black 2 ## 2 black 5 ## 3 blue 1 ## 4 blue 3 ## 5 blue 4 desc() 関数を使って value の値で降順にソート arrange(df, desc(value)) ## color value ## 1 black 5 ## 2 blue 4 ## 3 blue 3 22
- mean(value)) / sd(value)) ## # A tibble: 5 x 3 ## # Groups: color [2] ## color value z ## <fct> <int> <dbl> ## 1 blue 1 -1.09 ## 2 black 2 -0.707 ## 3 blue 3 0.218 ## 4 blue 4 0.873 ## 5 black 5 0.707 37
= scale(value)) ## # A tibble: 5 x 3 ## # Groups: color [2] ## color value z ## <fct> <int> <dbl> ## 1 blue 1 -1.09 ## 2 black 2 -0.707 ## 3 blue 3 0.218 ## 4 blue 4 0.873 ## 5 black 5 0.707 38
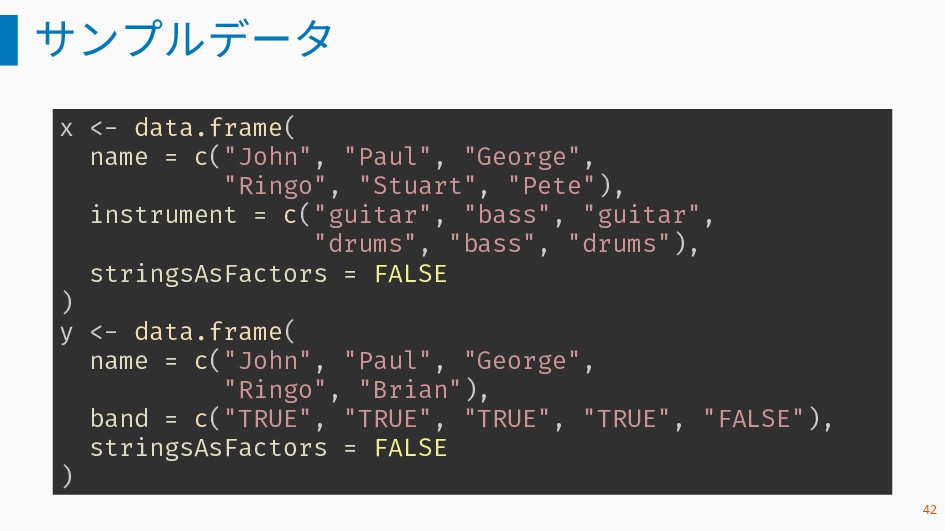
と y の行を出力 inner_join(x, y) ## Joining, by = "name" ## name instrument band ## 1 John guitar TRUE ## 2 Paul bass TRUE ## 3 George guitar TRUE ## 4 Ringo drums TRUE 43
の行も出力される。これに対応す る y の行の値は NA となる。 left_join(x, y) ## Joining, by = "name" ## name instrument band ## 1 John guitar TRUE ## 2 Paul bass TRUE ## 3 George guitar TRUE ## 4 Ringo drums TRUE ## 5 Stuart bass <NA> ## 6 Pete drums <NA> 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![パイプ RStudio では,パイプ演算子をショートカット [Ctrl]+[Shift]+[M] で入力できる。 hourly_delay <- flights %>% filter(!is.na(dep_delay))](https://files.speakerdeck.com/presentations/1f8ebfe9ec794ec382c9cfa777672d3d/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ウインドウ関数 # 累積分布 cume_dist(x) ## [1] 0.4 0.4 1.0 1.0](https://files.speakerdeck.com/presentations/1f8ebfe9ec794ec382c9cfa777672d3d/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}