Tổ chức: TopDev.
Chủ đề: Dữ liệu lớn và các bước tiếp cận trong 3 giờ
Speaker: Ông Xuân Hồng - Researcher engineer @ Trusting Social.
Ngày: 30/09/2017.
được, chỉ có thể tạo ra RDD mới. • Lazy evaluated: tính toán để đó, chừng nào có Action mới thực thi. • Distributed: phân tán trên các cluster/workers. RDD cơ bản
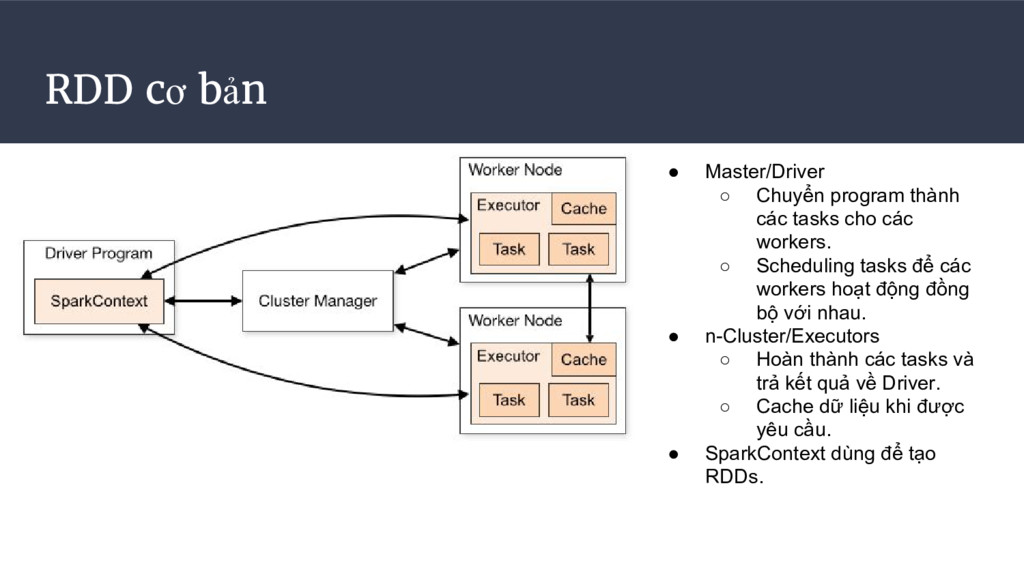
tasks cho các workers. ◦ Scheduling tasks để các workers hoạt động đồng bộ với nhau. • n-Cluster/Executors ◦ Hoàn thành các tasks và trả kết quả về Driver. ◦ Cache dữ liệu khi được yêu cầu. • SparkContext dùng để tạo RDDs.
filter() • distinct() • sample() • collect() • count() • countByValue() • take() • top() • takeOrdered() Các thao tác transformations chỉ được thực thi khi lệnh Actions được gọi. Ví dụ: hàm action collect() sẽ trigger hàm transformations map() thực hiện tính toán của mình.
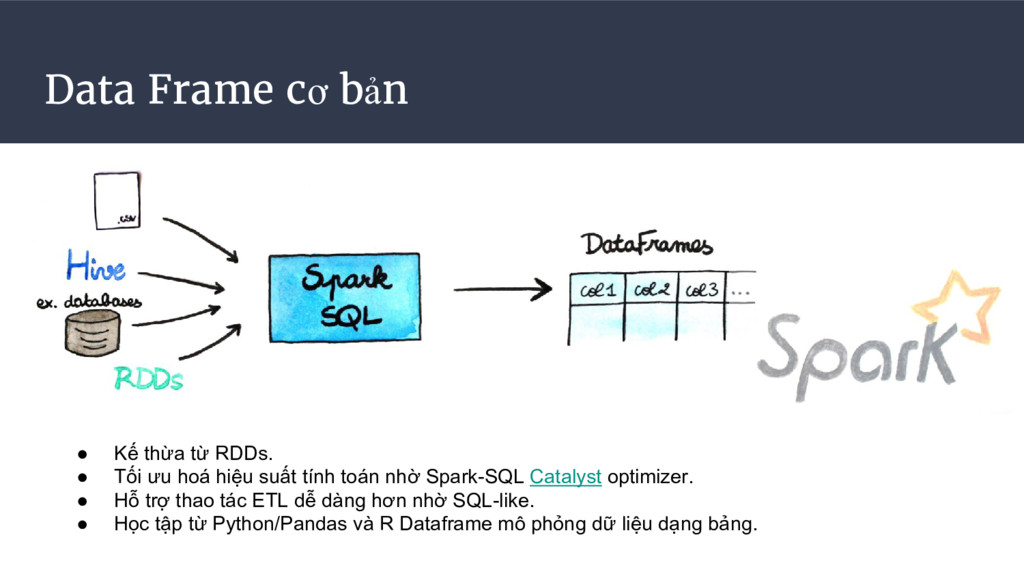
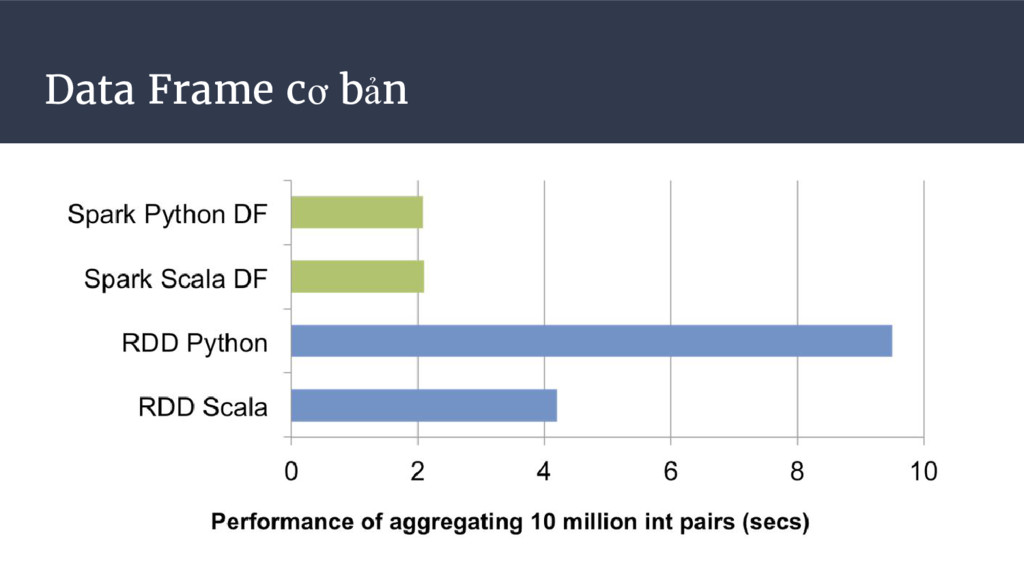
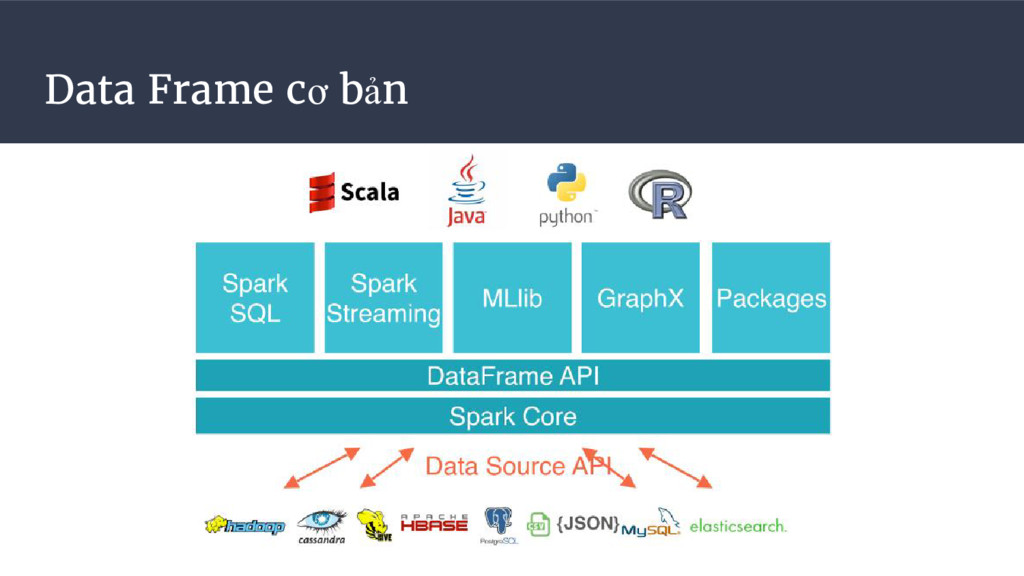
Tối ưu hoá hiệu suất tính toán nhờ Spark-SQL Catalyst optimizer. • Hỗ trợ thao tác ETL dễ dàng hơn nhờ SQL-like. • Học tập từ Python/Pandas và R Dataframe mô phỏng dữ liệu dạng bảng.
hiệu suất. • Nên dùng Schema để load đúng định dạng dữ liệu. • Binary (parquet, gzip) > Text (csv, json), File > Database. • Tự tạo dữ liệu Big Data bằng Mockaroo. • Nên sử dụng cache khi bảng dữ liệu được sử dụng nhiều lần tiếp đó. • Nên xoá cache trước khi khởi tạo cache mới để tránh tràn bộ nhớ. • Đối với bảng dữ liệu lớn nên lưu bảng tạm ra đĩa thay vì cache. • Code SparkSQL sáng sủa hơn Dataframe built-in function. • Upgrade lên version 2.0 khi có thể để tối ưu tính toán và quản lý bộ nhớ. • Học thông qua: ◦ Thực hành ◦ Cheat sheet ◦ Side project Kinh nghiệm
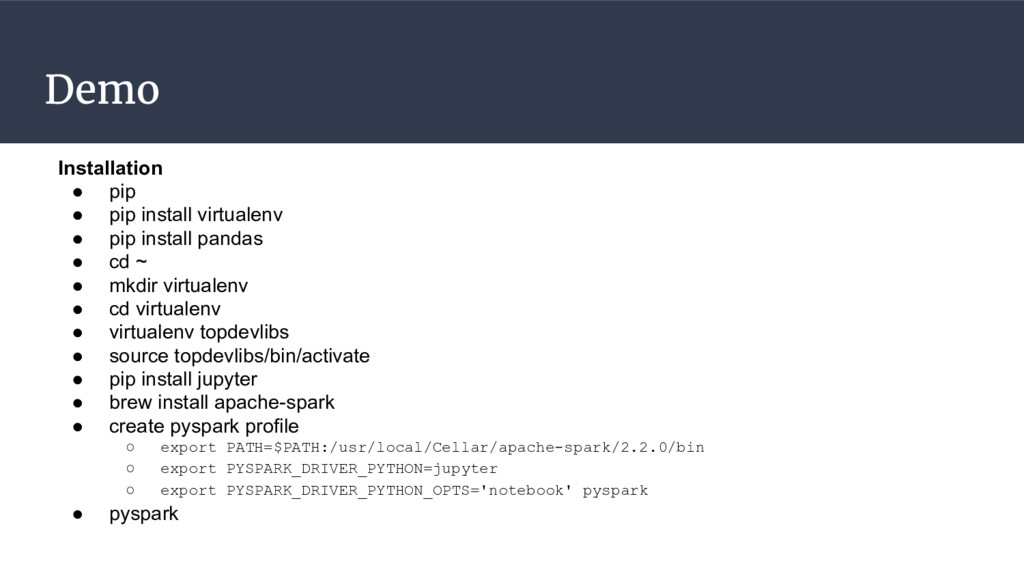
Marathon, Chronos. • Configuration cho Spark • Cách deploy bằng Docker. • Databricks community. • Load dữ liệu từ các source khác (MongoDB, MySQL, PostgreSQL, S3, JDBC, Cassandra …) • Làm việc với AWS S3, Google Cloud Storage. • Python vs Scala vs R. • Spark Dataframe vs Pandas Dataframe. • Cache vs Persist. • Cài notebook cho Spark Scala. • Cấu hình hệ thống notebook cho từng yêu cầu hệ thống khác nhau (spark-small, spark-medium, spark-large, spark-extra).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}