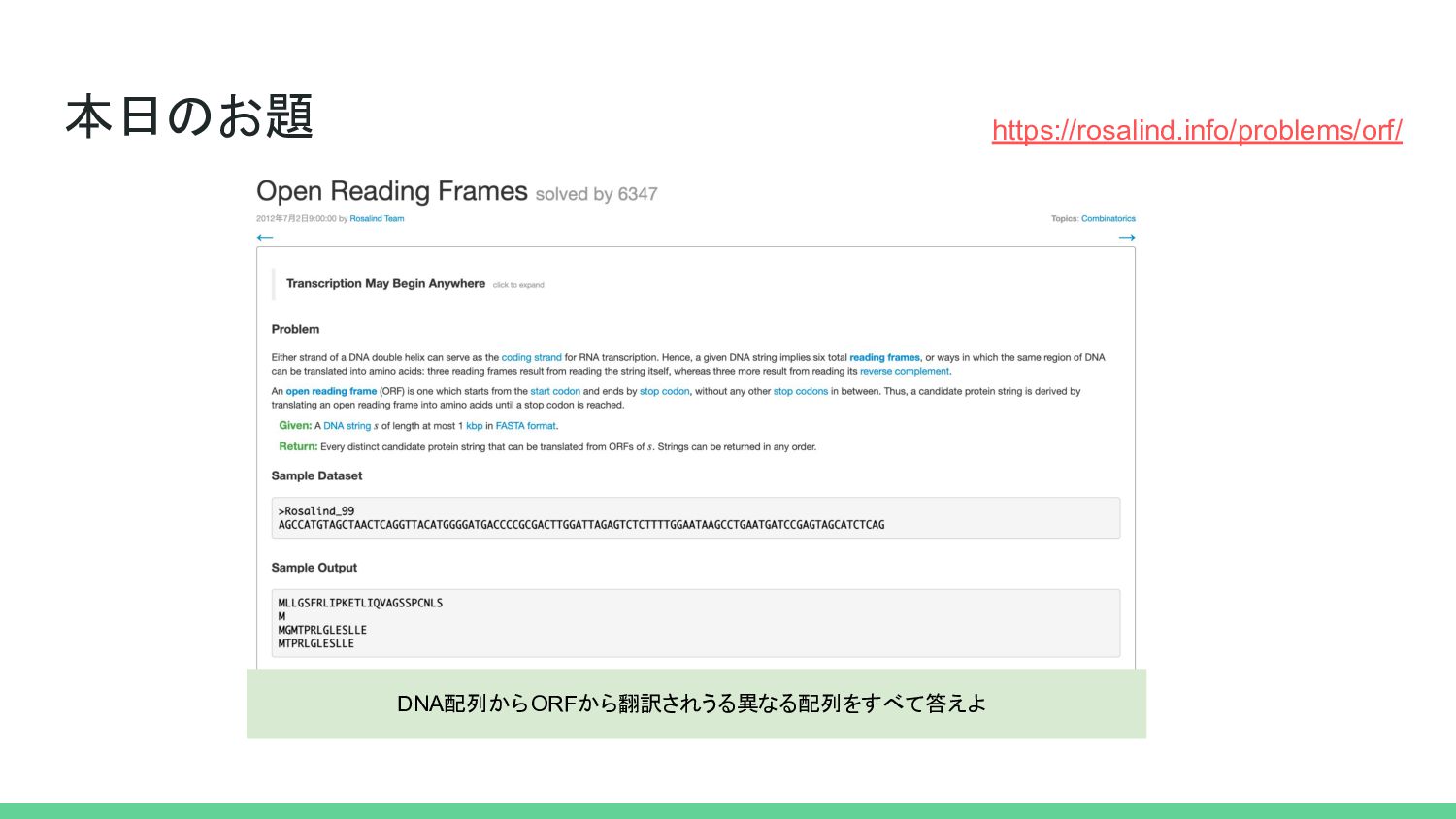
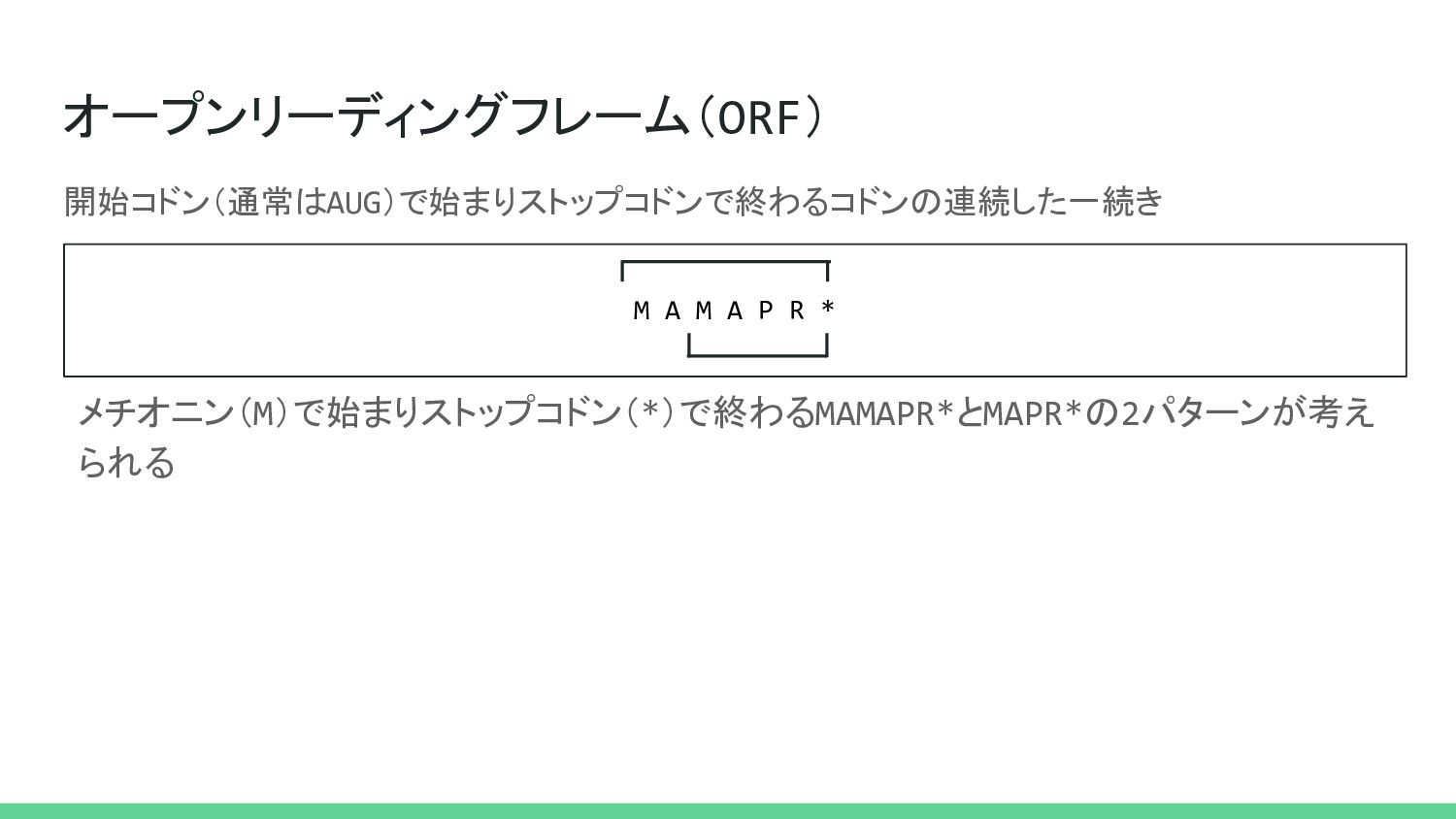
3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9 2 3 4 5 6 7 8 9 3で割ったときの余り部分を取り除けばWarningは解消される >>> Seq.translate('AAAACCCGGU') BiopythonWarning: Partial codon, len(sequence) not a multiple of three. Explicitly trim the sequen ce or add trailing N before translation. This may become an error in future. Biopythonでは3の倍数でない長さの配列を翻訳しようとするとWarningがでる https://en.wikipedia.org/wiki/File:Reading_Frame.png 核酸分子内のヌクレオチド配列を重なり合わない連続したトリプレットに分割する方法
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}