Share
2023/4/25に実施したMLOps Communityイベント「LLM(GPT, PaLM等) with MLOps LT大会!!!」での発表スライドです。 https://mlops.connpass.com/event/279156/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
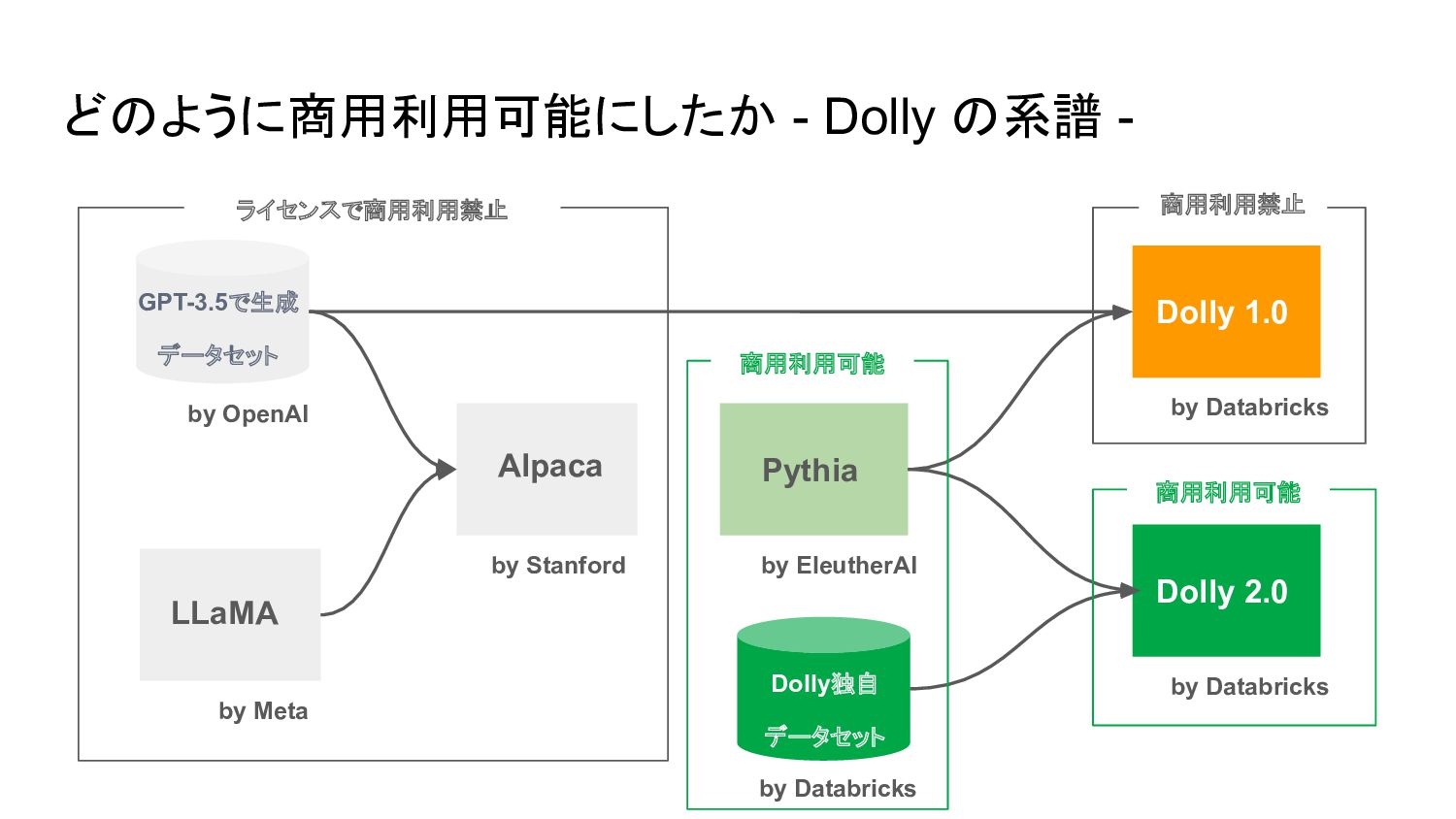{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}