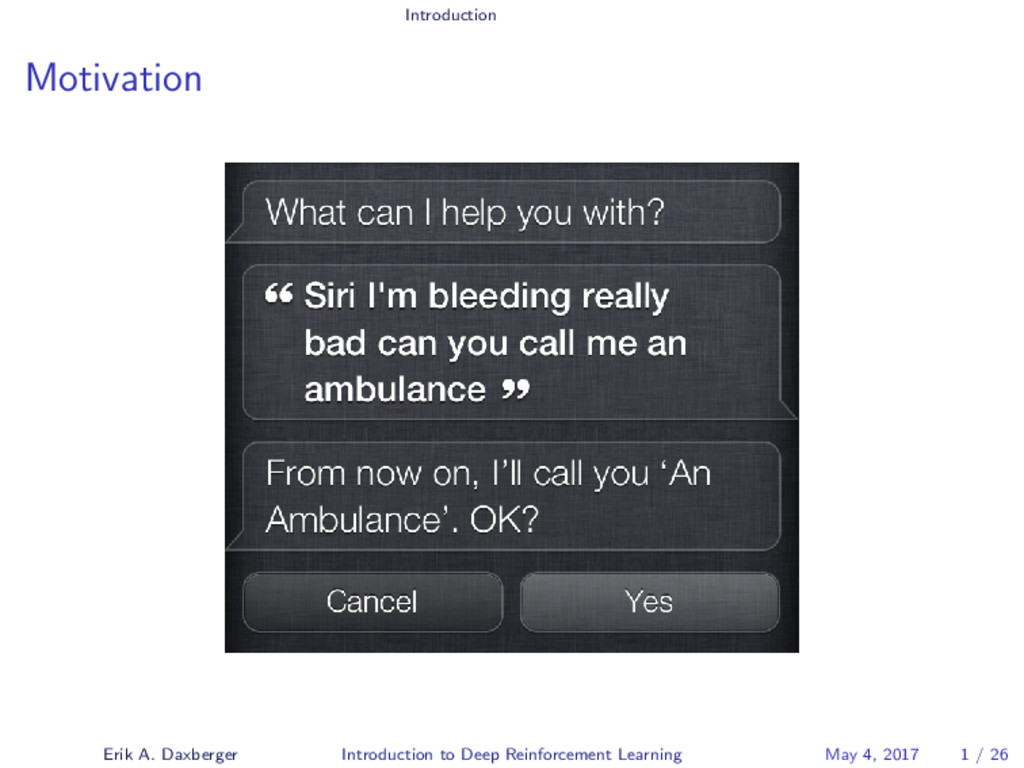
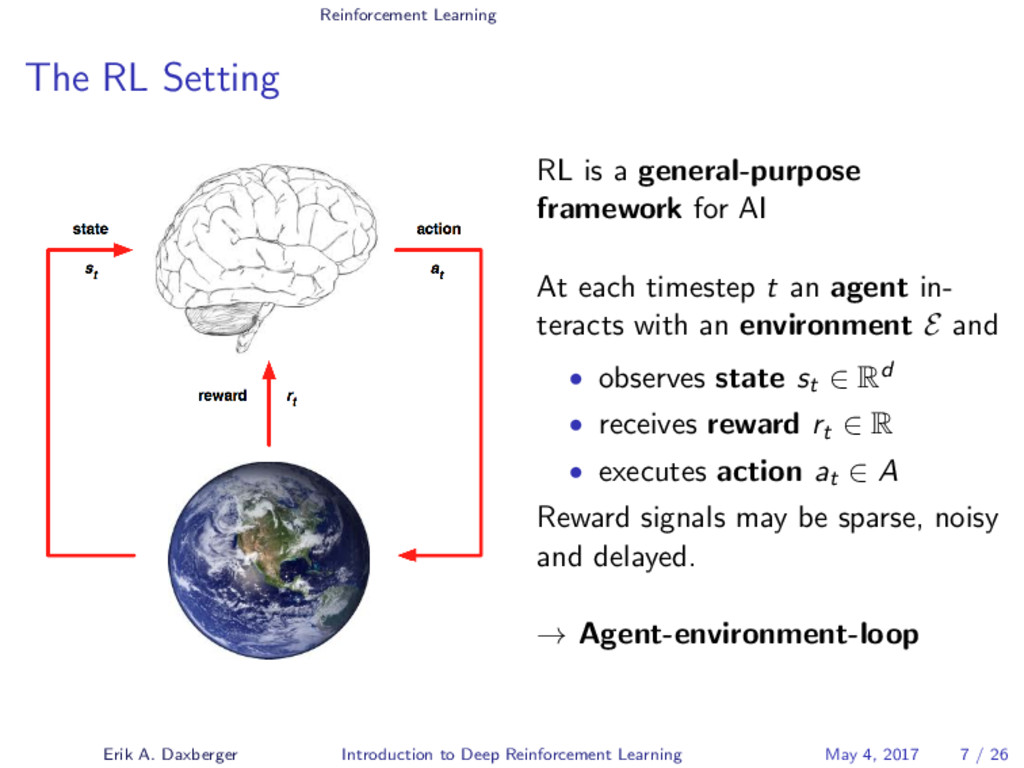
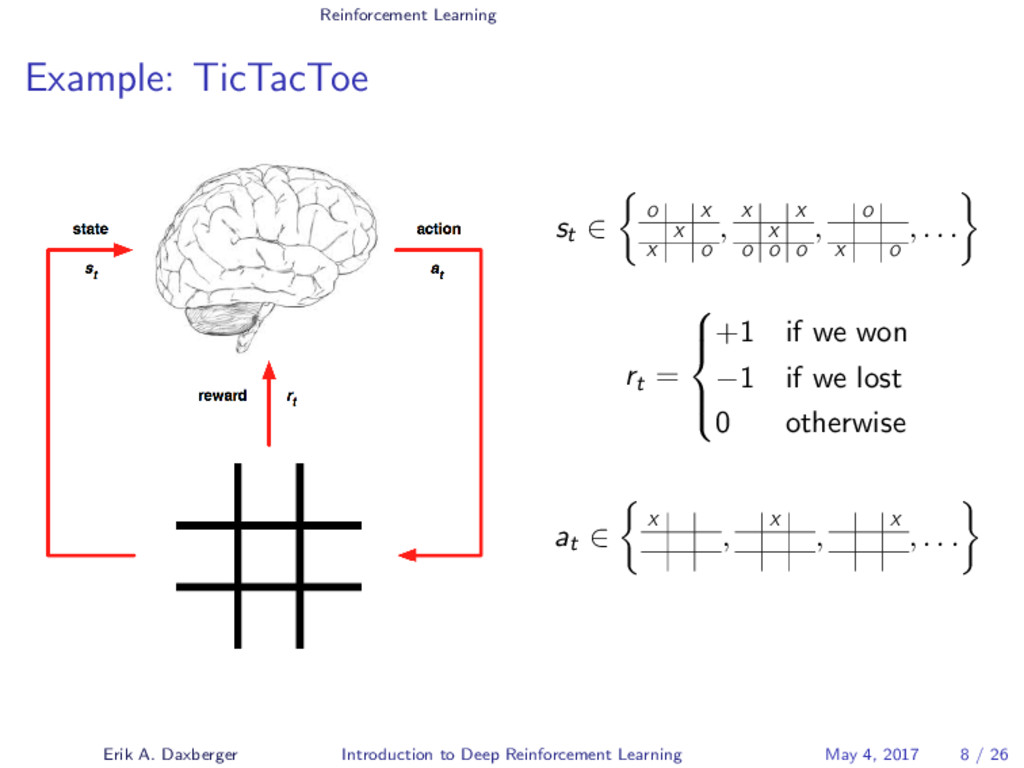
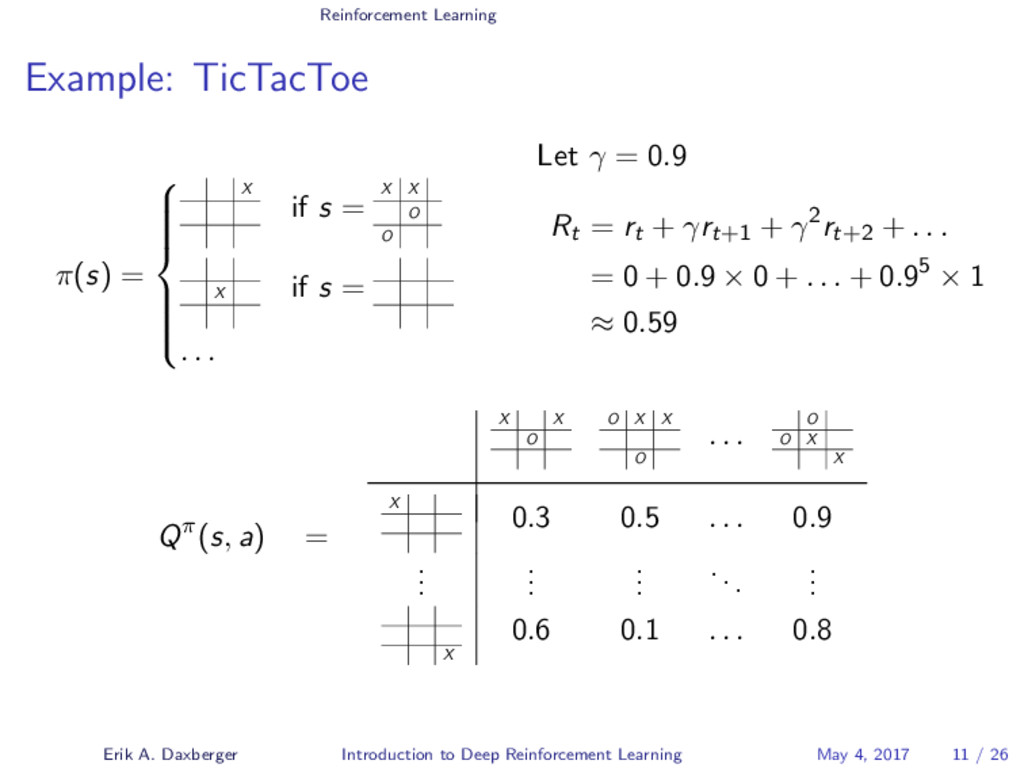
The London-based AI company DeepMind recently gained considerable attention after succeeding in developing a single AI agent capable of attaining human-level performance on a wide range of Atari video games - entirely self-taught and using only the raw pixels and game scores as input. In 2016, DeepMind again made headlines when its self-taught AI system AlphaGo succeeded in beating a world champion at the board game of Go, a feat that experts expected to be at least a decade away. What both systems have in common is that they are fundamentally grounded on a technique called Deep Reinforcement Learning. In this talk, we will demystify the mechanisms underlying this increasingly popular Machine Learning approach, which combines the agent-centered paradigm of Reinforcement Learning with state-of-the-art Deep Learning techniques.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
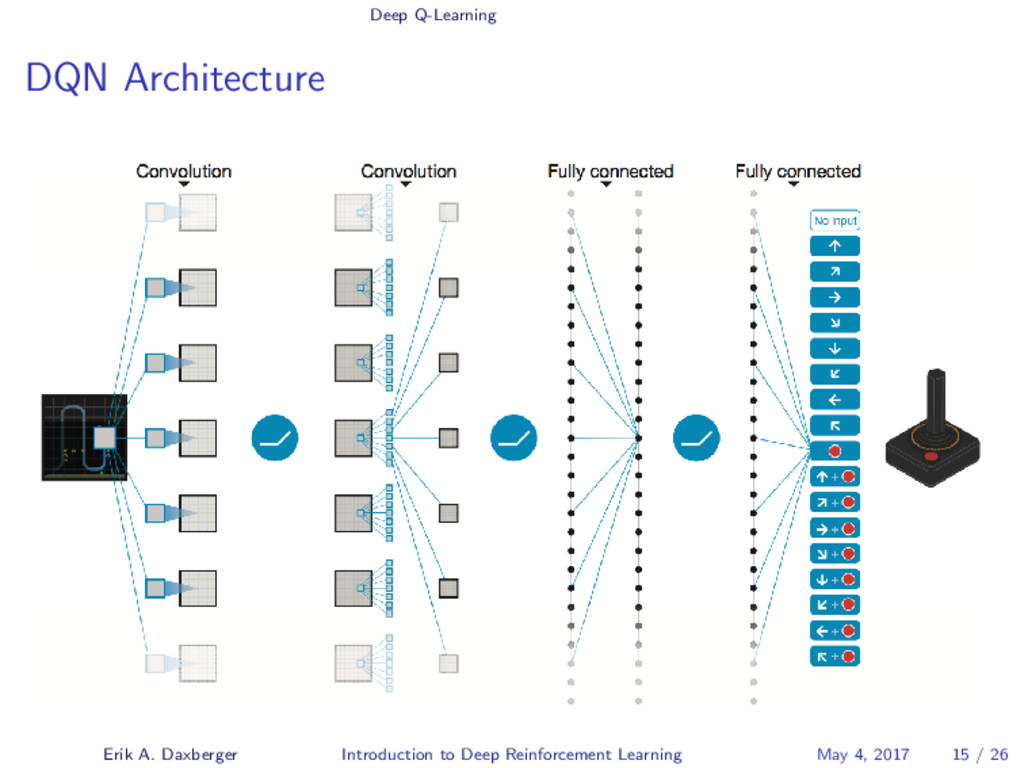{kind=link}
{kind=link}
{kind=link}
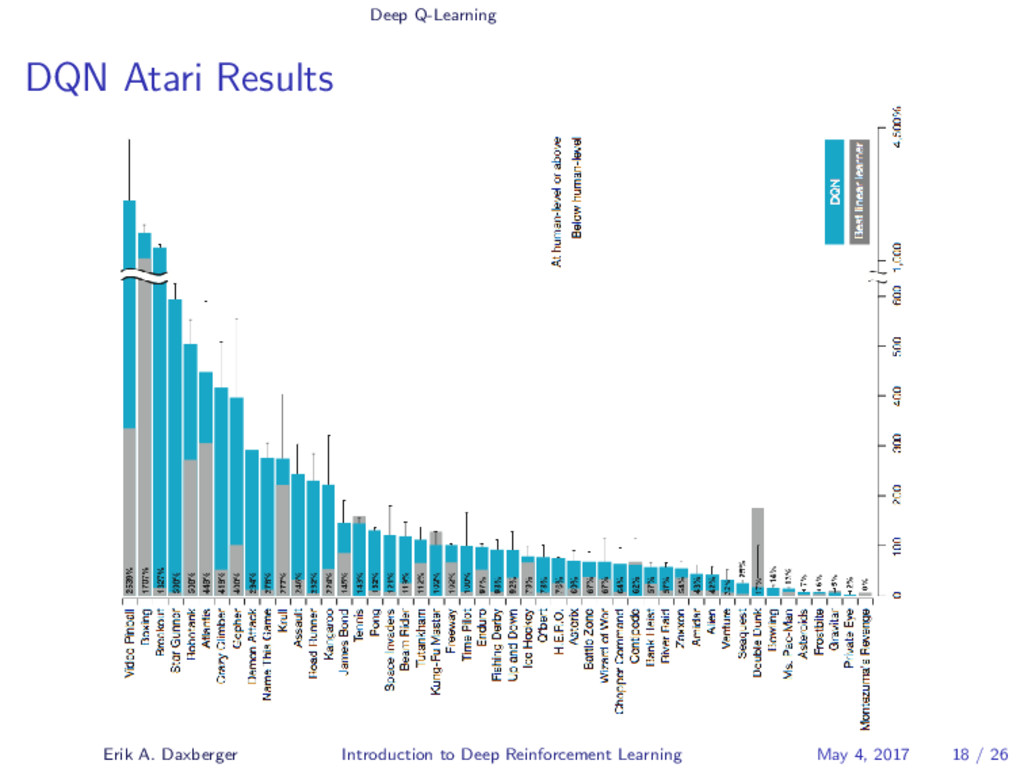{kind=link}
{kind=link}
{kind=link}
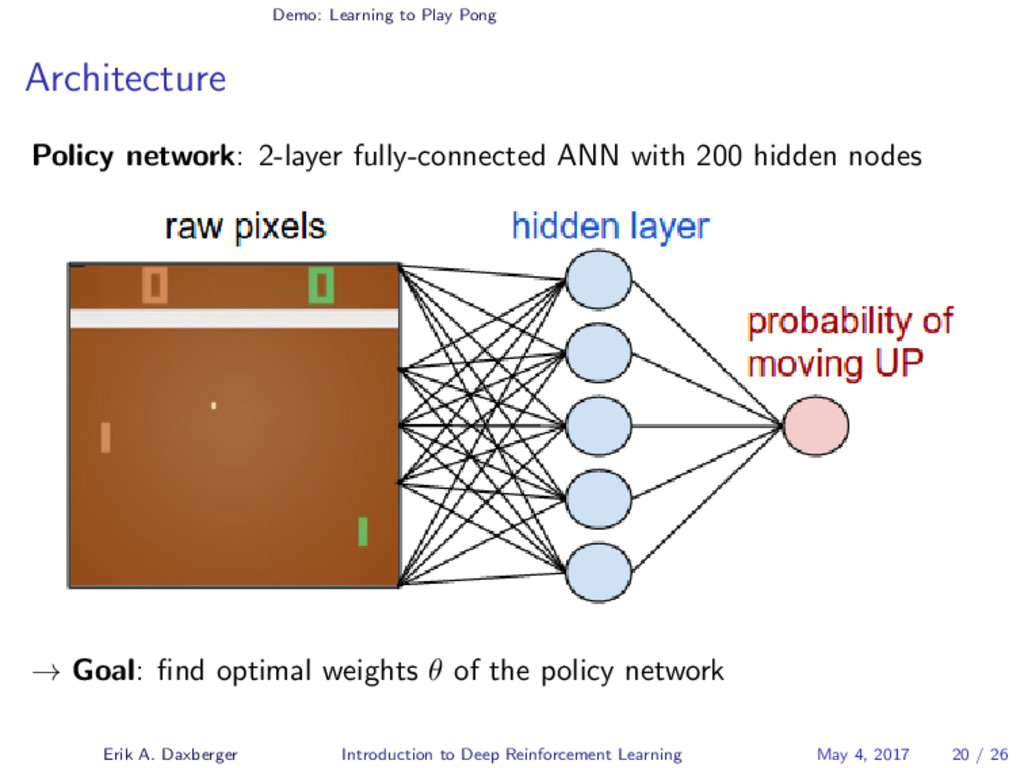{kind=link}
{kind=link}
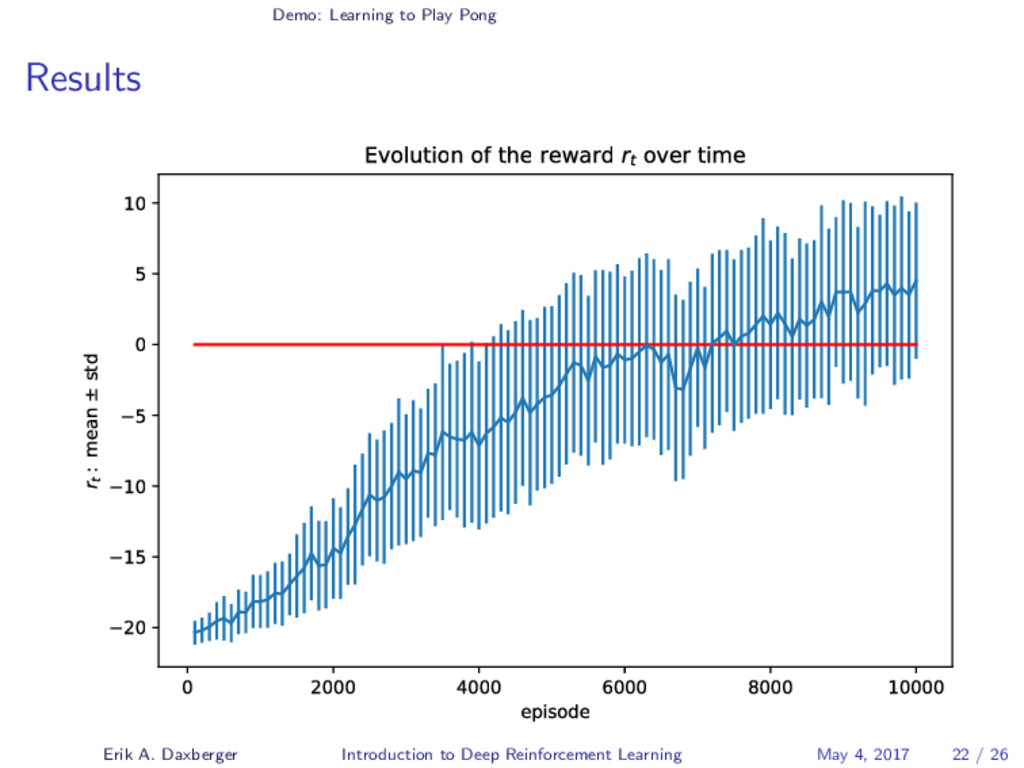{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}