Nowaday, we all notice about the hard thing to escape the circulation of AI topics. One of the resions of AI, machine learning (especially deep ones) is the most interesting technology among them and use these tools without well consideration. So, I mumble about casual use of ML tools from the data minging point of view.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
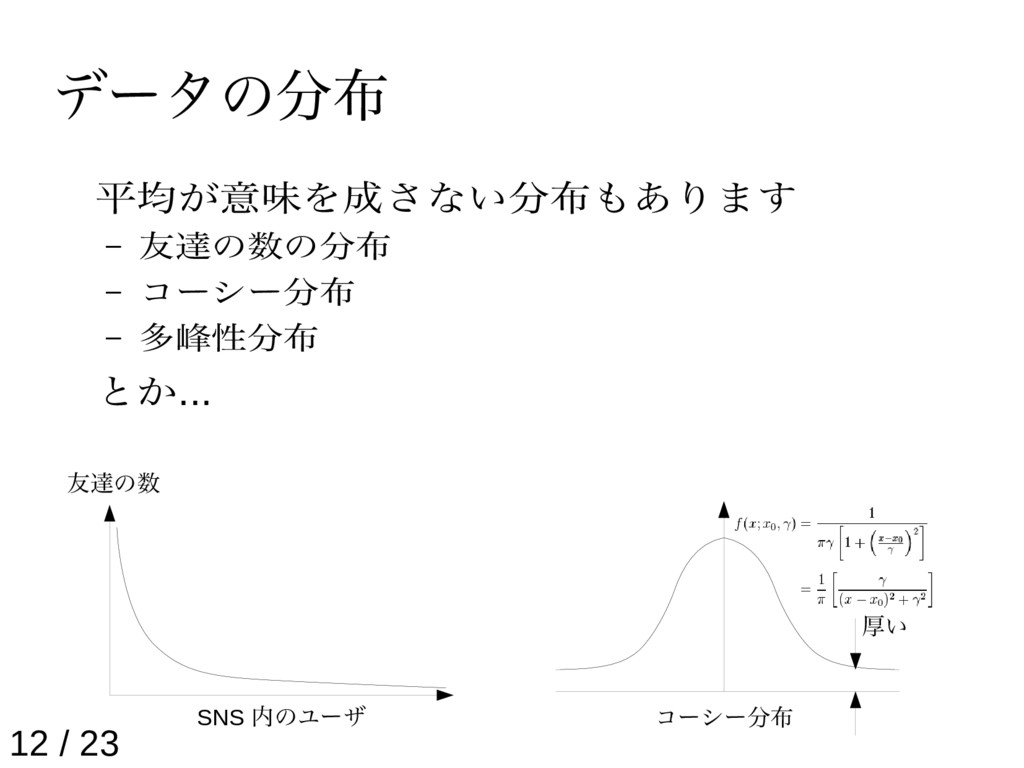{kind=link}
{kind=link}
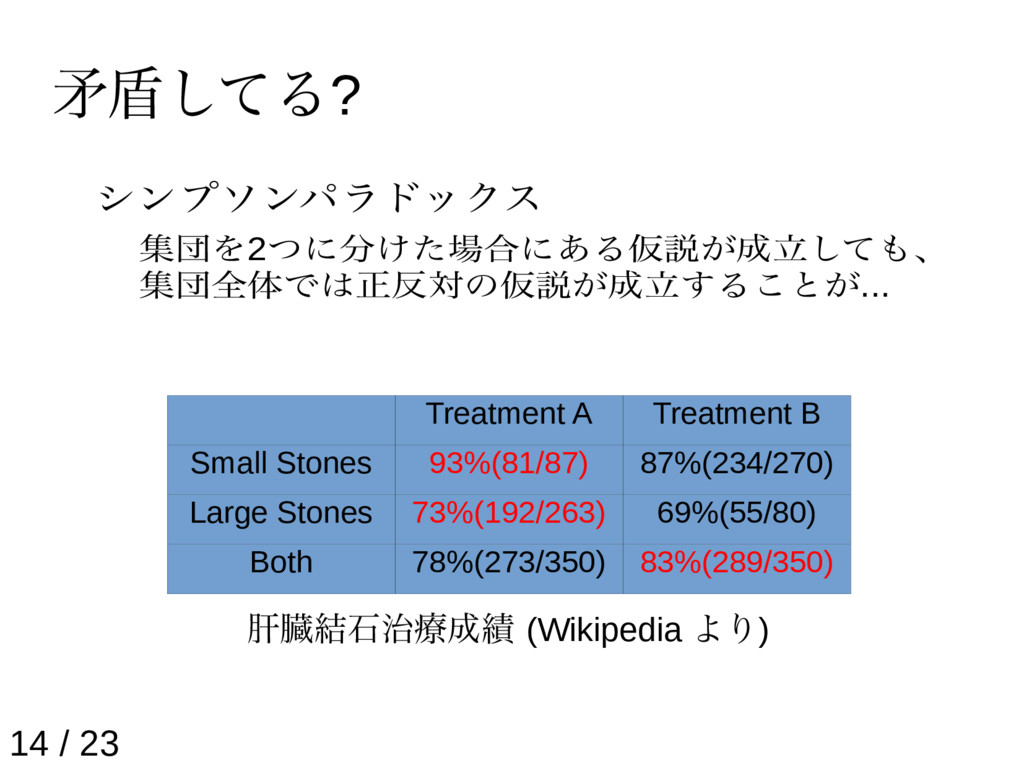{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}