Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AI時代に求められる思考のパラダイムシフト
Search
NRI Netcom
PRO
May 22, 2026
Technology
200
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AI時代に求められる思考のパラダイムシフト
NRI Netcom
PRO
May 22, 2026
More Decks by NRI Netcom
See All by NRI Netcom
Platform Engineeringはじめの一歩
nrinetcom
PRO
2
85
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
AWSマンスリーアップデートピックアップ 2026年5月分
nrinetcom
PRO
0
79
Keynoteから考える、AIエージェント時代で何が変わるのか?
nrinetcom
PRO
0
100
「Google Cloud Next '26」で発表された、BigQueryの最新機能を使ってみよう
nrinetcom
PRO
0
99
Gemini Code AssistとGeminiCLIの活用例
nrinetcom
PRO
0
100
ジュニアエンジニアはSREとどう向き合うべきか
nrinetcom
PRO
1
170
AWS認定資格は本当に意味があるのか?
nrinetcom
PRO
7
5.8k
AWSマンスリーアップデートピックアップ 2026年3月分
nrinetcom
PRO
0
100
Other Decks in Technology
See All in Technology
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
230
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
210
カードゲーム作りが教えてくれた プロダクトオーナーシップ
moritamasami
0
110
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.5k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
270
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.5k
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.5k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.3k
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
260
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
370
Featured
See All Featured
Testing 201, or: Great Expectations
jmmastey
46
8.2k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Writing Fast Ruby
sferik
630
63k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Git: the NoSQL Database
bkeepers
PRO
432
67k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Why Our Code Smells
bkeepers
PRO
340
58k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Transcript
AI時代に求められる思考のパラダイムシフト 2026年5月19日 NRIネットコム株式会社 デジタル戦略推進本部 デジタル戦略部 越川 徹也 NRIネットコム TECH AND
DESIGN STUDY#99
1 Copyright(C) NRI Netcom, Ltd. All rights reserved. 自己紹介 入社
業務内用 2022年9月 主にクラウドを利用した内製化支援 最近はAI活用もご支援 氏名 越川徹也
2 Copyright(C) NRI Netcom, Ltd. All rights reserved. 生成AIはアンプ ▪
アンプ(増幅器)とは、入力された信号をそのまま大きく増幅して出力する装置です。音を生み出すのではなく、 「元の信号」を忠実に増幅するだけです。 ▪ 生成AIも同じです。入力した思考をそのまま増幅して出力します。出力の質は、入力する思考の質で決まります。 ▪ 思考の解像度が高い人はより深い出力を、何も考えずに入力した人にはその浅さがそのまま返ってきます。AIは思 考の深浅を問わず、ただ忠実に増幅するだけです。 ▪ 時に想定外の気づきを与える「触媒」的な側面もありますが、AIが自動的に良い答えを届けてくれるわけではありま せん。AIを活かすカギは、使う人自身の思考にあります。
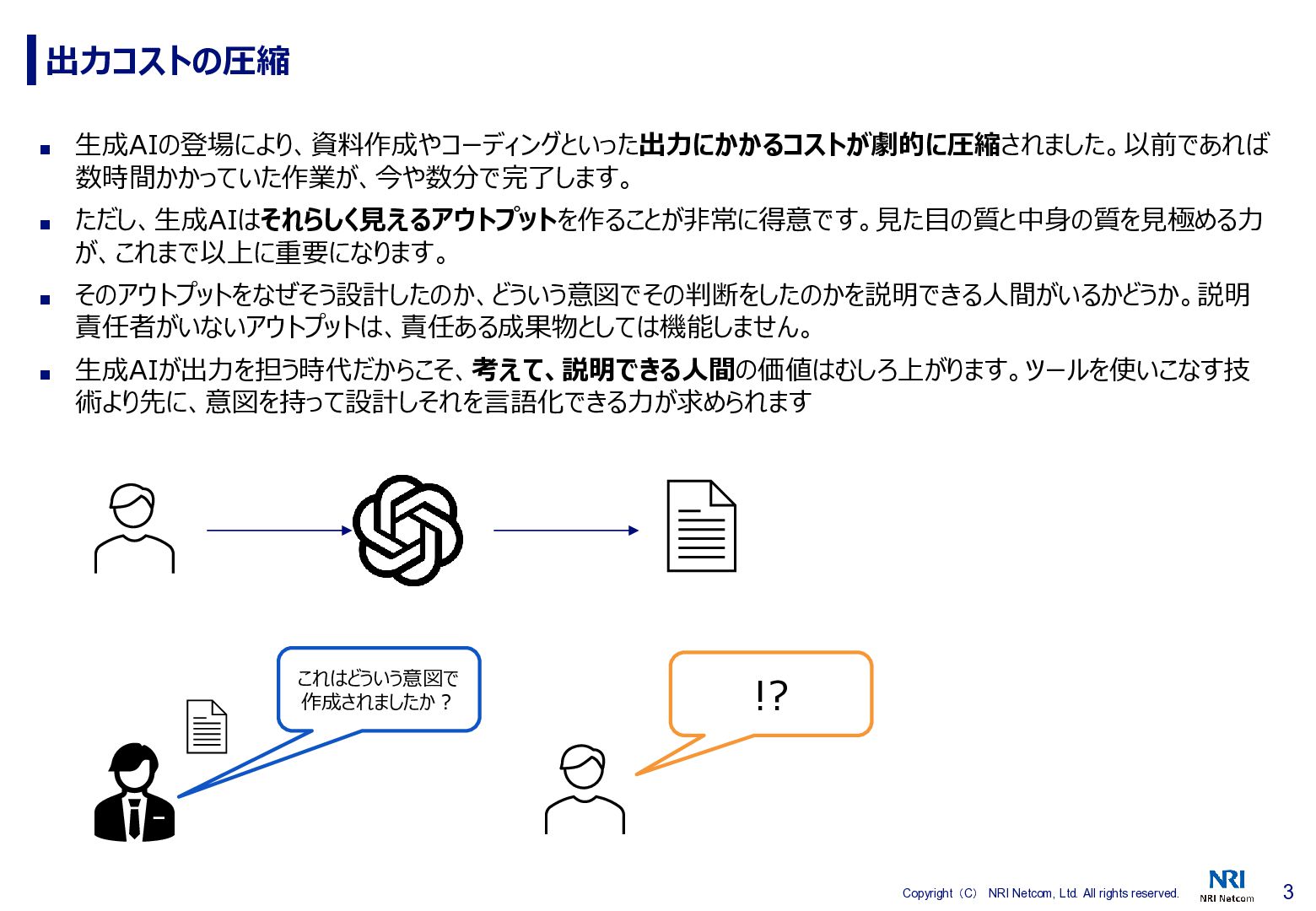
3 Copyright(C) NRI Netcom, Ltd. All rights reserved. 出力コストの圧縮 ▪
生成AIの登場により、資料作成やコーディングといった出力にかかるコストが劇的に圧縮されました。以前であれば 数時間かかっていた作業が、今や数分で完了します。 ▪ ただし、生成AIはそれらしく見えるアウトプットを作ることが非常に得意です。見た目の質と中身の質を見極める力 が、これまで以上に重要になります。 ▪ そのアウトプットをなぜそう設計したのか、どういう意図でその判断をしたのかを説明できる人間がいるかどうか。説明 責任者がいないアウトプットは、責任ある成果物としては機能しません。 ▪ 生成AIが出力を担う時代だからこそ、考えて、説明できる人間の価値はむしろ上がります。ツールを使いこなす技 術より先に、意図を持って設計しそれを言語化できる力が求められます これはどういう意図で 作成されましたか? !?
4 Copyright(C) NRI Netcom, Ltd. All rights reserved. エンジニアは何を身に付けるべきか ▪
生成AIによって出力コストは劇的に圧縮されました。つまり、ハードスキルそのものの価値が相対的に下がるハードス キルのデフレ化が起きているということです。 ▪ わかりやすい例がコーディングです。コードをゼロかける必要はなくなりました。ただし、AIが生成したコードを読み、意 図を理解し、正しく判断できる力は依然として必要です。書けるから読める・判断できるへ、求められるスキルの質 が変化しています。 ▪ では、ハードスキルが相対化されたこの時代に、エンジニアは何を学ぶ必要があるのでしょうか。それは、一段上位の 概念を学ぶことだと思います。つまり、作るから設計し、判断するへとシフトするイメージです。 ▪ これはコーディングに限った話ではありません。どの領域においても、作業レベルのスキルはAIに委ねながら、その上位 にある構造・意図・判断の層を人間が担うという役割分担が、これからのスタンダードになっていくと思います。
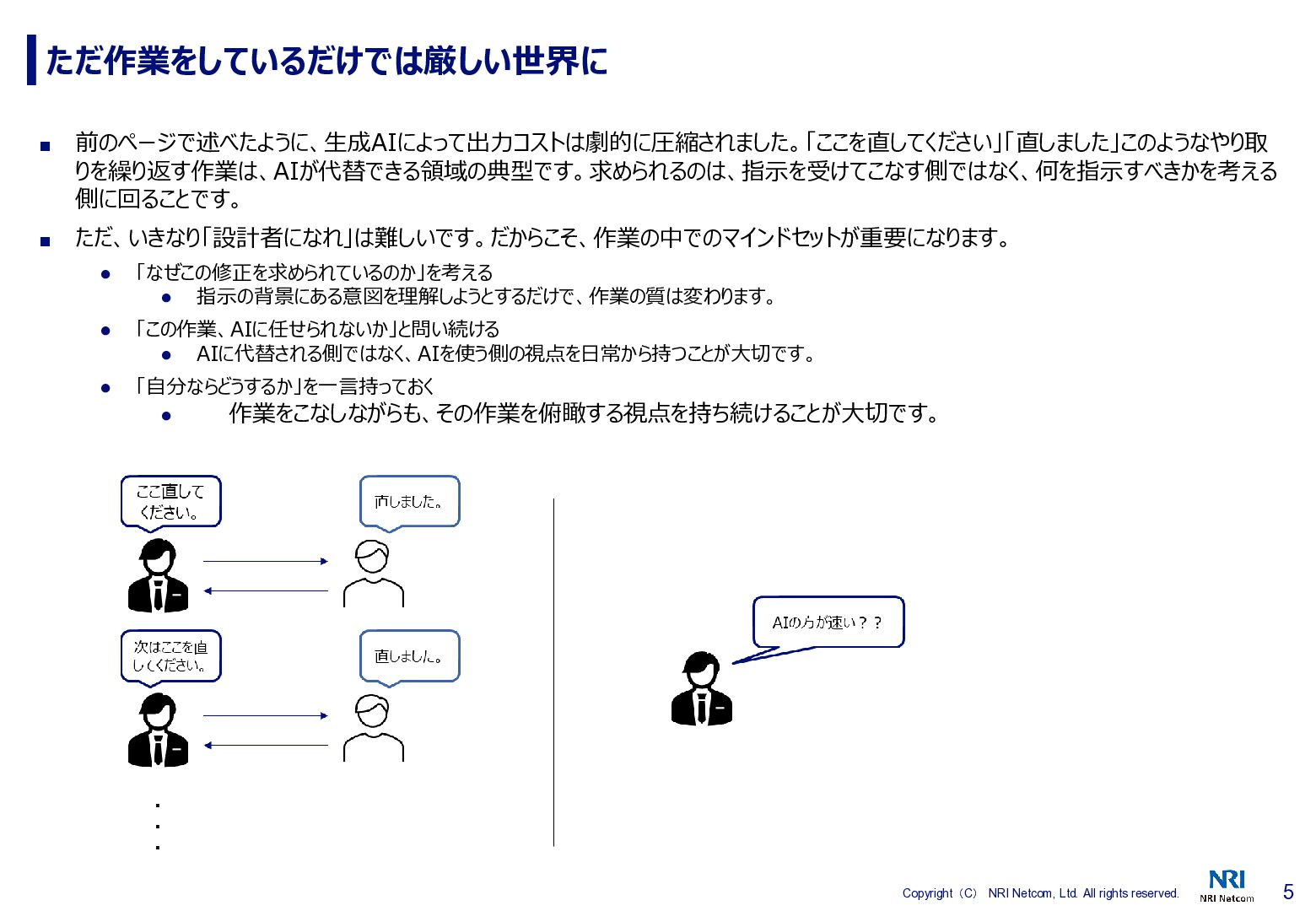
5 Copyright(C) NRI Netcom, Ltd. All rights reserved. ただ作業をしているだけでは厳しい世界に ▪
前のページで述べたように、生成AIによって出力コストは劇的に圧縮されました。「ここを直してください」「直しました」このようなやり取 りを繰り返す作業は、AIが代替できる領域の典型です。求められるのは、指示を受けてこなす側ではなく、何を指示すべきかを考える 側に回ることです。 ▪ ただ、いきなり「設計者になれ」は難しいです。だからこそ、作業の中でのマインドセットが重要になります。 • 「なぜこの修正を求められているのか」を考える • 指示の背景にある意図を理解しようとするだけで、作業の質は変わります。 • 「この作業、AIに任せられないか」と問い続ける • AIに代替される側ではなく、AIを使う側の視点を日常から持つことが大切です。 • 「自分ならどうするか」を一言持っておく • 作業をこなしながらも、その作業を俯瞰する視点を持ち続けることが大切です。
6 Copyright(C) NRI Netcom, Ltd. All rights reserved. 1.生成AIの進化の過程
7 Copyright(C) NRI Netcom, Ltd. All rights reserved. 生成AIの進化の過程➀ ▪
2022年末、ChatGPTの登場は衝撃的でした。それまでのチャットボットとは次元が違う、まるで人間と会話してい るような自然さで、世界中に瞬く間に普及しました。最初にできることはシンプルで、テキストを入力してテキストが返 ってくるだけです。しかし、それだけで十分すぎるほどの衝撃でした。 ▪ その後、進化は急速に進みます。 • 画像生成への対応:テキストの指示だけで画像を生み出せるようになりました。 • マルチモーダル化:テキストだけでなく、画像や音声も入出力できるようになり、扱える情報の幅が一気に広がりました。 ▪ 当初「生成AI=テキストを扱うもの」という認識が一般的でしたが、この時点でその常識は大きく塗り替えられていま した。
8 Copyright(C) NRI Netcom, Ltd. All rights reserved. 生成AIの進化の過程② ▪
次の転換点は、生成AI単体の限界を超えるための外部連携でした。 • Web検索との統合:学習済みの知識だけでなく、リアルタイムの情報にもアクセスできるようになりました。 • コード実行環境との統合:生成AIが本来苦手とする計算やデータ分析を、コードを書いて自ら実行することで補えるようにな りました。 ▪ こうして生成AIは、一つのモデルが何でもこなす存在から、複数の機能が役割分担して動く構造へと変化しました。Web検索・コー ド実行・外部サービス連携など、それぞれの得意分野を組み合わせて動く仕組みが、今や生成AIの標準的なあり方になっています。 ▪ そして今、さらに次の変化が起きています。人間がプロンプトを投げて結果を受け取るという一問一答の使い方から、生成AIが自ら 考え・判断し・行動するエージェント型の活用へとシフトしつつあります。指示を出す側から、動く仕組みを設計する側へ。生成AIとの 関わり方そのものが変わり始めています。
9 Copyright(C) NRI Netcom, Ltd. All rights reserved. 2.AI時代に求められる思考のパラダイムシフト
10 Copyright(C) NRI Netcom, Ltd. All rights reserved. テストの考え方の違い ▪
従来のテストは、システムがどう振る舞うべきかを明確に定義できることが大前提でした。判定条件を事前に設計で きていたからこそ、テストが機能していたのです。 ▪ しかし、生成AIを組み込んだシステムではこの前提が崩れます。生成AIは確率的に動作するため、同じ質問に対し て毎回まったく同じ回答が返ってくるとは限りません。 ▪ 特にRAGのような回答品質が問われる領域では、「これが正解」と言い切れる判定条件を設計すること自体が難し くなります。一方で、エージェントのようにプロセスの達成可否が明確な領域では、「正しいツールを呼べたか」「タスク を完了できたか」といった判定条件を設計できる部分もあり、従来のテストに近いアプローチが使える場面もあります。 ▪ 判定条件が曖昧な領域では、多くの人に実際に触れてもらい、評価基準に沿って回答の質を評価してもらうことが 重要になります。さらに LLM-as-a-Judge(生成AI自身に品質評価をさせる仕組み)との組み合わせが、コスト と品質を両立する現実解になっています。「何が正解か」を定義する難しさと向き合うことが、生成AIシステム開発に おいて重要です。
11 Copyright(C) NRI Netcom, Ltd. All rights reserved. テックリードとプロダクトオーナ ▪
テックリードとプロダクトオーナ • テックリードとは、技術的な意思決定に責任を持つ役割です。アーキテクチャ設計・技術選定・品質担保など、「技術的に正し く、持続可能に作れるか」を担保する存在です。 • プロダクトオーナとは、プロダクトの価値に責任を持つ役割です。ユーザーにとって何が価値なのか、どの機能を優先すべきか、 「作るべきか・作らないか」の判断を担います。 ▪ テックリードに求められる視点の変化 • 生成AIを組み込んだプロダクトは、進化のスピードが桁違いに速いです。モデルの性能向上・API仕様の変更・価格改定など、 生成AIベンダーの動きにプロダクトが良くも悪くも強く引っ張られます。 • このスピードについていくためには、技術的な追従だけでは足りません。「この技術の変化がユーザーにどう影響するのか」 という 視点を、テックリード自身が持つ必要があります。
12 Copyright(C) NRI Netcom, Ltd. All rights reserved. 確率的か確定的か ▪
確率的な世界と確定的な世界 • 確定的(Deterministic)な世界とは、同じ入力に対して常に同じ出力が返ってくることが保証された世界です。従来の ファンクションコーリング(関数呼び出し)はその典型で、「冪等性(べきとうせい)」何度実行しても結果が変わらない性 質が担保されています。 • 確率的(Probabilistic)な世界とは、同じ入力に対して毎回異なる出力が返り得る世界です。生成AIはこちらに属しま す。確率分布に基づいて回答を生成するため、同じプロンプトでも回答が変わることがあります。 ▪ 生成AIに確定性を求めてはいけない • 生成AIに確定性を求める声は少なくありません。「なぜ毎回違う答えが返るのか」「テストが通らない」「品質が安定しない」 これらは確定的な世界の常識を、確率的な世界に持ち込んでいることから生まれる誤解です。 • 求められるのは、確定性を前提とした設計の見直しです。確率的な出力を受け入れたうえで、品質をどう評価するか・どこま でを許容範囲とするか・どう補完するか。
13 Copyright(C) NRI Netcom, Ltd. All rights reserved. まとめ ▪
最新のトレンドをすべて追い続ける必要はありません。ただ、普遍的で本質的な情報にはアンテナを 張り続けることが重要です。AIがどれだけ進化しても、最後に残るのは判断する人間です。既にその 兆候は始まっています。 ▪ 生成AIを使いこなすためには、ツールの習熟より先に、判断できる知見と思考の土台を持っておくこと が、これからの時代の最大の武器になります。
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}