Presented in the Education Exhibit at RSNA 2024.
If you refer to the contents in this slide, please show this citation information:
Masahiro Oda, Hirotsugu Takabatake, Masaki Mori, Hiroshi Natori, Kensaku Mori, ``How Image Generation AI and Multimodal AI Work and The Applications in CAD,'' RSNA2024, PHEE-4, McCormick Place, Chicago (conference: 2024/12/01-12/05)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
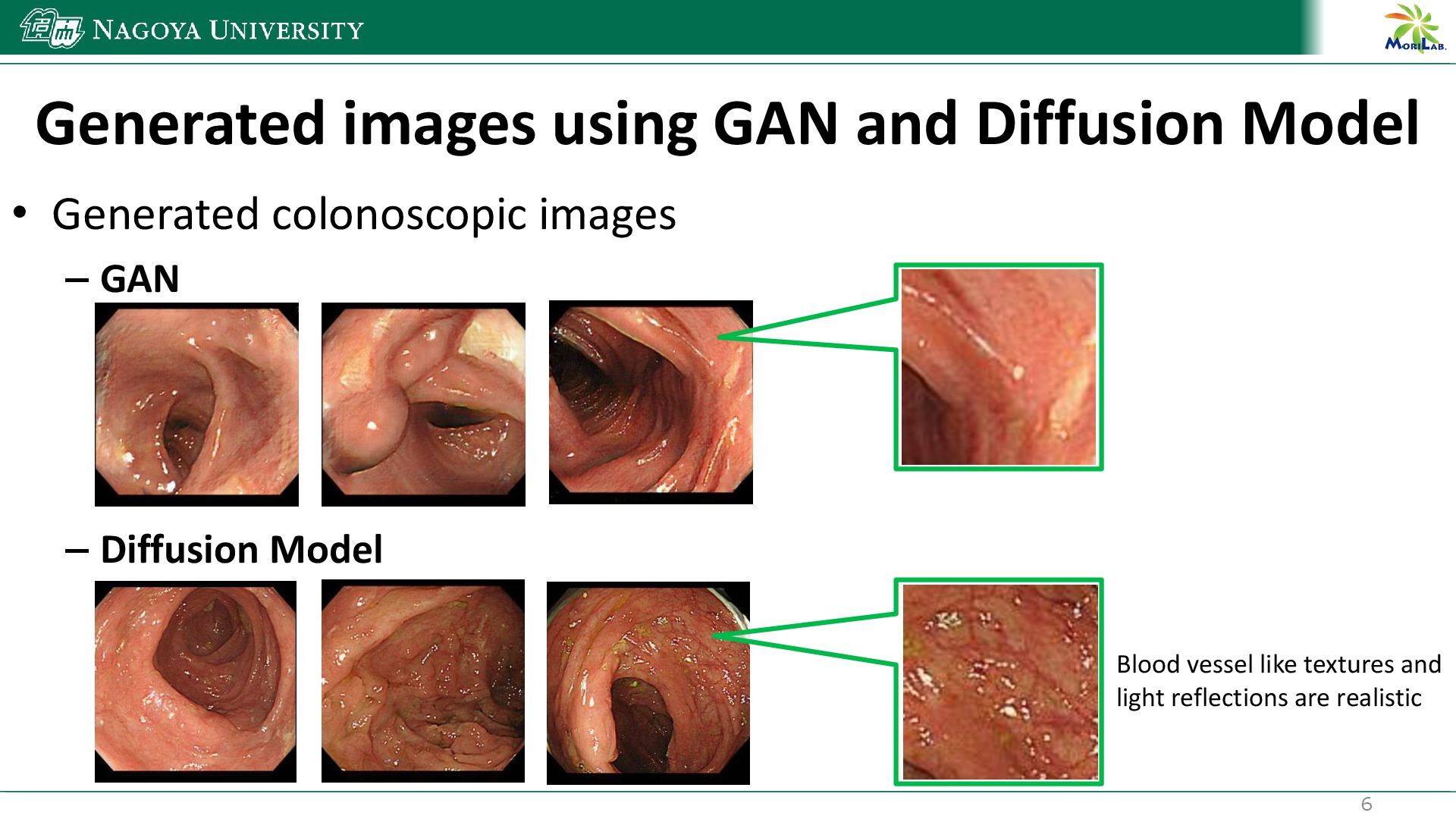{kind=link}
{kind=link}
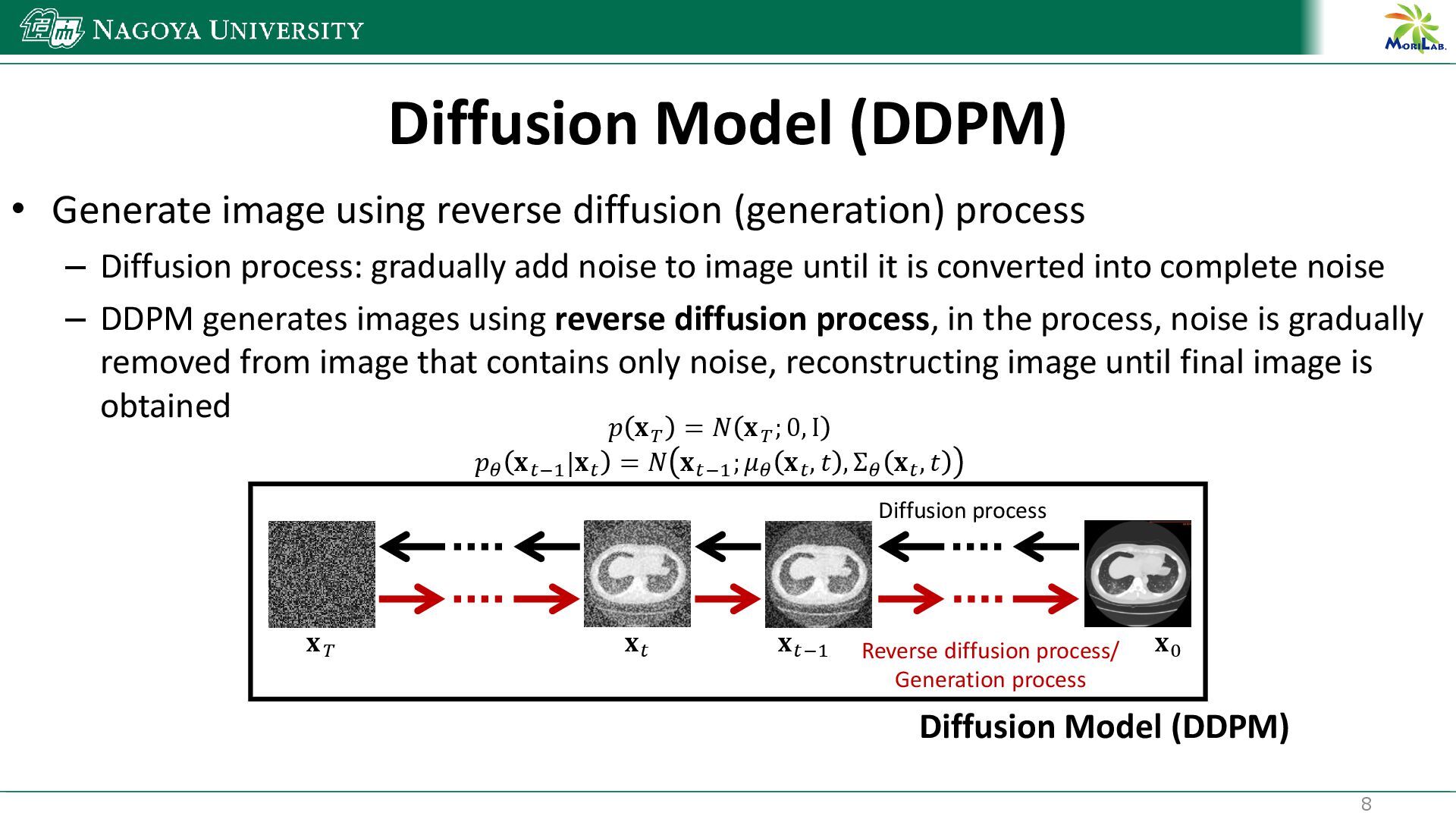{kind=link}
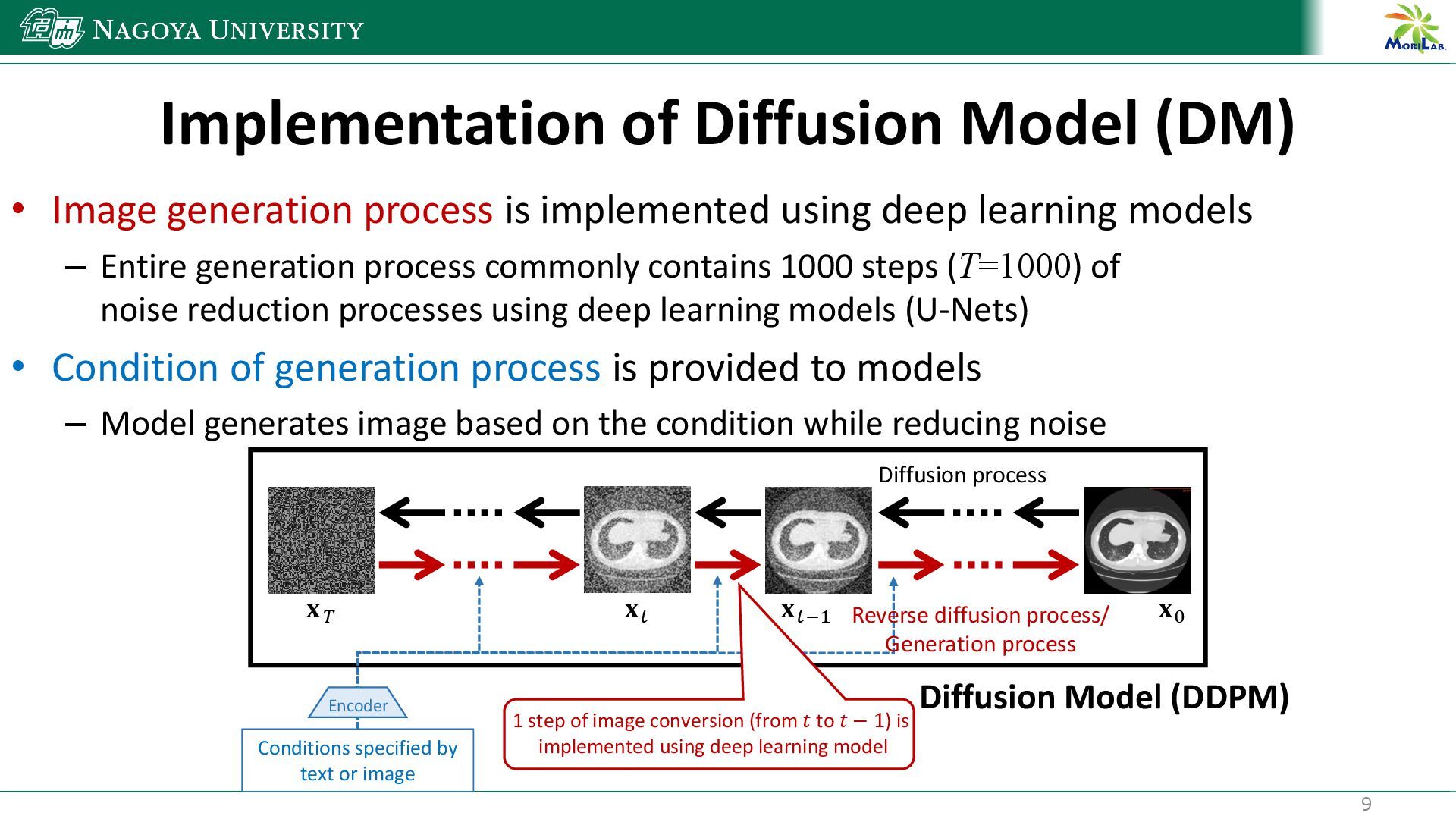{kind=link}
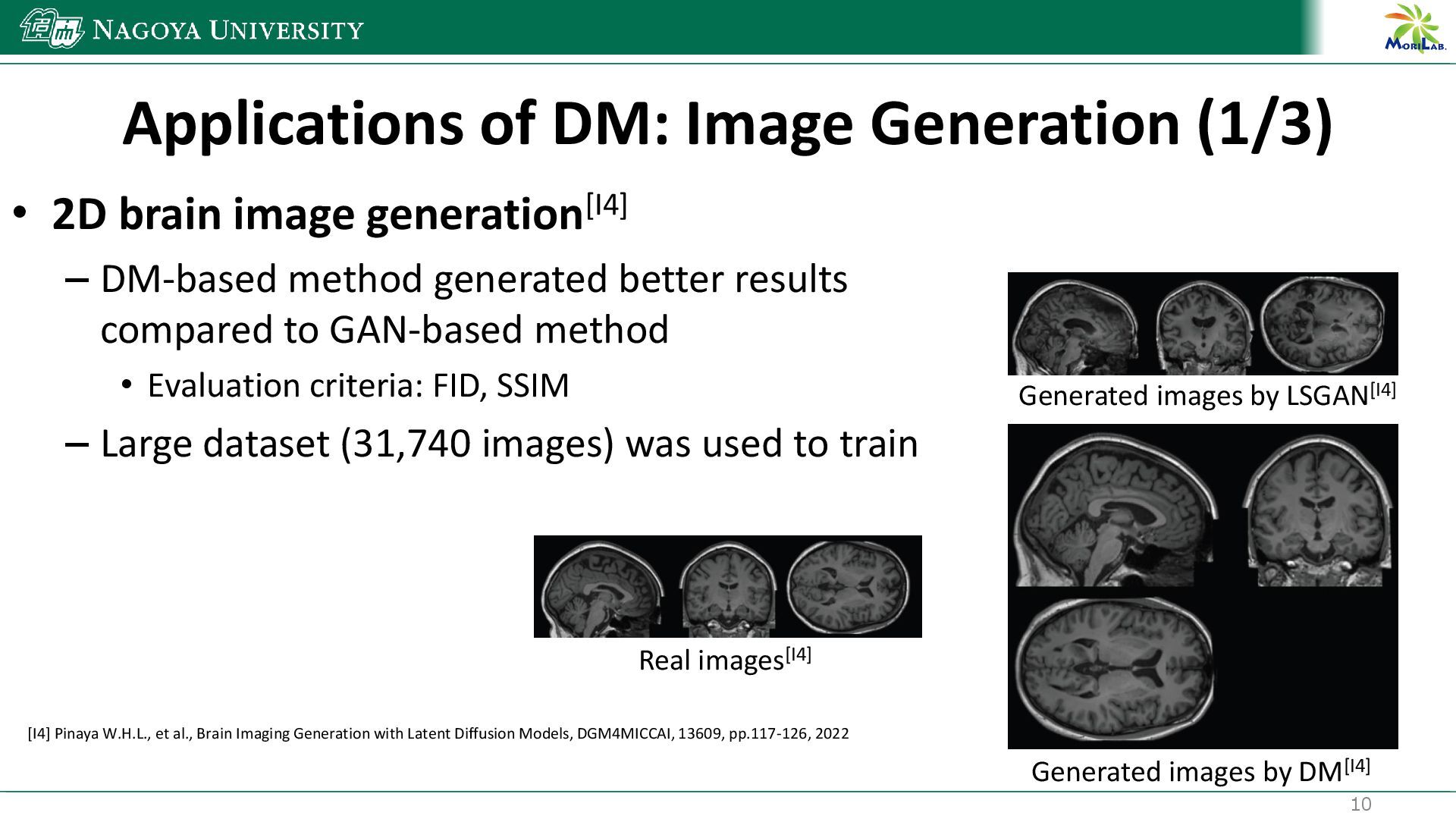{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Multimodal AI: DALL·E 2[M2] • Text encoder – CLIP[M3] is](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_18.jpg){kind=link}
![Multimodal AI: Stable Diffusion[M4] • Image generation – DM is](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_19.jpg){kind=link}
![Multimodal AI: Segment Anything Model (SAM)[M5] • Large model having](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_20.jpg){kind=link}
![Multimodal AI: Segment Anything Model 2 (SAM 2)[M6] • Model](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_21.jpg){kind=link}
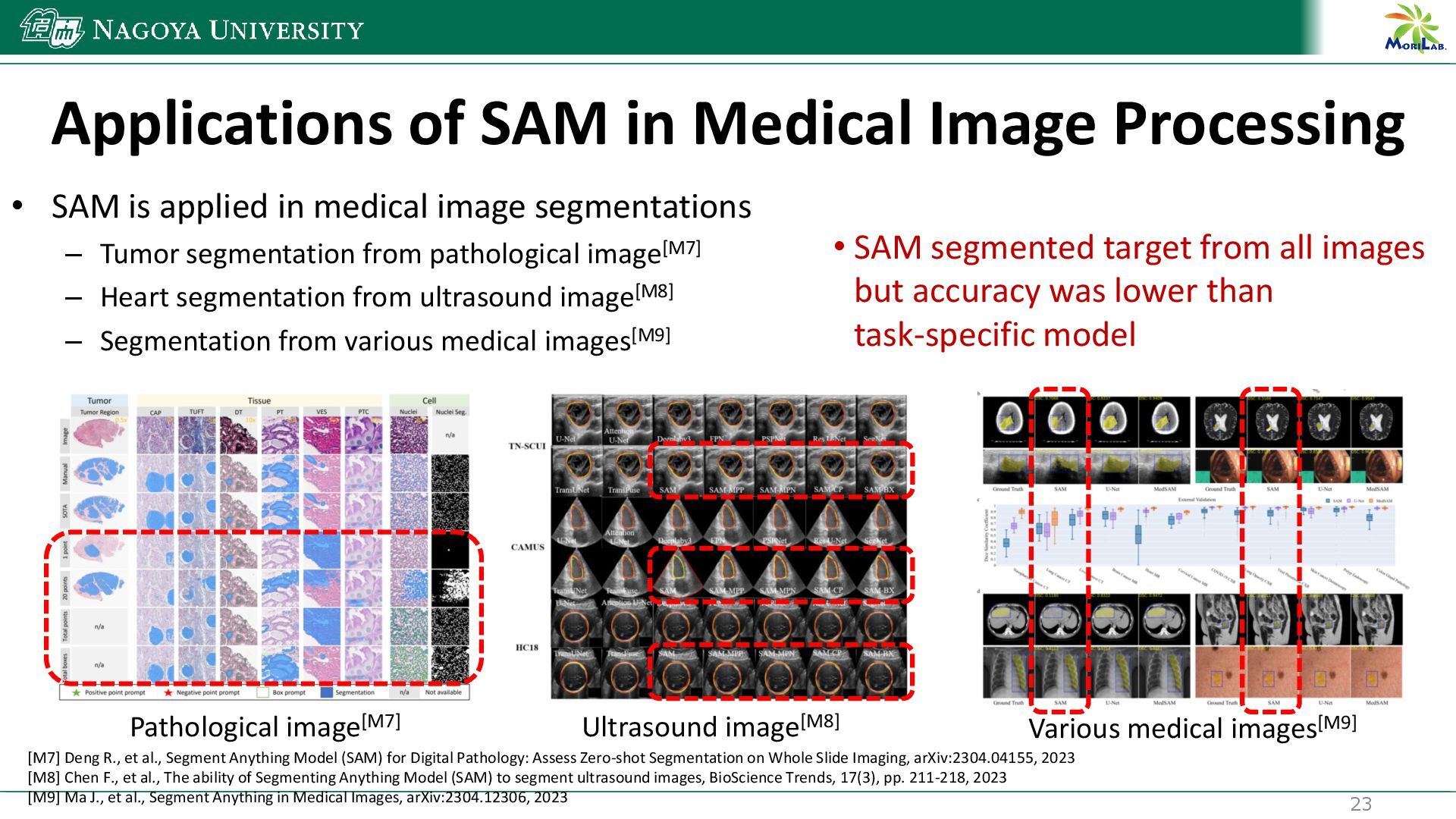{kind=link}
![Multimodal AI: Medical Image Multimodal AI • MedSAM[M10] – Developed](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_23.jpg){kind=link}
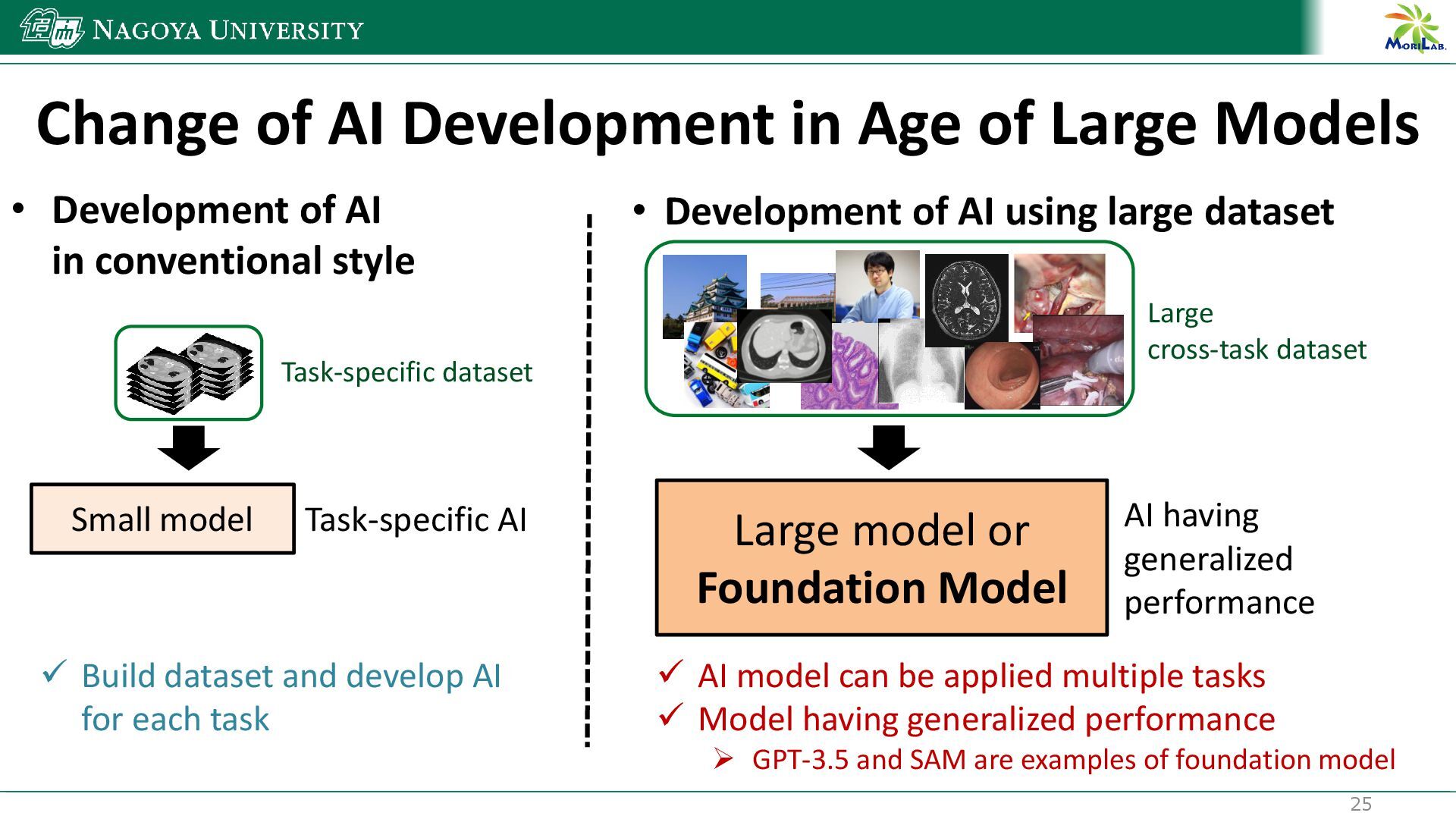{kind=link}
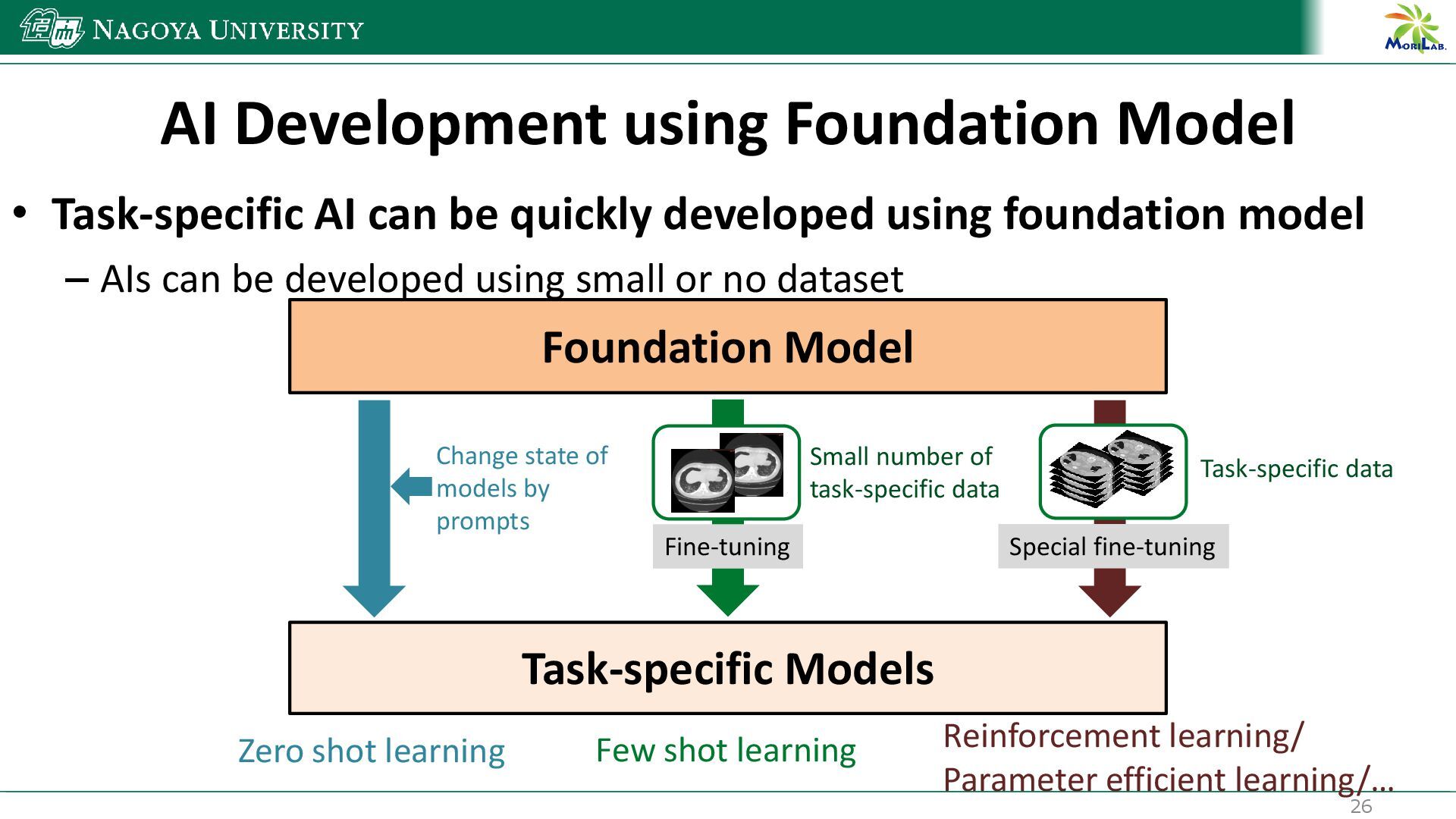{kind=link}
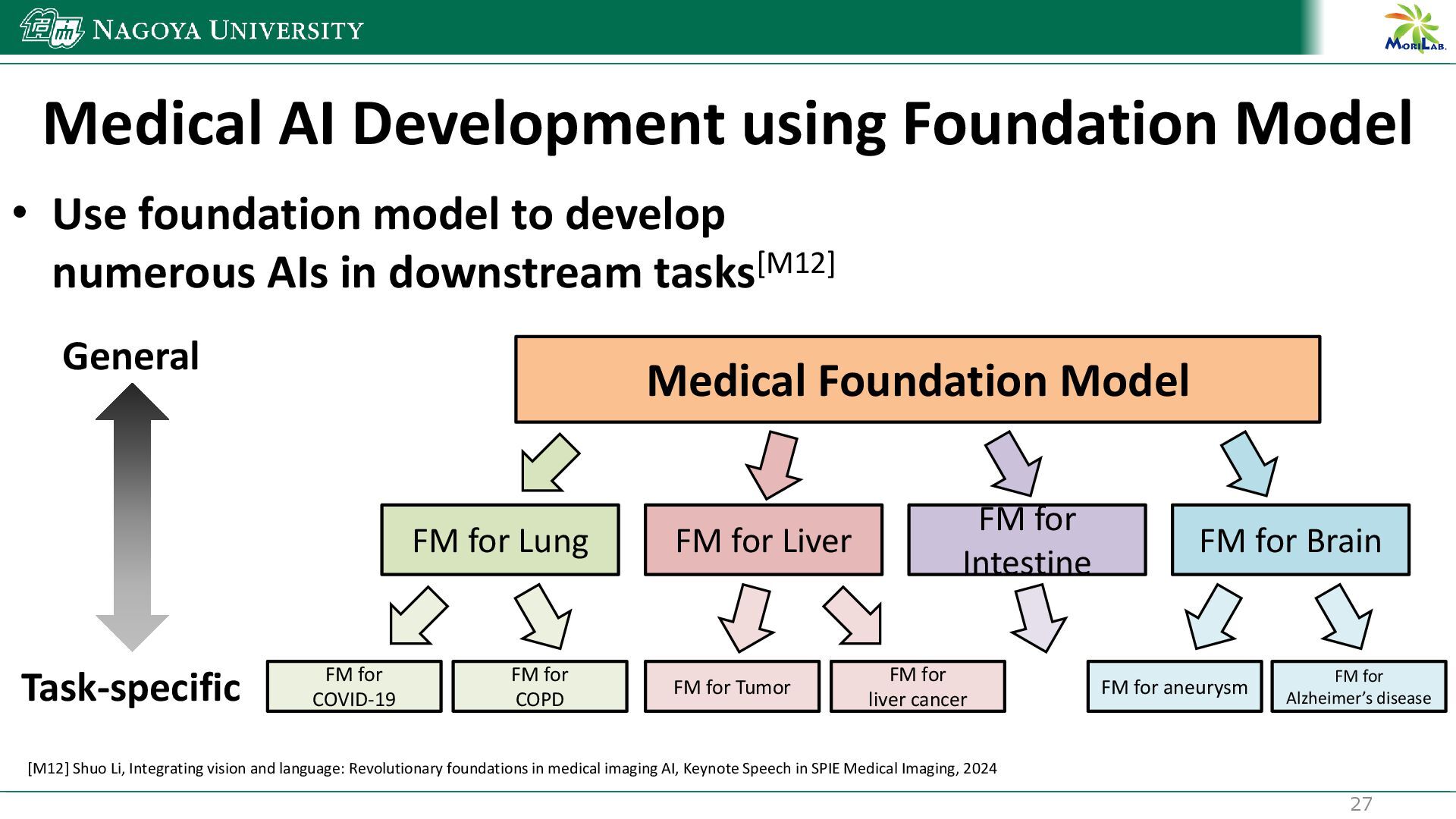{kind=link}
![Foundation Models for Medical Images (1/2) • Prov-GigaPath[M13] – Foundation](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_27.jpg){kind=link}
![Foundation Models for Medical Images (2/2) • BiomedCLIP[M15] – Multimodal](https://files.speakerdeck.com/presentations/e4108306a9264264b4d3b7f9804c740e/slide_28.jpg){kind=link}
{kind=link}