help ensure code quality and codebase health. Using good practices when writing code will support the characteristics of good code, that is: Maintainability, scalability, readability, and portability. “ Code is written once and read thousands of times “ Some good coding practices, such as commenting, don’t affect the functionality of a program. However, they do impact the experience for the humans who’ll be reading and maintaining that code. You may be able to get your program to execute, but if you don’t implement best practices, a quickly done task can backfire by creating confusion and problems in the future.
a software development principle, the main aim of which is to reduce repetition of code. Write Every Time(WET) is an abbreviation to mean the opposite i.e. code that doesn’t adhere to DRY principle. Advantages of DRY? Maintainability: The biggest benefit of using DRY is maintainability. If you have to modify the logic, you have to copy-paste all over the place. By having non-repeated code, you only have to maintain the code in a single place. Also Readability, Reuse, Cost, Testing is easier.
debugging by examining source code before a program is run. It’s done by analyzing a set of code against a set (or multiple sets) of coding rules. Static analysis is commonly used to comply with coding guidelines — such as MISRA. And it’s often used for complying with industry standards — such as ISO 26262. e.g.: MISRA C:1998 MISRA C:1998 was published in 1998 and remains widely used today. It was written for C90. There are 127 coding rules, including: Rule 59: The statement forming the body of an "if", "else if", "else", "while", "do ... while", or "for" statement shall always be enclosed in braces
testing begins. For organizations practicing DevOps, static code analysis takes place during the “Create” phase. Code Smells Code smells indicate a deeper problem, but as the name suggests, they are sniffable or quick to spot. The best smell is something easy to find but will lead to an interesting problem, like classes with data and no behavior. Code smells can be easily detected with the help of tools. Having code smells does not certainly mean that the software won’t work, it would still give an output, but it may slow down processing, increased risk of failure and errors while making the program vulnerable to bugs in the future.
makes it shorter. Simplification + shortness = code that’s easier to simplify and cheaper to support. There’s also more subtle duplication, when specific parts of code look different but actually perform the same job. This kind of duplication can be hard to find and fix.
golden rules used by object-oriented developers since the early 2000s. They set the standard of how to program in OOP languages and now beyond into agile development and more.
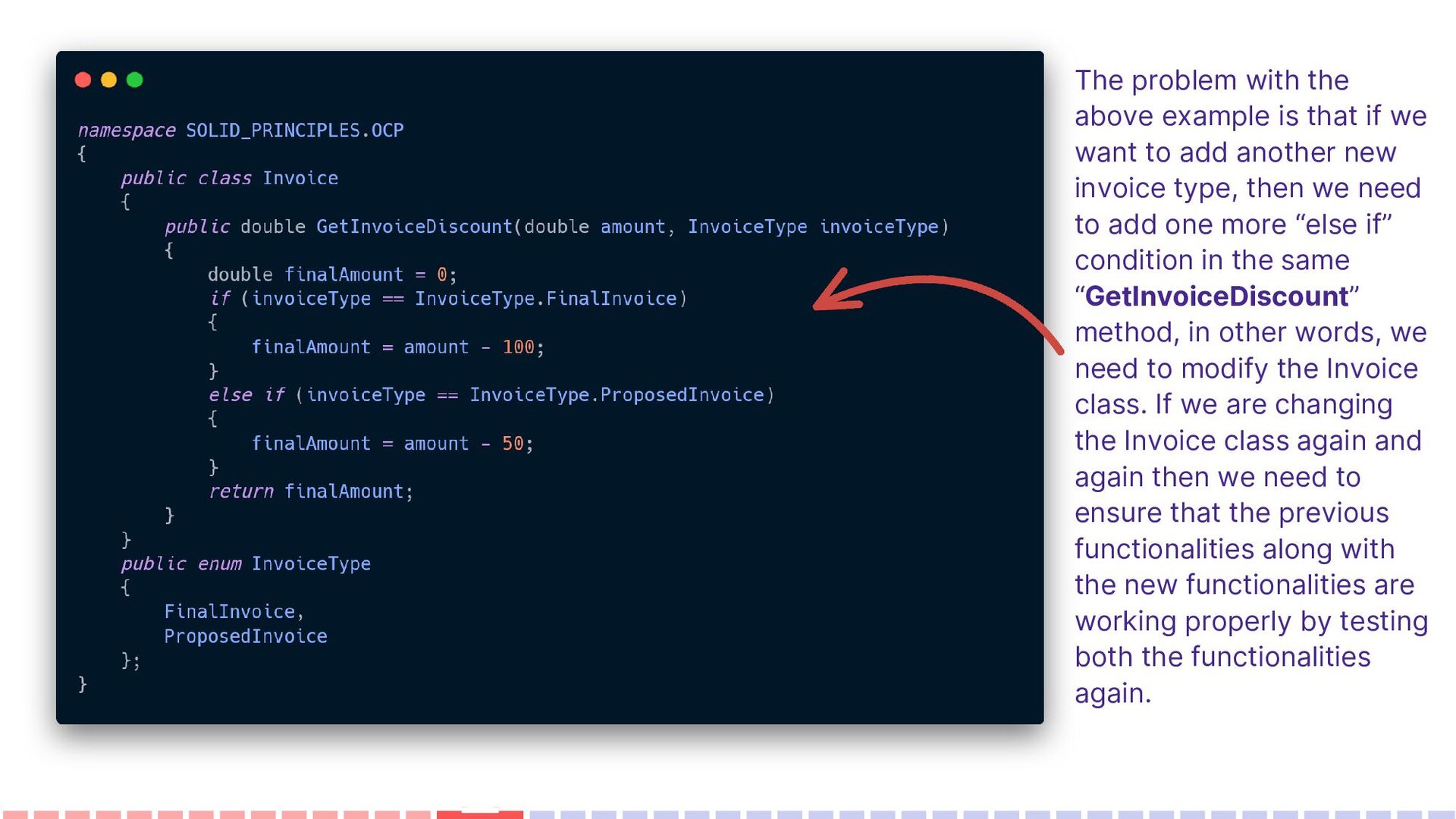
want to add another new invoice type, then we need to add one more “else if” condition in the same “GetInvoiceDiscount” method, in other words, we need to modify the Invoice class. If we are changing the Invoice class again and again then we need to ensure that the previous functionalities along with the new functionalities are working properly by testing both the functionalities again.
created three classes FinalInvoice, ProposedInvoice, and RecurringInvoice. All these three classes are inherited from the base class Invoice and if they want then they can override the GetInvoiceDiscount() method. Tomorrow if another Invoice Type needs to be added then we just need to create a new class by inheriting it from the Invoice class.
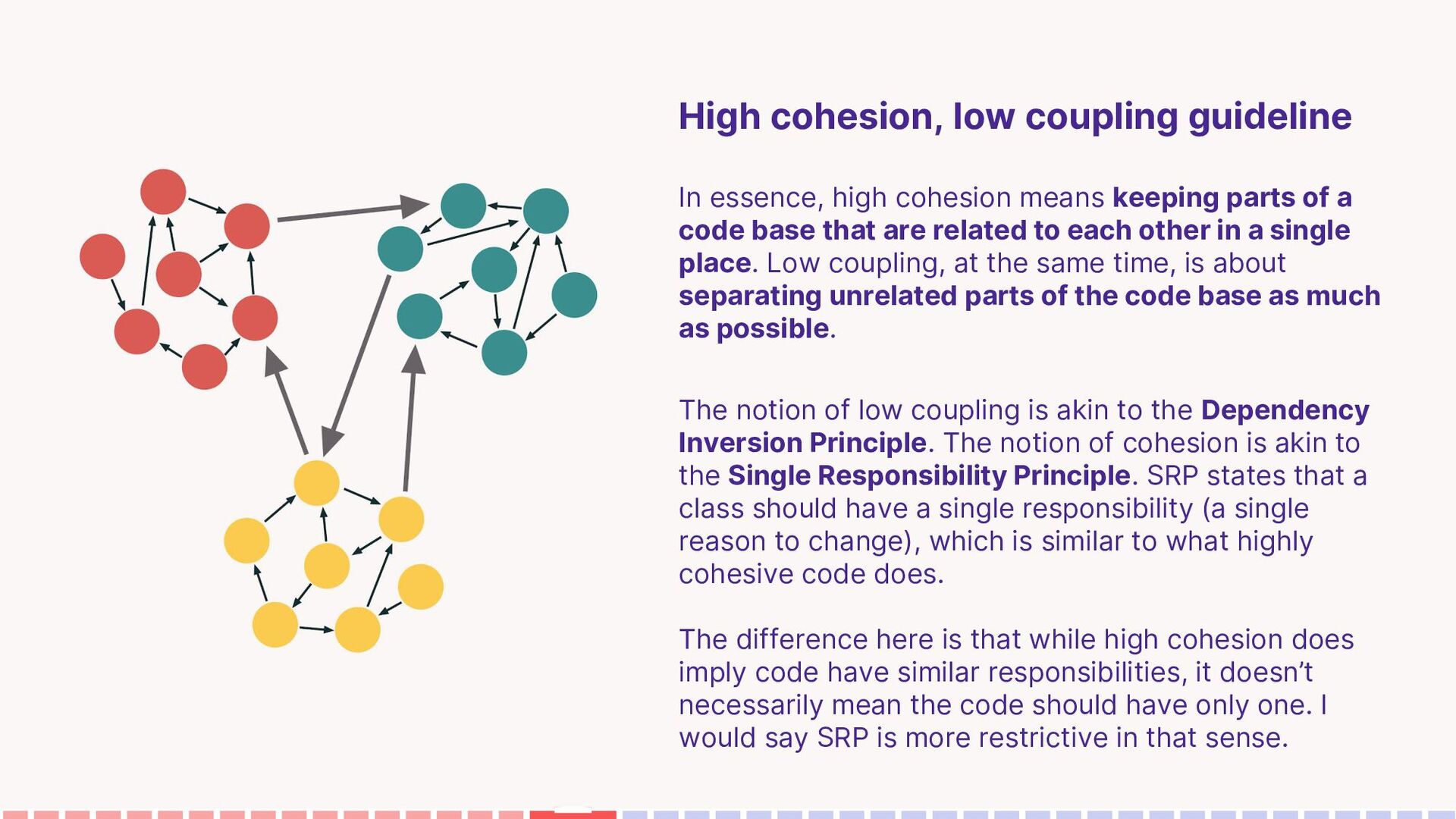
keeping parts of a code base that are related to each other in a single place. Low coupling, at the same time, is about separating unrelated parts of the code base as much as possible. The notion of low coupling is akin to the Dependency Inversion Principle. The notion of cohesion is akin to the Single Responsibility Principle. SRP states that a class should have a single responsibility (a single reason to change), which is similar to what highly cohesive code does. The difference here is that while high cohesion does imply code have similar responsibilities, it doesn’t necessarily mean the code should have only one. I would say SRP is more restrictive in that sense.
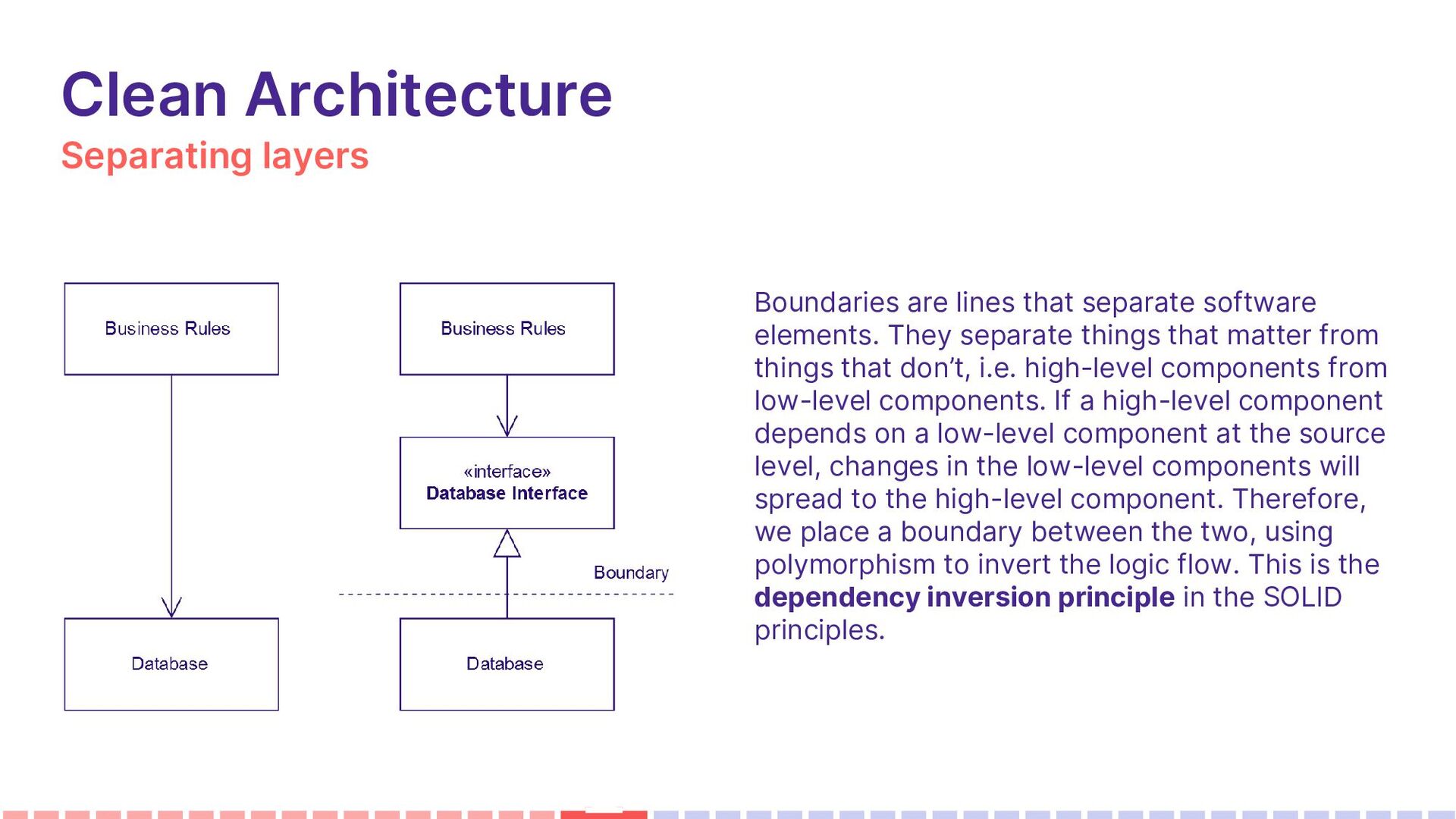
elements. They separate things that matter from things that don’t, i.e. high-level components from low-level components. If a high-level component depends on a low-level component at the source level, changes in the low-level components will spread to the high-level component. Therefore, we place a boundary between the two, using polymorphism to invert the logic flow. This is the dependency inversion principle in the SOLID principles.
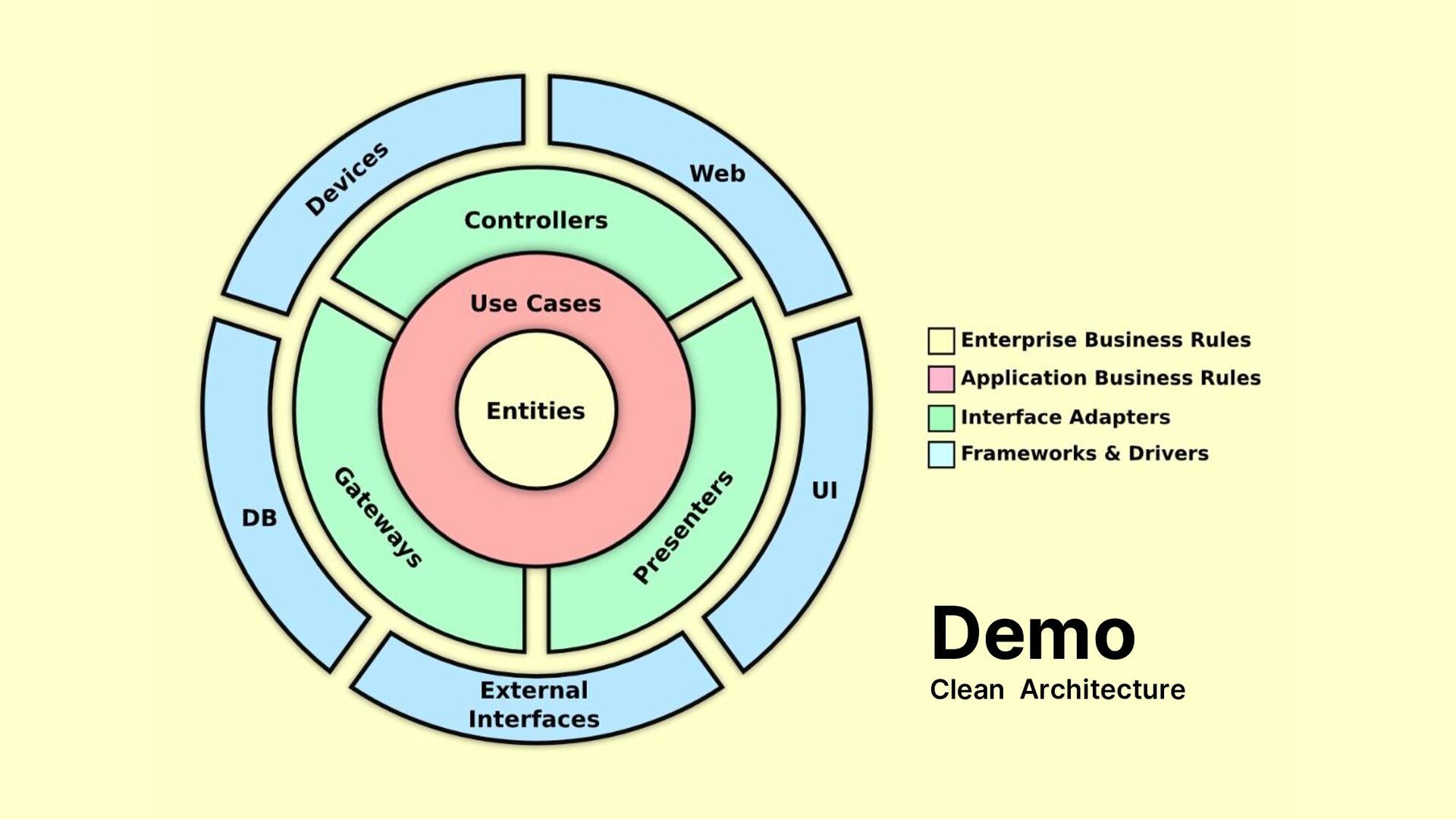
we can organize these components into layers. Layers are concentric and represent how fundamental (or high-level) components are. At the core, we have the high-level policies, i.e. stable and abstract components encapsulating our business rules. On the outer ring, we have the details, for example, unstable and concrete GUI’s. Source-level dependencies should be organized according to the dependency rule: outer layers should depend on inner layers (at the source-level), and not vice versa. We can remove violations of the dependency rule by setting boundaries as explained above. Entities: objects containing critical business logic. For example, a bank could establish that no loans are granted to customers not satisfying some credit score requirements. Entities may be shared across apps in the same enterprise. Use-cases: app-specific business rules. For example, the sequence of screens to execute a bank transfer. Interface adapters: Gateways, presenters and controllers. For example, this layer will contain the MVC architecture of the GUI and also objects that transform data between the format of the database and the use-cases. Frameworks and drivers: web frameworks, database, the view of MVC.
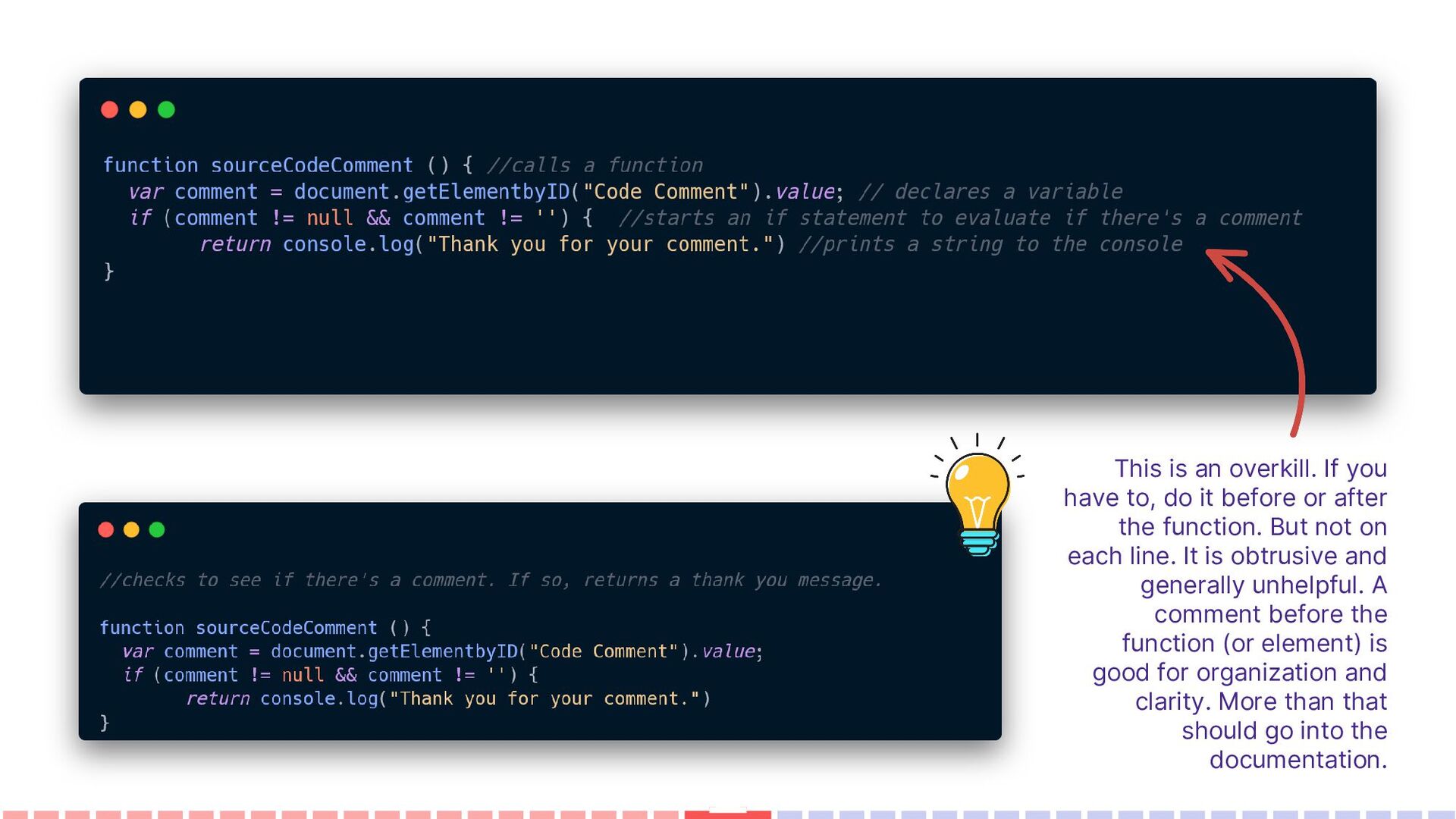
and “why” Comments When reading code, developers typically take the path of least resistance when trying to understand how it works. When provided a function with a comment, most developers will read the comment instead of reading the code itself, especially if the function is long and complex.
before or after the function. But not on each line. It is obtrusive and generally unhelpful. A comment before the function (or element) is good for organization and clarity. More than that should go into the documentation.
only understand 0/1. So, Keep It Simple & Stupid Keep your methods small, each method should never be more than 40-50 lines. Each method should only solve one small problem, not many use cases. If you have a lot of conditions in the method, break these out into smaller methods. It will not only be easier to read and maintain but also can find bugs a lot faster.
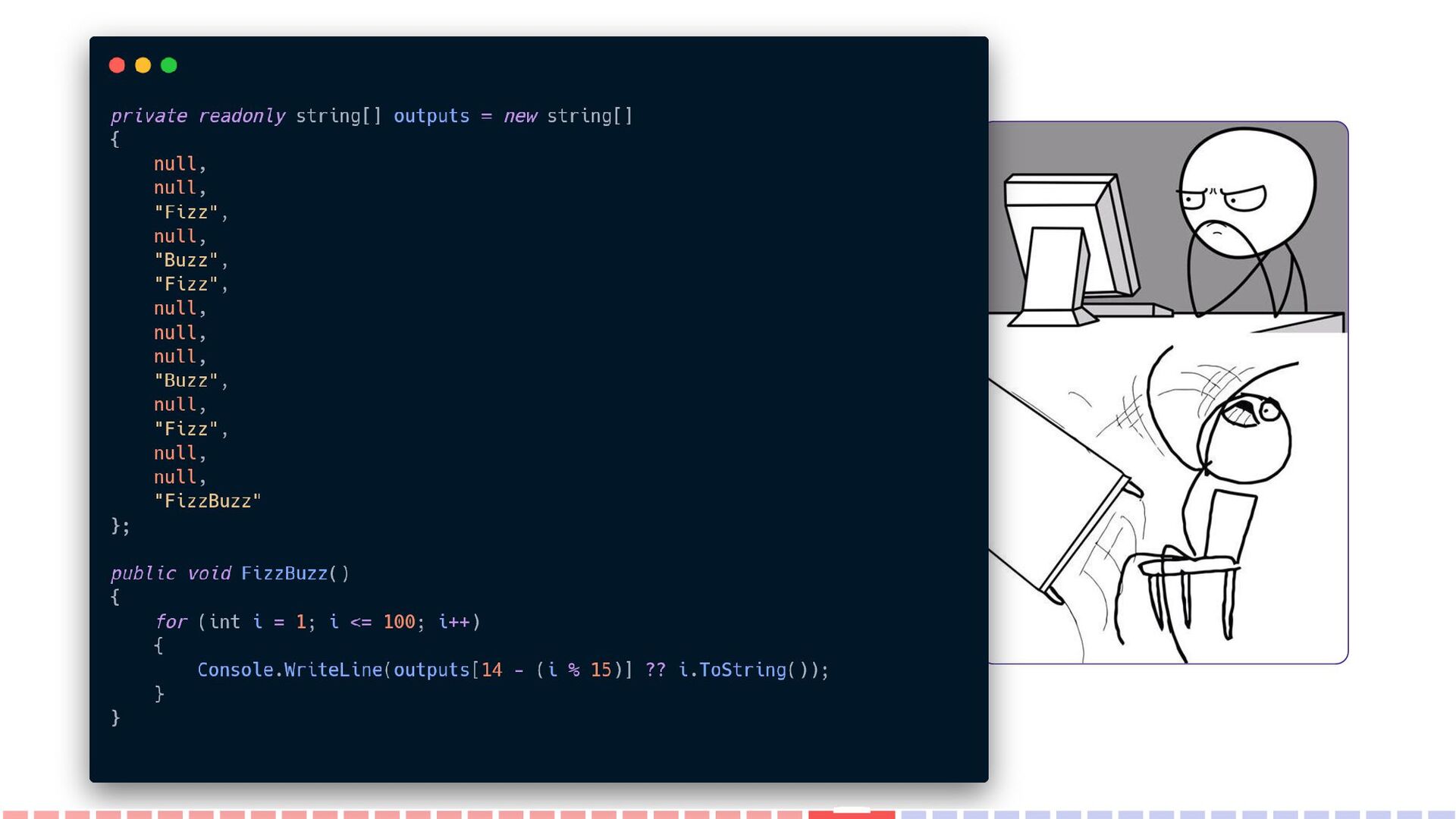
If the current number is divisible by 3, you should print the word "Fizz". • If the current number is divisible by 5, you should print the word "Buzz". • If the current number is divisible by both 3 and 5, you should print the word "FizzBuzz". • If the current number isn't divisible by either 3 or 5, you should print the number.
define it, we assume that we want code to perform better. We say that code optimization is writing or rewriting code so a program uses the least possible memory or disk space, minimizes its CPU time or network bandwidth, or makes the best use of additional cores. Optimization sounds ideal. Ironically, the very aspect of our code we are trying to optimize can be sabotaged by this process, taking out innocent bystanders along the way. Avoid Premature Optimization “Optimize Your Habits, Not Your Code”
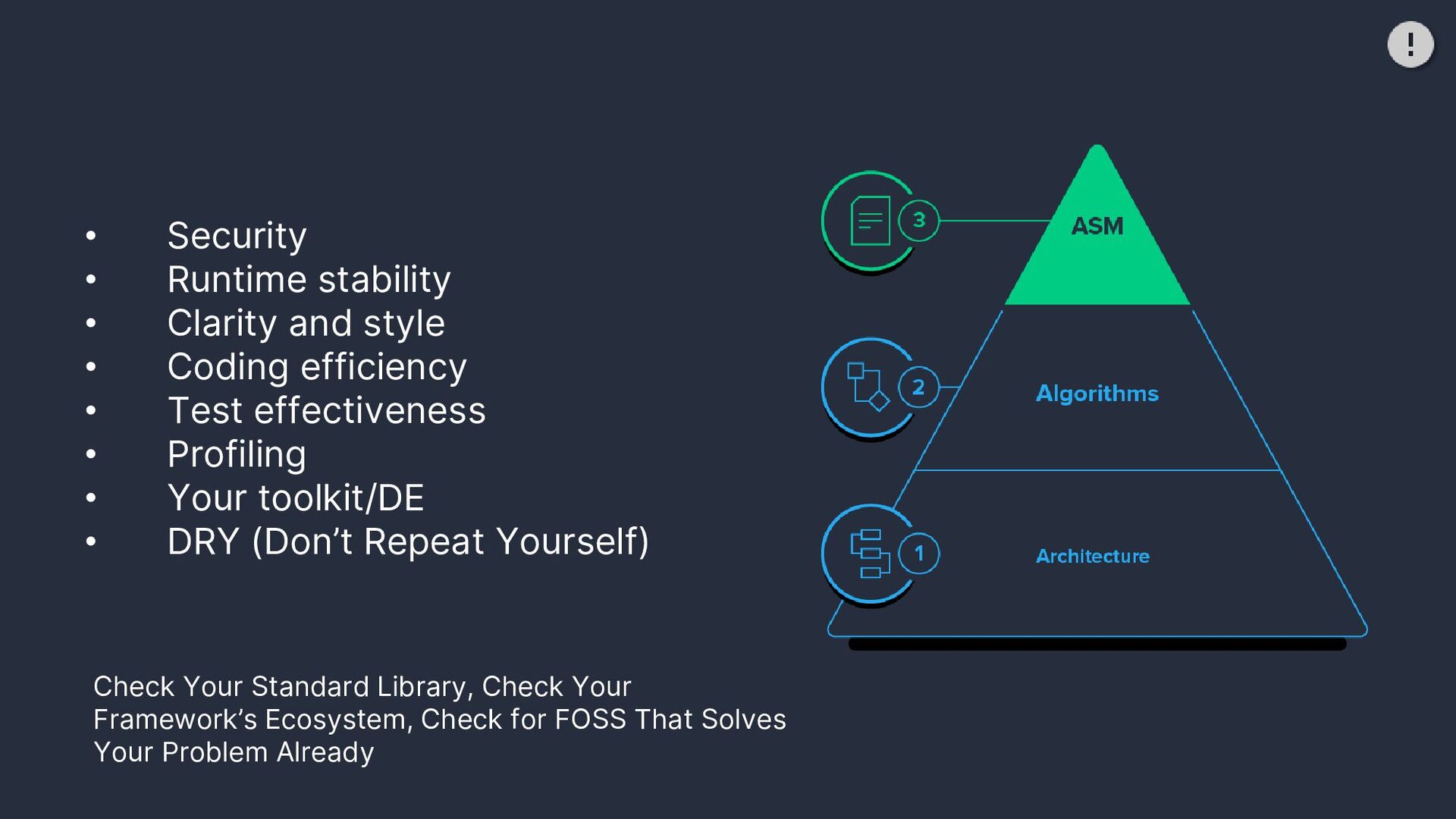
Coding efficiency • Test effectiveness • Profiling • Your toolkit/DE • DRY (Don’t Repeat Yourself) Check Your Standard Library, Check Your Framework’s Ecosystem, Check for FOSS That Solves Your Problem Already
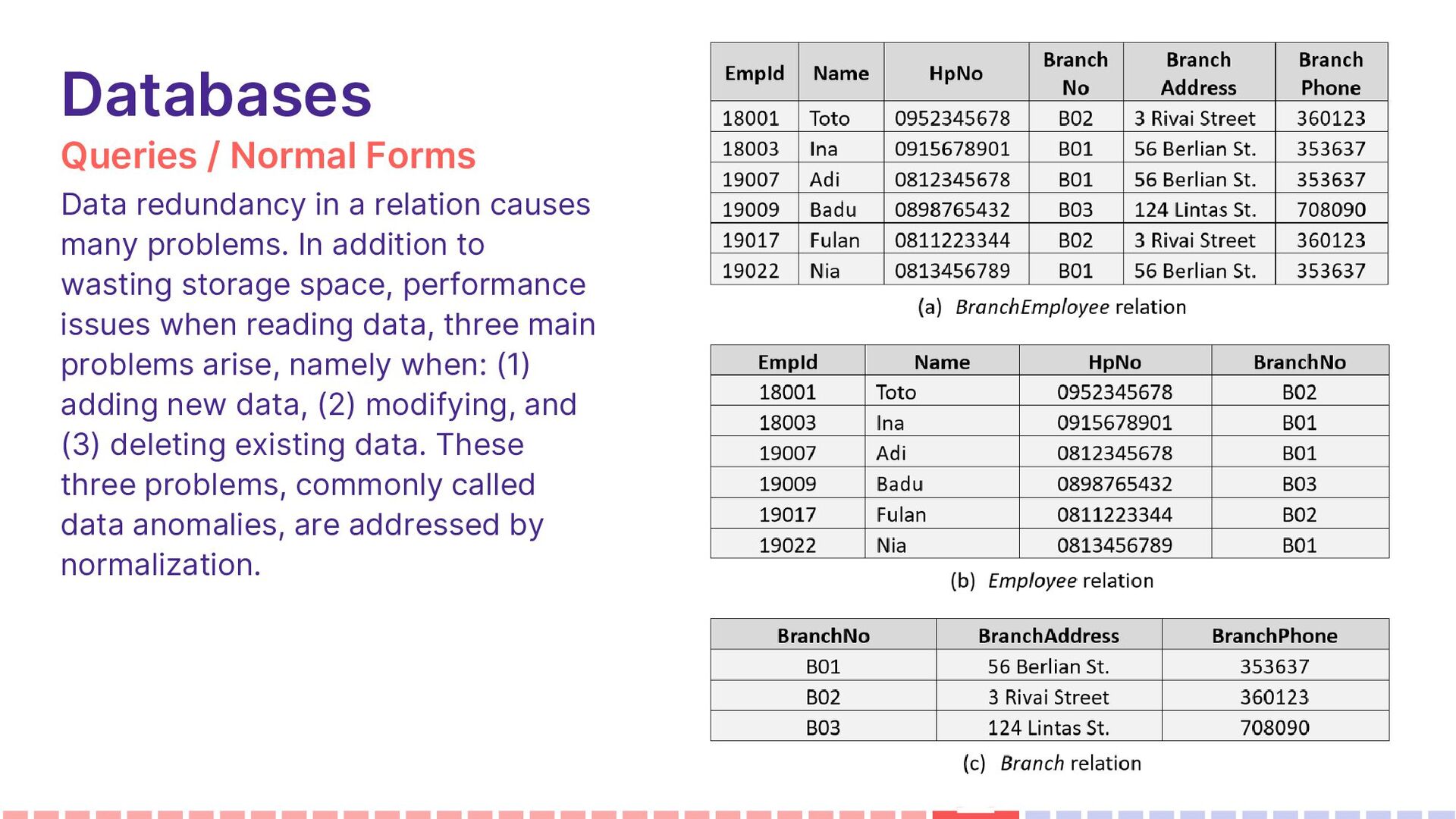
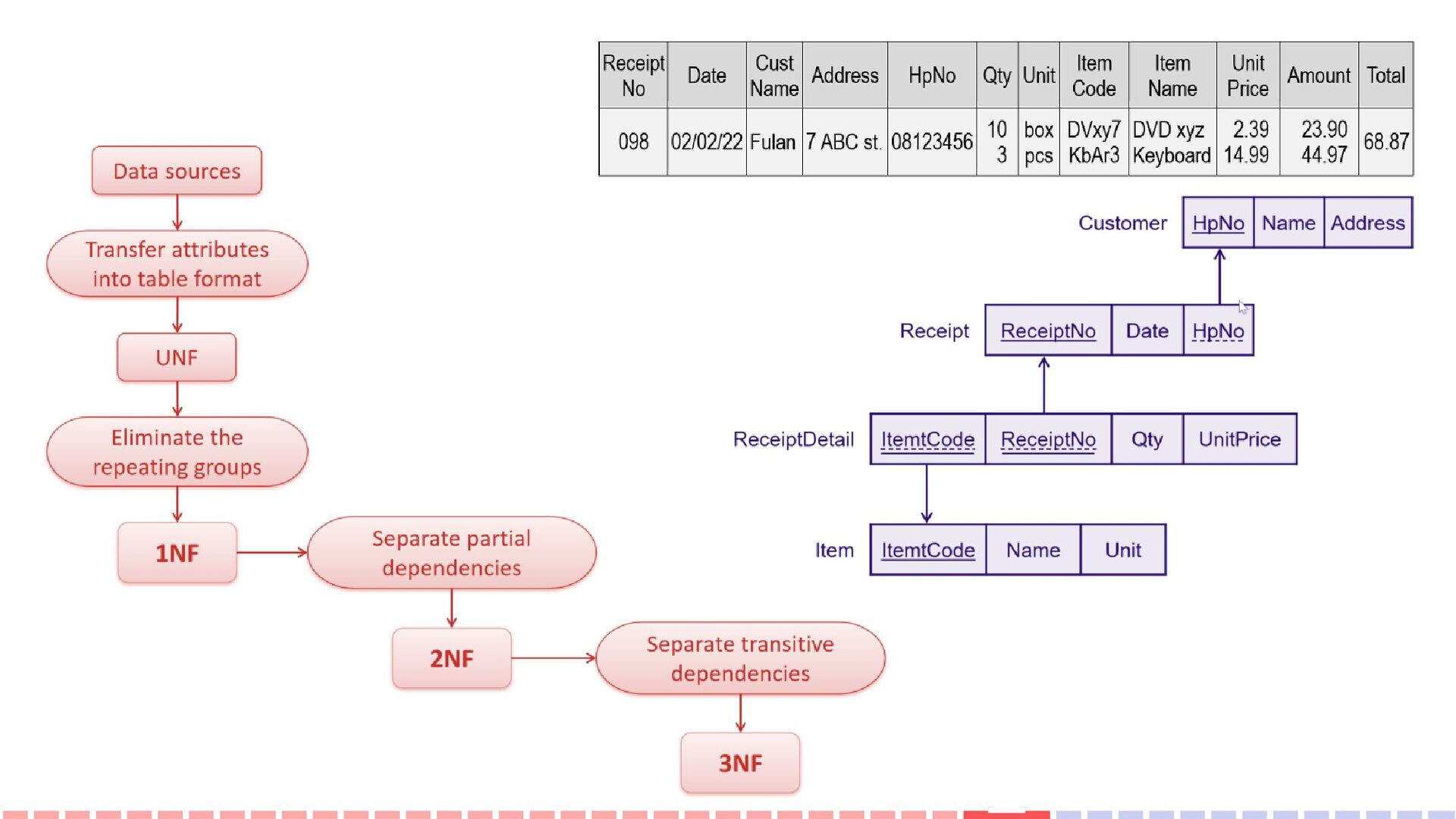
causes many problems. In addition to wasting storage space, performance issues when reading data, three main problems arise, namely when: (1) adding new data, (2) modifying, and (3) deleting existing data. These three problems, commonly called data anomalies, are addressed by normalization.
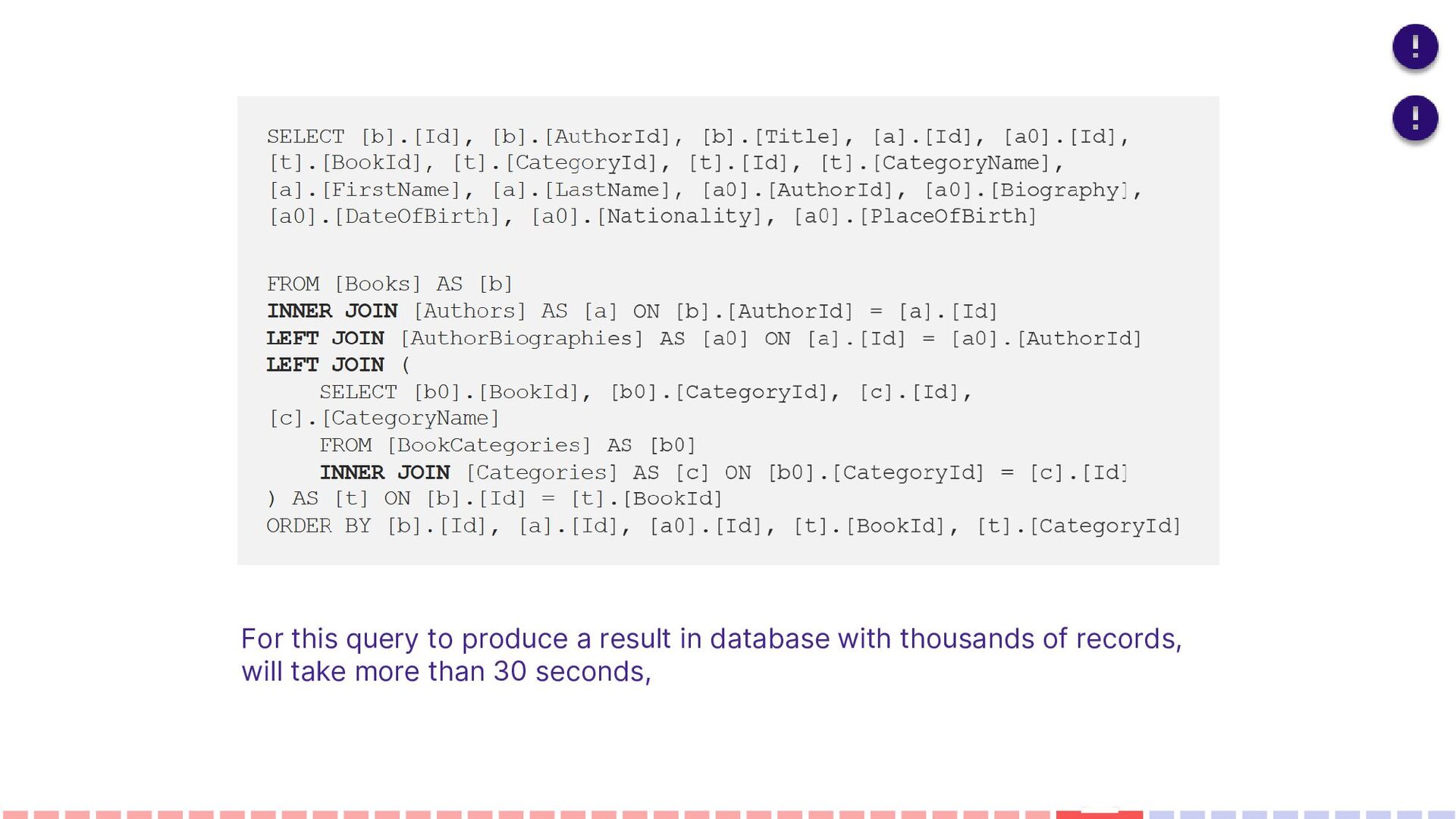
optimization are some of the main aspects for database developers and administrators. They need to carefully consider the usage of specific operators, the number of tables on a query, the size of a query, its execution plan, statistics, resource allocation, and other performance metrics – all that may improve and tune query performance or make it worse. • Avoid too many JOINs • Avoid using SELECT DISTINCT • Use SELECT fields instead of SELECT * • Use TOP to sample query results
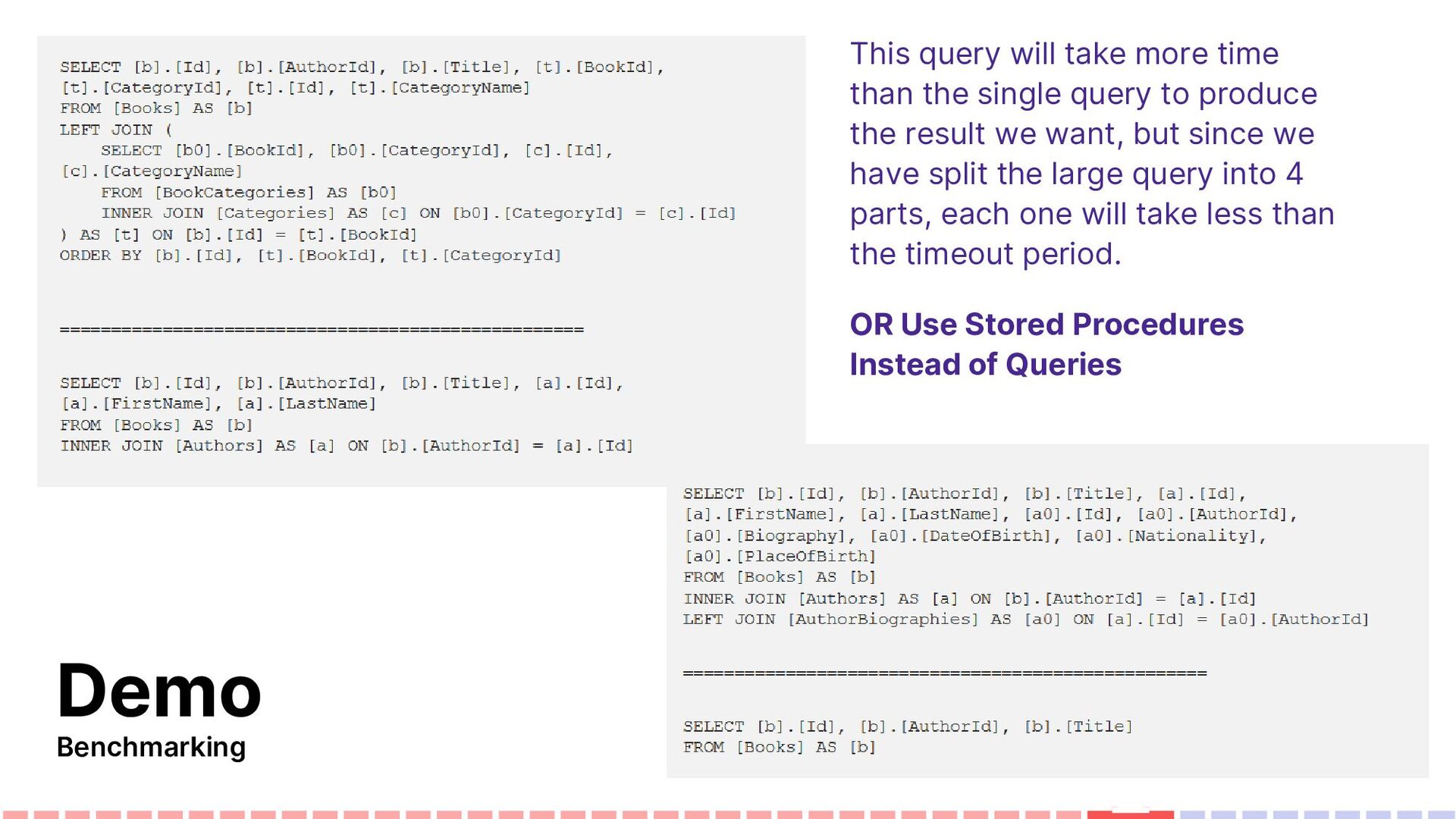
to produce the result we want, but since we have split the large query into 4 parts, each one will take less than the timeout period. OR Use Stored Procedures Instead of Queries Demo Benchmarking
Multiple If-else Statements • Avoid Getting the Size of the Collection in the Loop • Use Primitive Types Wherever Possible • Avoid Creating Big Objects Often • Use of Unnecessary Log Statements and Incorrect Log Levels
constructs in terms of simpler ones. For example, while loops and foreach loops can be rewritten in terms of for loops. Then, the rest of the code only has to deal with for loops. For, Foreach and While loops are converted to while loops when C# compiler converts this to intermediate code Demo Lowering
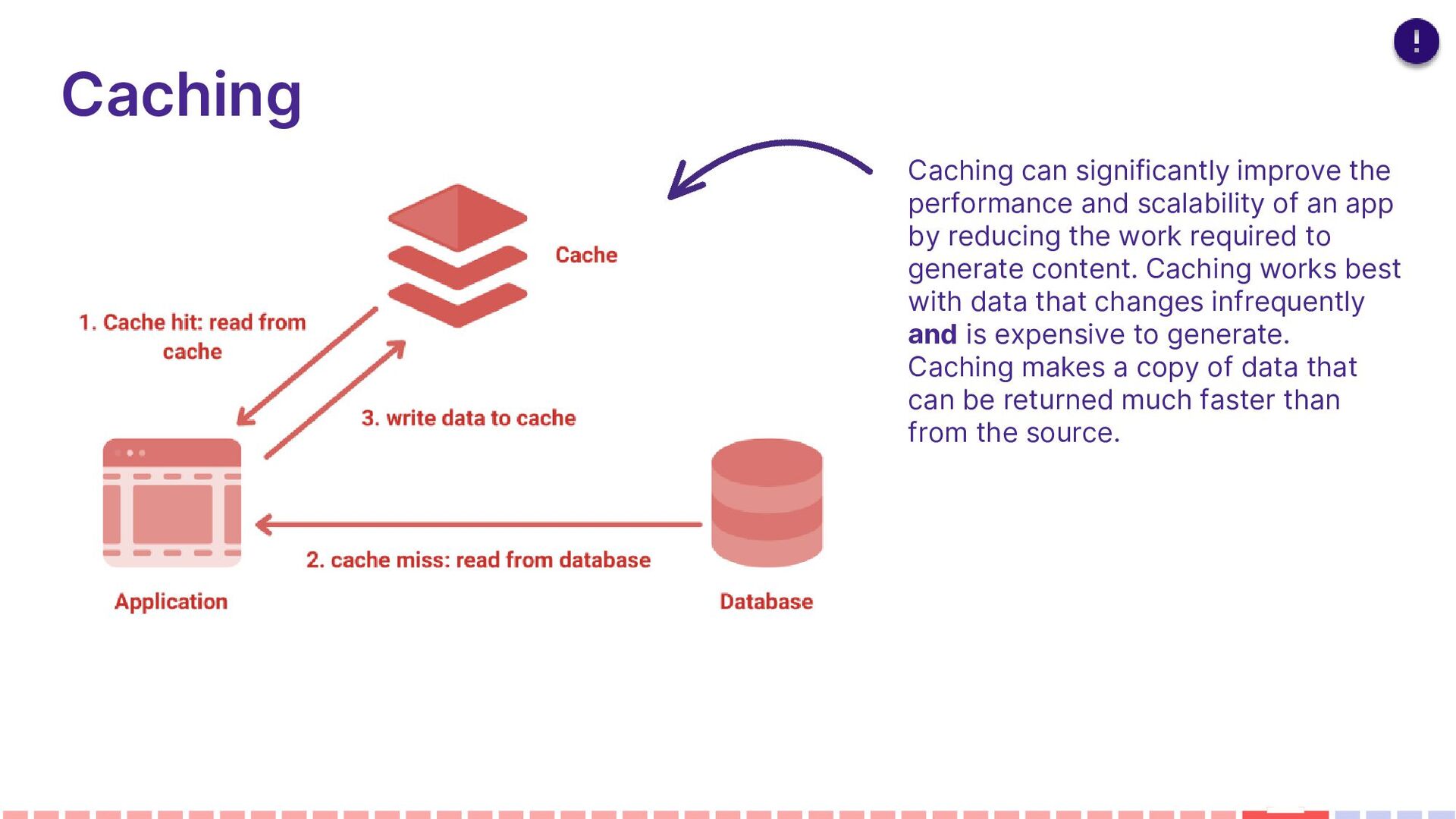
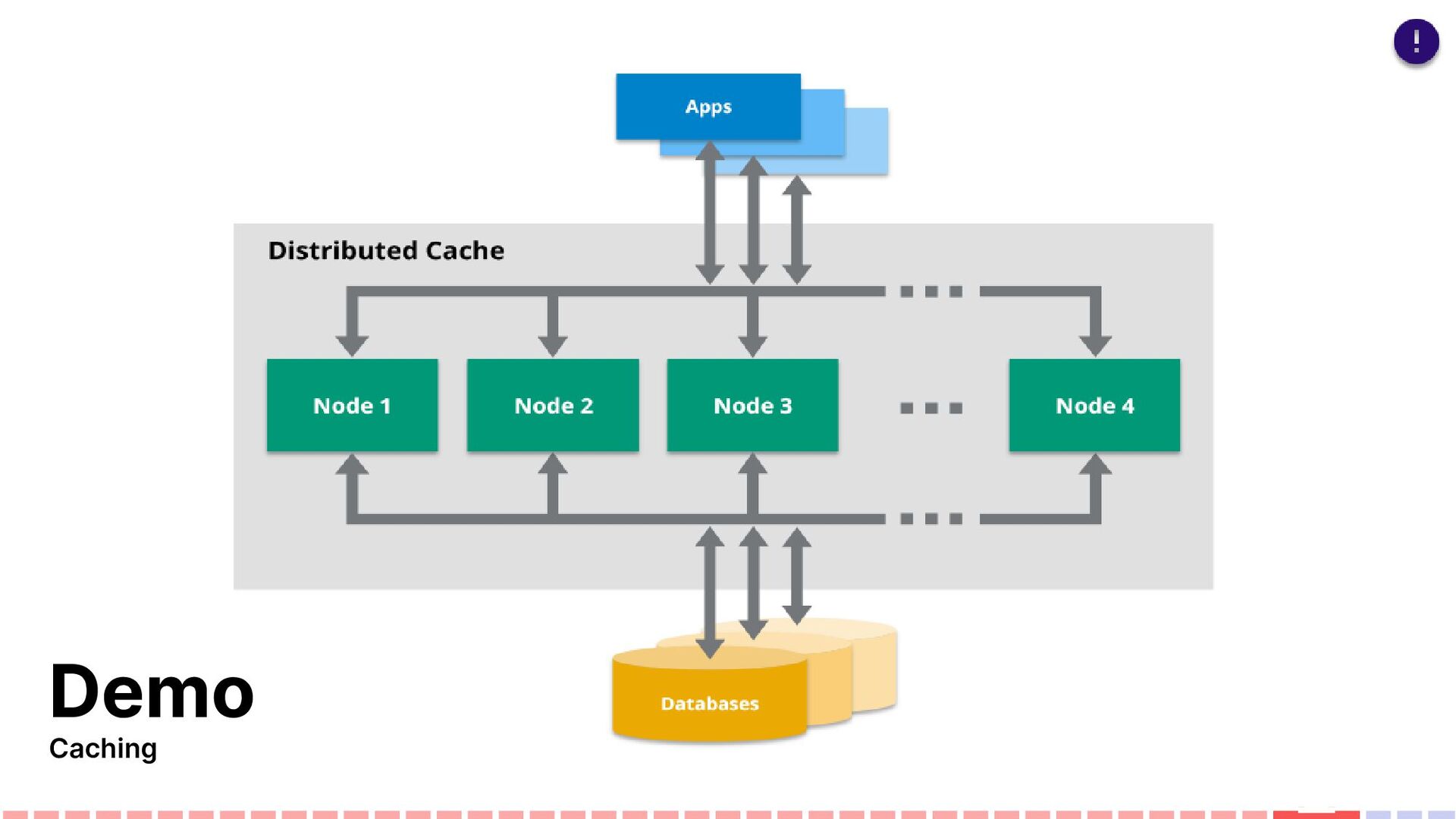
an app by reducing the work required to generate content. Caching works best with data that changes infrequently and is expensive to generate. Caching makes a copy of data that can be returned much faster than from the source.
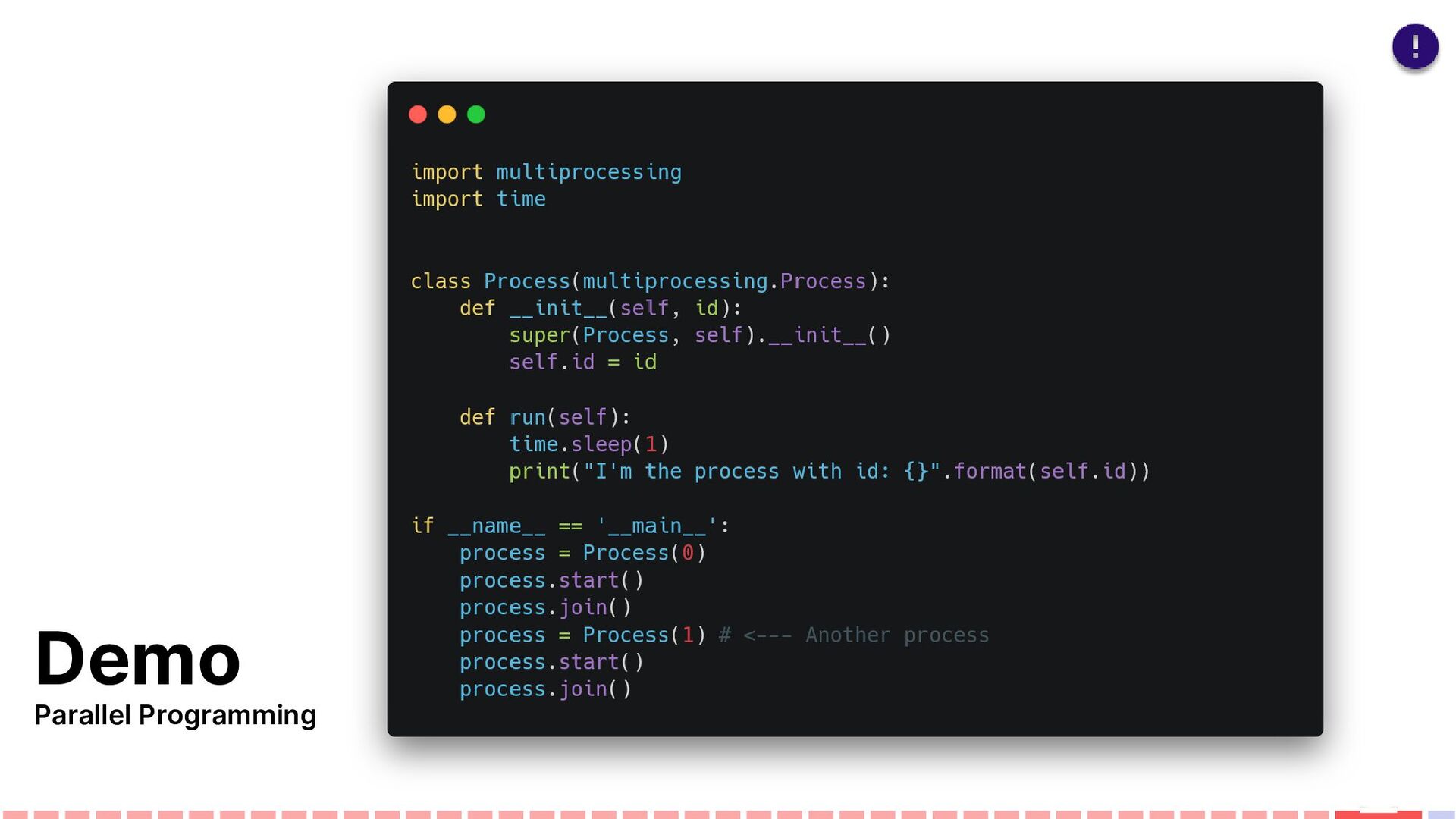
more than just a performance play. That is its key benefit. Even though there are some scenarios where concurrent execution is a clear solution, you usually can't just automatically assume that dividing the workload over several cores will outperform the sequential execution, so a lot of measurement is usually involved. "Going parallel" is not a cure for everything since there are some caveats you should definitely be aware of. With these in mind, you should be able to make the proper and educated decision whether to stay sequential or dive into parallel programming.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![99x.io Thank you! /nishan_cw nishanc.medium.com /nishanchathuranga [email protected]](https://files.speakerdeck.com/presentations/1c688b192abc4d718047e2c008a59020/slide_46.jpg){kind=link}