MongoDB Boulder 2012
One of the challenges that comes with moving to MongoDB is figuring how to best model your data. While most developers have internalized the rules of thumb for designing schemas for RDBMSs, these rules don't always apply to MongoDB. The simple fact that documents can represent rich, schema-free data structures means that we have a lot of viable alternatives to the standard, normalized, relational model. Not only that, MongoDB has several unique features, such as atomic updates and indexed array keys, that greatly influence the kinds of schemas that make sense.
![MongoBoulder 2012 Schema Design Robert Stam [email protected]](https://files.speakerdeck.com/presentations/4f3065f73a27420022006223/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
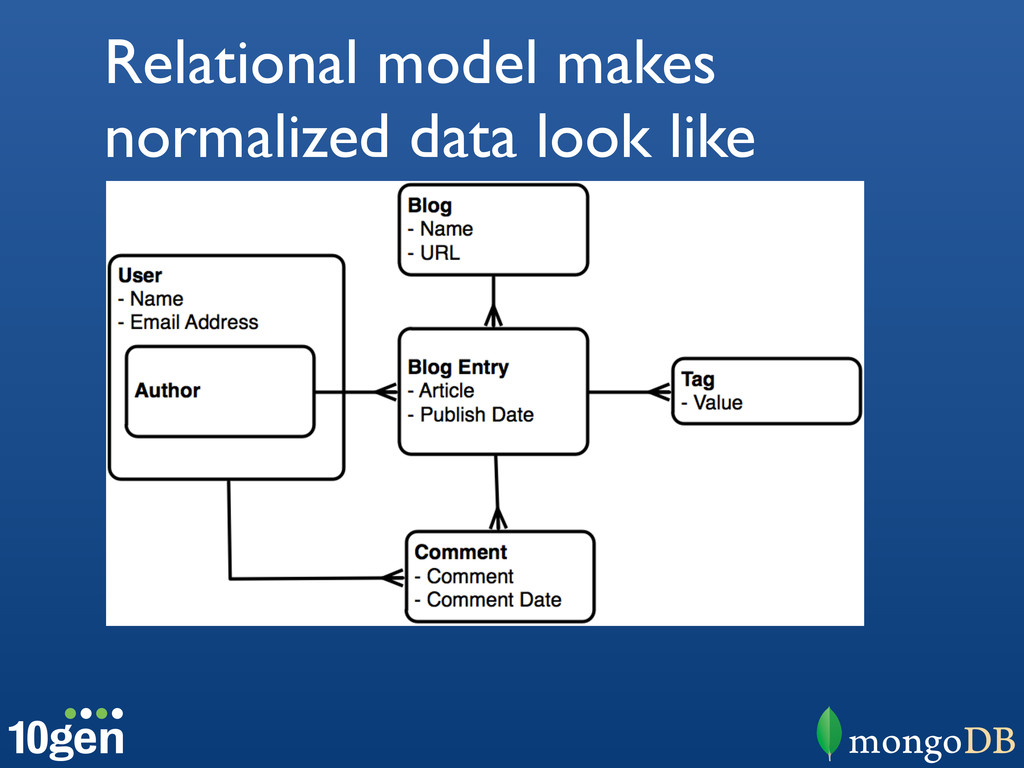{kind=link}
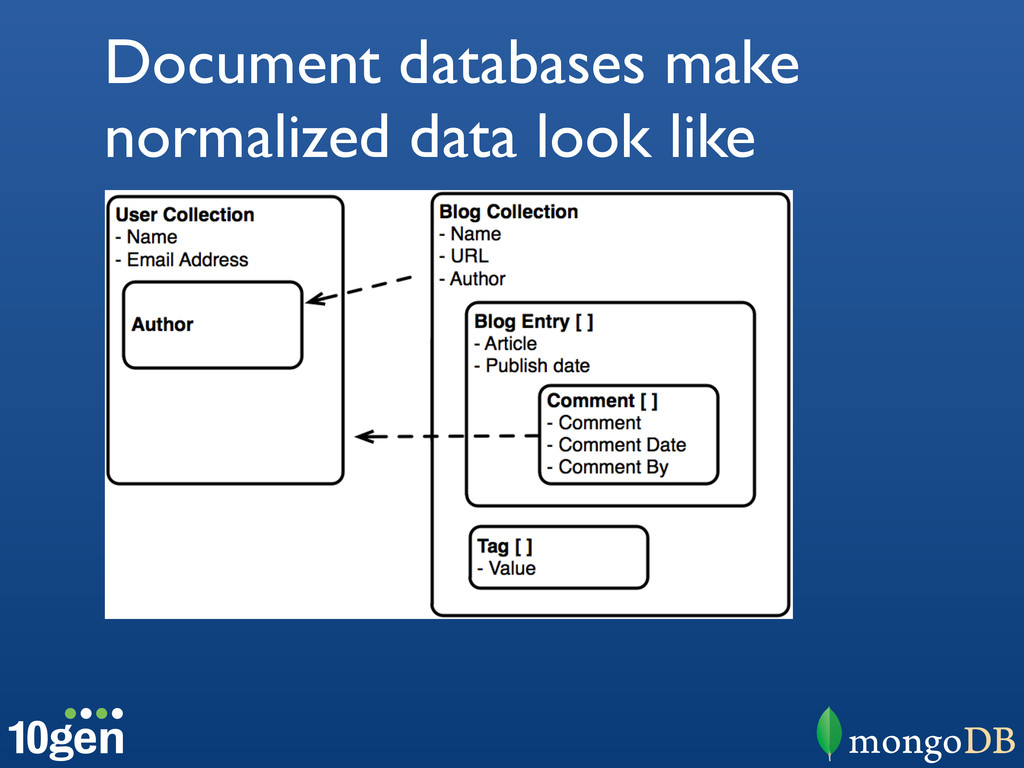{kind=link}
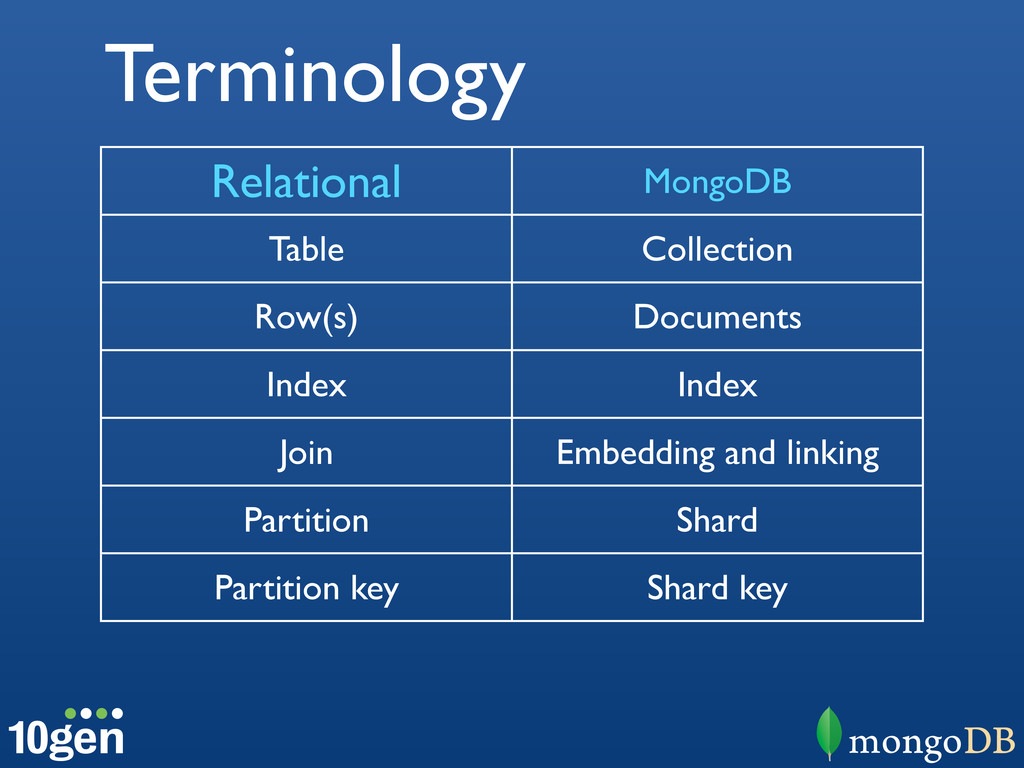{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
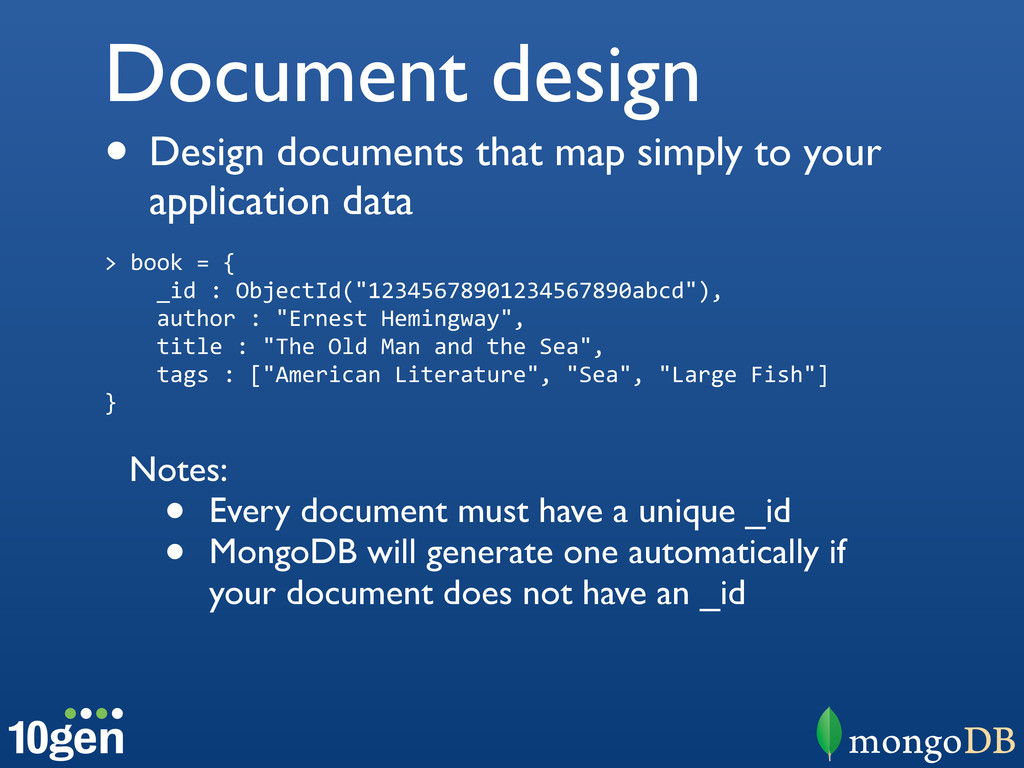{kind=link}
{kind=link}
{kind=link}
{kind=link}
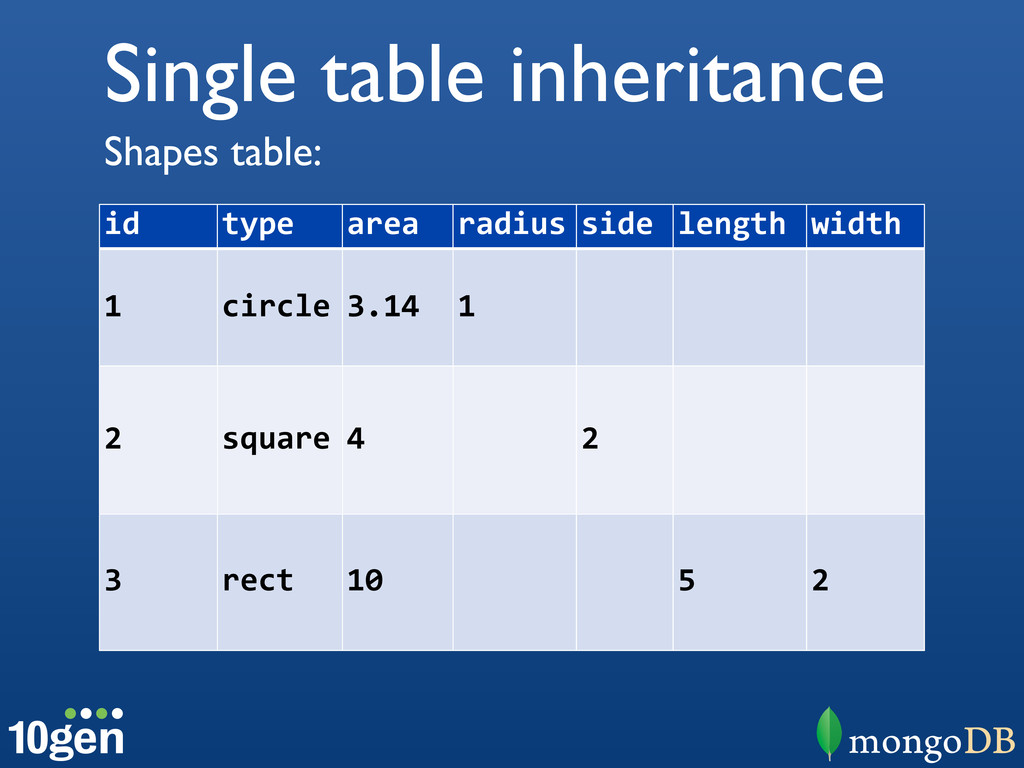{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}