Nền tảng Thuật toán của AI, Machine Learning, Big Data
Tổ chức: TopDev.
Chủ đề: Nền tảng thuật toán của AI, Machine Learning, Big Data
Speaker: Ông Xuân Hồng - Researcher engineer @ Trusting Social.
Ngày: 15/10/2017.
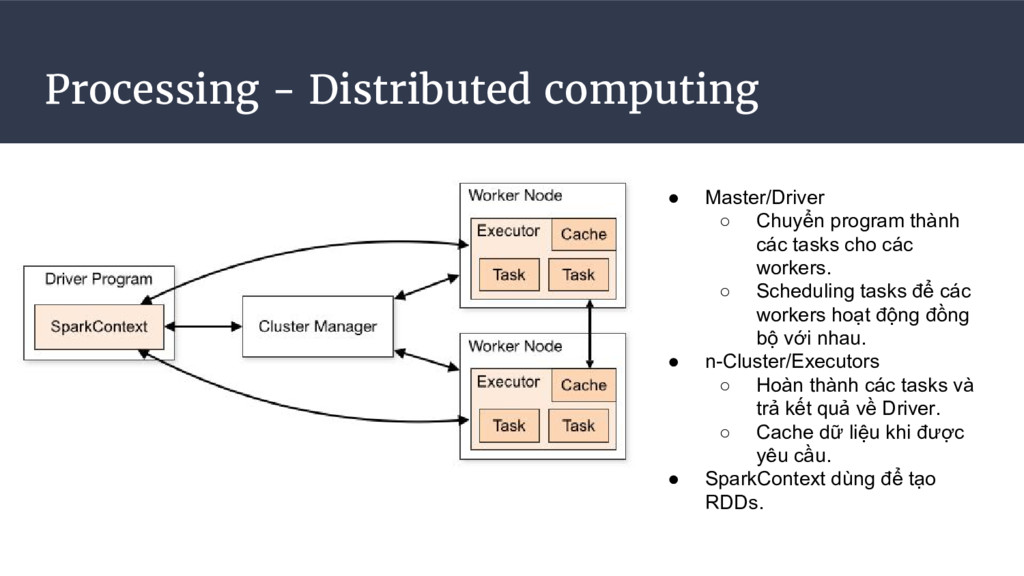
các tasks cho các workers. ◦ Scheduling tasks để các workers hoạt động đồng bộ với nhau. • n-Cluster/Executors ◦ Hoàn thành các tasks và trả kết quả về Driver. ◦ Cache dữ liệu khi được yêu cầu. • SparkContext dùng để tạo RDDs.
• MP4, MOV • Zip, gzip Compression Giả sử lưu lượng dữ liệu truyền qua Internet là 1.000.000.000 TB/s. Nếu kĩ thuật nén cải thiện được 0.1%. Ta sẽ tiết kiệm được 1.000.000.000 * 0.1 / 100 = 1.000.000 TB/s
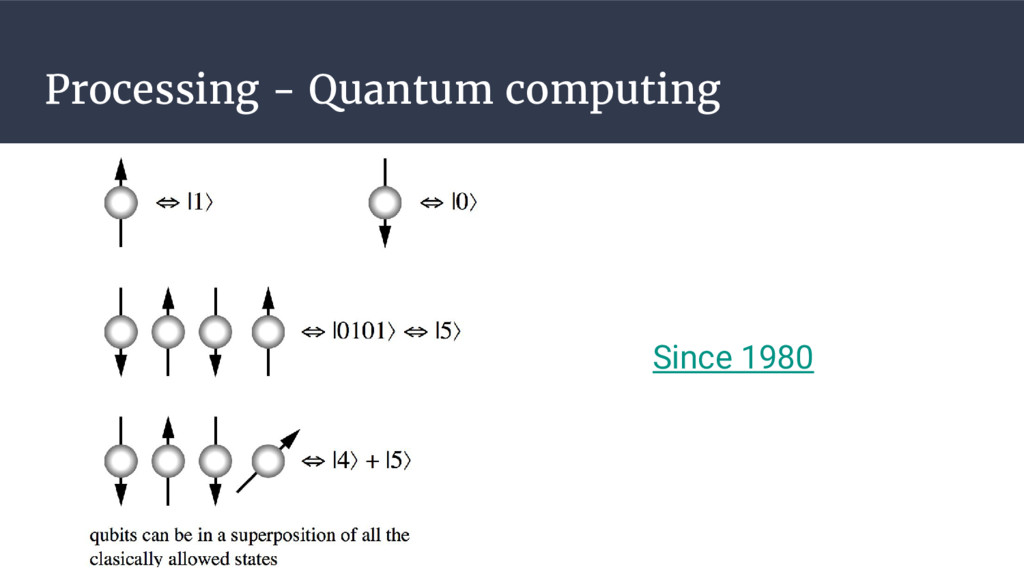
tốc tính toán. • Sử dụng vim, nano, less để quan sát file Big Data. • Kiến thức cần có: toán rời rạc, xác suất thống kê, đại số tuyến tính. ◦ Tính độ phức tạp. ◦ Đọc hiểu các giải thuật liên quan. • Sử dụng các công nghệ tiên tiến khi cần thiết: ◦ GPU, quantum computing • Yêu thích việc tối ưu tính toán. • Nên áp dụng thuật toán theo hướng: ◦ Chia để trị. ◦ Quy hoạch động. ◦ Xấp xỉ. ◦ Độ phức tạp không quá O(n^2). • Cố gắng thu nhỏ dữ liệu càng nhiều càng tốt: ◦ Lấy mẫu 1% quần thể. ◦ Giảm số chiều dữ liệu. • Nên sử dụng binary file parquet cho lưu trữ và tính toán Big Data. ◦ Kích thước được nén nhỏ. ◦ Column oriented Chia sẻ kinh nghiệm
Introduction to Algorithm, 3rd Edition (MIT Press) • Sketching algorithm for Big Data • Mining massive dataset (Stanford) • 7 techniques dimensionality reduction • Microsoft quantum computing Tham khảo thêm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
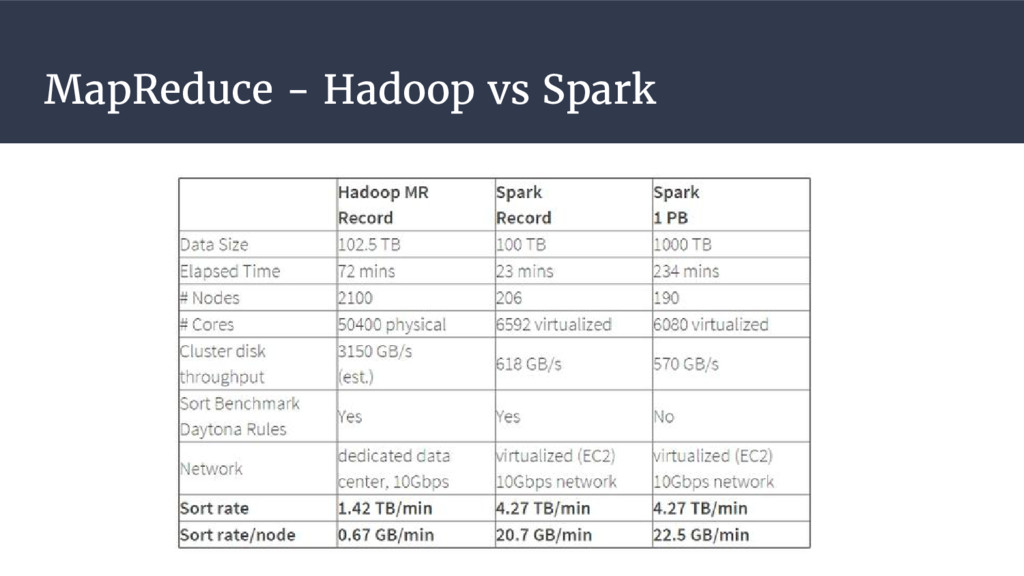{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
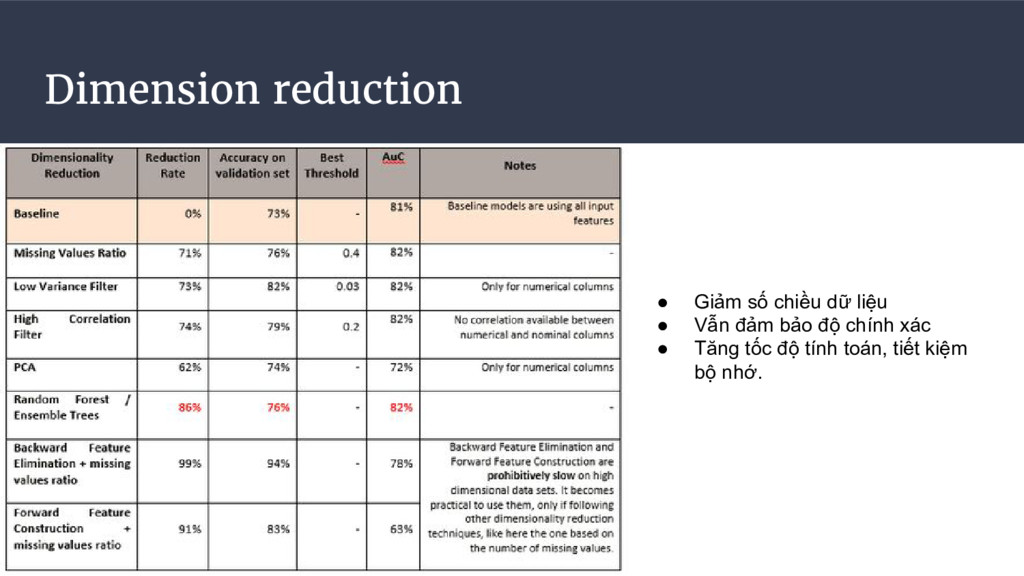{kind=link}
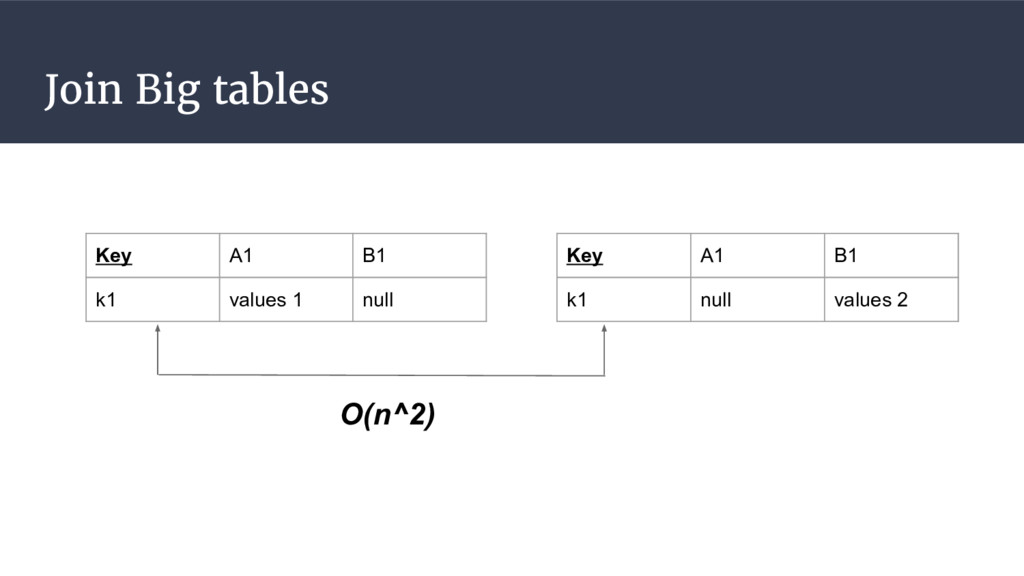{kind=link}
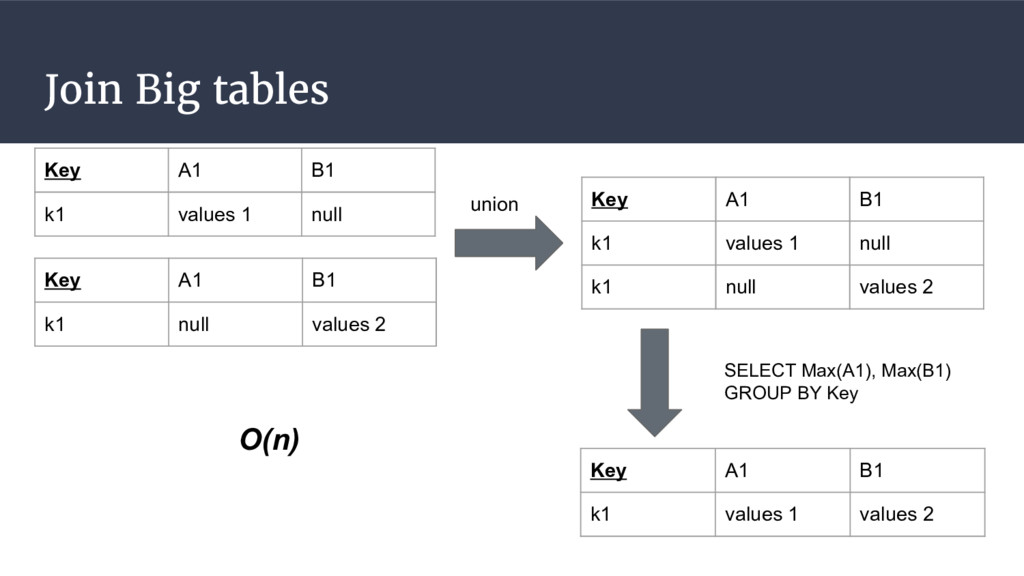{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}