Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
oku-slide-stat2-8
Search
Makito Oku
March 29, 2022
Education
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
oku-slide-stat2-8
数理統計学特論II
おまけ ベイズ法
奥 牧人 (未病研究センター)
Makito Oku
March 29, 2022
More Decks by Makito Oku
See All by Makito Oku
oku-slide-20260209
okumakito
0
82
oku-slide-20240802
okumakito
0
220
oku-slide-20231129
okumakito
0
200
oku-slide-20230827
okumakito
0
210
oku-slide-20230213
okumakito
0
320
oku-slide-20221212
okumakito
0
150
oku-slide-20221129
okumakito
0
230
oku-slide-20221115
okumakito
0
1.4k
oku-slide-20220820
okumakito
0
460
Other Decks in Education
See All in Education
Where Data Meets Storytelling
georgesinnott
0
130
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
0513
cbtlibrary
0
220
[2026前期火5] 論理学(京都大学文学部 前期 第5回)「 ならばの問題演習・proof net・かつの規則」
yatabe
0
360
NDIAS Automotive / IoT CTF 2026 Recap - Keyfob & OSINT
himitu23
0
220
Portable & Reproducible Research Environments in the Age of AI Agents
denkiwakame
0
490
2026年度春学期 統計学 第13回 不確かな測定の不確かさを測る ― 不偏分散とt分布 (2026. 6. 25)
akiraasano
PRO
1
110
✅ レポート採点基準 / How Your Reports Are Assessed
yasslab
PRO
0
390
Beyond the Prompt: Programming as a Pathway to Statistical Thinking
minecr
0
230
Examen de Selectividad. Geografía junio 2026 (Convocatoria Ordinaria). UCLM
juanmartin2026
1
1.9k
焦燥を平穏に変えるエンジニアのための哲学
ichimichi
7
5.7k
[2026前期火5] 論理学(京都大学文学部 前期 第3回)「形式言語と四つのキーワード:メタ・構成・意味論・ハーモニー」
yatabe
0
590
Featured
See All Featured
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
30 Presentation Tips
portentint
PRO
1
350
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Navigating Weather and Climate Data
rabernat
0
340
Code Review Best Practice
trishagee
74
20k
The Cult of Friendly URLs
andyhume
79
6.9k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
The agentic SEO stack - context over prompts
schlessera
0
840
Crafting Experiences
bethany
1
210
Transcript
数理統計学特論II おまけ ベイズ法 奥 牧人 (未病研究センター) 1 / 35
前回の復習 前回の目的 最尤推定と尤度比検定の漸近特性に関する証明の概要を理解する こと 前回の達成目標 最尤推定量の漸近有効性の証明に使う用語を複数あげられる。 カルバック・ライブラー情報量の意味を説明できる。 対数尤度比が漸近的に 分布に従う理由を説明できる。 χ2
2 / 35
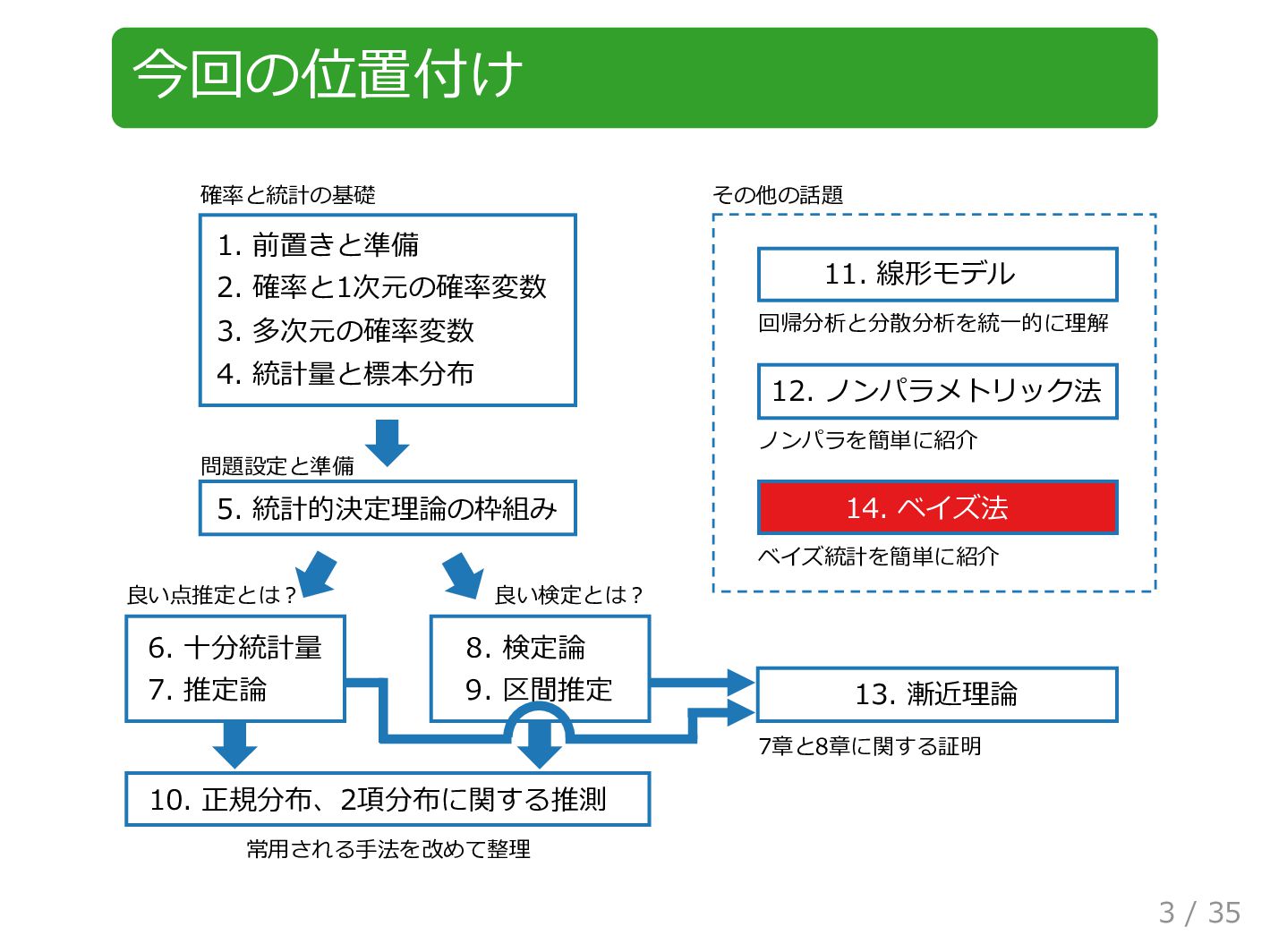
今回の位置付け 1. 前置きと準備 2. 確率と1次元の確率変数 3. 多次元の確率変数 4. 統計量と標本分布 5.
統計的決定理論の枠組み 6. ⼗分統計量 7. 推定論 8. 検定論 9. 区間推定 10. 正規分布、2項分布に関する推測 その他の話題 11. 線形モデル 12. ノンパラメトリック法 13. 漸近理論 14. ベイズ法 確率と統計の基礎 良い点推定とは︖ 良い検定とは︖ 問題設定と準備 7章と8章に関する証明 回帰分析と分散分析を統⼀的に理解 常⽤される⼿法を改めて整理 ベイズ統計を簡単に紹介 ノンパラを簡単に紹介 3 / 35
今回の目的と達成目標 目的 ベイズ統計学の基本用語の意味を理解すること 達成目標 ベイズの定理の式を書くことができる。 事前分布と事後分布の意味を説明できる。 MAP推定の意味を説明できる。 共役事前分布の意味を説明できる。 4 /
35
予習用キーワードの確認 ベイズの定理 ベータ分布 5 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 6 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 7 / 35
ベイズ統計学と古典的統計学 古典的統計学 1920年代に基礎が成立 パラメータを固定値と考える ベイズ統計学 1950年代以降に発展 (トーマス・ベイズは18世紀の人物) パラメータを確率変数と考える 8 /
35
ベイズの定理 確率質量関数または確率密度関数を などと書く。 同時確率/同時確率密度の分解 ベイズの定理 ( とする) p(x) p(x, y)
= p(x|y)p(y) = p(y|x)p(x) p(y) ≠ 0 p(x|y) = p(y|x)p(x) p(y) 9 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 10 / 35
事前分布と事後分布 ベイズの定理の式にパラメータ と観測データ を代入 を 事前分布 (prior distribution) という。 を
事後分布 (posterior distribution) という。 は尤度関数 θ x = (x1 , … , xn ) p(θ|x) = p(x|θ)p(θ) p(x) ∝ p(x|θ)p(θ) p(θ) p(θ|x) p(x|θ) 11 / 35
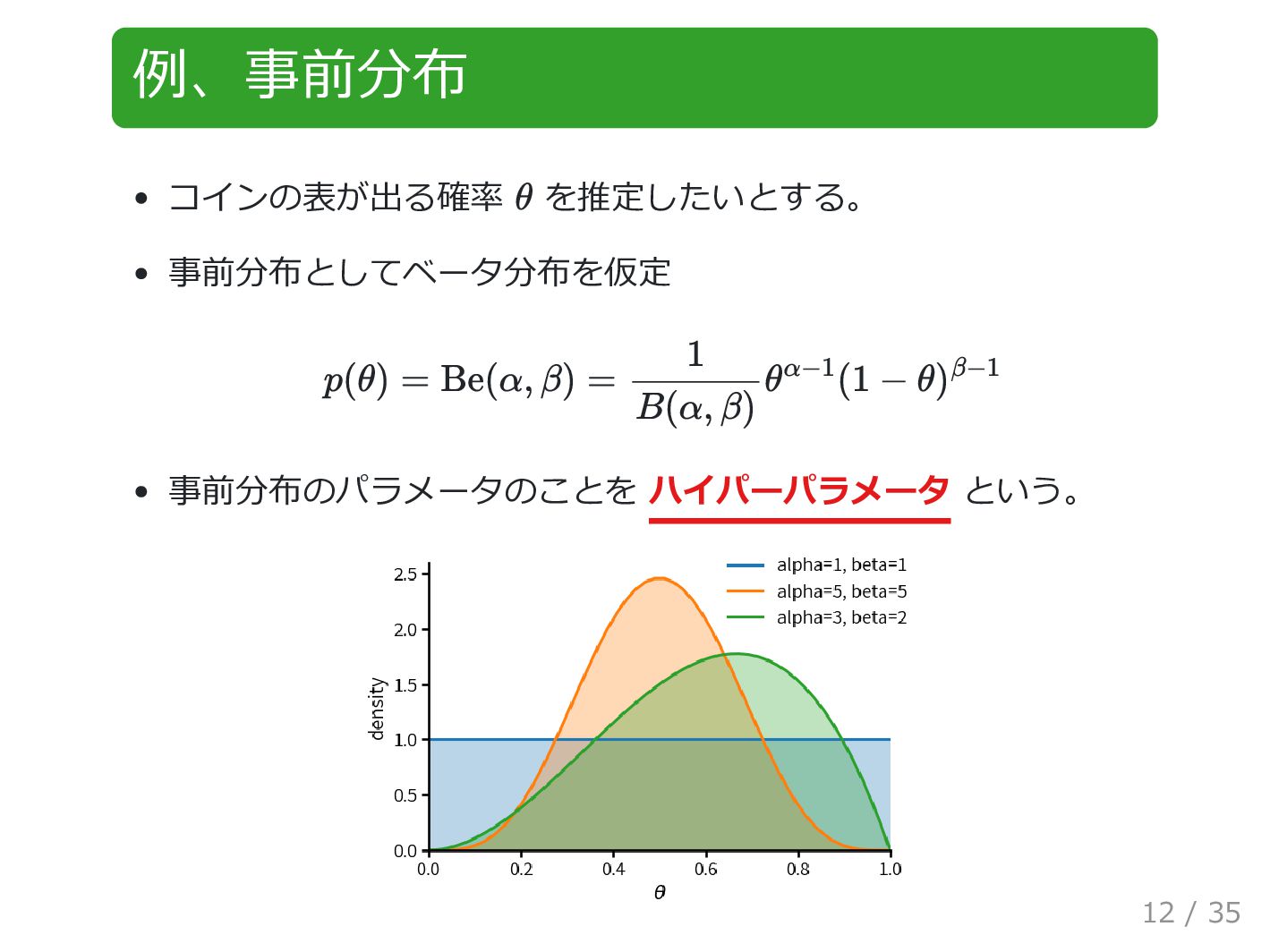
例、事前分布 コインの表が出る確率 を推定したいとする。 事前分布としてベータ分布を仮定 事前分布のパラメータのことを ハイパーパラメータ という。 θ p(θ) =
Be(α, β) = 1 B(α, β) θ α−1 (1 − θ) β−1 12 / 35
例、尤度関数 回投げたときに表の出る回数を とおくと 尤度関数 n X X ∼ Bin(n, θ)
p(x|θ) = ( )θ x (1 − θ) n−x n x 13 / 35
例、分母の計算 分母の を計算 ベータ関数 p(x) p(x) = ∫ 1 0
p(x, θ)dθ = ∫ 1 0 p(x|θ)p(θ)dθ = ∫ 1 0 ( )θ x (1 − θ) n−x 1 B(α, β) θ α−1 (1 − θ) β−1 dθ = ( ) B(α + x, β + n − x) B(α, β) n x n x B(a, b) = ∫ 1 0 y a−1 (1 − y) b−1 dy 14 / 35
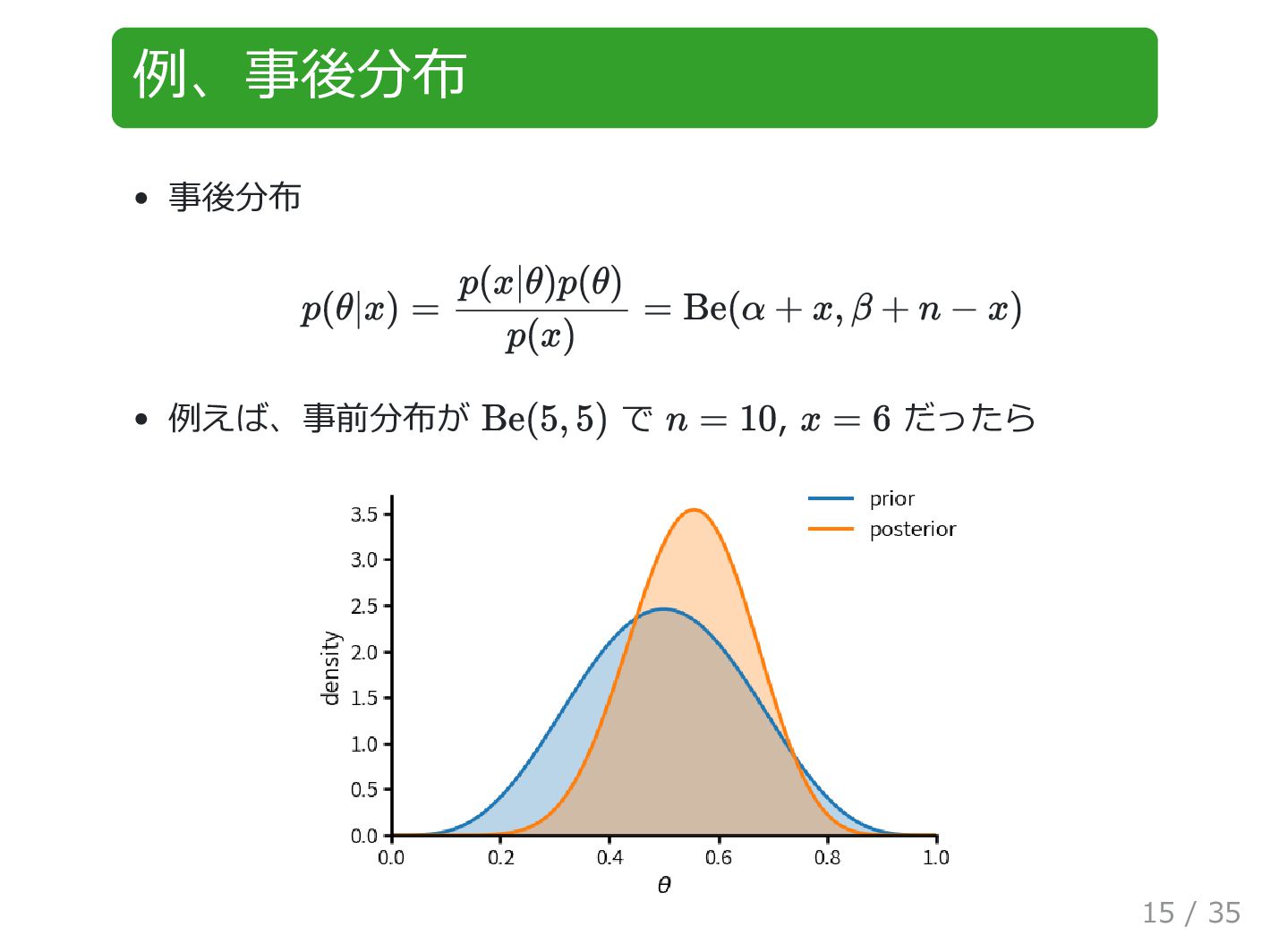
例、事後分布 事後分布 例えば、事前分布が で , だったら p(θ|x) = p(x|θ)p(θ) p(x)
= Be(α + x, β + n − x) Be(5, 5) n = 10 x = 6 15 / 35
例、平均値の変化 事前分布の平均値 事後分布の平均値 (ベイズ推定量) と との内分点 E[θ] = α α
+ β E[θ|x] = α + x α + β + n = α + β α + β + n ⋅ α α + β + n α + β + n ⋅ x n E[θ] x/n 16 / 35
点推定 以降では事後分布が連続分布の場合について説明する。 ベイズ推定量 (事後分布の平均値) MAP (maximum a posteriori) 推定量 (事後分布の最頻値)
MAP 推定量は分子の のみを使って計算できる。 ^ θ = E[θ|x] = ∫ θ p(θ|x)dθ ^ θ = arg max θ p(θ|x) p(x|θ)p(θ) 17 / 35
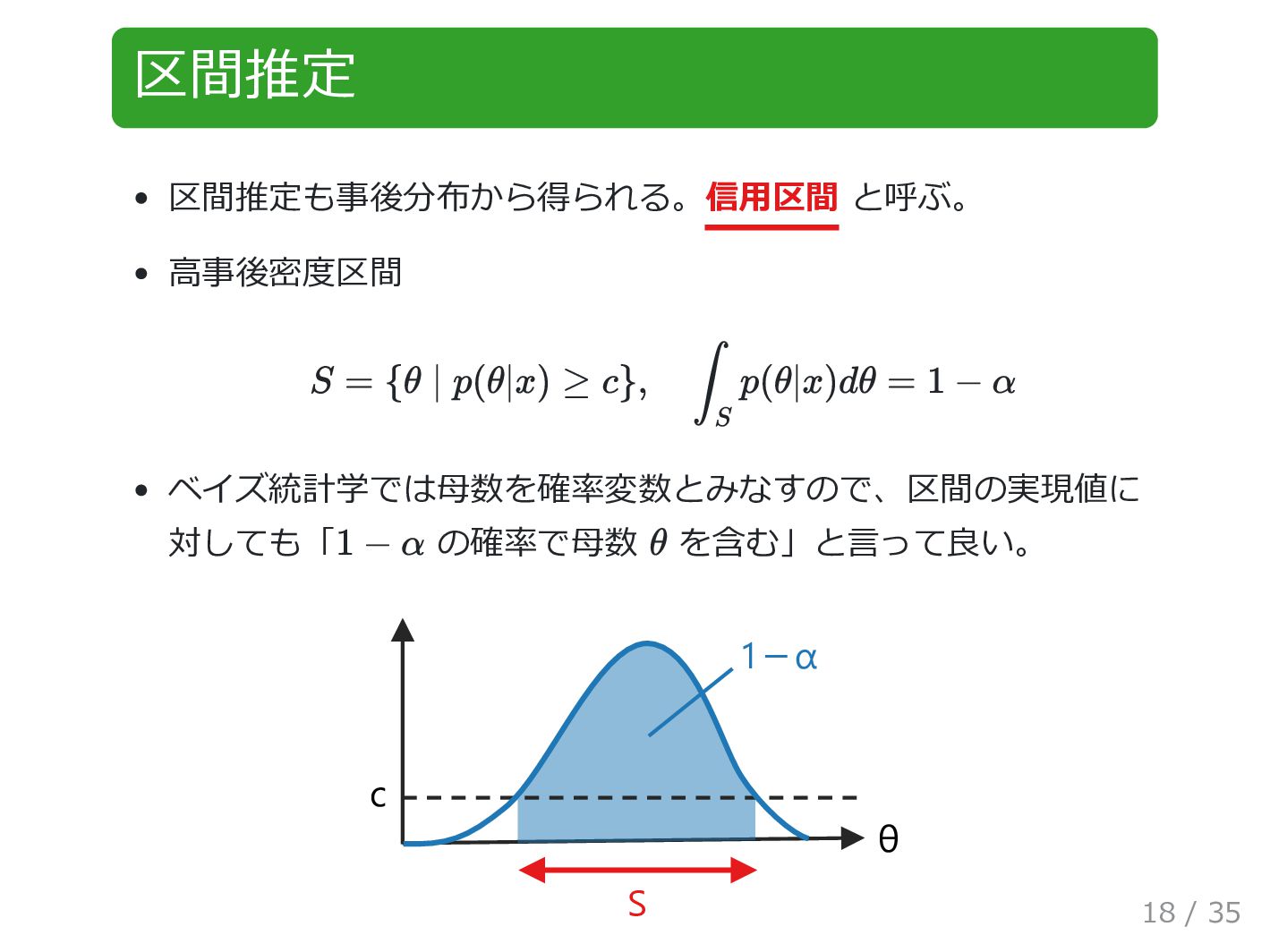
区間推定 区間推定も事後分布から得られる。信用区間 と呼ぶ。 高事後密度区間 ベイズ統計学では母数を確率変数とみなすので、区間の実現値に 対しても「 の確率で母数 を含む」と言って良い。 θ c
1-α S S = {θ ∣ p(θ|x) ≥ c}, ∫ S p(θ|x)dθ = 1 − α 1 − α θ 18 / 35
検定、単純仮説の場合 帰無仮説と対立仮説がともに単純仮説の場合 母数空間は なので、事前分布は以下の形 検定は単純に、事後確率が大きい方を採用 この場合、書き直すと尤度比検定になっている H0 : θ =
θ0 vs. H1 : θ = θ1 {θ0 , θ1 } p(θ0 ) = π0 , p(θ1 ) = π1 = 1 − π0 p(θ1 |x) > p(θ0 |x) ⇒ reject p(x|θ1 ) p(x|θ0 ) > π0 π1 ⇒ reject 19 / 35
検定、複合仮説の場合 帰無仮説と対立仮説がともに複合仮説の場合 ただし , とする 事前分布 検定は、事後確率の大きい方を採用 H0 : θ
∈ Θ0 vs. H1 : θ ∈ Θ1 Θ0 ∪ Θ1 = Θ Θ0 ∩ Θ1 = ∅ p(θ) ∫ Θ 0 p(θ)dθ = π0 , ∫ Θ 1 p(θ)dθ = π1 = 1 − π0 ∫ Θ 1 p(θ|x)dθ > ∫ Θ 0 p(θ|x)dθ ⇒ reject 20 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 21 / 35
共役事前分布 先ほどのコイン投げの例では、事前分布と事後分布がいずれも ベータ分布の形をしていた。 また、尤度関数は二項分布だった。 共役事前分布 尤度関数の分布族に対して、事前分布と事後分布が同じ分布 族となるように選んだ事前分布のこと 22 / 35
無情報事前分布 事前の情報が無いときには 無情報事前分布 を使う。 積分すると にならない場合が多いが、広義の分布と考える。 位置母数 に対する無情報事前分布 尺度母数 に対する無情報事前分布
ジェフリーズの事前分布 (母数の変換に対して不変) 1 μ p(μ) = c, c > 0, − ∞ < μ < ∞ τ p(τ ) = c τ , c > 0, 0 < τ < ∞ p(θ) ∝ (det I(θ)) 1/2 23 / 35
複数の候補がある場合 先ほどのコイン投げの例では事前分布を と仮定した。 一様分布が適切だと考えるなら ジェフリーズの事前分布が適切だと考えるなら 一方、事後分布が なので、 を事前の 成功回数、 を事前の失敗回数とみなすことが出来る。
事前の回数をともに とするのが適切だと考えるなら、 に対応する広義の分布が適切 Be(α, β) Be(1, 1) Be(1/2, 1/2) Be(α + x, β + n − x) α β 0 α = β = 0 p(θ) ∝ θ −1 (1 − θ) −1 24 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 25 / 35
統計的決定理論の復習 推定と検定をまとめて扱うための理論的枠組み 決定 推定の場合、パラメータの推定値 検定の場合、 を選ぶなら 、 を選ぶなら 損失関数 推定の場合、
検定の場合、合っていれば 、間違っていれば リスク関数 d = δ(x) H0 0 H1 1 L(θ, d) (θ − d) 2 0 1 R(θ, δ) = E x|θ [L(θ, d)] 26 / 35
統計的決定理論の復習、続き 2つの決定関数 があるとき、全ての について なら「 は より良いか同等」といい、 と書く。 少なくとも1つの で等号が外れていれば
と書く。 ある決定関数 に対して、 となる が存在しなければ、 は 許容的 という。 δ1 , δ2 θ R(θ, δ1 ) ≤ R(θ, δ2 ) δ1 δ2 δ1 ⪰ δ2 θ δ1 ≻ δ2 δ δ ∗ ≻ δ δ ∗ δ 27 / 35
統計的決定理論の復習、続き ベイズリスク: リスク関数の事前分布 に関する期待値 ベイズ決定関数: ベイズリスクが最小の決定関数 π r(π, δ) =
∫ R(θ, δ)p(θ)dθ r(π, δ ∗ ) ≤ r(π, δ), ∀δ 28 / 35
事後分布を使った形に書き換え ベイズリスクを書き換え の実現値ごとに、事後分布に関する損失関数の期待値を最小化 する決定 を選べば、ベイズ決定関数になる。 r(π, δ) = ∫ R(θ,
δ)p(θ)dθ = ∫ (∫ L(θ, d)p(x|θ)dx)p(θ)dθ = ∫ (∫ L(θ, d)p(θ|x)p(x)dx)dθ = ∫ (∫ L(θ, d)p(θ|x)dθ)p(x)dx x d 29 / 35
ベイズ決定関数 点推定の場合は、事後分布の平均値 検定の場合は、事後確率が大きい方を採用 狭義の事前分布 に対するベイズ決定関数 が一意的であると き、 は許容的である。 通常は一意に定まる。 π
δ δ 30 / 35
Outline 1. ベイズ統計学と古典的統計学 2. 事前分布と事後分布 3. 事前分布の選択 4. 統計的決定理論から見たベイズ法 5.
ミニマックス決定関数と最も不利な分布 31 / 35
ミニマックス決定関数の復習 リスク関数の最大値 (最悪値) ミニマックス決定関数: リスク関数の最大値が最小の決定関数 ¯ R(δ) = sup θ
R(θ, δ) ¯ R(δ ∗ ) ≤ ¯ R(δ), ∀δ 32 / 35
最も不利な分布 ベイズリスクを最大化する事前分布を最も不利な分布という。 母数空間が有限集合でリスクセットが閉集合の場合、ミニマック ス決定関数は最も不利な事前分布に対するベイズ決定関数と一致 する。 33 / 35
まとめ ベイズ統計学の基本用語の意味を説明しました。 1. ベイズ統計学と古典的統計学 ! ベイズの定理の式を書くことができる? 2. 事前分布と事後分布 ! 事前分布と事後分布の意味を説明できる?
! MAP推定の意味を説明できる? 3. 事前分布の選択 ! 共役事前分布の意味を説明できる? 4. 統計的決定理論から見たベイズ法 5. ミニマックス決定関数と最も不利な分布 34 / 35
小テスト 今回はおまけなので、小テストの回答は必須ではありません。 試したい人はMoodleで小テストに回答して下さい。 回答した場合も成績には反映させません。 35 / 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![例、平均値の変化 事前分布の平均値 事後分布の平均値 (ベイズ推定量) と との内分点 E[θ] = α α](https://files.speakerdeck.com/presentations/0d1621da89ae41019f65f84520d71ef3/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}