Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Introduction to R
Search
nonki1974
April 06, 2019
Technology
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Introduction to R
nonki1974
April 06, 2019
More Decks by nonki1974
See All by nonki1974
GTFS with Tidytransit package
nonki1974
0
340
TokyoR#84_Rexams
nonki1974
0
230
都道府県別焼き鳥屋ランキングの作成
nonki1974
1
930
Introduction to dplyr
nonki1974
0
560
Introduction to ggplot2
nonki1974
1
540
Analyzing PSB tracks with R
nonki1974
0
620
introduction to fukuoka.R @ Fukuoka.LT
nonki1974
0
81
所要時間のヒートマップを作成する
nonki1974
0
600
gtfsr package @ fukuoka.R #11
nonki1974
0
360
Other Decks in Technology
See All in Technology
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
420
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
330
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
VPCセキュリティ対応の最新事情
nagisa53
1
290
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
150
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
220
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
430
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
230
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
170
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
630
Featured
See All Featured
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Fireside Chat
paigeccino
42
4k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
The Curse of the Amulet
leimatthew05
2
13k
The Language of Interfaces
destraynor
162
27k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
So, you think you're a good person
axbom
PRO
2
2.1k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
We Are The Robots
honzajavorek
0
280
Transcript
Introduction to R fukuoka.R #13 @nonki1974 April 6, 2019
ベクトル | データ構造の基本 # 正規乱数を 6 個生成 rnorm(6) ## [1]
-1.8346427 0.1121437 -0.2933256 ## [4] 0.8007794 -0.3860248 -0.2725474 → 行の先頭の [1] が何番目の要素かを示している 2
ベクトル | 数値(スカラ) → 数値も⻑さ 1 のベクトルとして扱われる 3+4 ## [1]
7 3
変数への代入 → 代入記号は <- → 変数 +[Enter] で中身を表示 x <-
rnorm(2) x ## [1] 1.8786776 0.9995424 4
ベクトルの作成 → c() 関数で値をつなげて (combine) ベクトルを作成 y <- c(3, 4.5)
y ## [1] 3.0 4.5 5
行列・配列 → 次元属性を持ったベクトル x <- rnorm(6) x ## [1] 0.2585055
0.6418958 -0.8850625 ## [4] -0.9304199 -0.2260441 1.4271053 dim(x) <- c(2, 3) x ## [,1] [,2] [,3] ## [1,] 0.2585055 -0.8850625 -0.2260441 ## [2,] 0.6418958 -0.9304199 1.4271053 6
要素の指定 | 行列・配列 x[2, 3] ## [1] 1.427105 # ベクトルの要素番号でも指定できる
# (ベクトルとしての性質も保持している) x[5] ## [1] -0.2260441 7
リスト → データ型の異なる複数のベクトルや,複数のリストを一括し て保持できるデータ構造。分析結果はリストで返されること が多い。 → リストの作成には list() 関数を使う。 date
<- "2015-10-01" city <- c(" 福岡市", " 北九州市") popl <- c(154, 96) fukuoka <- list(date = date, city = city, popl = popl) 8
リスト fukuoka ## $date ## [1] "2015-10-01" ## ## $city
## [1] "福 岡 市" "北 九 州 市" ## ## $popl ## [1] 154 96 9
要素の参照 | リスト → [[要素番号]] もしくは $ 要素名でリスト内のオブジェクト自 身を参照できる →
[要素番号] の場合はリストが返される fukuoka$city ## [1] "福 岡 市" "北 九 州 市" fukuoka[[2]] ## [1] "福 岡 市" "北 九 州 市" fukuoka[2] ## $city ## [1] "福 岡 市" "北 九 州 市" 10
データフレーム → 行列風の外見を持つ同じ大きさのベクトルを要素とするリス ト → data.frame() 関数で作成できる city <- c("
福岡市", " 北九州市", " 久留米市") code <- c("40130", "40100", "40203") popl <- c(154, 96, 30) area <- c(343, 492, 230) fukuoka.df <- data.frame( city = city, code = code, popl = popl, area = area ) 11
データフレームの出力 fukuoka.df ## city code popl area ## 1 福
岡 市 40130 154 343 ## 2 北 九 州 市 40100 96 492 ## 3 久 留 米 市 40203 30 230 12
データフレームの要素の参照 fukuoka.df$popl ## [1] 154 96 30 fukuoka.df[,3] ## [1]
154 96 30 fukuoka.df[1,] ## city code popl area ## 1 福 岡 市 40130 154 343 colnames(fukuoka.df) ## [1] "city" "code" "popl" "area" 13
データファイルの読み込み → 様々なフォーマットのファイルを R に読み込むことができる → カンマ区切り,タブ区切りのテキストファイルなど → read.table() が基本
→ ラッパーとして read.csv() や read.table() などがあ る 14
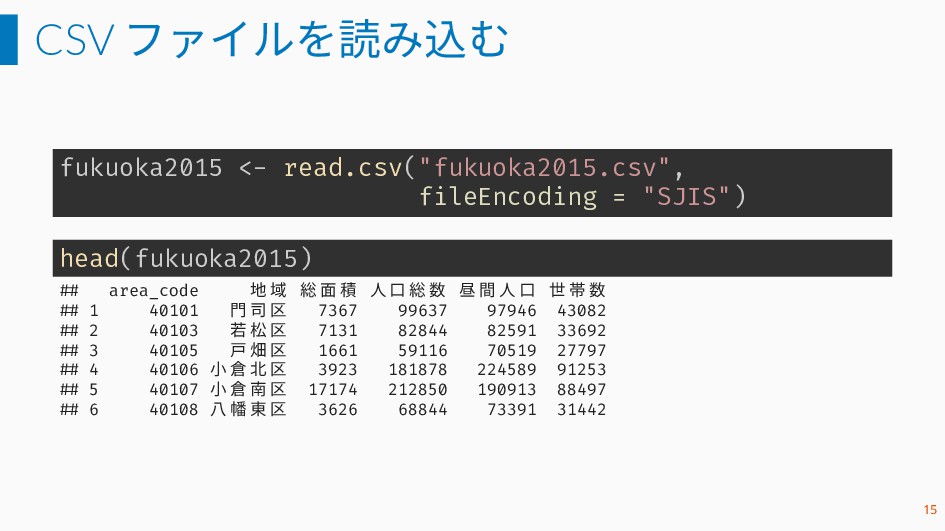
CSV ファイルを読み込む fukuoka2015 <- read.csv("fukuoka2015.csv", fileEncoding = "SJIS") head(fukuoka2015) ##
area_code 地 域 総 面 積 人 口 総 数 昼 間 人 口 世 帯 数 ## 1 40101 門 司 区 7367 99637 97946 43082 ## 2 40103 若 松 区 7131 82844 82591 33692 ## 3 40105 戸 畑 区 1661 59116 70519 27797 ## 4 40106 小 倉 北 区 3923 181878 224589 91253 ## 5 40107 小 倉 南 区 17174 212850 190913 88497 ## 6 40108 八 幡 東 区 3626 68844 73391 31442 15
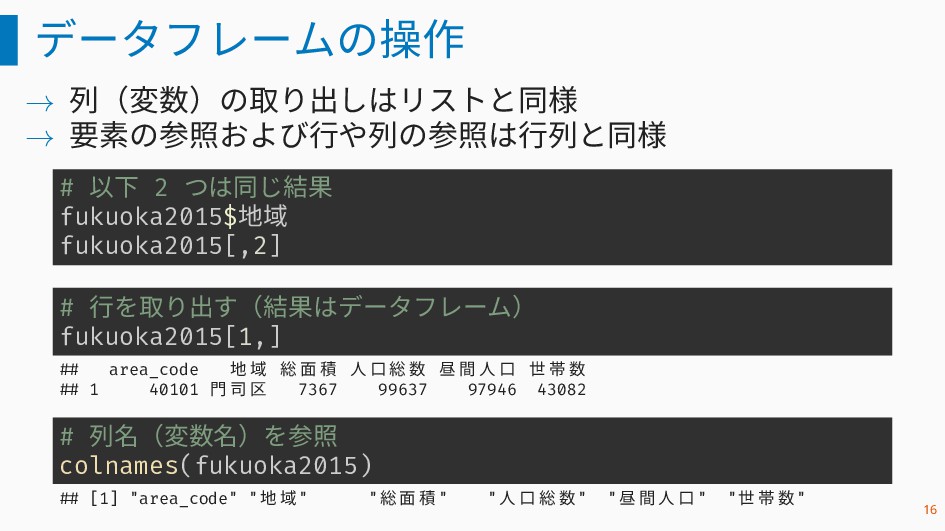
データフレームの操作 → 列(変数)の取り出しはリストと同様 → 要素の参照および行や列の参照は行列と同様 # 以下 2 つは同じ結果 fukuoka2015$地域
fukuoka2015[,2] # 行を取り出す(結果はデータフレーム) fukuoka2015[1,] ## area_code 地 域 総 面 積 人 口 総 数 昼 間 人 口 世 帯 数 ## 1 40101 門 司 区 7367 99637 97946 43082 # 列名(変数名)を参照 colnames(fukuoka2015) ## [1] "area_code" "地 域" "総 面 積" "人 口 総 数" "昼 間 人 口" "世 帯 数" 16
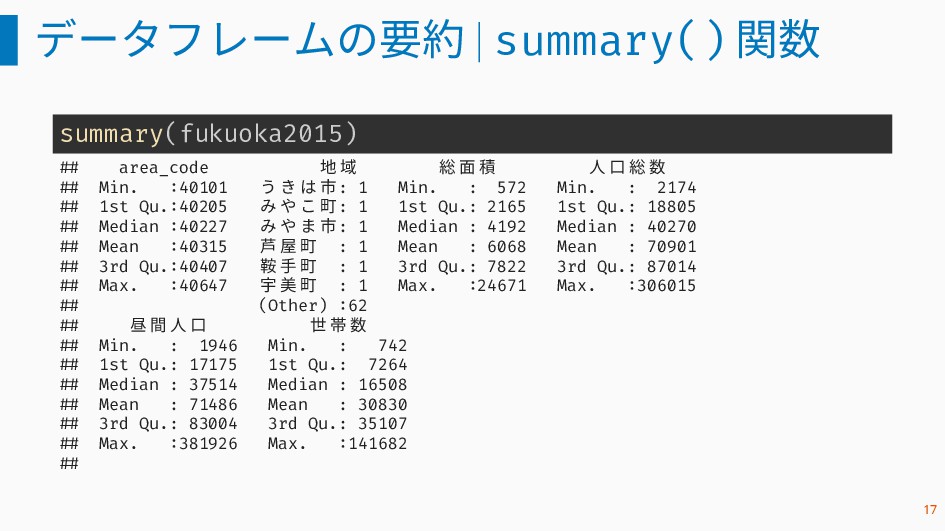
データフレームの要約 | summary() 関数 summary(fukuoka2015) ## area_code 地 域 総
面 積 人 口 総 数 ## Min. :40101 う き は 市: 1 Min. : 572 Min. : 2174 ## 1st Qu.:40205 み や こ 町: 1 1st Qu.: 2165 1st Qu.: 18805 ## Median :40227 み や ま 市: 1 Median : 4192 Median : 40270 ## Mean :40315 芦 屋 町 : 1 Mean : 6068 Mean : 70901 ## 3rd Qu.:40407 鞍 手 町 : 1 3rd Qu.: 7822 3rd Qu.: 87014 ## Max. :40647 宇 美 町 : 1 Max. :24671 Max. :306015 ## (Other) :62 ## 昼 間 人 口 世 帯 数 ## Min. : 1946 Min. : 742 ## 1st Qu.: 17175 1st Qu.: 7264 ## Median : 37514 Median : 16508 ## Mean : 71486 Mean : 30830 ## 3rd Qu.: 83004 3rd Qu.: 35107 ## Max. :381926 Max. :141682 ## 17
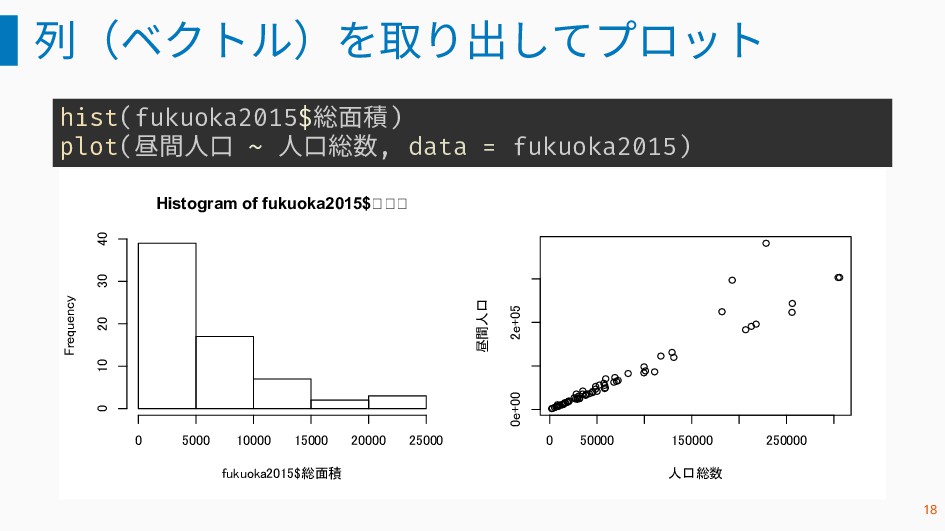
列(ベクトル)を取り出してプロット hist(fukuoka2015$総面積) plot(昼間人口 ~ 人口総数, data = fukuoka2015) Histogram of
fukuoka2015$総面積 fukuoka2015$総面積 Frequency 0 5000 10000 15000 20000 25000 0 10 20 30 40 0 50000 150000 250000 0e+00 2e+05 人口総数 昼間人口 18
パッケージによる機能拡張 → パッケージを使うことで多くのことが可能になる → install.packages() 関数を使ってインストール → パッケージ名 :: 関数名
() でパッケージ内の関数を利用で きる → library() 関数でパッケージをロードすればパッケージ名 を省略可能 → tidydata 形式をサポートしたパッケージ群を tidyverse パ ッケージで一括してインストールできる 19
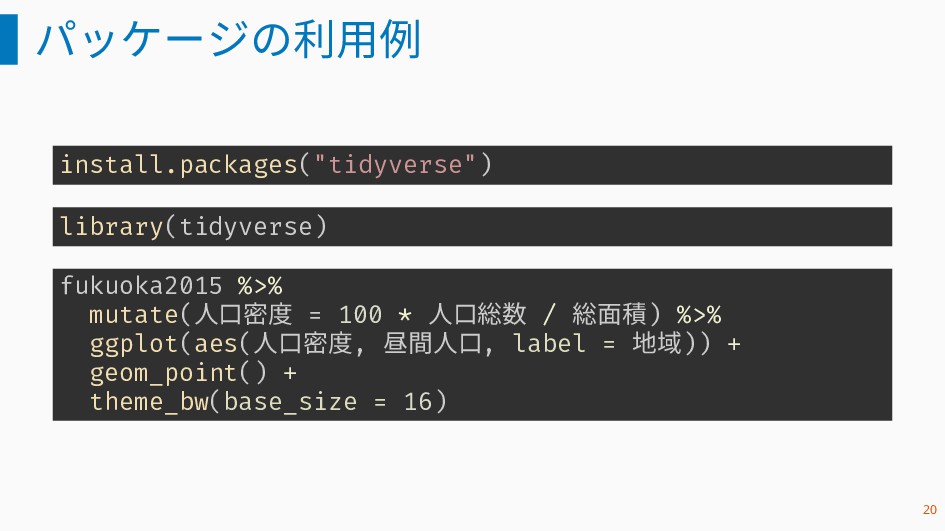
パッケージの利用例 install.packages("tidyverse") library(tidyverse) fukuoka2015 %>% mutate(人口密度 = 100 * 人口総数
/ 総面積) %>% ggplot(aes(人口密度, 昼間人口, label = 地域)) + geom_point() + theme_bw(base_size = 16) 20
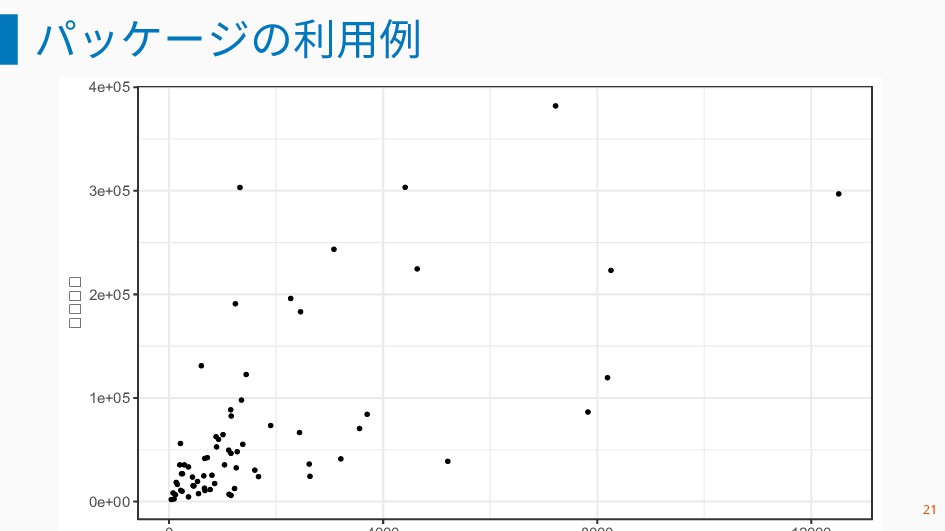
パッケージの利用例 0e+00 1e+05 2e+05 3e+05 4e+05 昼間人口 21
因子型 (factor) → R で名義尺度および順序尺度を扱うためのデータ型 → 文字型 (character) と異なるので注意 →
factor() 関数を使って,文字型のベクトルから因子型に変 換できる → levels 引数で水準(カテゴリ)のベクトルを指定 → 因子型の実体は整数型のベクトルに水準を表すベクトルが加 わったもの 22
とりあえず文字型 bloodtype <- c("B","A","A","A","AB", "B","AB","A","A","A","C") bloodtype ## [1] "B" "A"
"A" "A" "AB" "B" "AB" "A" "A" "A" "C" # ベクトルの要素をカウント table(bloodtype) ## bloodtype ## A AB B C ## 6 2 2 1 23
因子型に変換 | factor() 関数 bloodtype.f <- factor(bloodtype, levels = c("A",
"B", "O", "AB")) bloodtype.f ## [1] B A A A AB B AB A A A <NA> ## Levels: A B O AB # O 型がいない場合,度数ゼロで集計してくれる table(bloodtype.f) ## bloodtype.f ## A B O AB ## 6 2 0 2 table(addNA(bloodtype.f)) ## ## A B O AB <NA> ## 6 2 0 2 1 24
因子型の中身 str(bloodtype.f) ## Factor w/ 4 levels "A","B","O","AB": 2 1
1 1 4 2 4 1 1 1 ... # 整数型に変換 as.numeric(bloodtype.f) ## [1] 2 1 1 1 4 2 4 1 1 1 NA # 対応する水準ベクトルの文字に変換 as.character(bloodtype.f) ## [1] "B" "A" "A" "A" "AB" "B" "AB" "A" "A" "A" NA 25
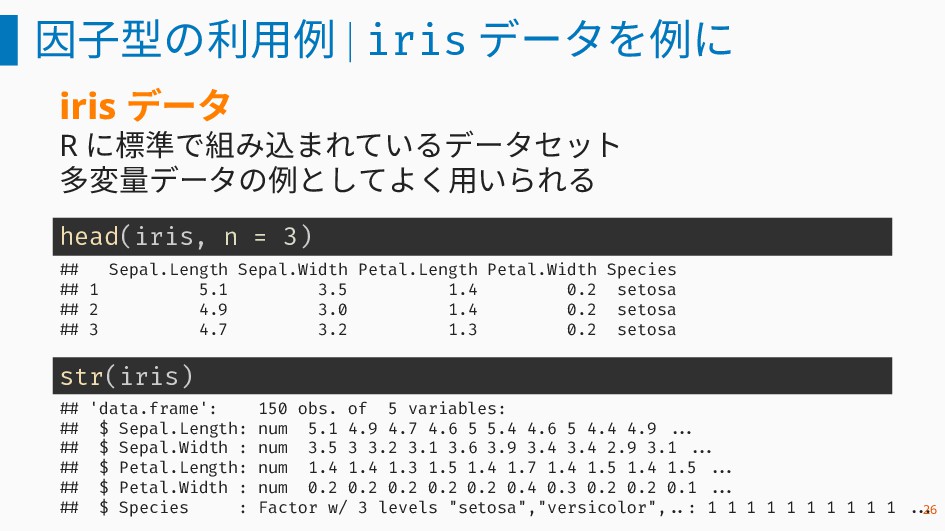
因子型の利用例 | iris データを例に iris データ R に標準で組み込まれているデータセット 多変量データの例としてよく用いられる head(iris,
n = 3) ## Sepal.Length Sepal.Width Petal.Length Petal.Width Species ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3.0 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa str(iris) ## 'data.frame': 150 obs. of 5 variables: ## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... ## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... ## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... ## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... ## $ Species : Factor w/ 3 levels "setosa","versicolor", ..: 1 1 1 1 1 1 1 1 1 1 ... 26
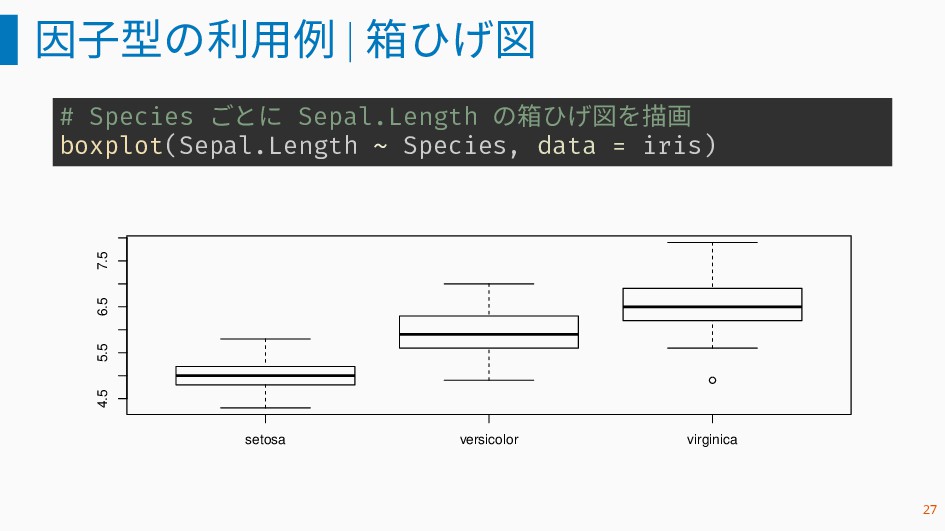
因子型の利用例 | 箱ひげ図 # Species ごとに Sepal.Length の箱ひげ図を描画 boxplot(Sepal.Length ~
Species, data = iris) setosa versicolor virginica 4.5 5.5 6.5 7.5 27
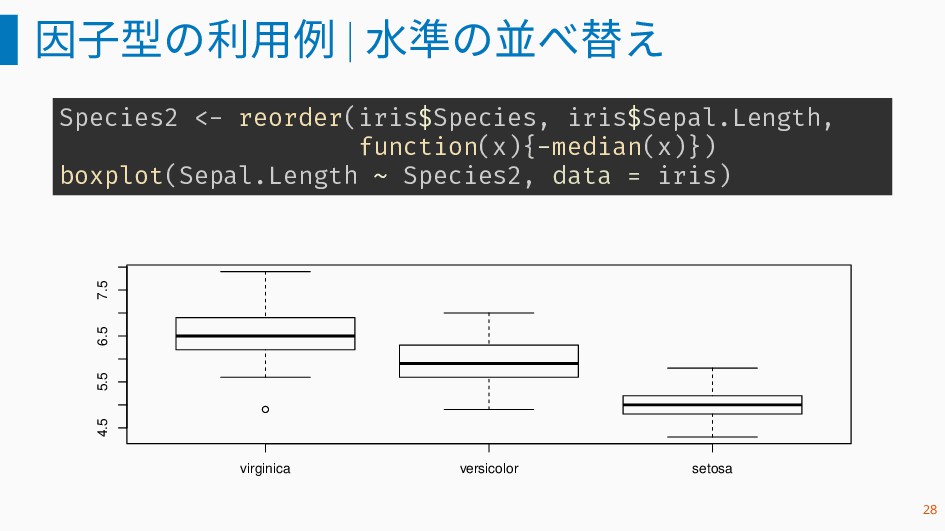
因子型の利用例 | 水準の並べ替え Species2 <- reorder(iris$Species, iris$Sepal.Length, function(x){-median(x)}) boxplot(Sepal.Length ~
Species2, data = iris) virginica versicolor setosa 4.5 5.5 6.5 7.5 28
因子型の利用例 | 層別散布図 ggplot(iris, aes(Sepal.Width, Petal.Width, color = Species)) geom_point()
+ facet_wrap(~Species) + theme_bw(base_size = 14) setosa versicolor virginica 2.0 2.5 3.0 3.5 4.0 4.52.0 2.5 3.0 3.5 4.0 4.52.0 2.5 3.0 3.5 4.0 4.5 0.0 0.5 1.0 1.5 2.0 2.5 Sepal.Width Petal.Width Species setosa versicolor virginica 29
{kind=link}
![ベクトル | データ構造の基本 # 正規乱数を 6 個生成 rnorm(6) ## [1]](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_1.jpg){kind=link}
![ベクトル | 数値(スカラ) → 数値も⻑さ 1 のベクトルとして扱われる 3+4 ## [1]](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_2.jpg){kind=link}
![変数への代入 → 代入記号は <- → 変数 +[Enter] で中身を表示 x <-](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_3.jpg){kind=link}
{kind=link}
![行列・配列 → 次元属性を持ったベクトル x <- rnorm(6) x ## [1] 0.2585055](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_5.jpg){kind=link}
![要素の指定 | 行列・配列 x[2, 3] ## [1] 1.427105 # ベクトルの要素番号でも指定できる](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_6.jpg){kind=link}
{kind=link}
![リスト fukuoka ## $date ## [1] "2015-10-01" ## ## $city](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_8.jpg){kind=link}
![要素の参照 | リスト → [[要素番号]] もしくは $ 要素名でリスト内のオブジェクト自 身を参照できる →](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
![データフレームの要素の参照 fukuoka.df$popl ## [1] 154 96 30 fukuoka.df[,3] ## [1]](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![とりあえず文字型 bloodtype <- c("B","A","A","A","AB", "B","AB","A","A","A","C") bloodtype ## [1] "B" "A"](https://files.speakerdeck.com/presentations/f8a70493573641b0a1181776ddac7dec/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}