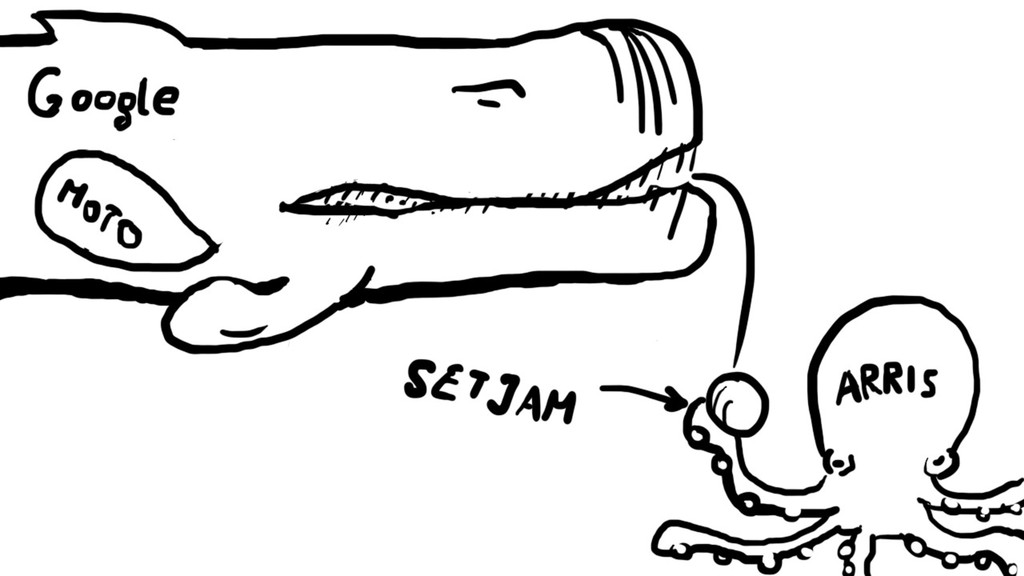
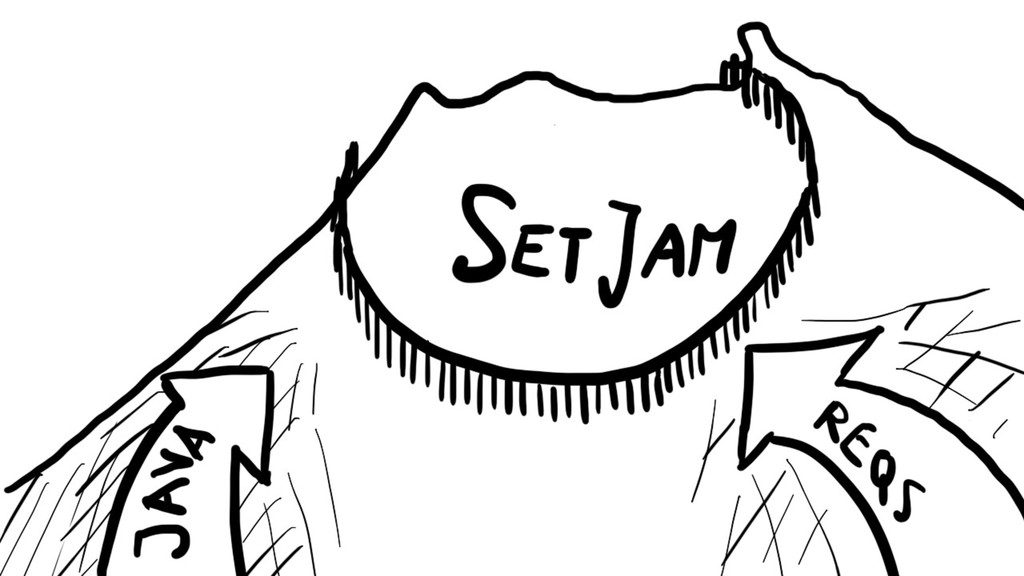
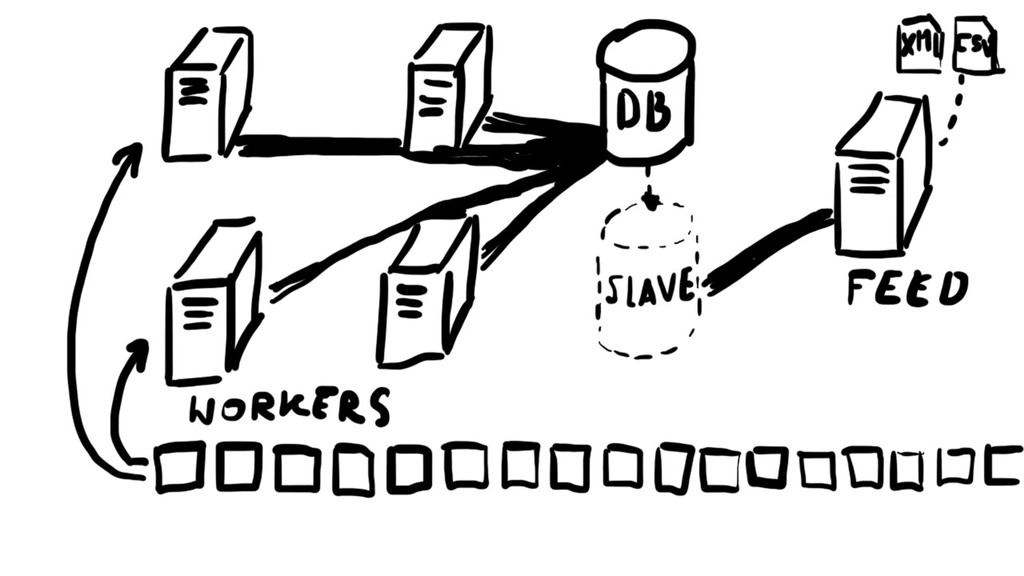
Support for multiple databases has been introduced in Django 1.2 in 2010, and, while amazing, it's still a minefield filled with programming gotchas. I've stumbled upon many of them while developing a highly distributed system at SetJam and want to share my pain with you.
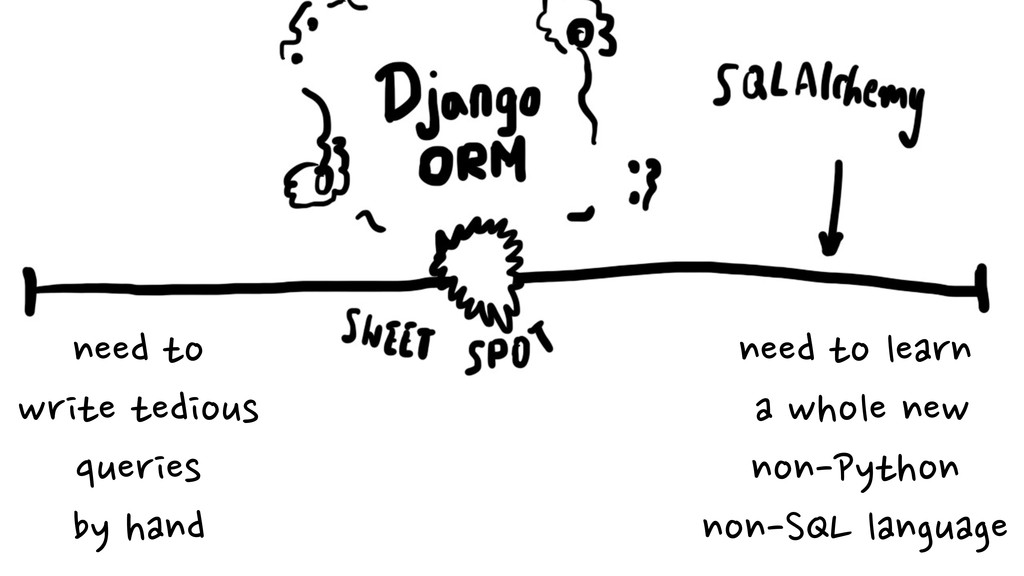
Knowing how to properly route queries, migrate schemas (using lovely South library) and then test the whole thing, while dodging chainsaws of Multi-DB API, will probably save you a few days of cursing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
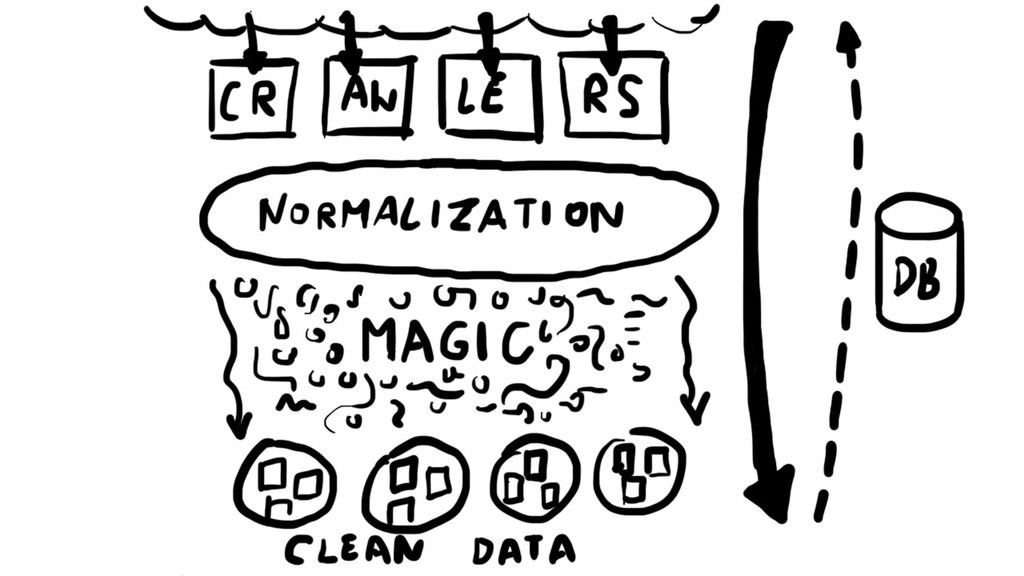{kind=link}
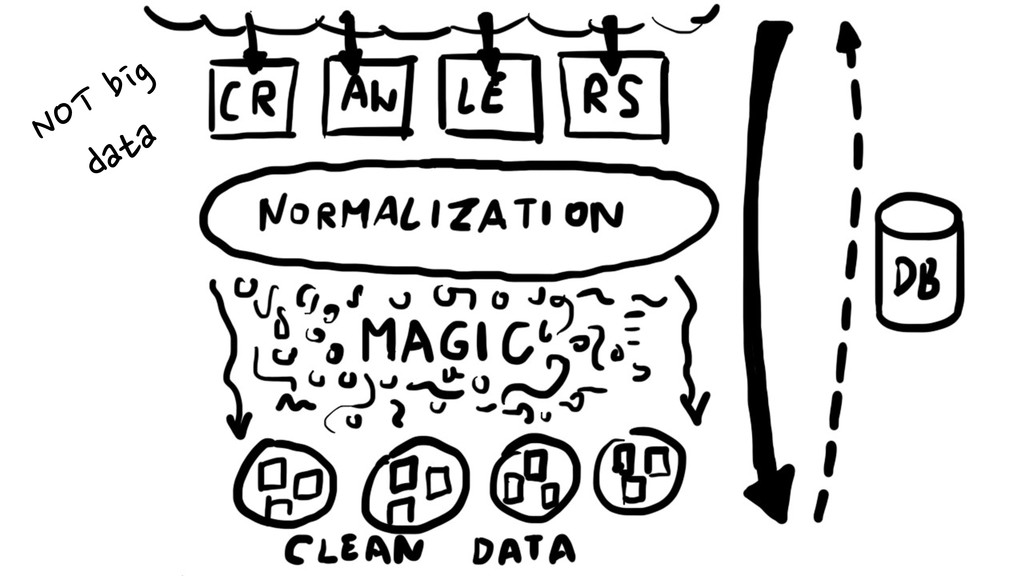{kind=link}
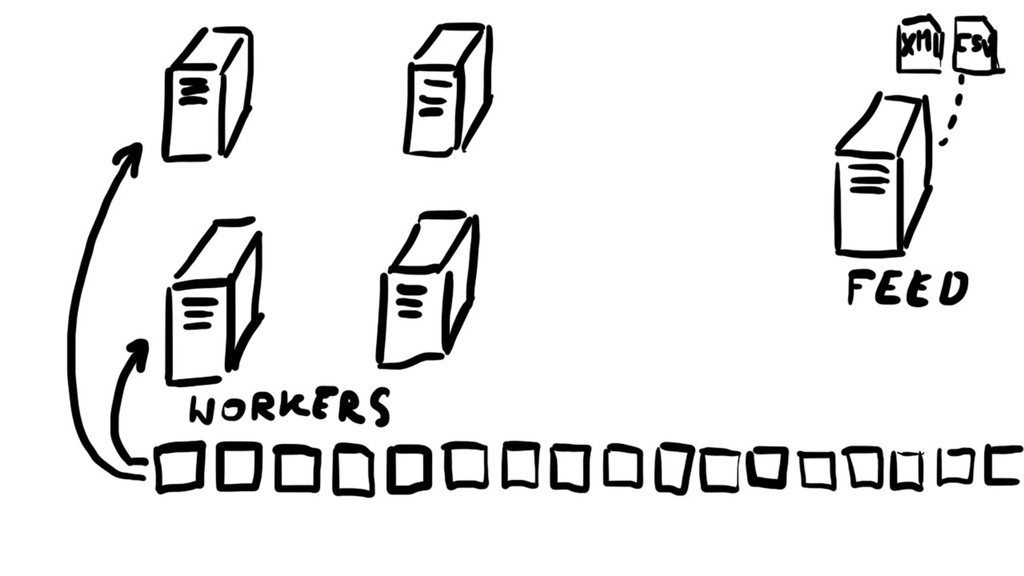{kind=link}
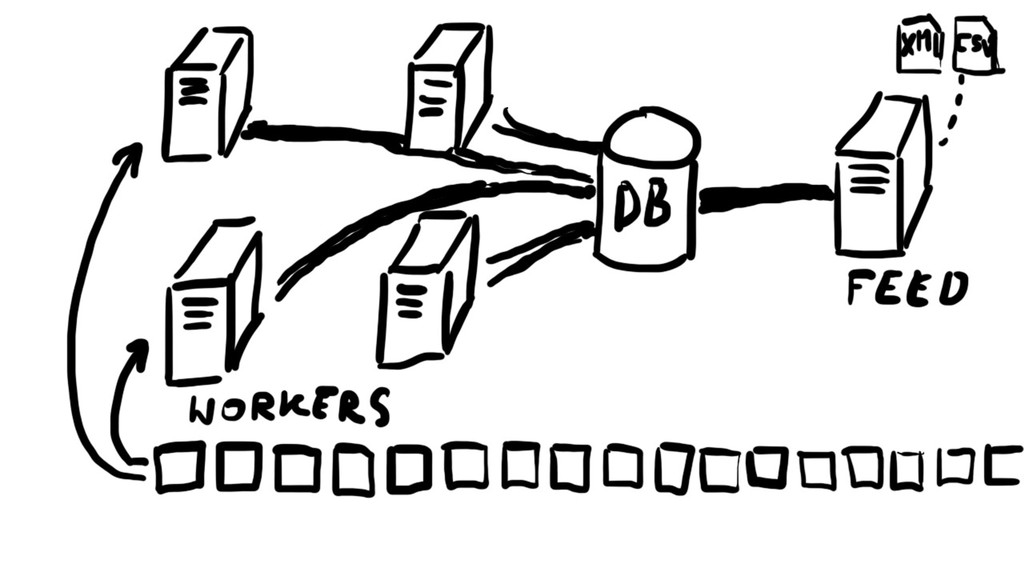{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
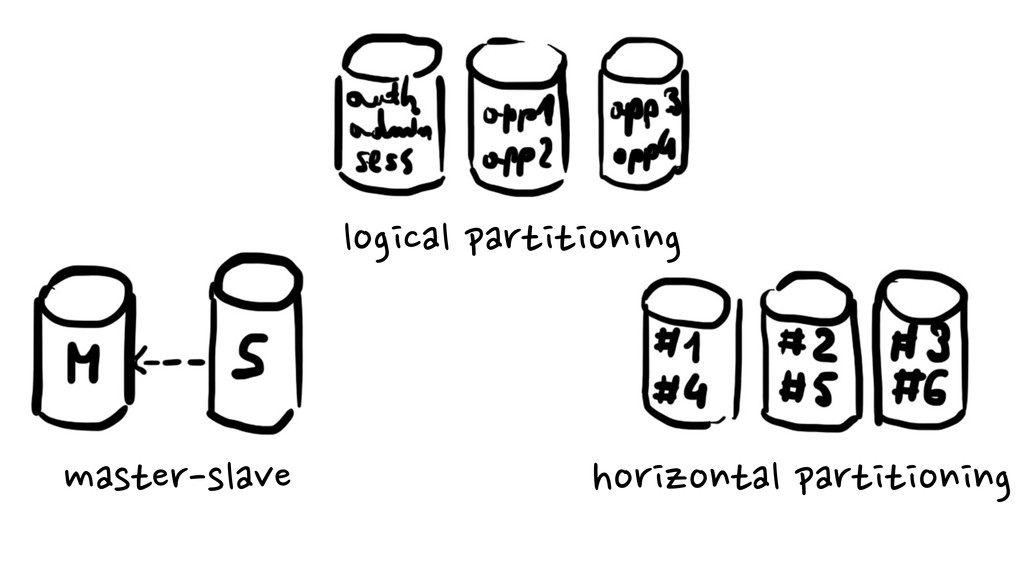{kind=link}
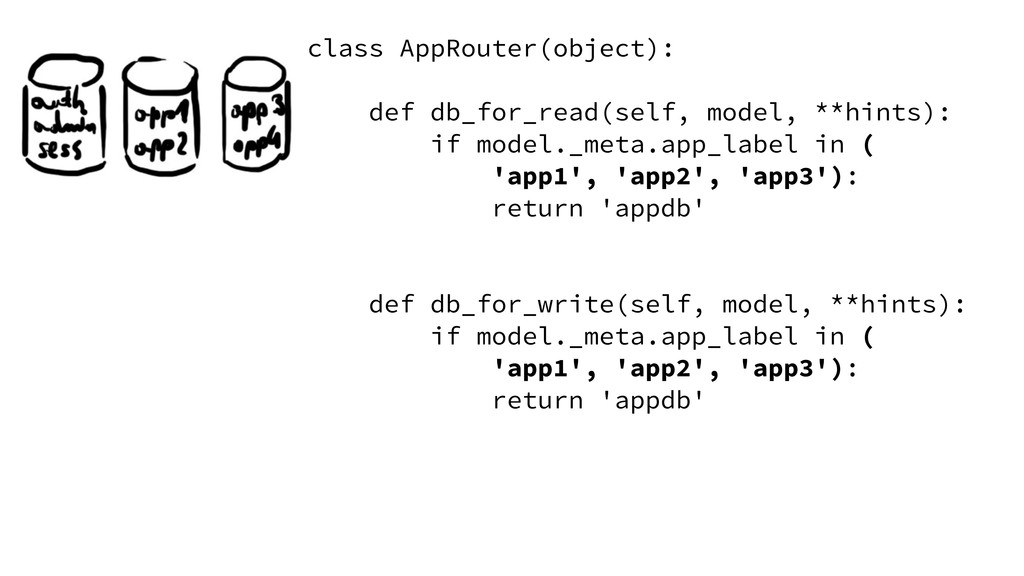
![class HorizontalPartitioningRouter(object): parts = ['p1', 'p2', 'p3'] def _db(self, obj):](https://files.speakerdeck.com/presentations/9e5e0160a02d013073cf3af825100fff/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
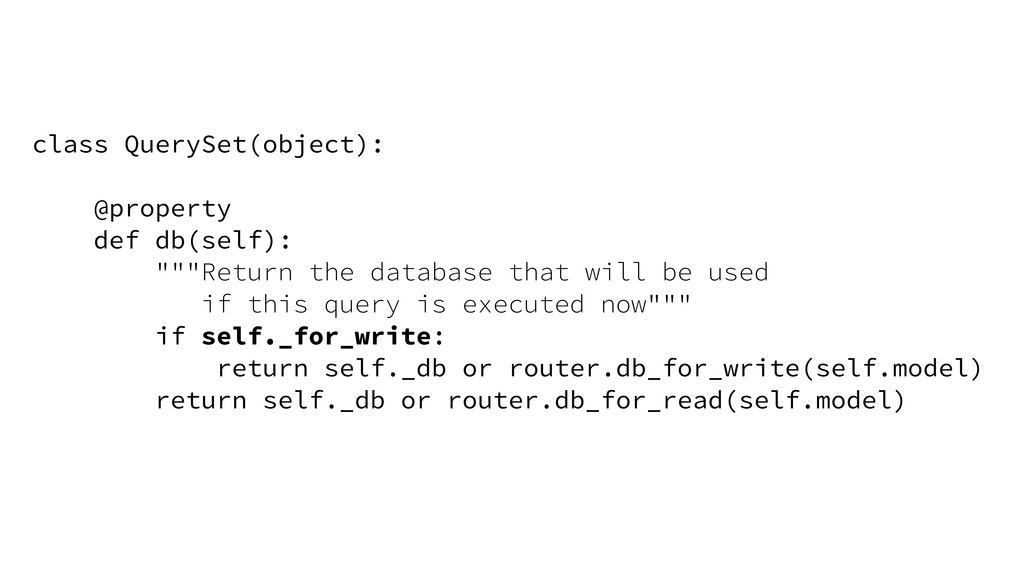{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
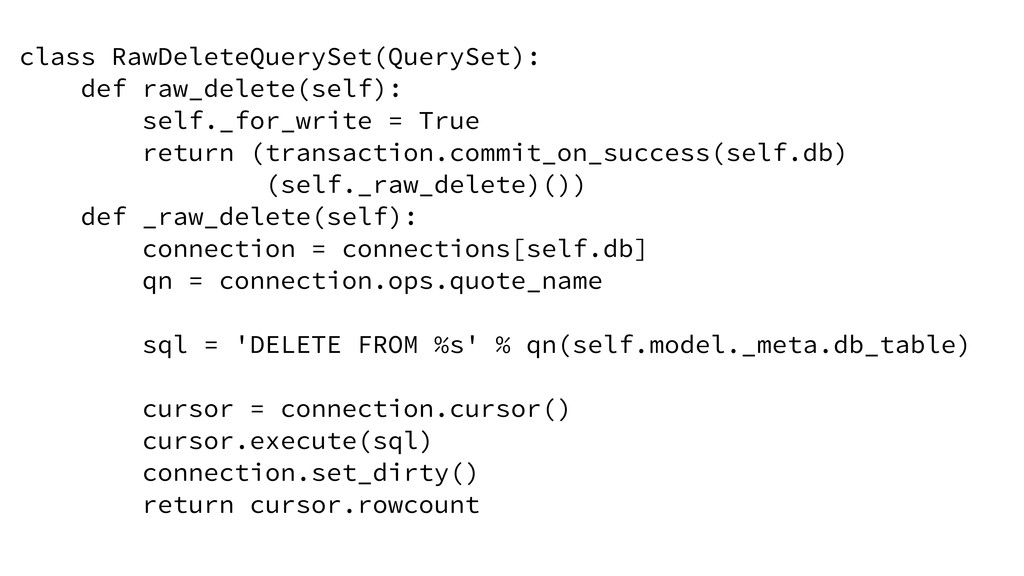
![class RawDeleteQuerySet(QuerySet): @transaction.commit_on_success def raw_delete(self): connection = connections[self.db] qn =](https://files.speakerdeck.com/presentations/9e5e0160a02d013073cf3af825100fff/slide_69.jpg){kind=link}
{kind=link}
![class RawDeleteQuerySet(QuerySet): @transaction.commit_on_success def raw_delete(self): connection = connections[self.db] qn =](https://files.speakerdeck.com/presentations/9e5e0160a02d013073cf3af825100fff/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}