Никита Учителев (Datacentric)
Мое выступление будет кратким введением в обучение реккурентных нейронных сетей. Сейчас обучить свою нейронную сетку может любой желающий, написав всего десяток строк кода. Я расскажу про то, что скрывается за этими строками, и почему нейросети еще не используются повсеместно.
9 февраля 2016, Moscow Python Meetup №32
{kind=link}
{kind=link}
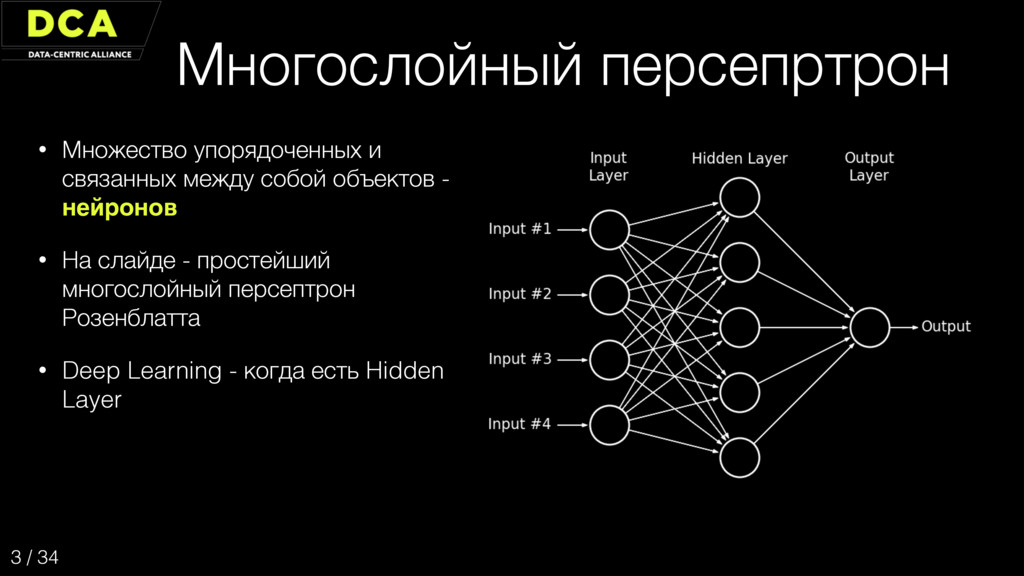{kind=link}
{kind=link}
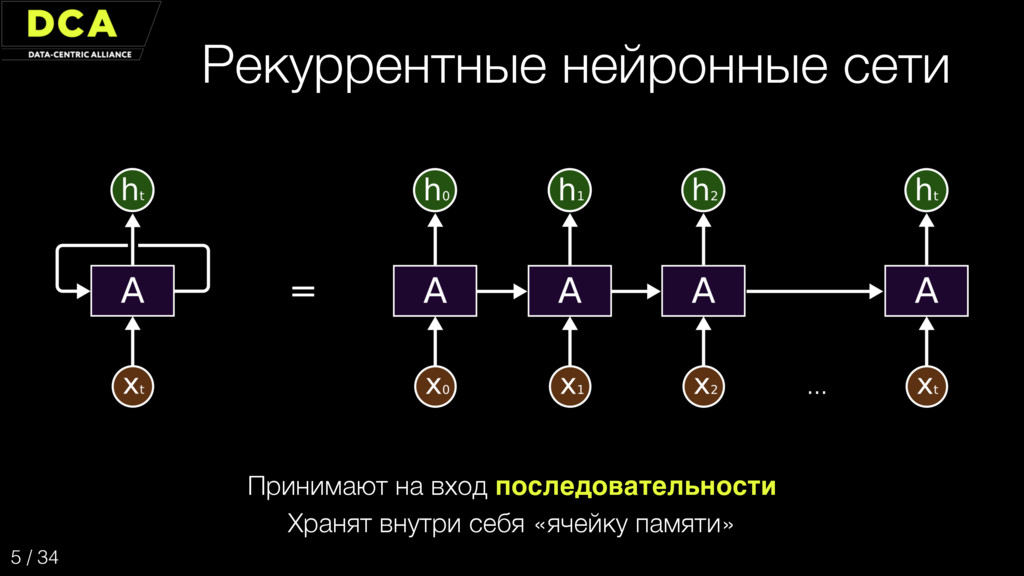{kind=link}
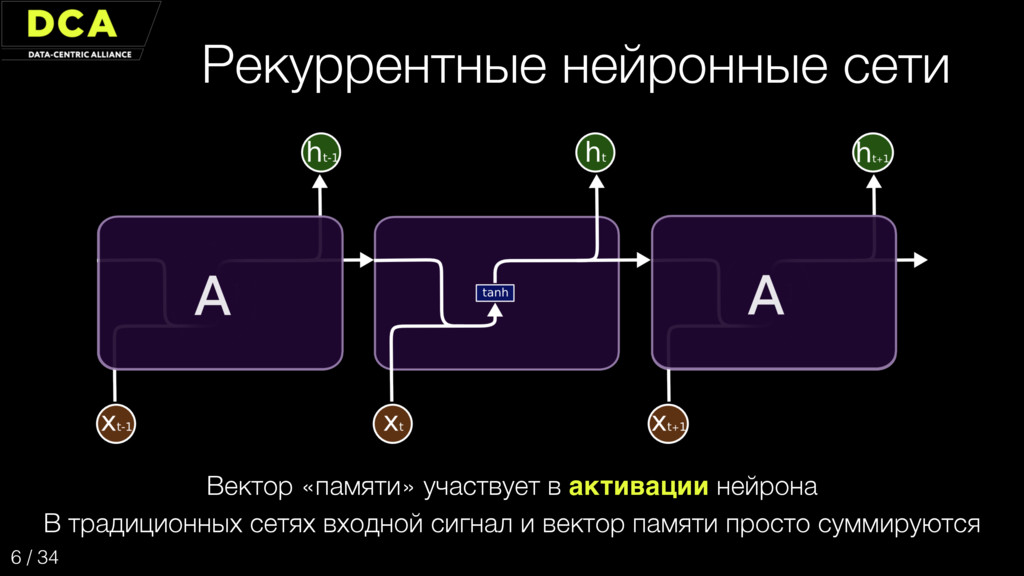{kind=link}
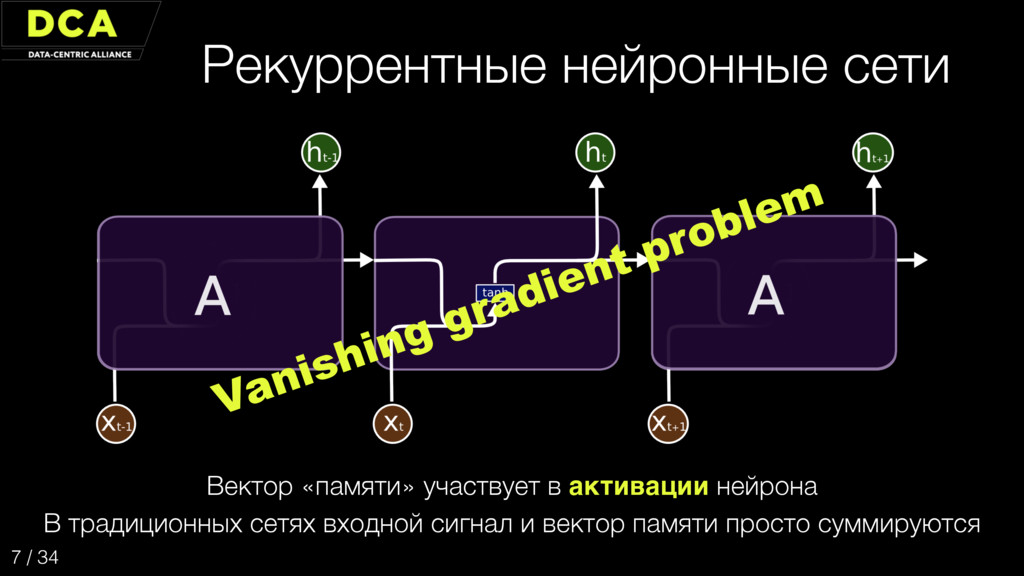{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
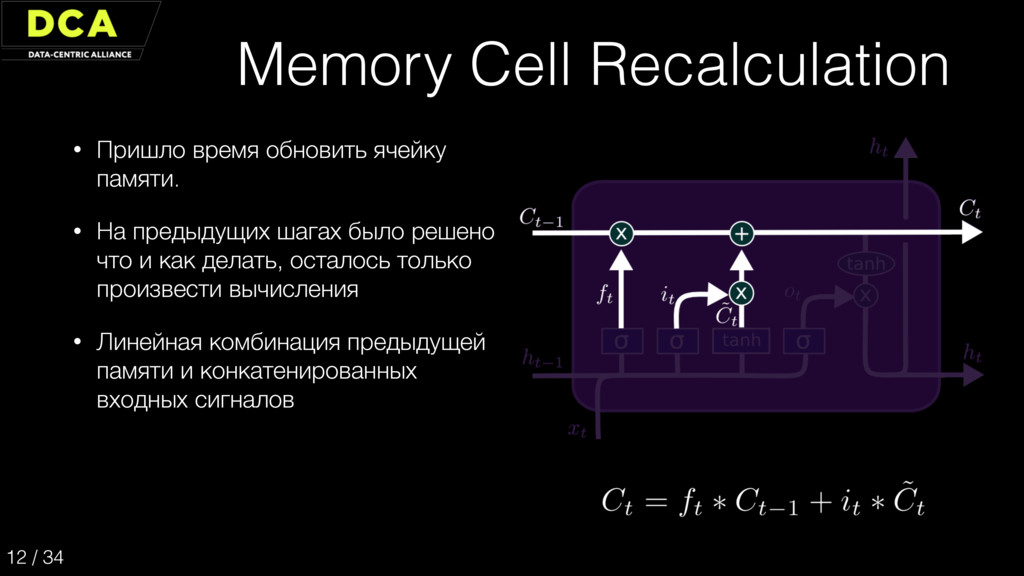{kind=link}
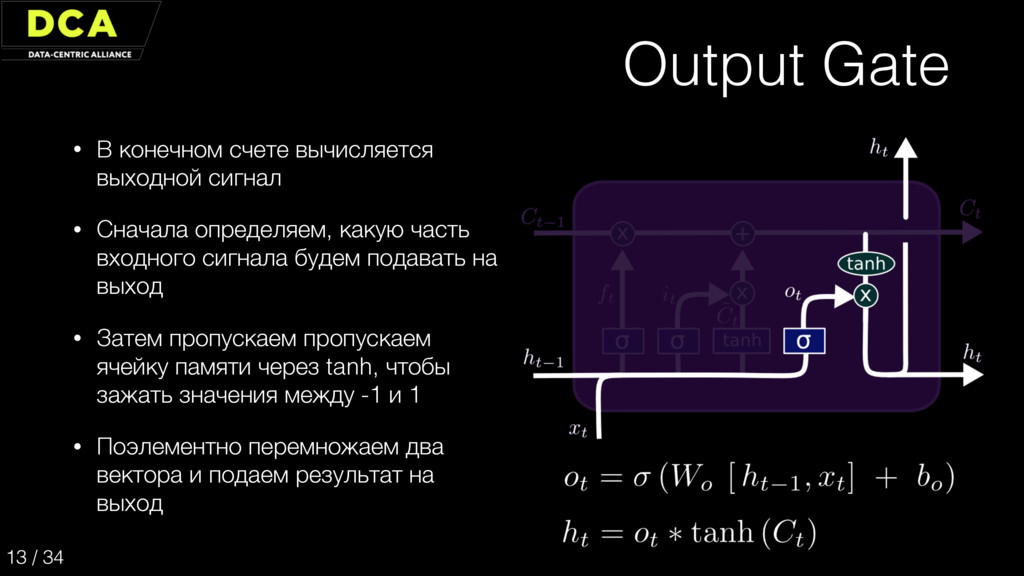{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}