Pachyderm is a data lake that offers complete version control for data and leverages the container ecosystem to provide reproducible data processing.
As data scientists, we know the best ideas come through collaboration. We also know reproducibility matters. Pachyderm makes both a reality, and this talk shows how. We’ll talk about data containers and analysis pipelines, and how they combine to make Pachyderm a Git for Data Science.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
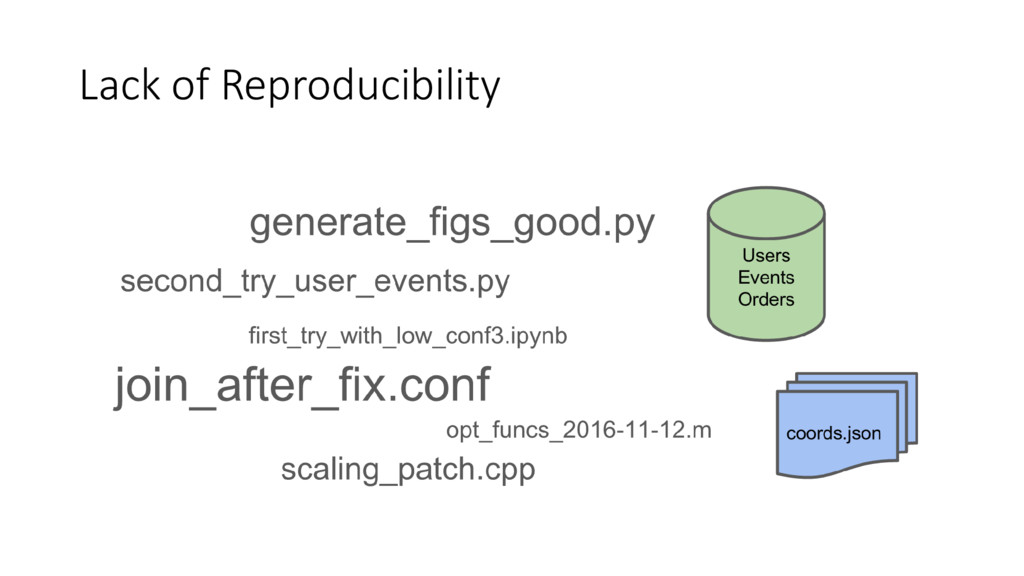{kind=link}
{kind=link}
{kind=link}
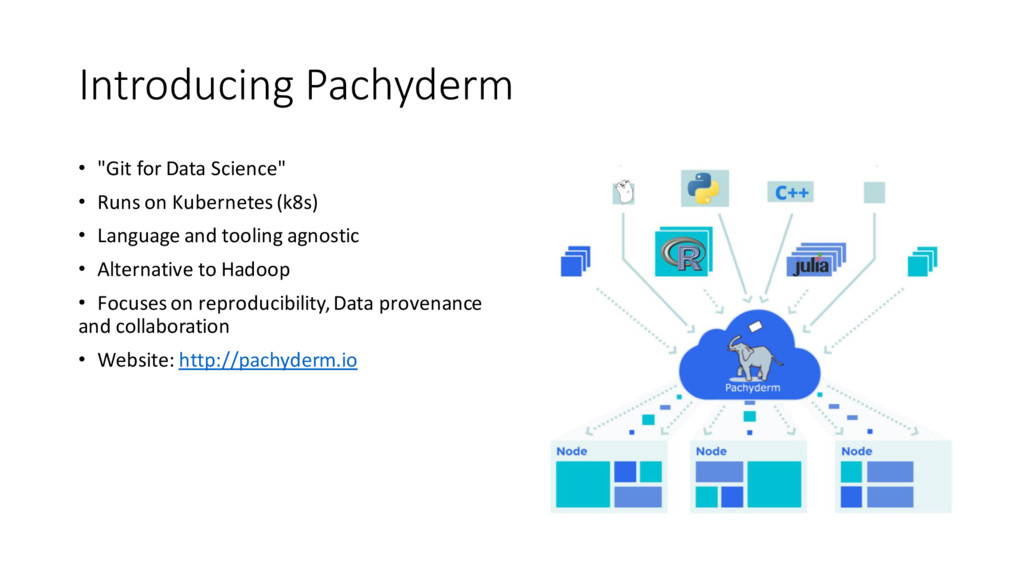{kind=link}
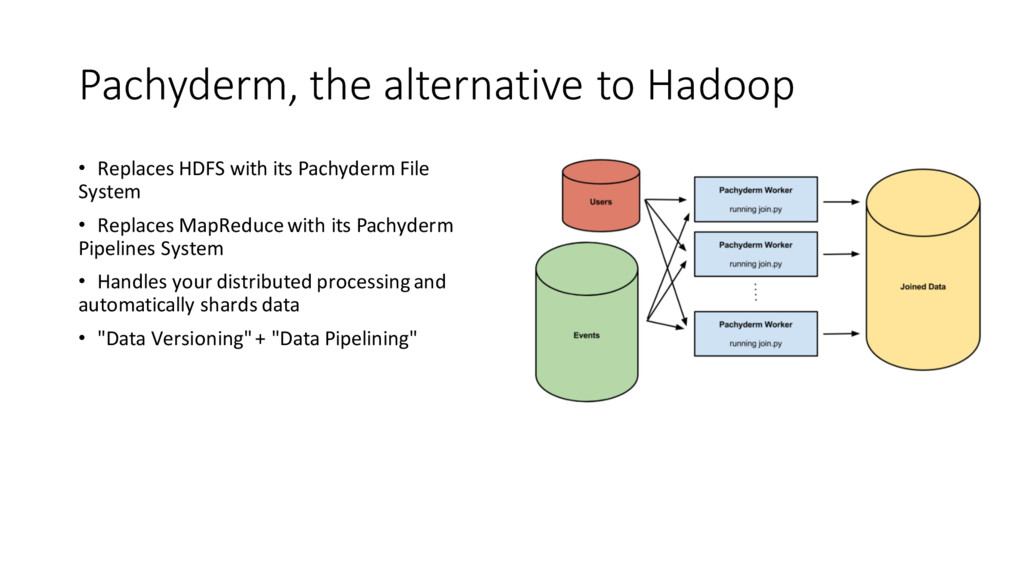{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}