Slides from Brian Clapper's presentation at the Philly Area Scala Meetup. Spark Streaming is a scalable, high-throughput, fault-tolerant tool set for consuming continual streams of data using the Apache Spark framework. This talk provides a brief overview of Spark, before jumping into Spark Streaming and what you can do with it.
![ArdenTex Inc. Streaming Brian Clapper ArdenTex Inc. [email protected], @brianclapper](https://files.speakerdeck.com/presentations/f76db35e1e8a45acad5352781a6221bc/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
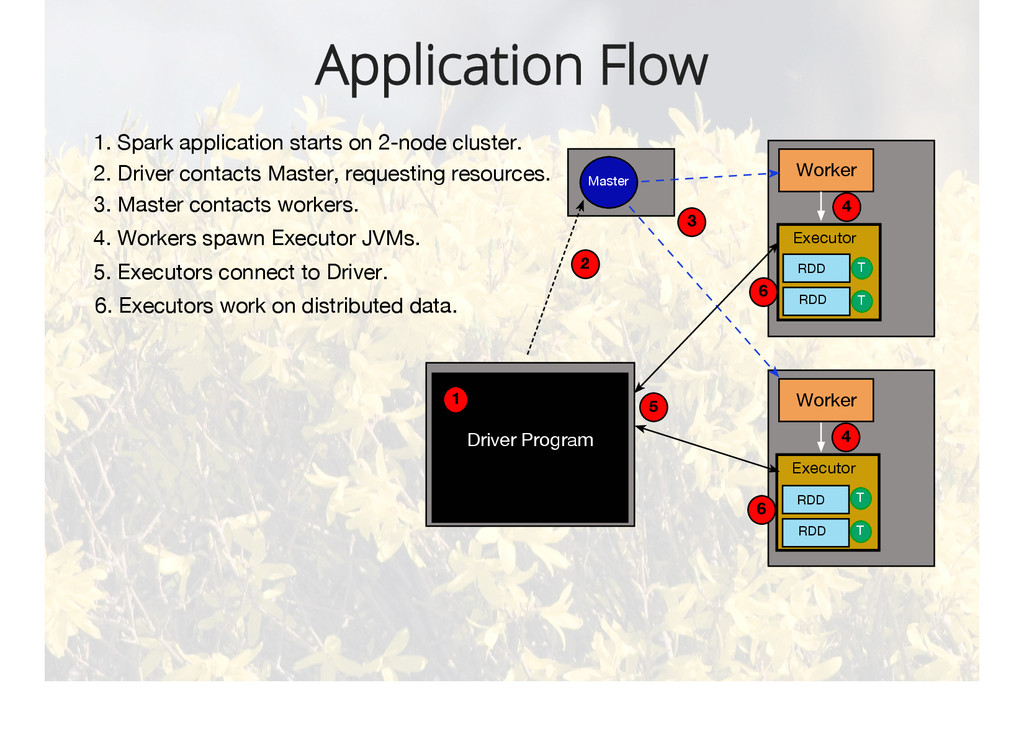{kind=link}
{kind=link}
{kind=link}
{kind=link}
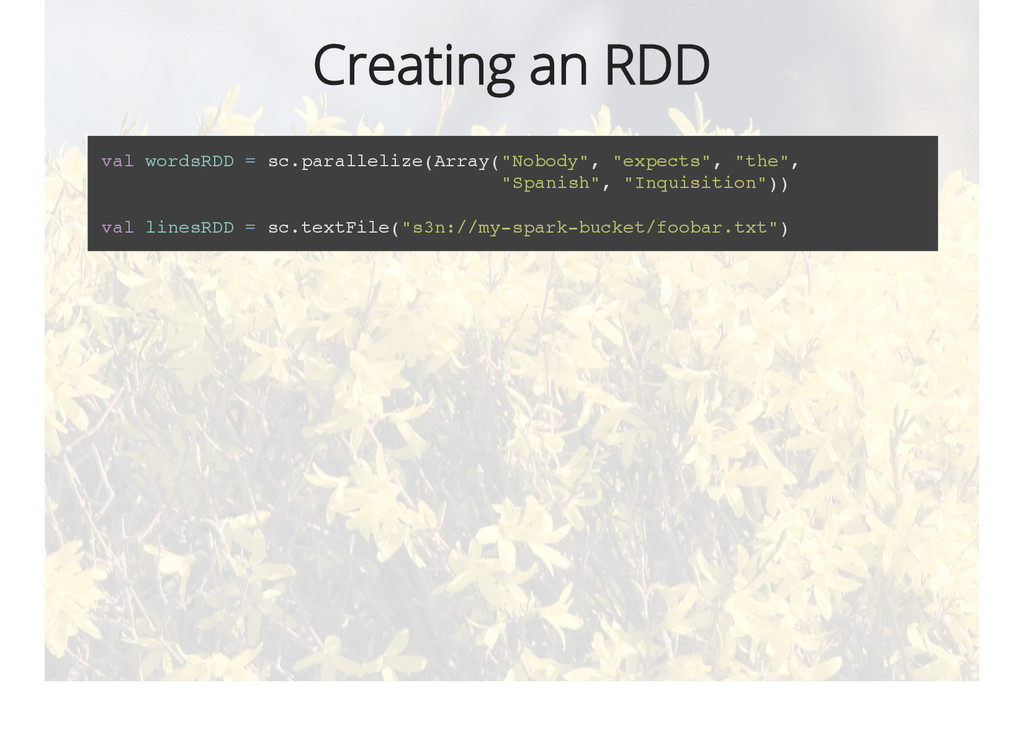{kind=link}
{kind=link}
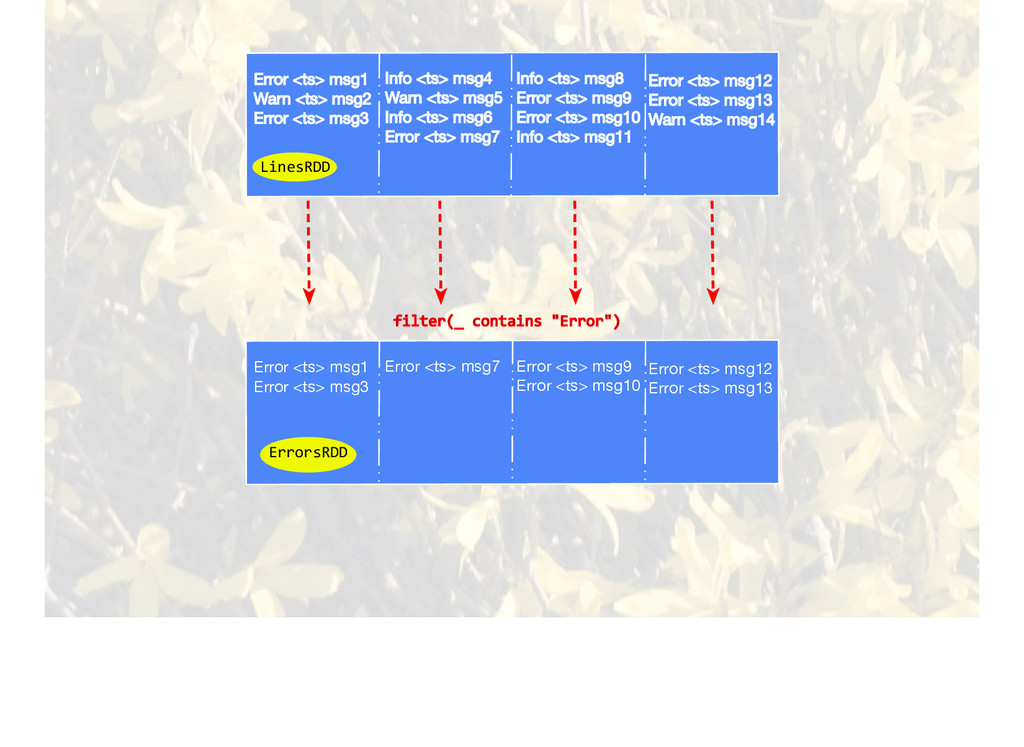{kind=link}
{kind=link}
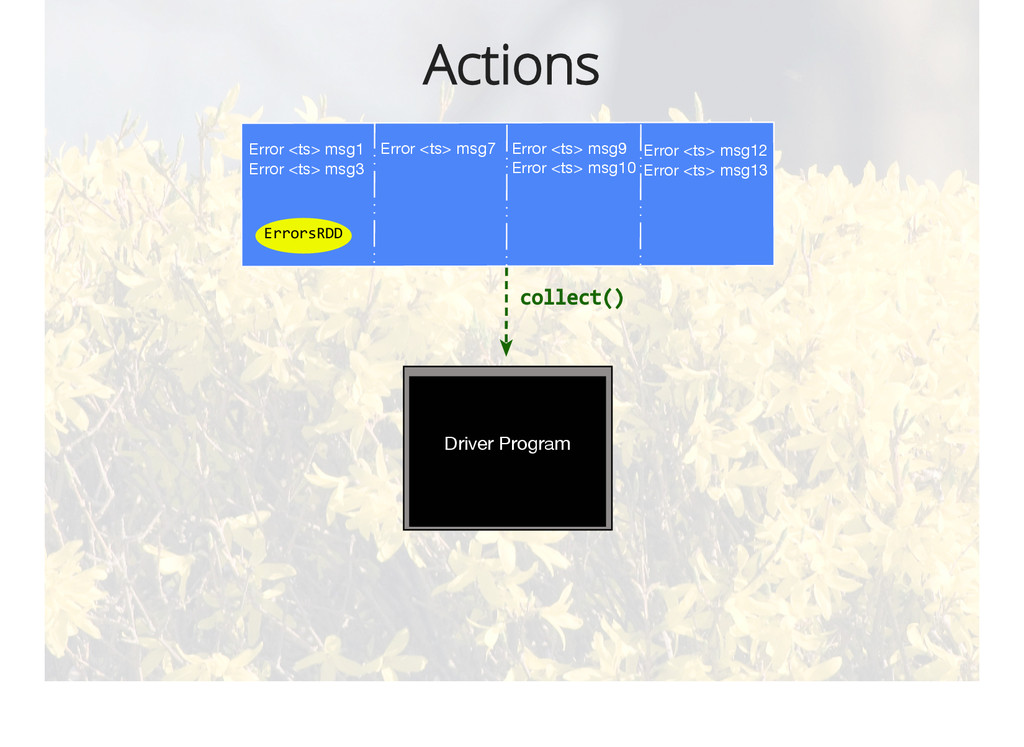{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
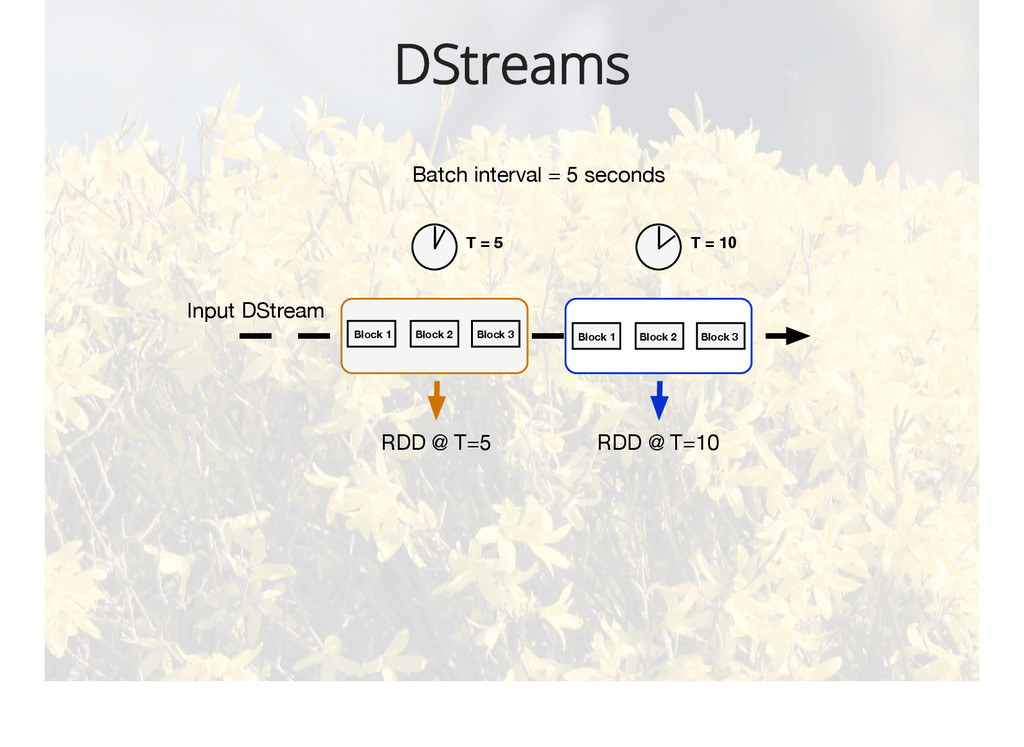{kind=link}
{kind=link}
{kind=link}
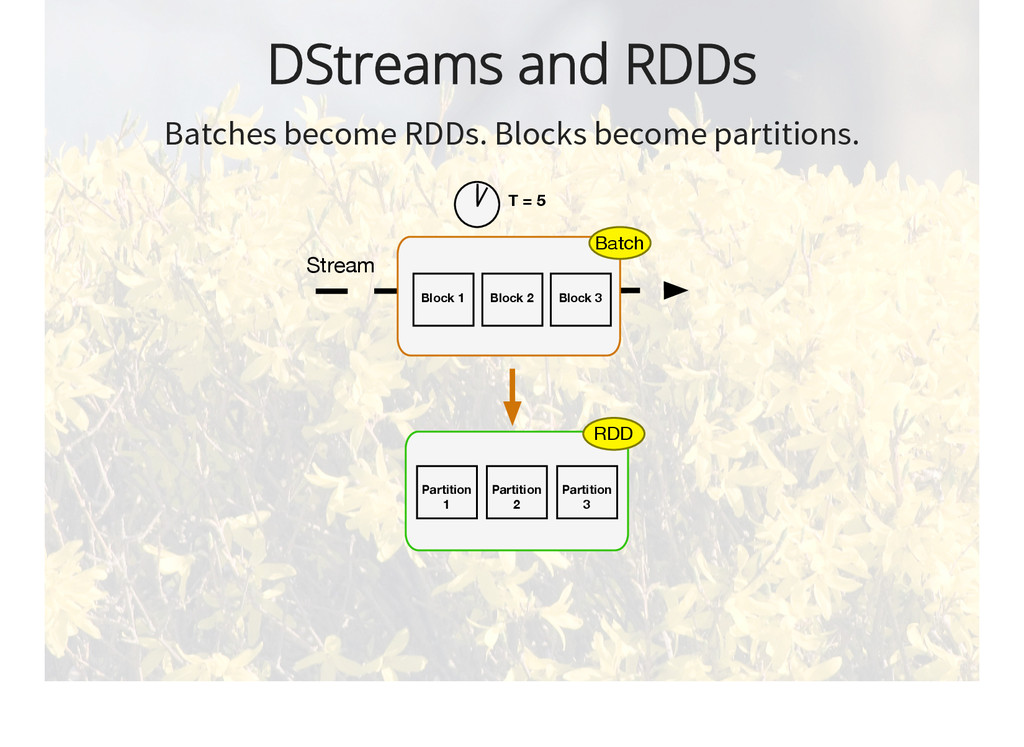{kind=link}
{kind=link}
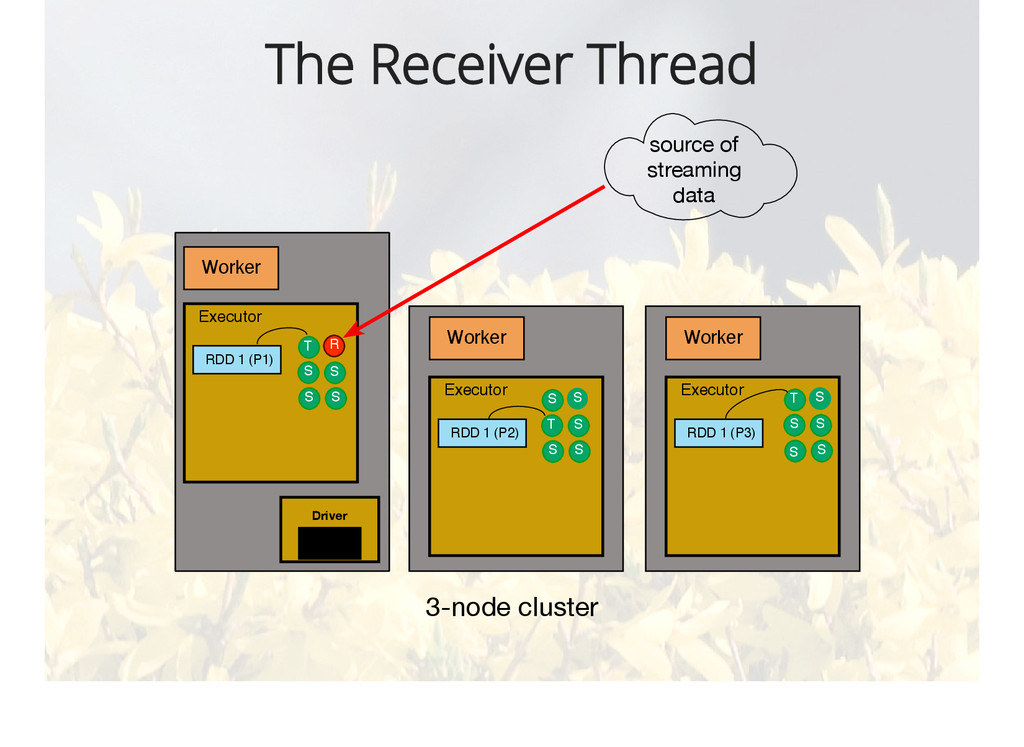{kind=link}
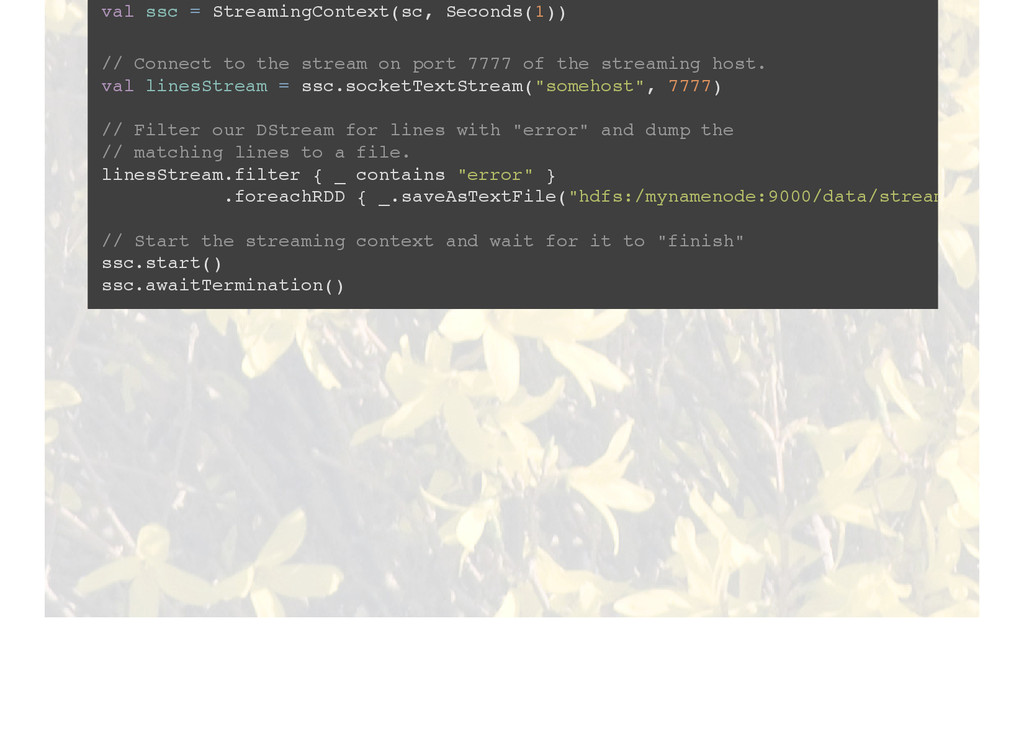{kind=link}
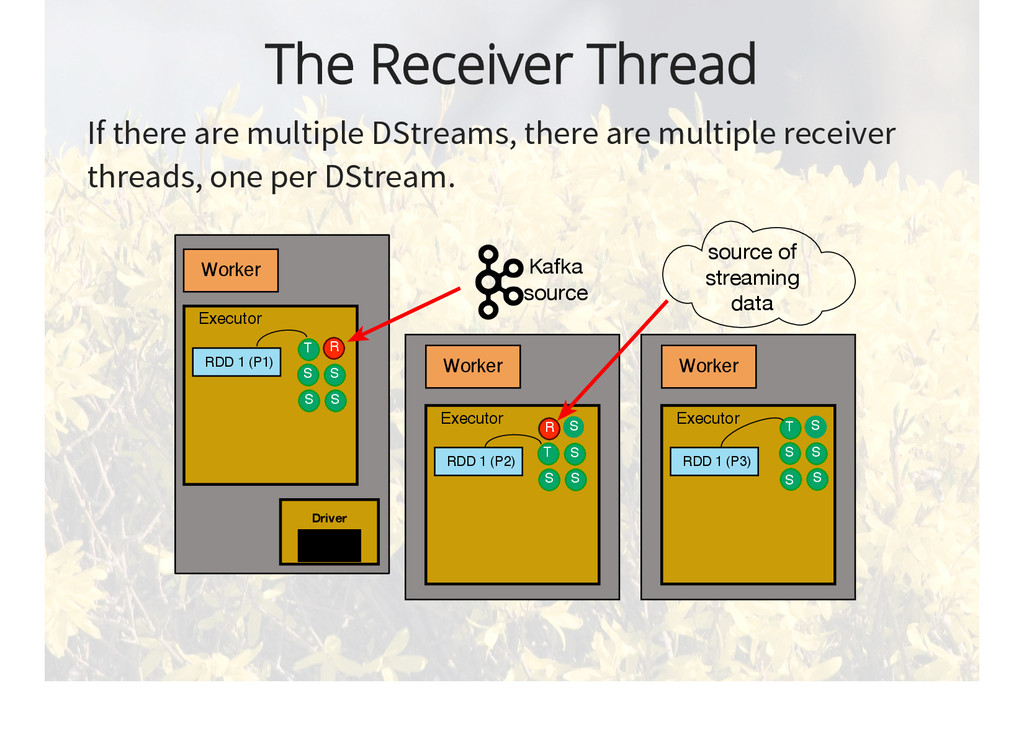{kind=link}
{kind=link}
{kind=link}