MongoSV 2011
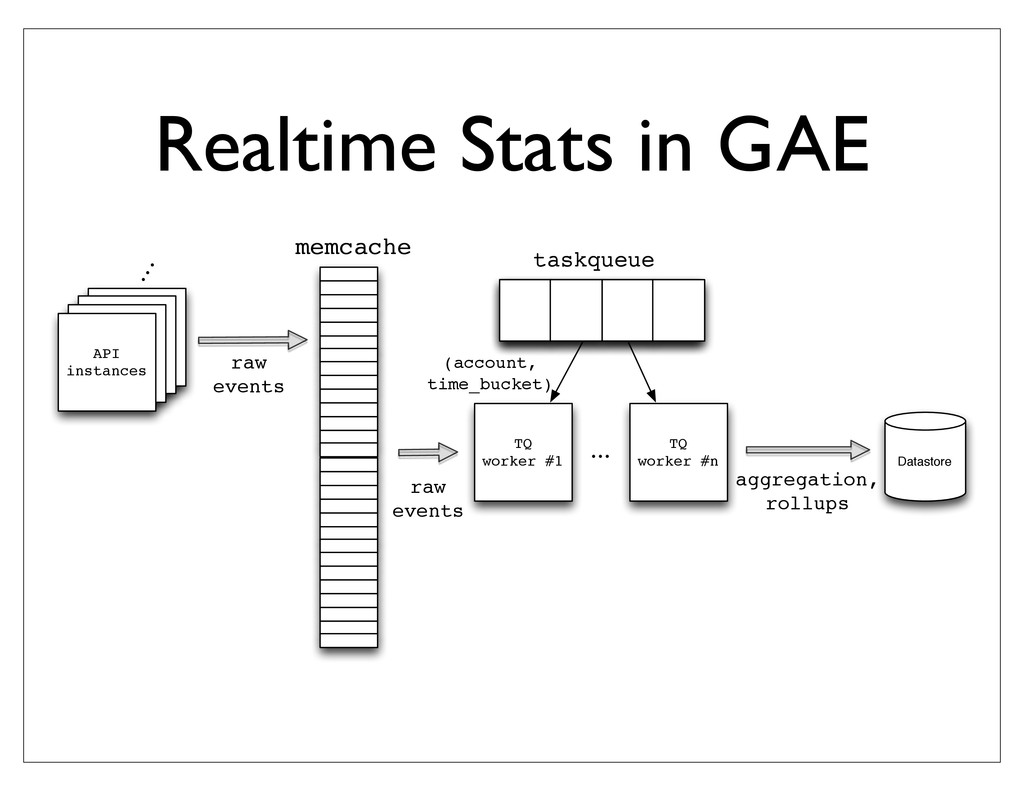
This talk will introduce MoPub, our data needs, and the challenges faced as we grew from 50M request / day to 1 billion / requests per day. We now use MongoDB for realtime stats (lots of counters!), our budgeting system, and our user store.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
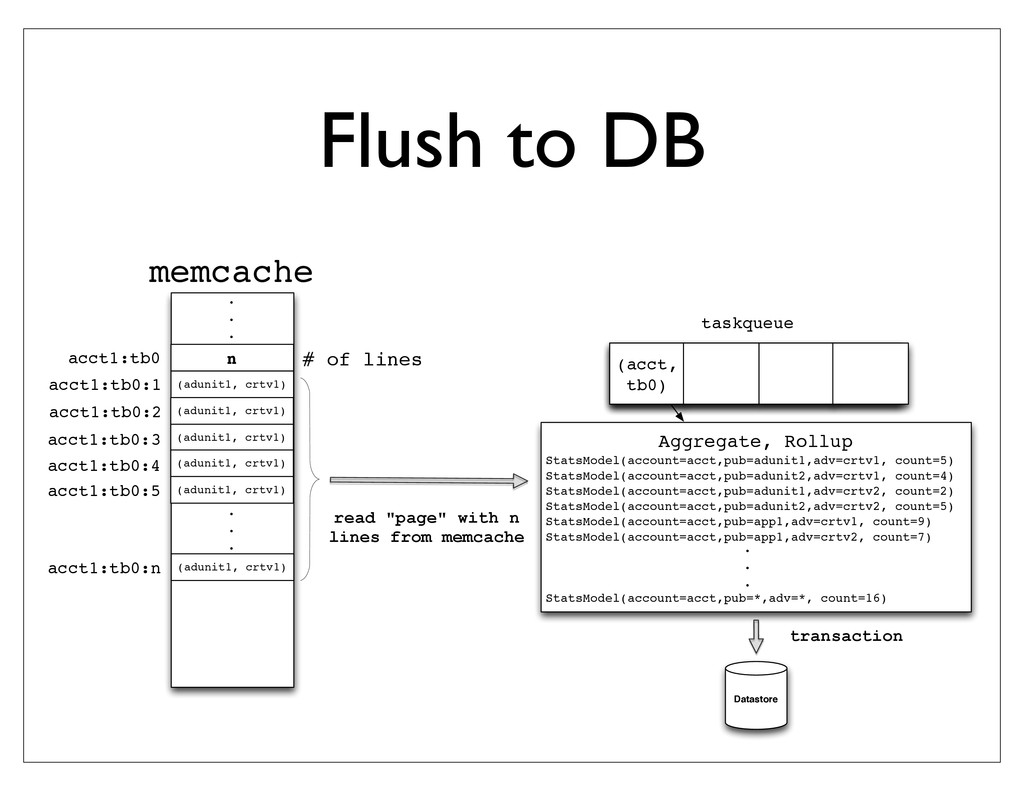{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
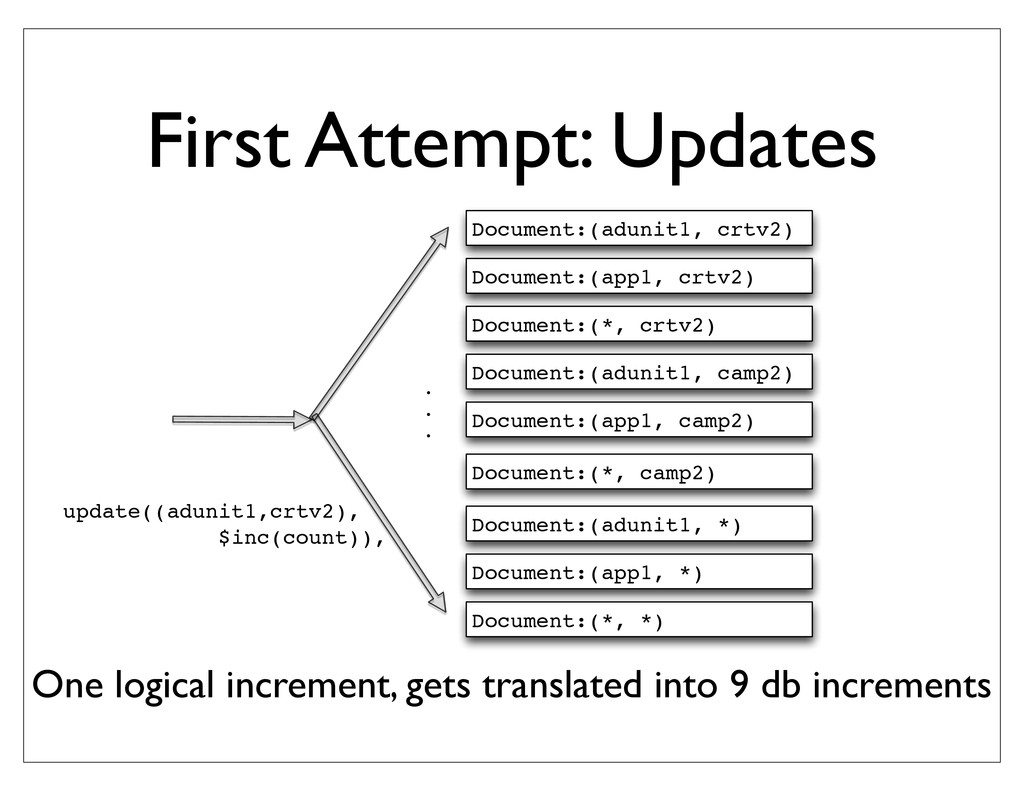{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? nafi[email protected]](https://files.speakerdeck.com/presentations/4f0388607dd7090027001c1f/slide_34.jpg){kind=link}
![We need help! [email protected]](https://files.speakerdeck.com/presentations/4f0388607dd7090027001c1f/slide_35.jpg){kind=link}