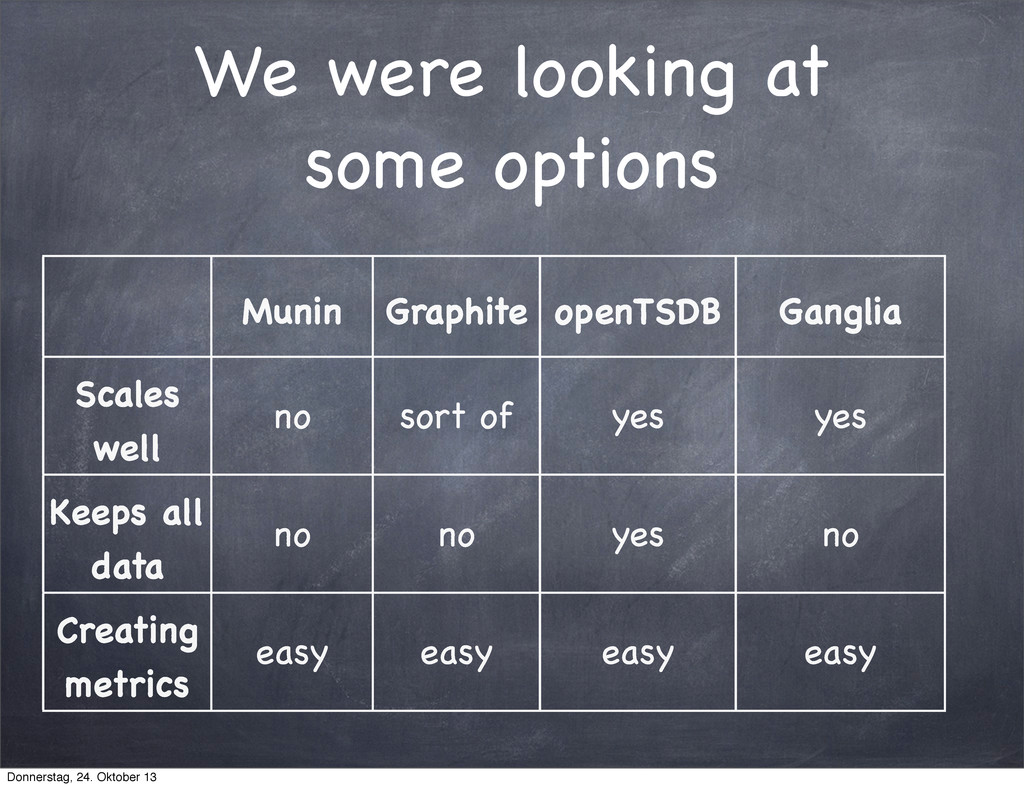
This is the talk about our metrics solution at gutefrage.net. We use openTSDB. I gave this talk at the Open Source Monitorin Conference 2013 in Nuremberg.
(mobile) about 5M Unique Users #3 German site (desktop) about 17M Unique Users > 4 Mio PI/day Part of the Holtzbrinck group Running several platforms (Gutefrage.net, Helpster.de, Cosmiq, Comprano, ...) Donnerstag, 24. Oktober 13
runs your collectors handles network connection, starts your collectors at set intervals does basic process management adds host tag, does deduplication Donnerstag, 24. Oktober 13
suitable for Petabytes of data on thousands of machines. Runs on commodity hardware Takes care of redundancy Used by e.g. Facebook, Spotify, eBay,... Donnerstag, 24. Oktober 13
store on top of HDFS Modeled after Google‘s BigTable Built for big tables (billions of rows, millions of columns) Automatic sharding by row key Donnerstag, 24. Oktober 13
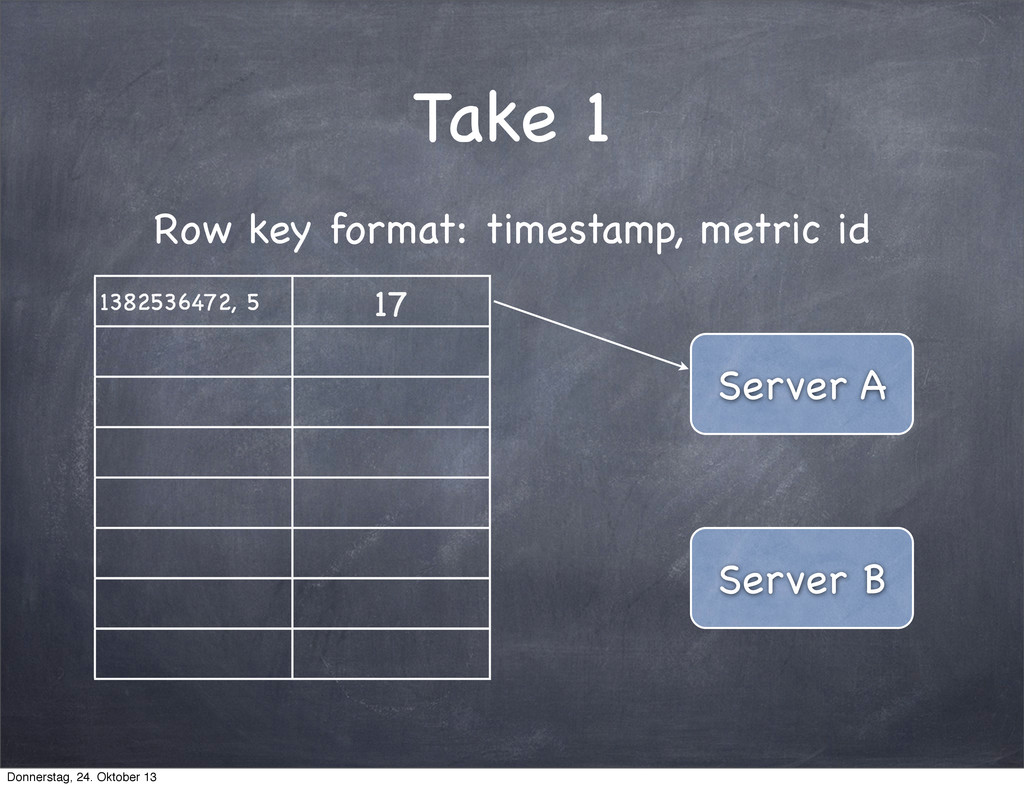
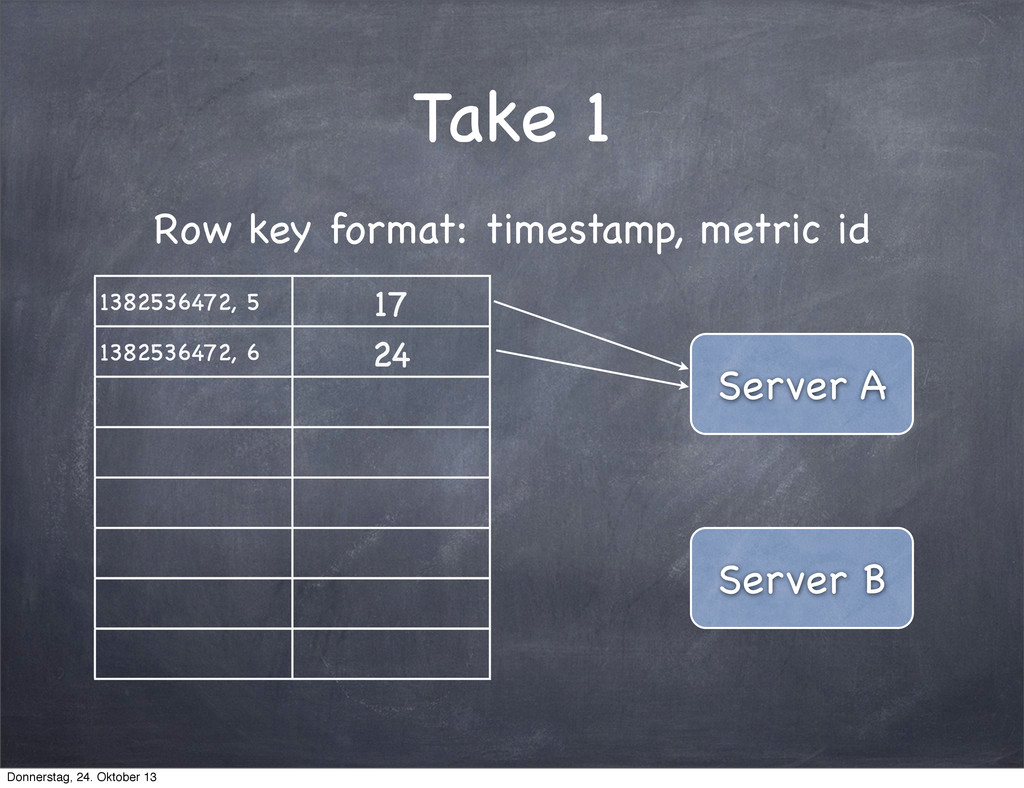
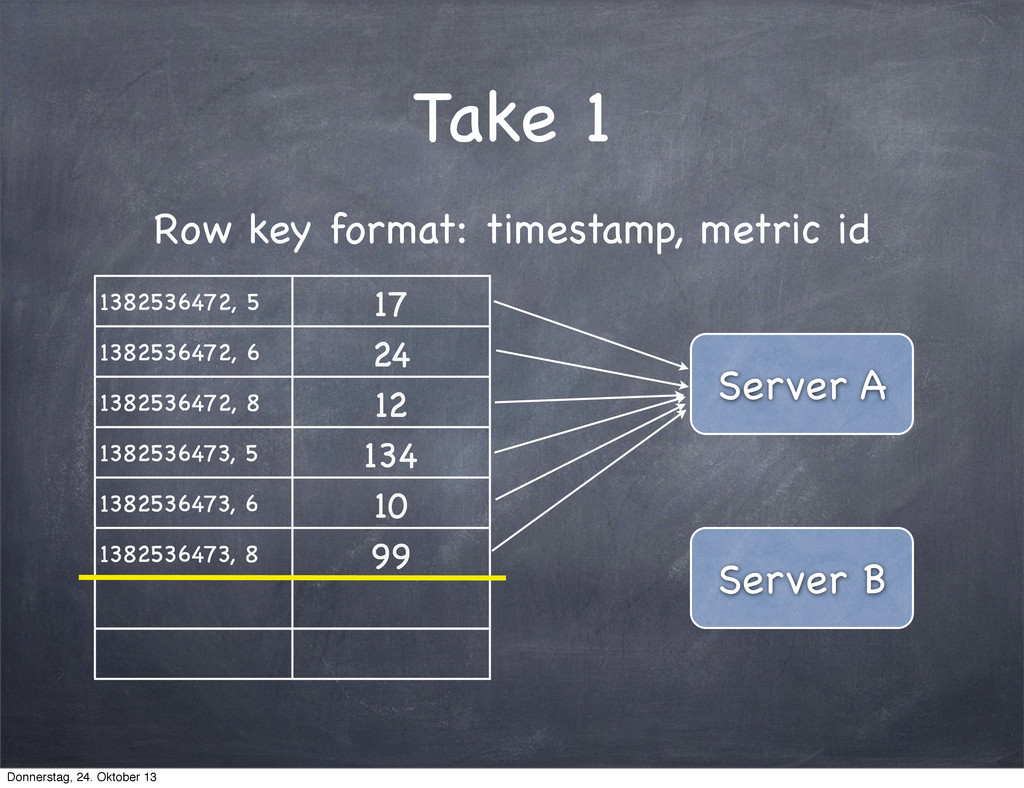
several thousand time series with no issues tcollector is decoupling measurement from storage Creating new metrics is really easy Donnerstag, 24. Oktober 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Please contact me: [email protected] @mydalon I‘ll upload the slides](https://files.speakerdeck.com/presentations/279e23c01ed60131fc303e1d2897ce69/slide_38.jpg){kind=link}