Sysmana 2017 monitorización de logs con el stack ELK
Cómo hacer analítica de los logs que producen las aplicaciones. Introducción teorica y práctica de las tres herramientas ELK(ElasticSearch, Logstash y Kibana).
◦ Proveedor (VirtualBox, VMWare, Docker…) ◦ Aprovisionador (Ansible, Puppet, Chef…) • Funciona con boxes predefinidas https://atlas.hashicorp.com/boxes/search • La definición de la máquina virtual se lee de un fichero de configuración, el Vagrant file 2/36
vagrant ssh # Entrar por ssh a la máquina $ vagrant suspend # Suspender la máquina $ vagrant resume # Despertar la máquina $ vagrant halt # Apagar la máquina $ vagrant status # Saber el estado de la máquina (apagada, ejecutándose o en modo suspensión): $ vagrant destroy # Destruir la máquina A todos los comandos se les puede añadir como argumento el nombre de la máquina, si tenemos varias 5/36
Se conecta a los equipos a configurar usando SSH • Trabaja con un inventario de máquinas a configurar • Existen playbooks o recetas ya configuradas por terceros https://galaxy.ansible.com/ 6/36
desde donde se ejecutarán las tareas • Inventory: archivo donde registramos los servidores sobre los cuales ejecutaremos las tareas • Playbook: archivo donde listamos las tareas a ejecutar, es como una receta de cocina. En formato YAML • Grupo de hosts: si se usa el mismo Playbook para varias máquinas, diferencia entre servidores • Task: bloque dentro del Playbook que define una acción específica a realizar, pj: instalar un paquete. • Module: Plugins que permiten realizar tareas de forma más fácil, como yum para instalar software, y también nosotros podemos crear los nuestros. • Role: una forma de ordenar los diferentes Playbooks. • Play: se refiere a la ejecución de un Playbook. • Facts: variables dentro de Ansible que contienen información sobre los servidores. Ej: SO, RAM, Dirs IP, etc. • Handlers: pequeño código que se usa cuando algo cambia. Por ej: si actualizas el archivo de configuración de Apache, un Handler reiniciará el servicio httpd. 7/36
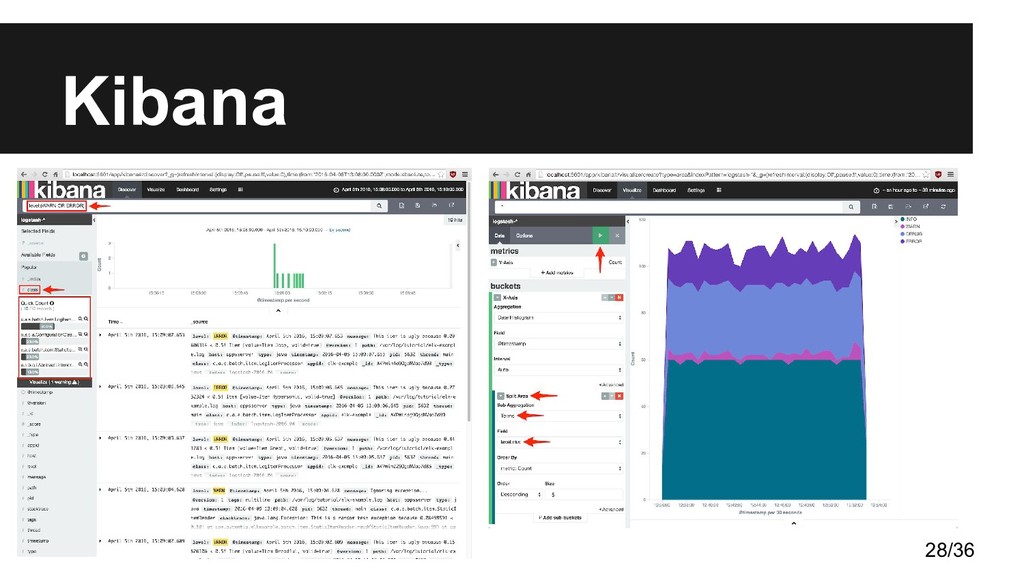
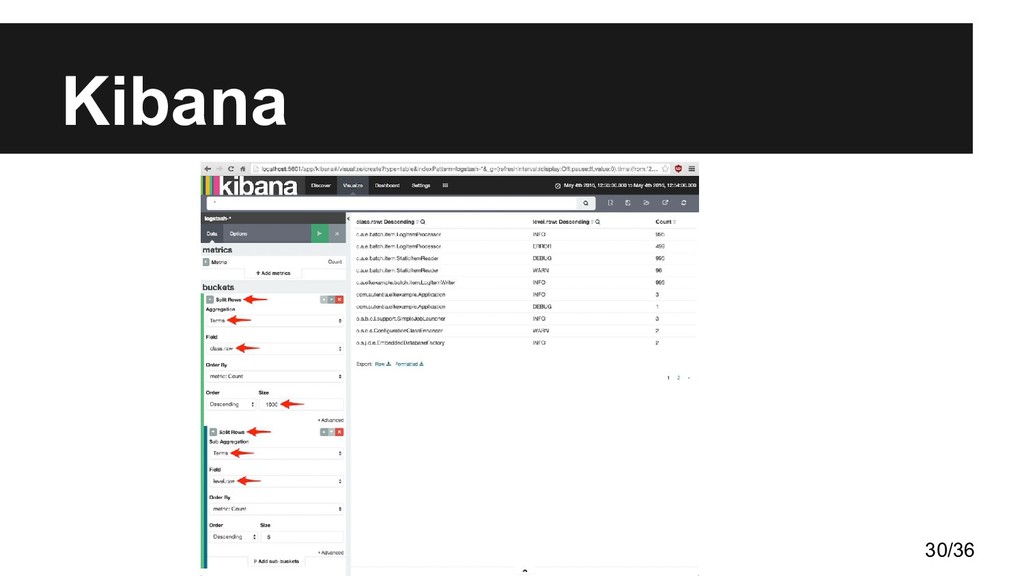
Kibana • Surge como respuesta a la necesidad de analítica • Problema de búsquedas con buenas visualizaciones • Lucene + sist. distribuido ElasticSearch para búsquedas • Normalización de datos con Logstash • Herramienta de visualización de datos Kibana • Tenemos un rival muy duro para soluciones de pago 9/36
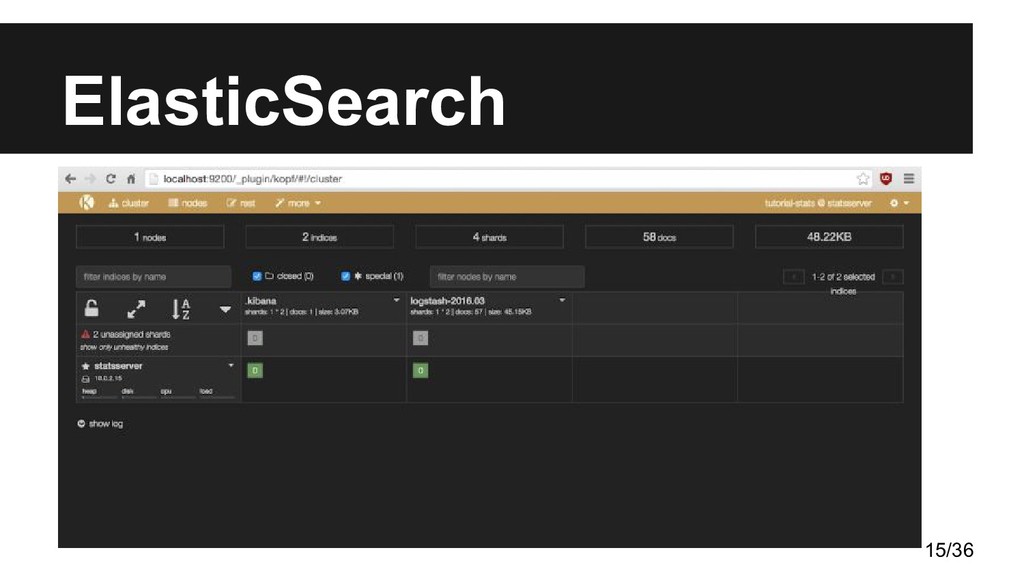
• Proporciona un motor de búsqueda de texto completo, distribuido y con capacidad de multi-tenencia con API REST + JSON • En nuestro ejemplo la usaremos como BBDD donde almacenar, indexar y buscar los eventos de log de las apps • Usuarios ilustres: Wikimedia, Mozilla, Quora, Foursquare, SoundCloud, GitHub, CERN y Stack Exchange
Java ejecutando una instancia del servicio • Límite 40% heap de la RAM • Tipos de nodos ◦ master => responsable de gestión del cluster y asegurar su integridad ◦ master-eligible => nodos candidatos a maestro según se necesite ◦ data => nodos normales conteniendo los datos y haciendo búsquedas ◦ client => enrutan peticiones dentro del clúster ◦ tribe => permiten agregar clústeres de forma transparente
en cluster donde se hacen las búsquedas • Internamente es una instancia de Lucene con sus datos, metadatos e índices • Cada índice tiene un número fijo y predeterminado de shards primarias, que son las fuentes que tienen la info almacenada e indexada en Elasticsearch • Para añadir o quitar shards primarias hay que recrear el índice (reindexar) • Shards de respaldo: copias que se distribuyen por los nodos del cluster para conseguir mayor rendimiento, alta disponibilidad y backup
en tokenizar los textos e intentar detectar otros valores primitivos • Mapping consiste en definir cómo un documento y los campos que contiene son almacenados e indexados. Por ejemplo, usamos mappings para definir: ◦ Qué campos string deberían tratarse como campos de texto ◦ Qué campos contienen números, fechas, localizaciones... ◦ Formato de los campos de fecha ◦ Reglas personalizadas para controlar el mapeado para campos añadidos dinámicamente
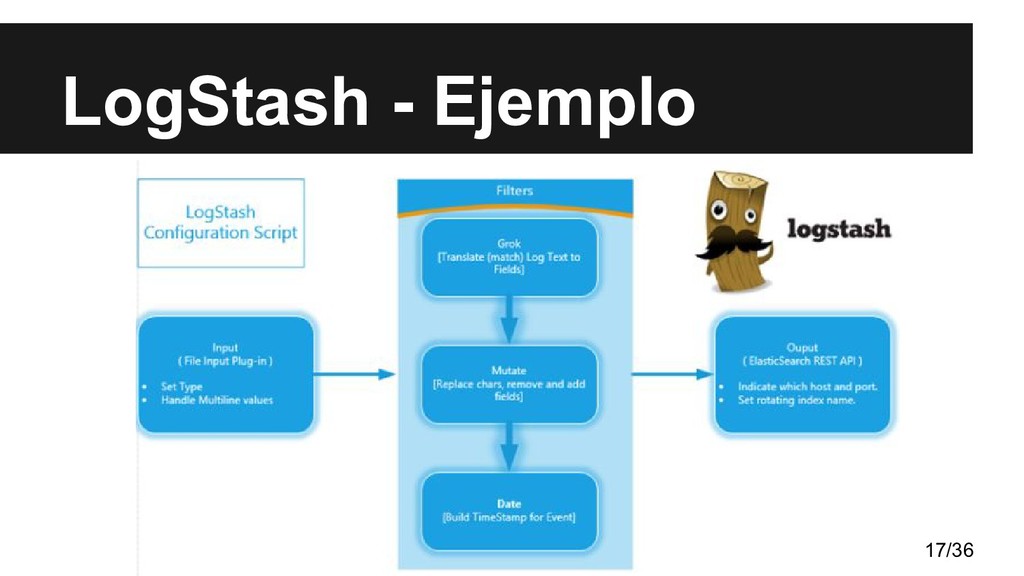
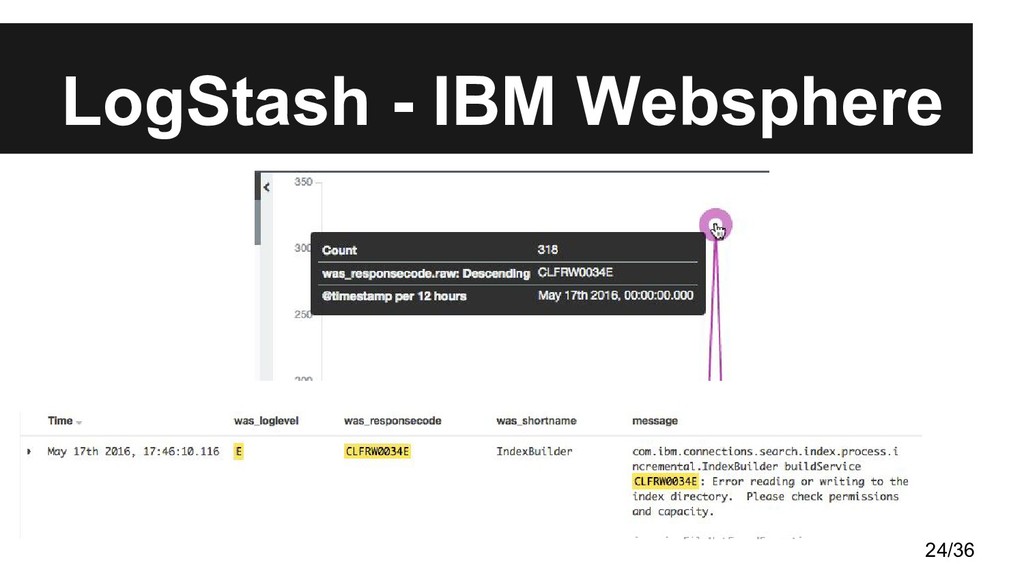
logs • En el caso que nos ocupa los guardaremos en ElasticSearch • La configuración consta de una sección input, una filter y otra output • Todo funciona en base a plugins, las estrellas de esta herramienta
to be regex, because numbers and $ can be in the word match => ["message", "\[%{DATA:wastimestamp} %{WORD:tz}\] %{BASE16NUM:was_threadID} (?<was_shortname>\b[A-Za-z0-9\$]{2,}\b) %{SPACE}%{WORD:was_loglevel}%{SPACE} %{GREEDYDATA:message}"] overwrite => [ "message" ] #tag_on_failure => [ ] } grok { # Extract the WebSphere Response Code match => ["message", "(?<was_responsecode>[A-Z0-9]{9,10})[:,\s\s]"] tag_on_failure => [ ] }
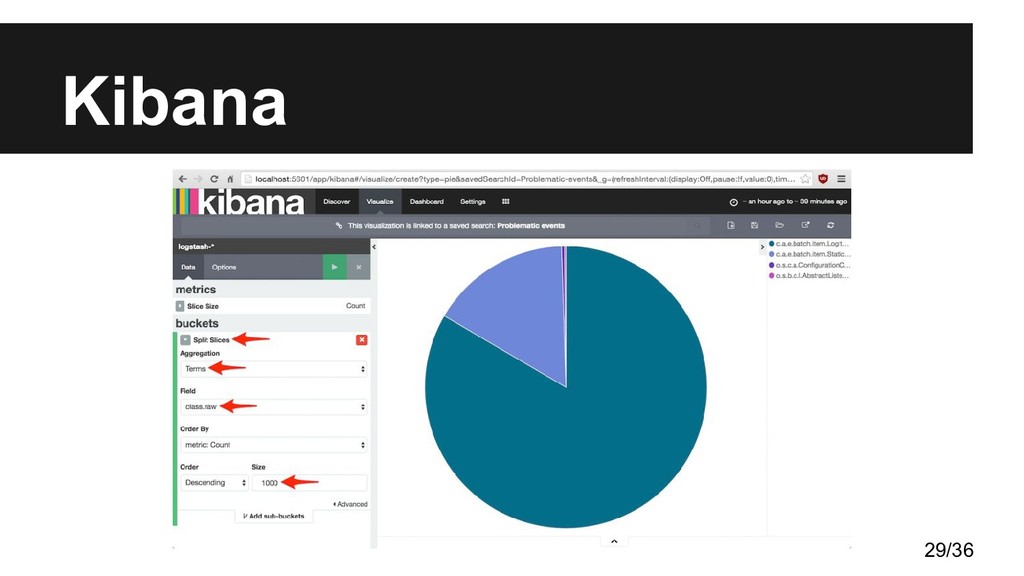
información almacenada en una base de datos • Los usuarios pueden crear gráficos de barras, líneas, tartas, mapas, etc., sobre grandes cantidades de datos • Permite montar tableros de mandos o dashboards a medida según las necesidades 26/36
more https://www.stoeps.de/better-logstash-filter-to-analyze-systemout-log-and-some-more/ • Análisis de logs con Kibana https://www.adictosaltrabajo.com/tutoriales/analisis-de-logs-con-kibana/ • Twitter Elasticsearch example https://github.com/elastic/examples/tree/master/ElasticStack_twitter 35/36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}