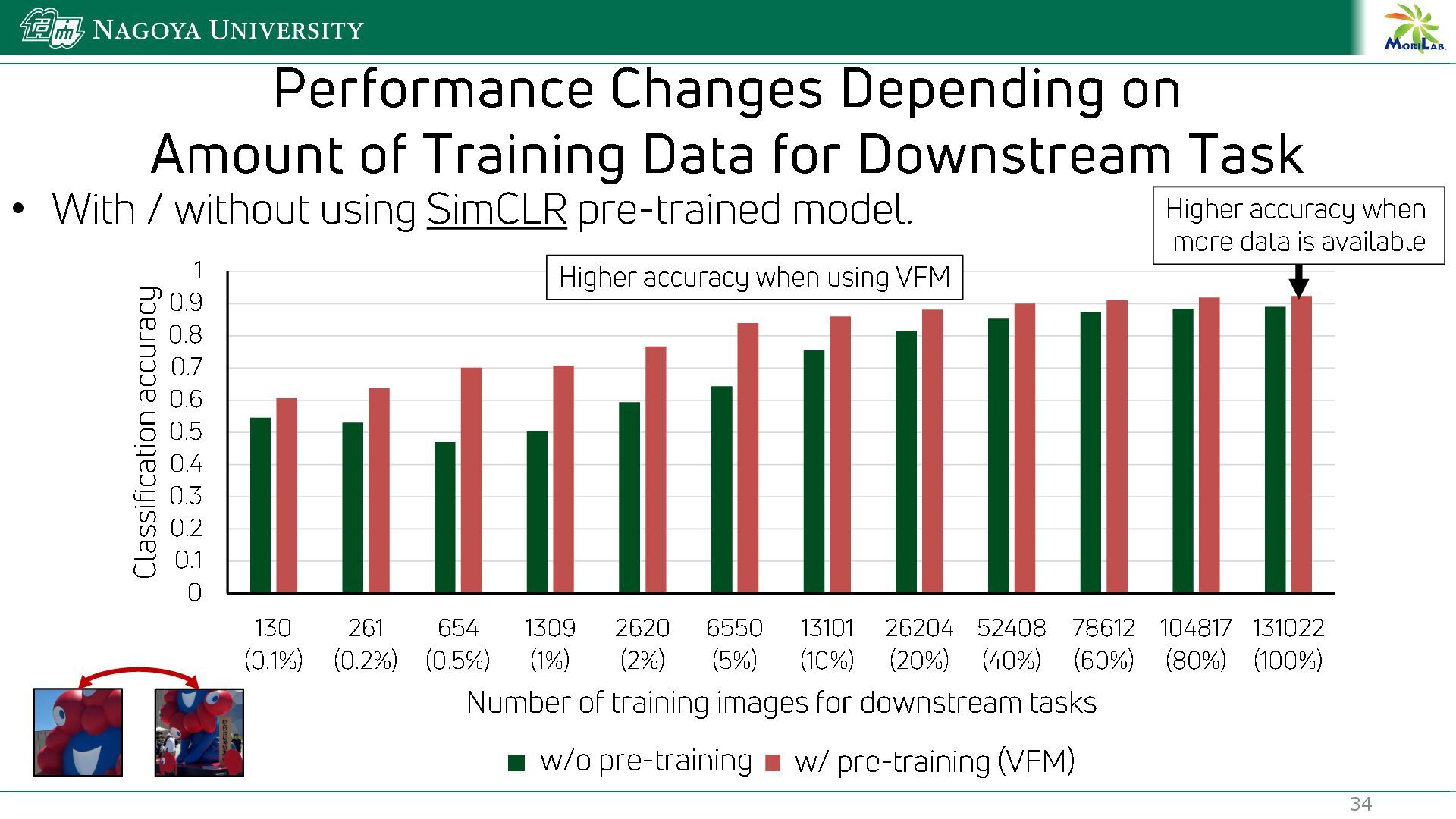
{kind=link}
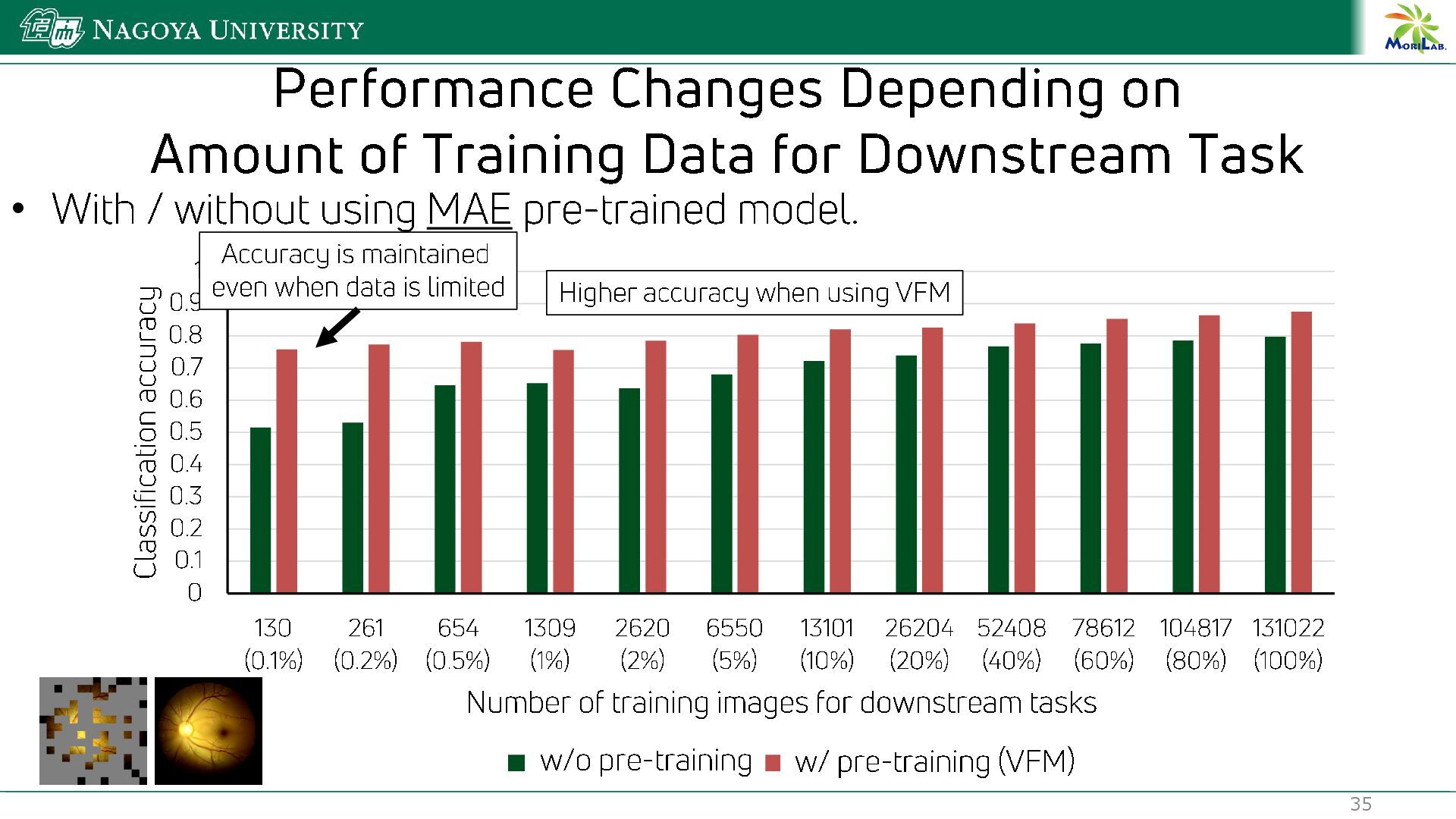
{kind=link}
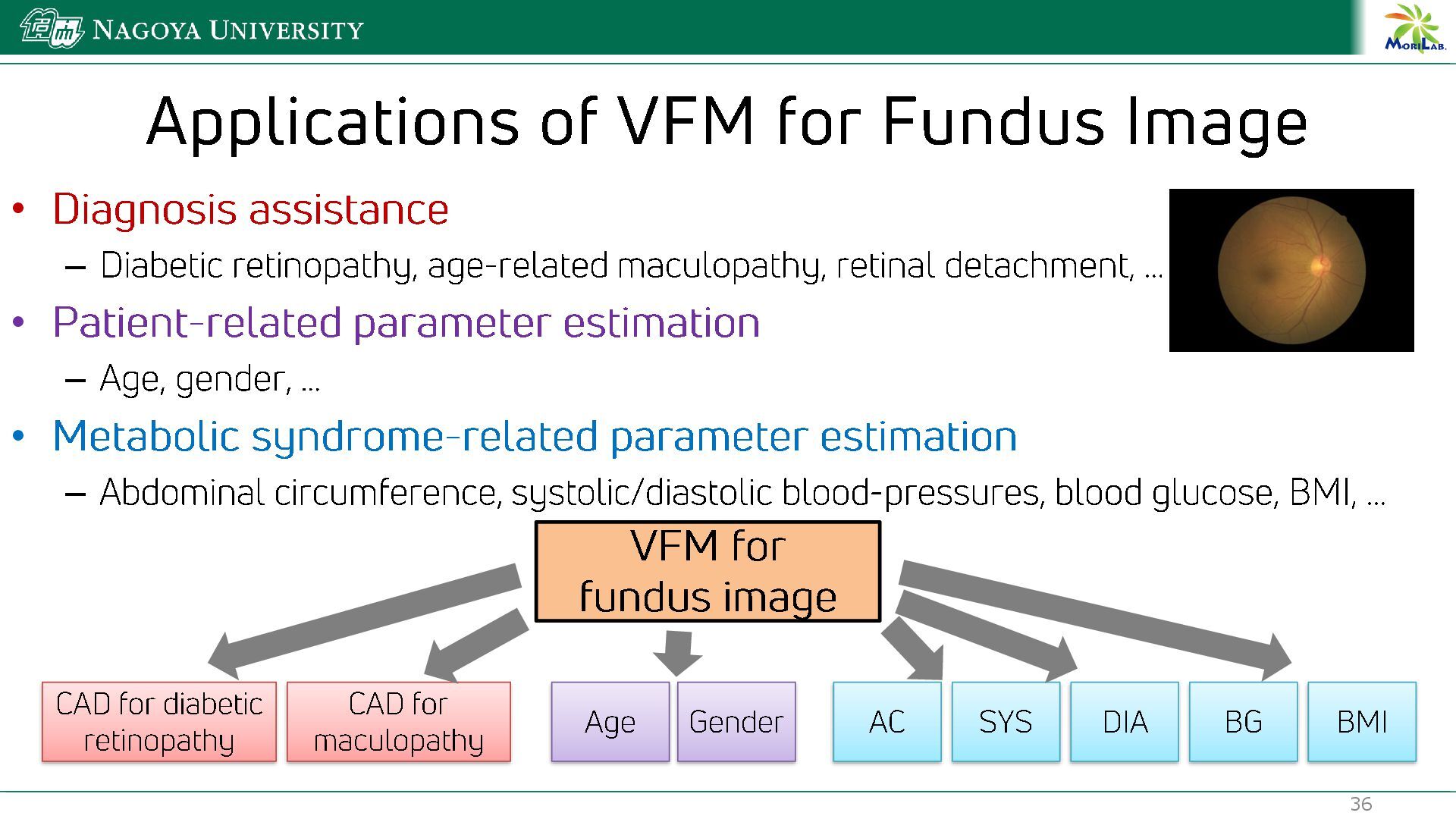
{kind=link}
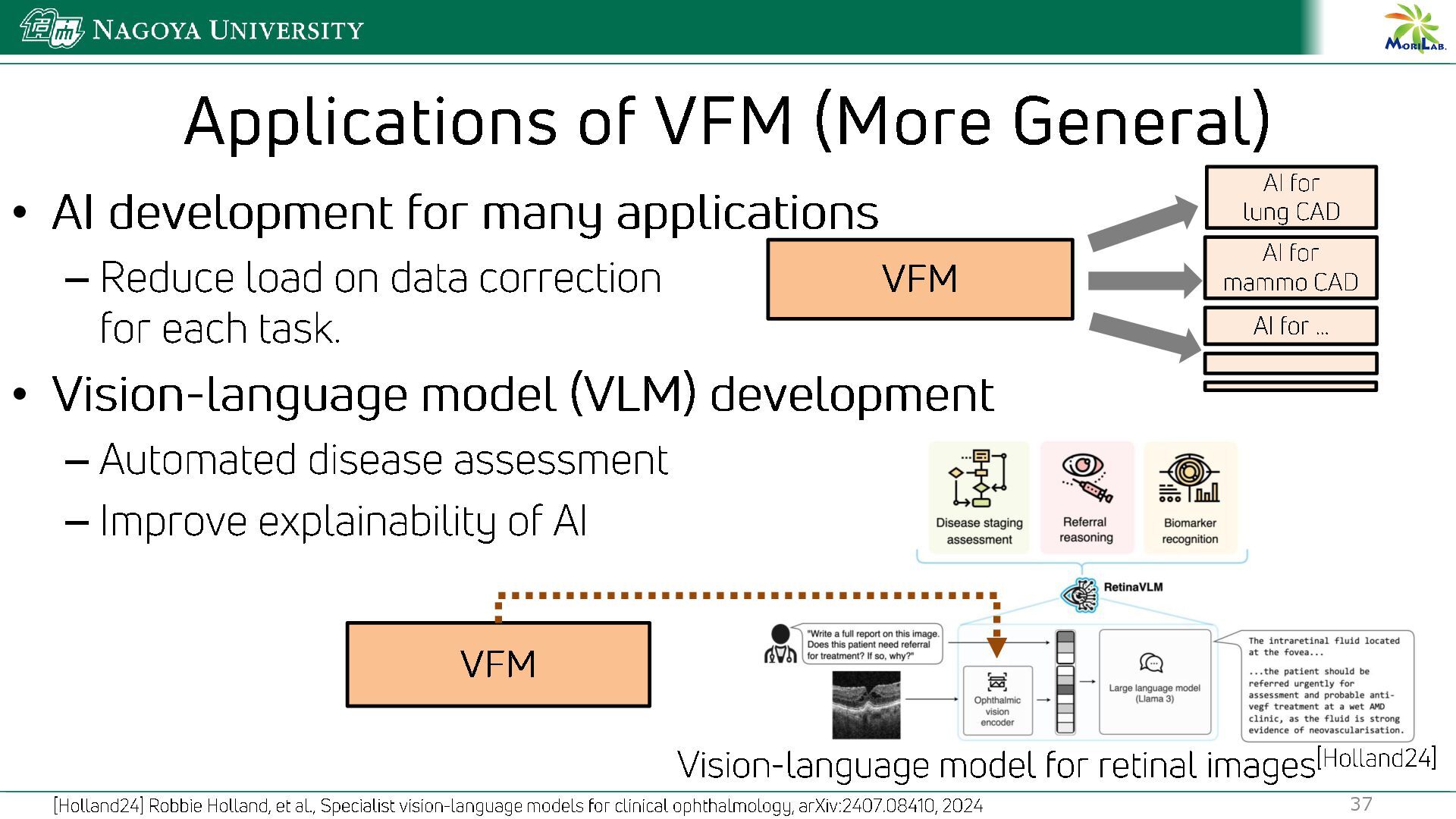
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}