Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Backlog の運用監視 / Operational Monitoring of Backlog
Search
株式会社ヌーラボ
PRO
October 30, 2017
Technology
8.3k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Backlog の運用監視 / Operational Monitoring of Backlog
2017年10月30日(月)に行われたGeeks Who Drink in福岡 モニタリング勉強会edition でヌーラボの松浦が発表した、「Backlogの運用監視」の資料です。
株式会社ヌーラボ
PRO
October 30, 2017
More Decks by 株式会社ヌーラボ
See All by 株式会社ヌーラボ
The_Evolution_of_Bits_AI_SRE.pdf
nulabinc
PRO
0
340
進化するBits AI SREと私と組織
nulabinc
PRO
4
800
実践 Datadog MCP Server
nulabinc
PRO
4
800
全社横断PjM⽀援チーム “PEaS”の取り組みと プロジェクトマネジメント でのAI活⽤について
nulabinc
PRO
0
190
Datadog の RBAC のすべて
nulabinc
PRO
4
840
Datadog Live Tokyo 2025登壇資料
nulabinc
PRO
0
180
How to Migrate Your Backlog Free Plan
nulabinc
PRO
0
250
チームワークマネジメント Bar #5
nulabinc
PRO
0
95
Geeks Who Drink Fukuoka - 202508
nulabinc
PRO
0
72
Other Decks in Technology
See All in Technology
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
12
5.5k
認証認可だけじゃない! ID管理の構成要素と ライフサイクルを意識しよう
ritou
1
540
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
1
150
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.9k
貴方はどのエンジニアリングを磨くのか
hatyibei
0
100
SRE Lounge Hiroshimaへの招待
grimoh
0
500
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.5k
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
240
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
CIで使うClaude
iwatatomoya
0
190
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.2k
Featured
See All Featured
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Utilizing Notion as your number one productivity tool
mfonobong
4
350
How to Talk to Developers About Accessibility
jct
2
290
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Skip the Path - Find Your Career Trail
mkilby
1
160
Typedesign – Prime Four
hannesfritz
42
3.1k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Claude Code のすすめ
schroneko
67
230k
Transcript
Backlog の運用監視 松浦 祐亮 ‒ Nulab Inc. Geeks Who Drink
in Fukuoka モニタリング勉強会 Edition
自己紹介 ‒ Yusuke Matsuura @matsuzj ‒ Nulab Inc. ‒ Site
Reliability Engineer @Backlog ‒ 趣味は登山・キャンプ ‒ Job ‒ Web サービスの開発/運用を始めて11年ぐらい経ちます ‒ アプリケーションエンジニアからインフラ方面へ ‒ 現在は運用・改善・トラブルシュート等 ‒ Team ‒ 2015年7月から Nulab のインフラ担当としてジョイン ‒ 2016年9月から SRE チームを2名で発足 ‒ 2017年8月から SREメンバーが追加されて3名体制へ
話す内容 1. Backlog の歴史と経緯 2. Backlog の運用と監視の概要 3. 運用監視内容と改善サイクルについて 4.
今後改善したいこと
1. Backlog の歴史と経緯
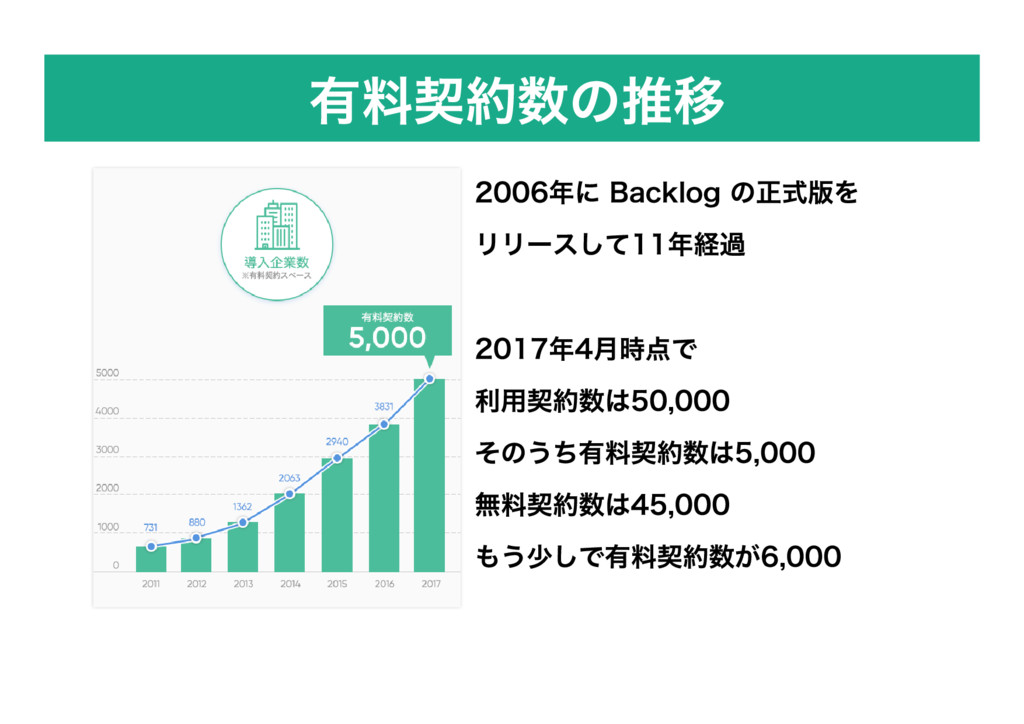
有料契約数の推移 2006年に Backlog の正式版を リリースして11年経過 2017年4月時点で 利用契約数は50,000 そのうち有料契約数は5,000 無料契約数は45,000 もう少しで有料契約数が6,000
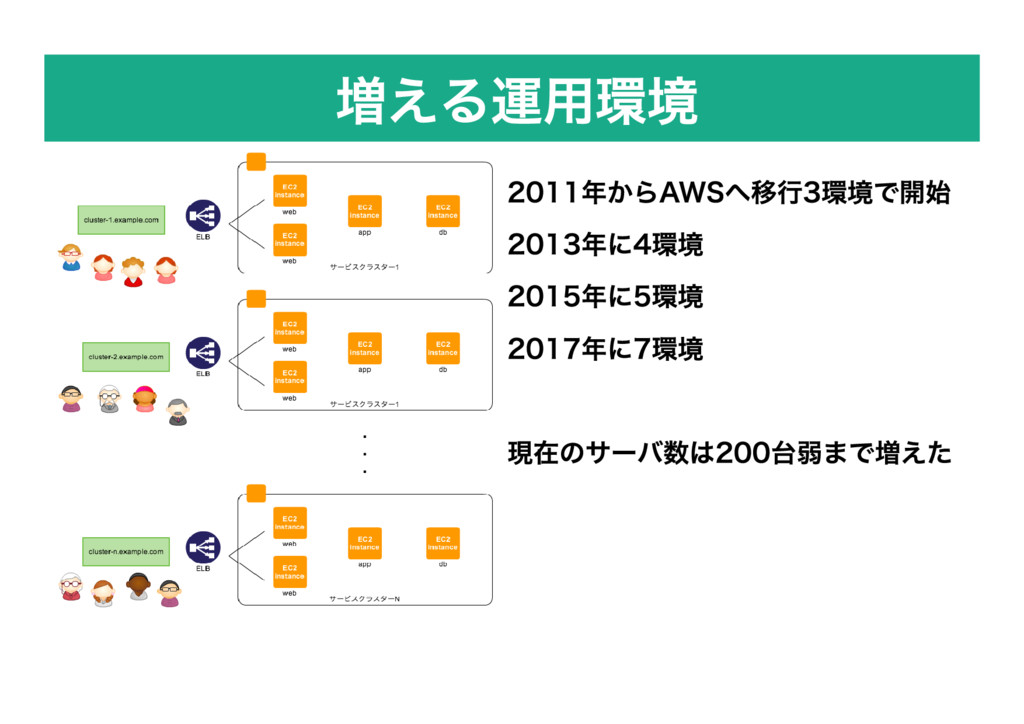
増える運用環境 2011年からAWSへ移行3環境で開始 2013年に4環境 2015年に5環境 2017年に7環境 現在のサーバ数は200台弱まで増えた
11年もやってるとレガシーな システムになって運用も大変 なんじゃない?
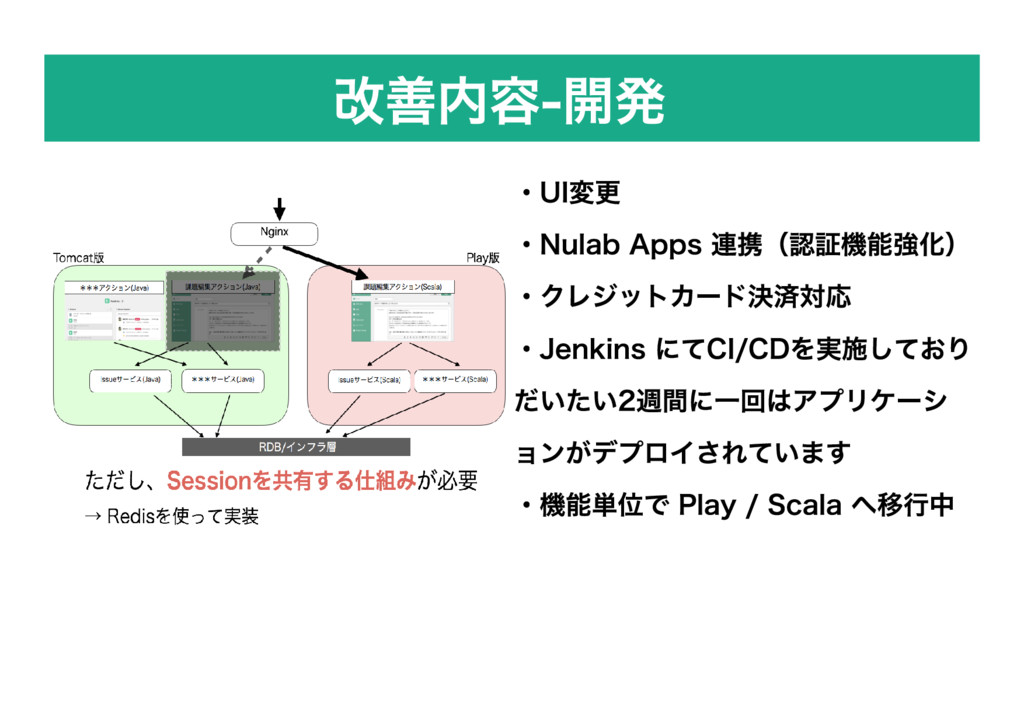
改善内容 ‒ 開発 ・UI変更 ・Nulab Apps 連携(認証機能強化) ・クレジットカード決済対応 ・Jenkins にてCI/CDを実施しており
だいたい2週間に一回はアプリケーシ ョンがデプロイされています ・機能単位で Play / Scala へ移行中
改善内容 ‒ 運用 ・Infrastructure as Code の実施 (Terraform, Ansible, Serverspec,
awspec) ・運用環境をより安定性の高いものへ 移行(EC2, ALB , RDS for Aurora, ElasticCash, VPC) ・ミドルウェアの改善・開発(Proxy サーバ設置, Git SSH サーバの更新、 画像配信方法の変更)
長くBacklog を使っていただ けるようにメンバー全員で常 に改善を実施しています
前置きが長くなりましたが運 用と監視について説明してい きます
2. Backlog の運用と監視概要
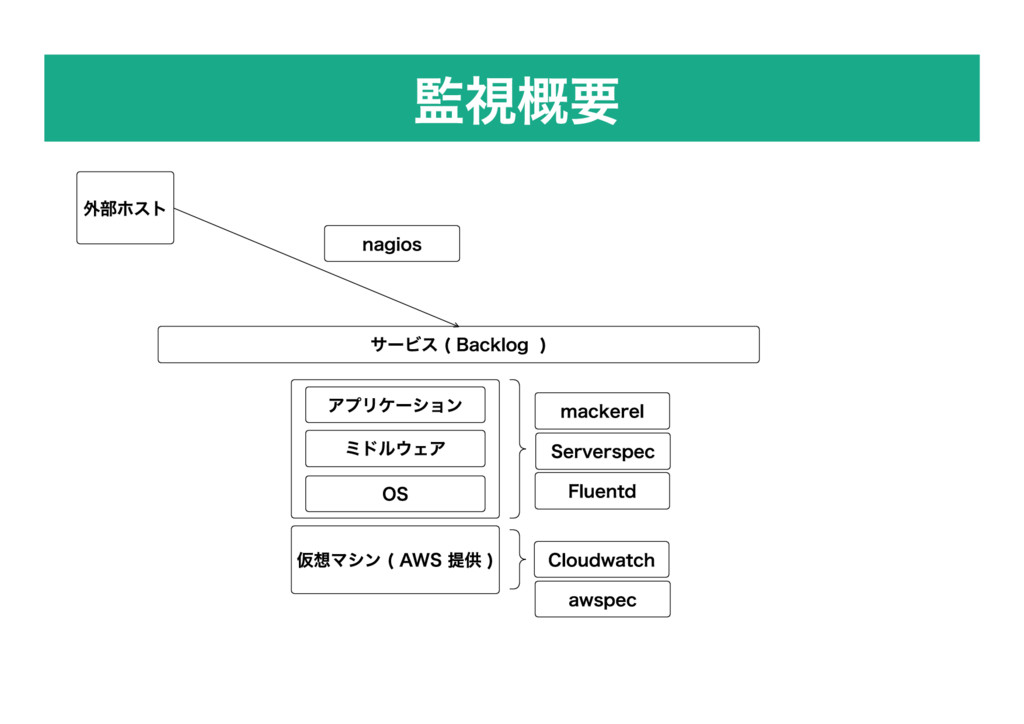
監視概要 仮想マシン ( AWS 提供 ) 外部ホスト OS ミドルウェア アプリケーション
Cloudwatch mackerel サービス ( Backlog ) nagios Serverspec awspec Fluentd
Nagios ユーザーの操作に近いところを監視しています ・アプリケーションの外形監視 ・Git にログインできるか ・WebDAV にログインできるか ・SSL 証明書の有効期限は過ぎていないか ・RDS
のAレコードのチェック(フェイルオーバーの検 知)
Mackerel ホスト単位の監視はすべて Mackerel (mon)で実施 ・2014年からMackerelを使用 ・Role単位でグラフがみれるため傾向分析がしやすい ・インスタンスのスケールアップした後傾向分析しやすい ・さっとプラグインを作成できるのがお気に入り
Mackerelグラフサンプル
Fluentd ・アプリケーションログをパースして通知したい場合等に 利用 ・すべての環境の MySQL スローログを集約し、毎日 pt‒ query‒digest で傾向分析する
Serverspec サーバの構成をテスト ・変更点がレポジトリに push された場合に Jenkins に てテストを実施 ・日に3回 Jenkins
によるテストを実施 ・ミドルウェアやアプリケーションの設定値が正しいか ・ディスクのマウント先が正しいか ・必要なデーモンが起動しているか ・サーバプロビジョニングが正しく行われたか ・Serverspec が通ってから Mackerel を起動します
awspec AWSリソースの設定をテスト ・RDSの構成チェックやパラメータグループの設定 ・EIPが正しいインスタンスにアタッチされているか ・EBSが正しいインスタンスにアタッチされているか ・永続化層は Terraform では作成しないためテストを書 いている
監視まとめ ・Mackerel だけ監視することはできるが、冗長化のため Nagios は残しています ・無駄に見えるところもあるが多重でチェックをかけるよ うにしている ・複雑になっても気づかないよりはましなので監視項目を 増やしたが少し煩雑になってきている ・マネージドのサービスを使っていないインスタンスはい
つでも入替えられるように構成管理のテストを充実させて います ・通知のチャネルは Typetalk 使ってます
3. 運用監視内容と改善サイク ルについて
改善内容 日々の運用状況をみて発生ベースで対応しています ・アプリケーションの負荷状況をみてアプリケーションサ ーバを増やす ・DBサーバの負荷状況に応じてスケールアップする ・アプリケーションのデプロイに問題があれば状況をみて ロールバックを実施、原因がわかっていればサーバの数を 増やす、スケールアップをして次のリリースまで運用する こともある( リリース予定は
Google Calendar に記載 ) ・わりとフレキシブルに構成変更をしています
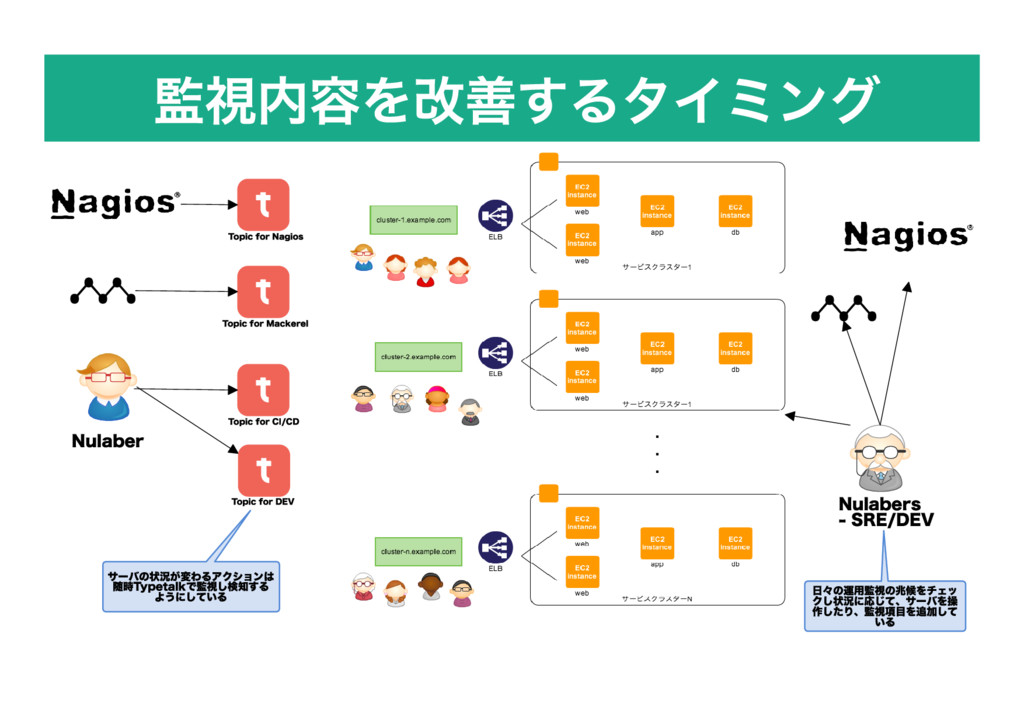
監視内容を改善するタイミング Topic for Nagios Topic for CI/CD Topic for Mackerel
サーバの状況が変わるアクションは 随時Typetalkで監視し検知する ようにしている 日々の運用監視の兆候をチェッ クし状況に応じて、サーバを操 作したり、監視項目を追加して いる Nulaber Topic for DEV Nulabers ‑ SRE/DEV
4. まとめ・今後改善したいこと
問題点 今回改めて本を読みました Mackerel を生かしきれてない箇所がめ だった ・Ansible での Role が細分化されてい ない箇所があるため、そのまま監視項目
が反映されている ・独自プラグインを書いているものも多 いので公式によせていく
まとめ・今後改善したいこと ・監視内容は日々の積み重ね ・定期的な監視項目の見直しが足りていない ・不要なものは削除する ・ホストが日々増えていくが、削減に対する意識が足りなかった ・増えた go‒check‒plugins をチェックする ・mkr で
Mackerel 監視項目のコード化 ・マルチロールによる運用に変更 ・通知先の統一(PagerDuty導入)
インフラエンジニア募集 https://nulab‑inc.com/ja/about/careers/
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}