Share
LLM in Production 2023/08/18の登壇資料「LLMプロダクトのロバスト性と運用」です。 https://llm-in-production.connpass.com/event/290321/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![> ܭࢉػՊֶʹ͓͚Δɺϩόετωε (ӳ: robustness)ɺϩόετੑɺݎ࿚ੑͱɺίϯϐϡʔλγεςϜ Ͱ࣮ߦதͷΤϥʔ[1][2]ɺޡͬͨೖྗʹରॲͰ͖Δೳྗͷ͜ͱɻ ݎ࿚ੑʹɺݎ࿚ͳϓϩάϥϛϯάɺ ݎ࿚ͳػցֶशɺݎ࿚ͳηΩϡϦςΟωοτϫʔΫͳͲɺܭࢉػՊֶͷଟ͘ͷ͕ͯ·Δ ϩόετੑͱ フリー百科事典『ウィキペディア(Wikipedia)』ロバストネス (コンピュータ)](https://files.speakerdeck.com/presentations/26640a551d474973adcdb0b71e783f98/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
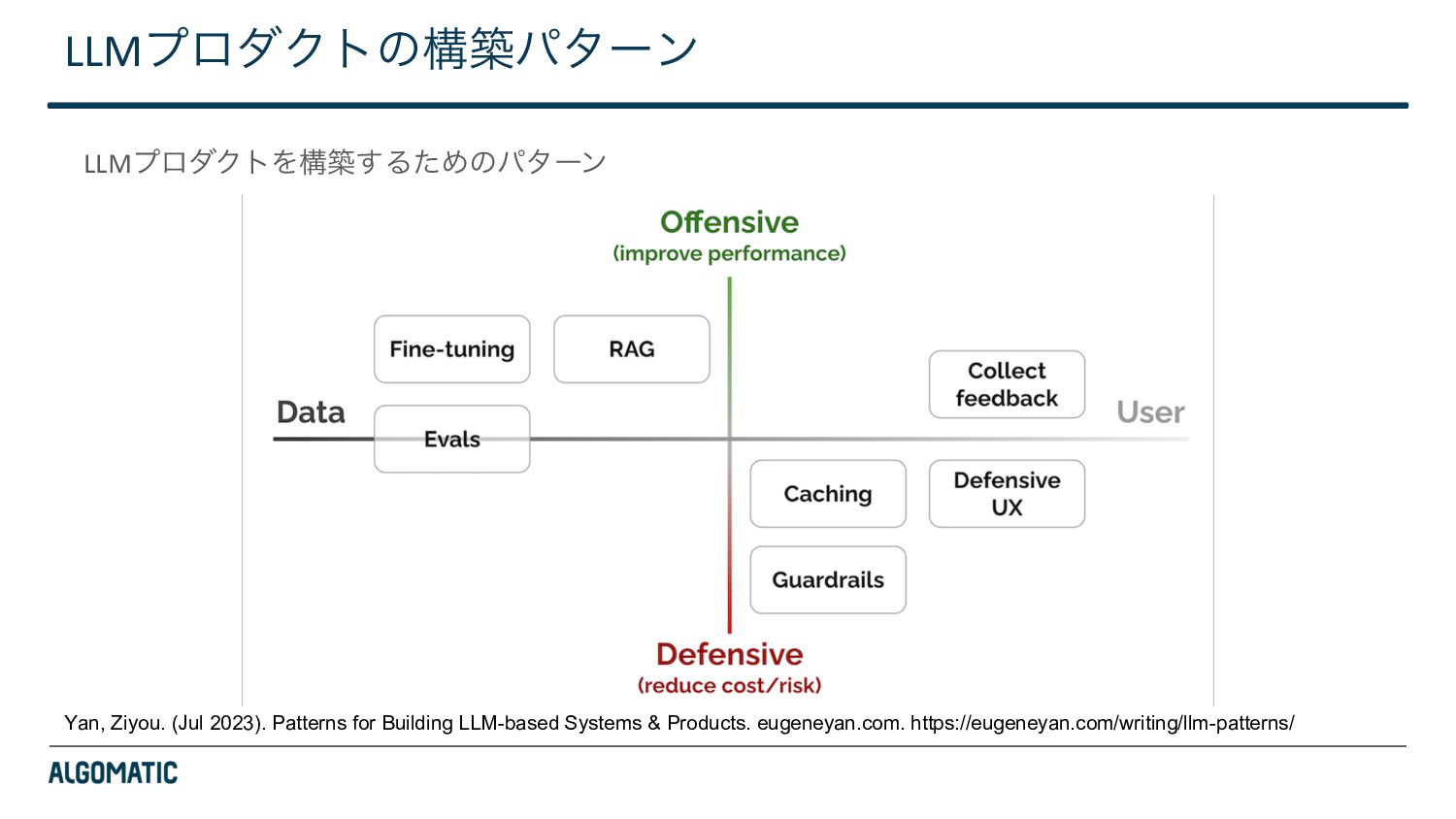{kind=link}
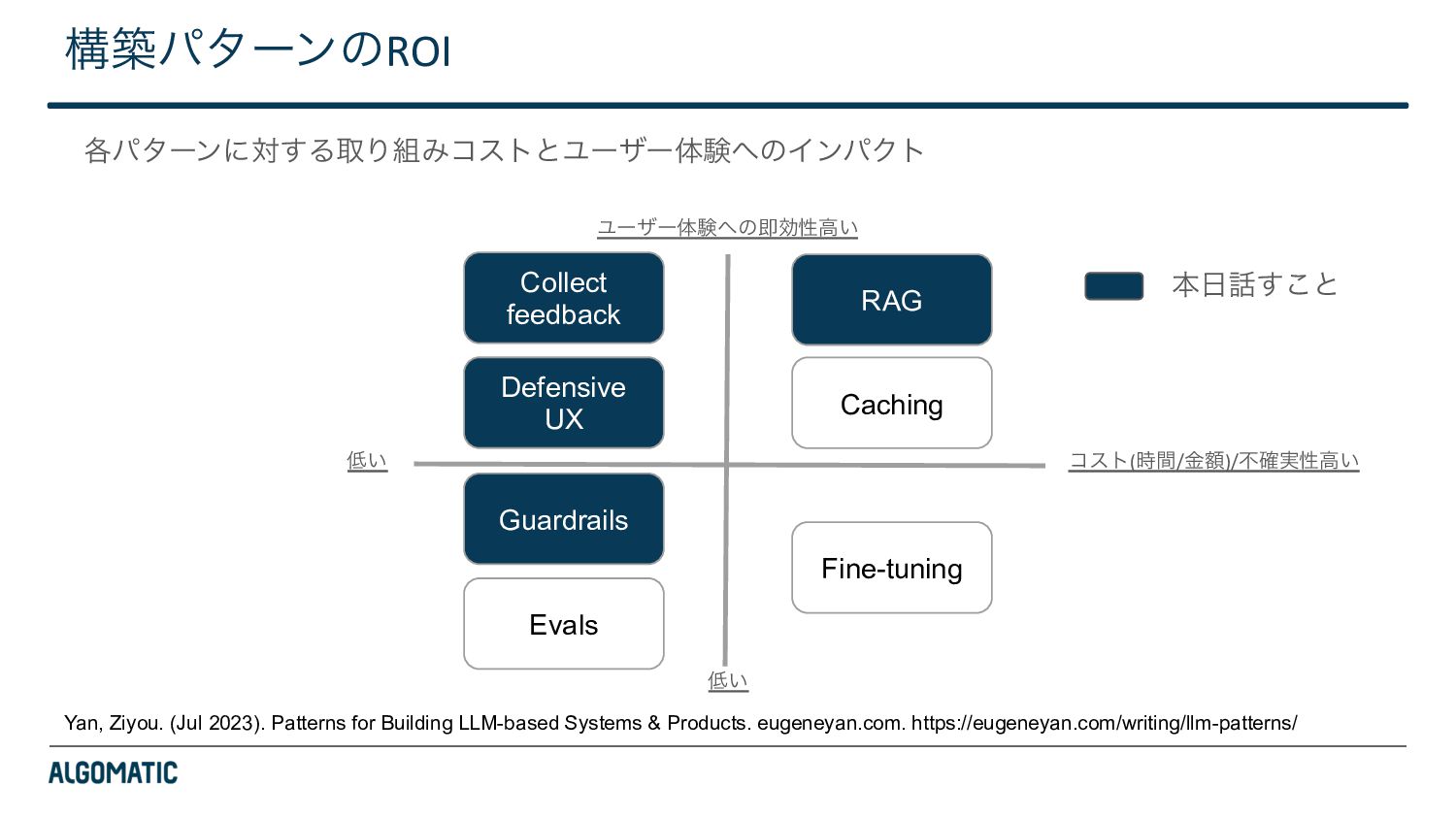{kind=link}
{kind=link}
{kind=link}
{kind=link}
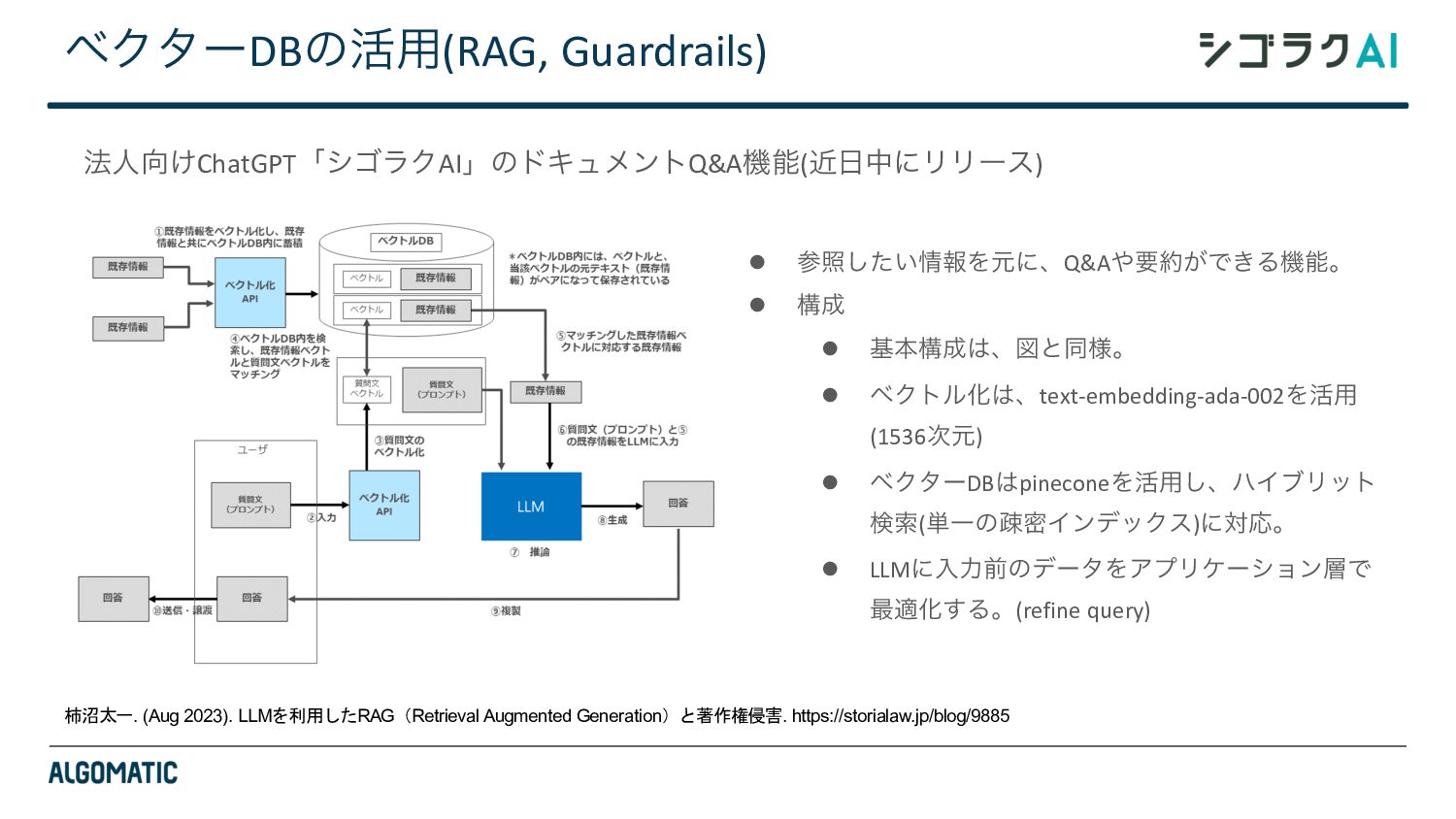{kind=link}
{kind=link}
{kind=link}
{kind=link}
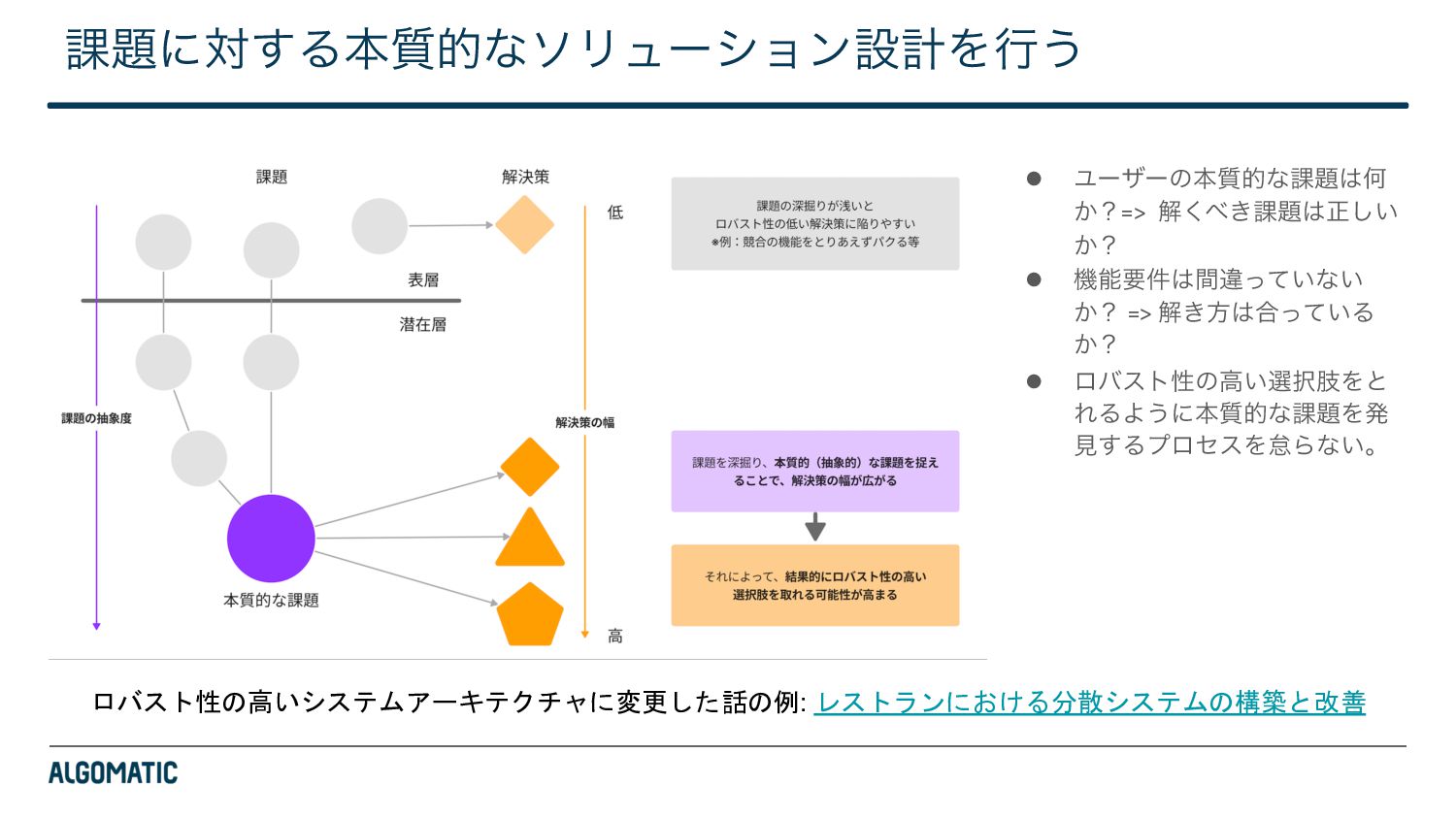{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}