A presentation given to the Royal Statistical Society
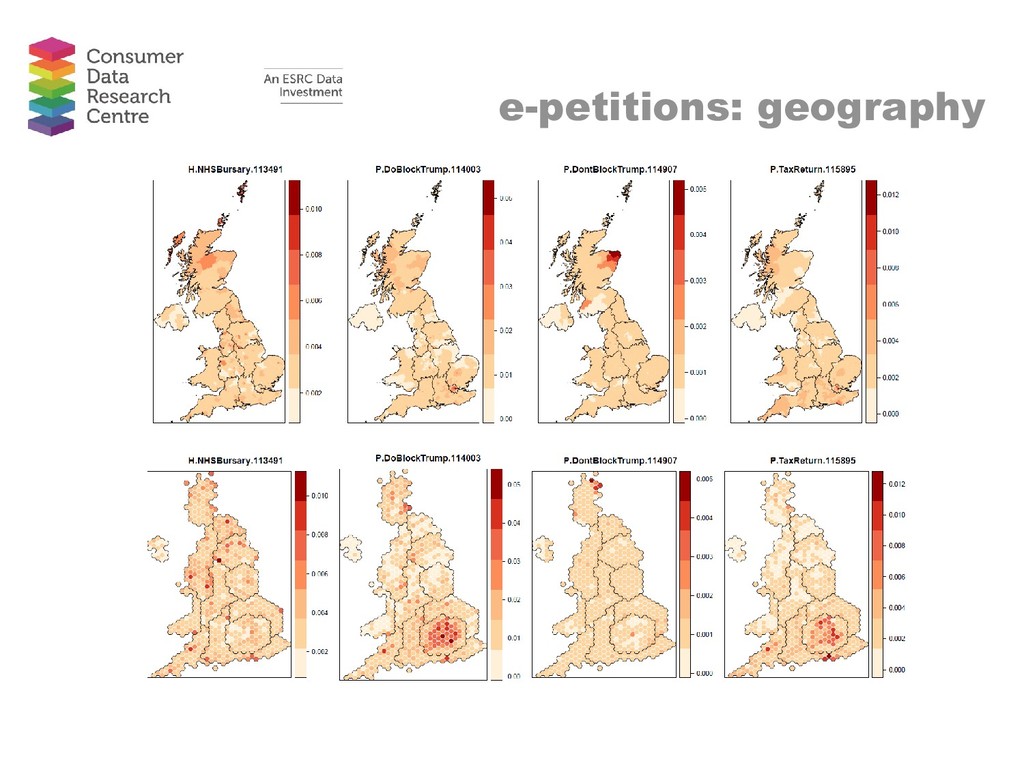
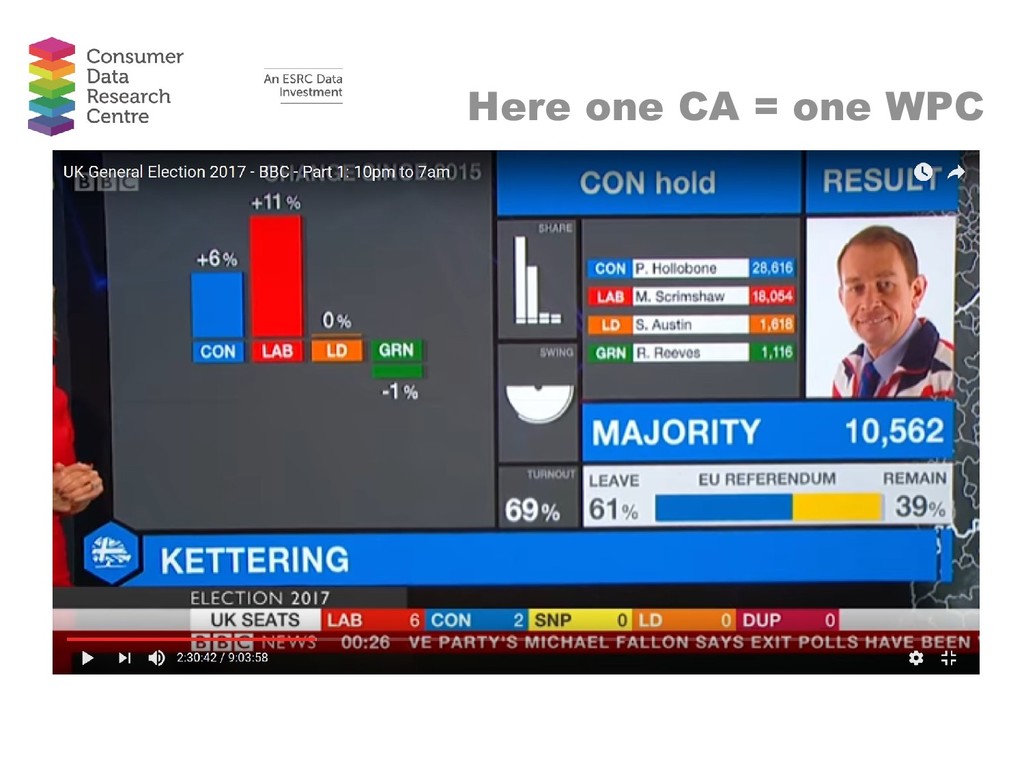
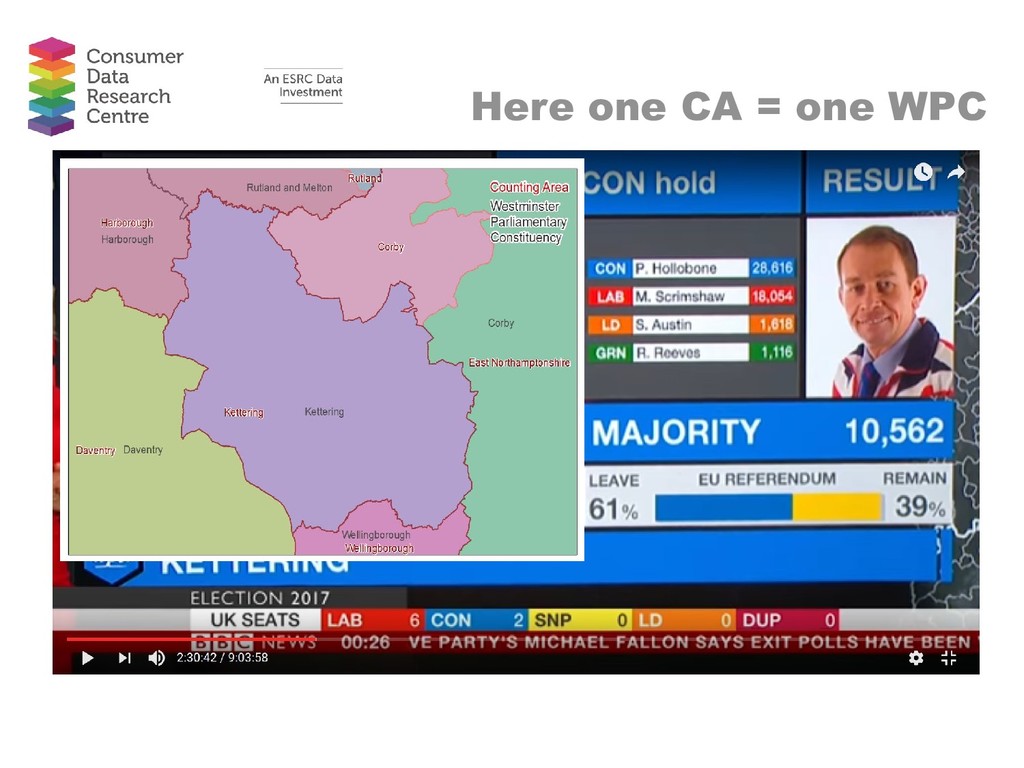
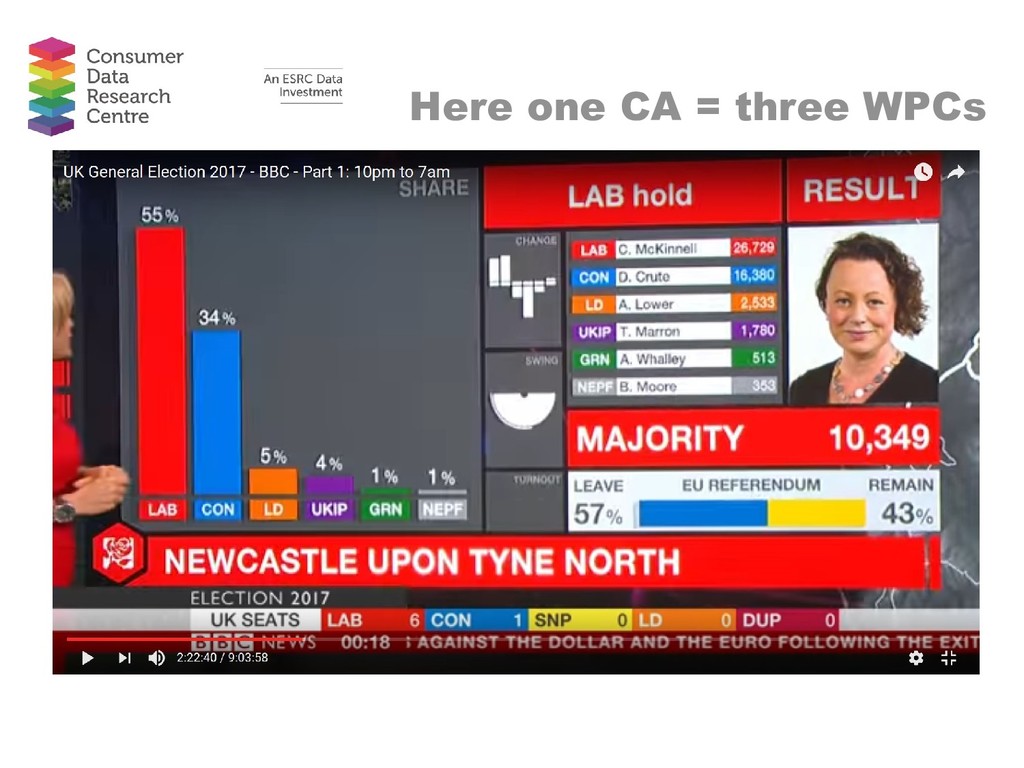
Abstract: There is currently much discussion and hype around the use of big data to provide insight in to a range of phenomena, from consumer behaviour to travel patterns. In this talk, I move away from discussion of big and emerging data to focus on recent work using what I loosely term ‘novel’ data. These are novel in the sense that they are data which are not routinely used in academia but which can provide insight in to local level phenomena and spatial patterns. I provide two substantive examples. The first dataset comes from a commercial provider and reports the characteristics of properties in the sales and rentals market. I use these data to assess local variation in house prices and in rent/price ratios. The second dataset is provided by the UK Government’s e-petitions website. I use these data to estimate the Brexit referendum vote share for Westminster Parliamentary Constituencies and to create a classification of Constituencies based on the types of petitions constituents sign. In both examples I utilise techniques often used on big datasets alongside more conventional techniques. Maps are used as a key tool for interpreting local level variations in both cases. The overall aim of this talk is to highlight that there are a wide range of data available which can provide insight in to spatial patterns which are not routinely used in research. Once we stop worrying about finding big datasets to solve problems, we can focus on applying useful techniques to the range of novel datasets available to us.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
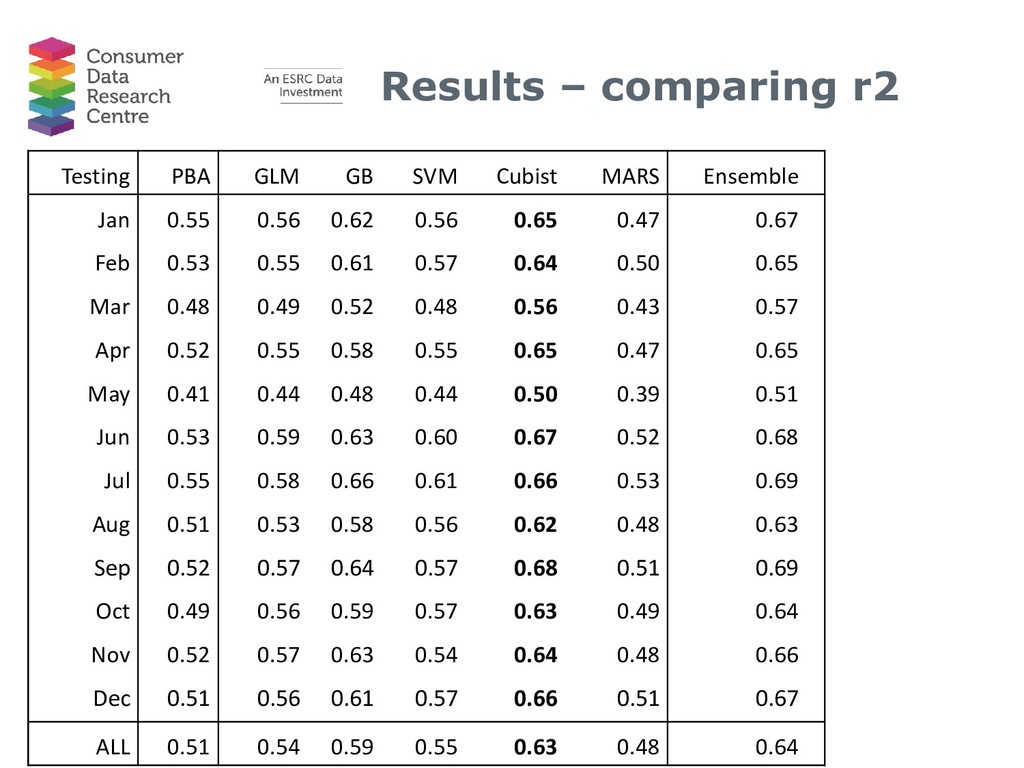{kind=link}
{kind=link}
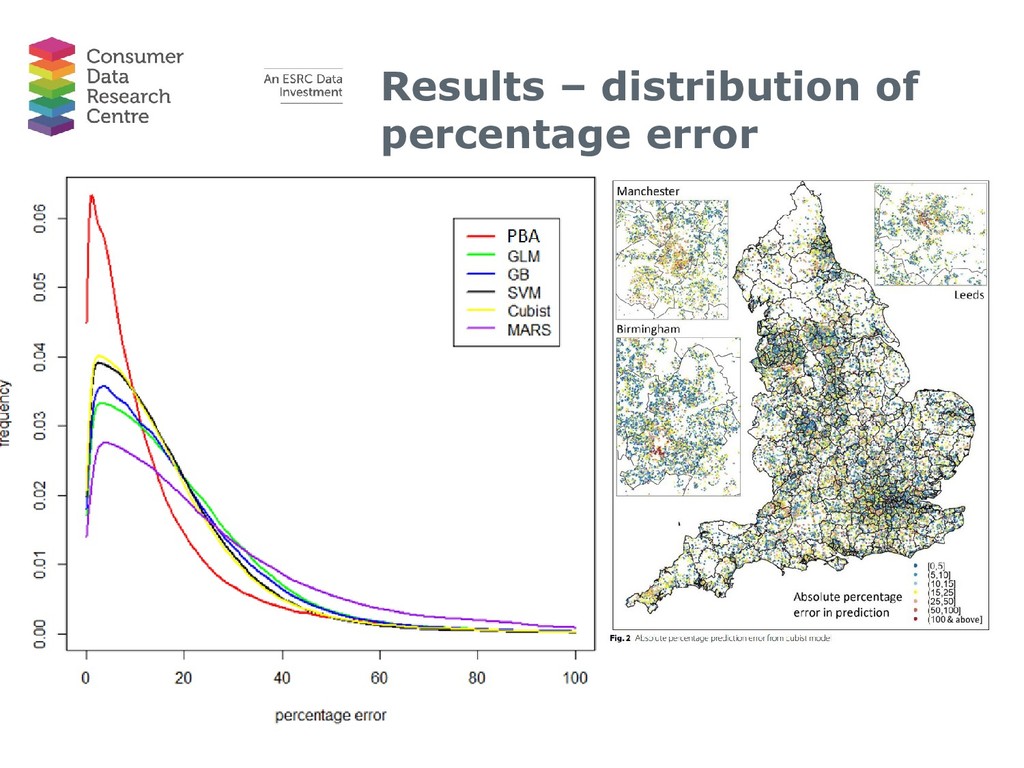{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
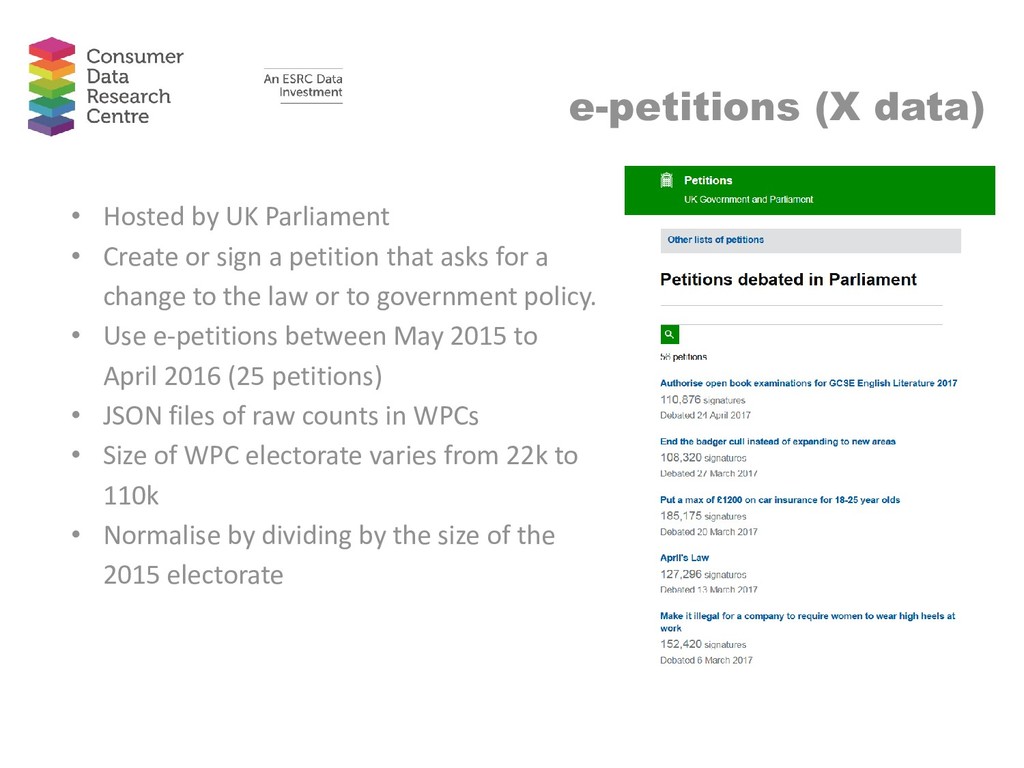{kind=link}
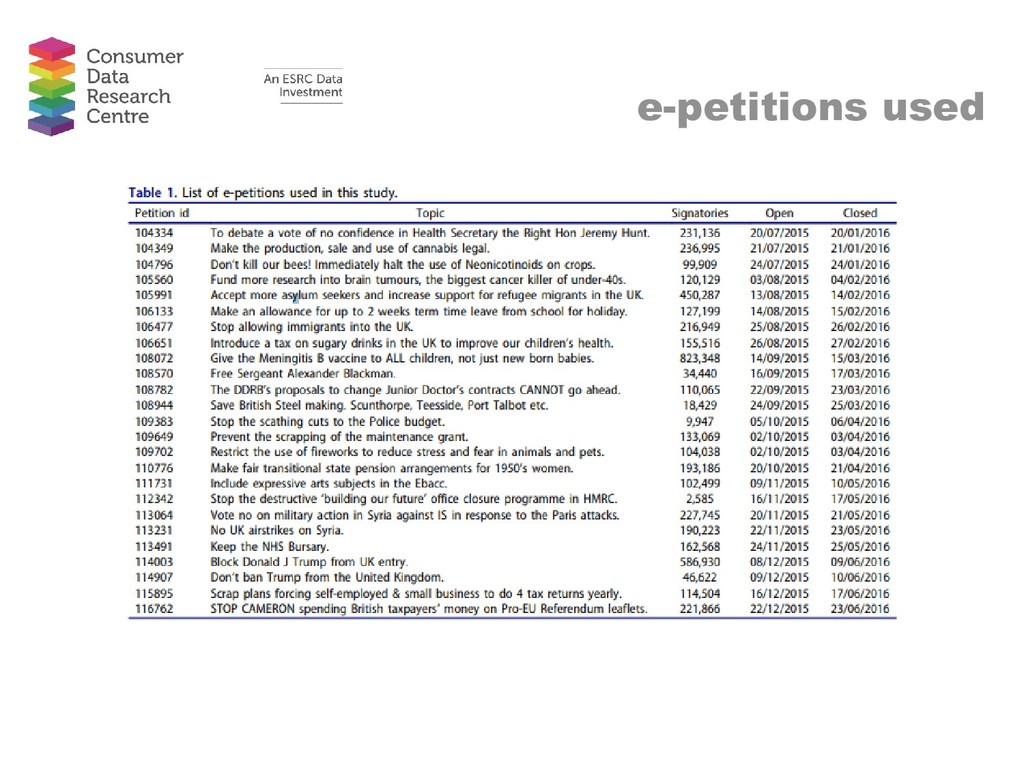{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}