Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Finding the Longest Shared Subsequence: Finding...
Search
onouyek
February 04, 2022
Programming
300
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Finding the Longest Shared Subsequence: Finding K-mers, Writing Functions, and Using Binary Search
【第10回】ゼロから始めるゲノム解析 (Python編)
onouyek
February 04, 2022
More Decks by onouyek
See All by onouyek
Finding Open Reading Frames
onouyek
0
390
Inferring mRNA from Protein: Products and Reductions of Lists
onouyek
0
380
Find a Motif in DNA: Exploring Sequence Similarity
onouyek
0
350
Finding the Hamming Distance: Counting Point Mutations
onouyek
0
470
Creating the Fibonacci Sequence: Writing, Testing, and Benchmarking Algorithms
onouyek
1
500
Transcribing DNA into mRNA: Mutating Strings, Reading and Writing Files
onouyek
0
550
DNA methylation analysis using bisulfite sequencing data
onouyek
0
910
Operations on Genomic Intervals and Genome Arithmetic
onouyek
0
370
Exploratory Data Analysis with Unsupervised Machine Learning
onouyek
0
320
Other Decks in Programming
See All in Programming
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
180
JJUG CCC 2026 Spring: JSpecify で実現する Kotlin フレンドリーな Java API 設計
ternbusty
1
170
ふつうのFeature Flag実践入門
irof
7
4k
TSKaigi Night Talks 2026_TypeScriptでサプライチェーンの整合性を型に閉じ込める
geekplus_tech
0
350
肥大化するレガシーコードに立ち向かうためのインターフェース分離と依存の逆転 / JJUG CCC 2026 Spring
hirokunimaeta
0
560
Make SRE Operations Easier with Azure SRE Agent
kkamegawa
0
6.2k
代数的データ型って何が嬉しいの? #frontend_phpcon_do
kajitack
8
3.7k
「AIで開発し、AIを届ける」をEvalでつなぐ 〜AIネイティブに始めるプロダクト開発の実践〜 / Connecting "Develop with AI, deliver AI" with Eval
rkaga
4
5.1k
気づいたらRubyで100作品 ー クリエイティブコーディングが生活の一部になるまで / 100 Ruby Sketches Later: How Creative Coding Became Part of My Life
chobishiba
3
580
Spring Security 実践 ─ GraphQL APIで実務に役立つ 認証・認可 を学ぶ
wagyu
0
230
Oxlintのカスタムルールの現況
syumai
6
1.1k
Dataformのリポジトリを立ち上げるときにまずやること / dataform-day0-2026
snhryt
0
160
Featured
See All Featured
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Abbi's Birthday
coloredviolet
2
8.1k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
420
エンジニアに許された特別な時間の終わり
watany
107
250k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
590
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
230
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Rails Girls Zürich Keynote
gr2m
96
14k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
190
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Transcript
【第10回】ゼロから始めるゲノム解析 (Python編) Finding the Longest Shared Subsequence: Finding K-mers, Writing
Functions, and Using Binary Search @onouyek
本勉強会の概要・目的 書籍名 対象者/目的 Mastering Python for Bioinformatics Python・バイオインフォマティクス知識ほぼ ゼロの人を対象に、正しい Pythonのコー
ディング手法について学ぶ 頻度 毎週〜隔週開催予定 登壇者 募集中!
Rosalindとは • 問題解決を通じてバイオインフォマティク ス、プログラミング、およびアルゴリズムを 学習するためのプラットフォーム • 大学やハッカソン、就職の面接にも 600回 以上の採用実績あり 参考:https://qiita.com/_kimoton/items/d534d0fa9b83dd7dc412
概要
環境構築 - 必要パッケージ群のインストール # 公開されているレポジトリからファイル群を取得 $ git clone https://github.com/kyclark/biofx_python $
cd biofx_python # requirements.txtに記載のパッケージをインストール $ pip3 install -r requirements.txt # pylintの設定ファイルをホームディレクトリに移動 $ cp pylintrc ~/.pylintrc # mypyの設定ファイルをホームディレクトリに移動 $ cp mypy.ini ~/.mypy.ini
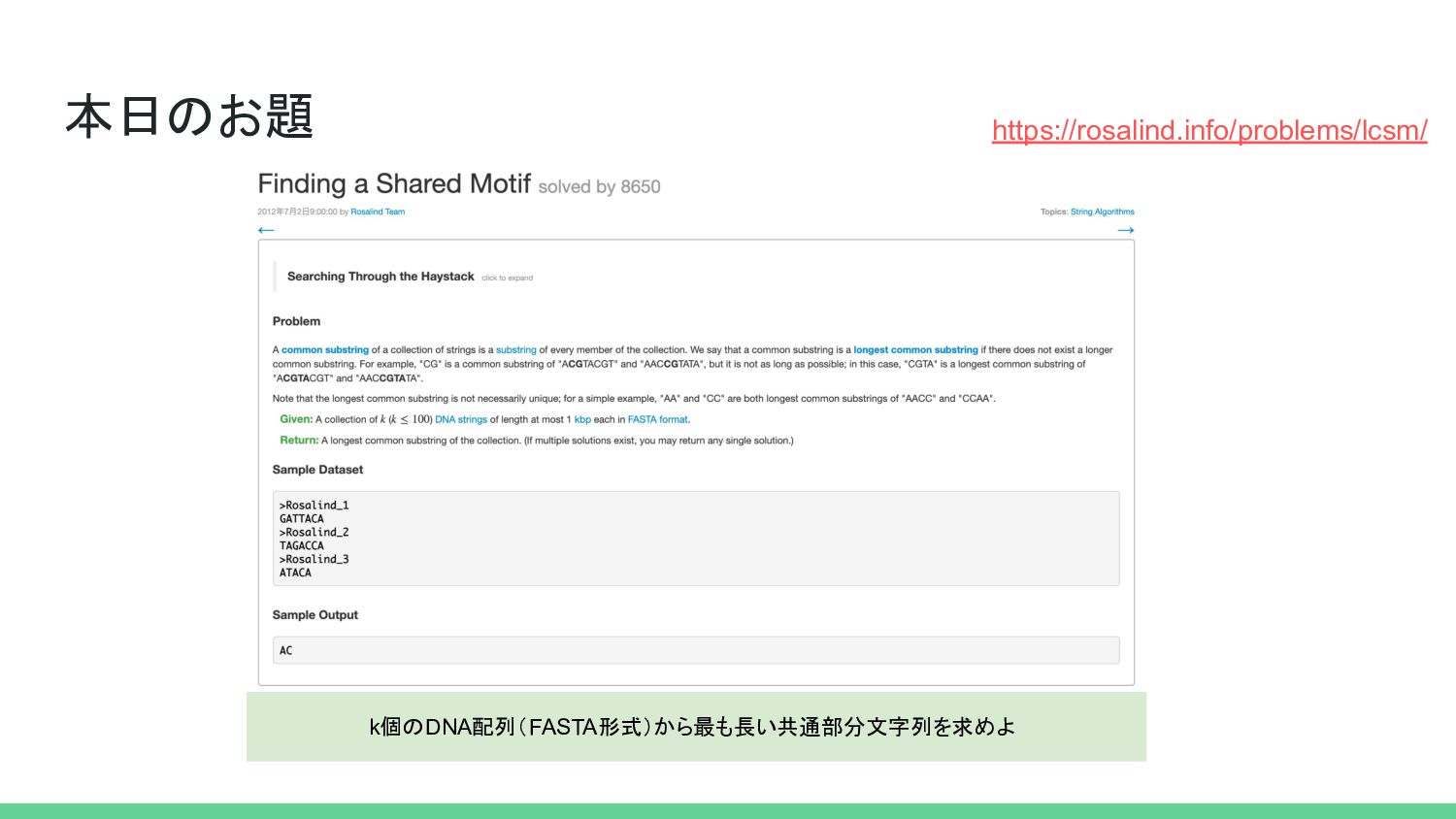
本日のお題 https://rosalind.info/problems/lcsm/ k個のDNA配列(FASTA形式)から最も長い共通部分文字列を求めよ
前提知識編
最長共通部分文字列 $ cat tests/inputs/1.fa >Rosalind_1 GATTACA >Rosalind_2 TAGACCA >Rosalind_3 ATACA
以下の例ではCA、TA、ACが最長共通部分文字列 >Rosalind_1 GATTACA >Rosalind_2 TAGACCA >Rosalind_3 ATACA >Rosalind_1 GATTACA >Rosalind_2 TAGACCA >Rosalind_3 ATACA >Rosalind_1 GATTACA >Rosalind_2 TAGACCA >Rosalind_3 ATACA
FASTAファイルの読み込み >>> from Bio import SeqIO >>> fh = open('./tests/inputs/1.fa')
>>> recs = SeqIO.parse(fh, 'fasta') >>> type(recs) <class 'Bio.SeqIO.FastaIO.FastaIterator'> Bio.SeqIO.parse()でイテレータを作る >>> fh = open('./tests/inputs/1.fa') >>> seqs = [str(rec.seq) for rec in SeqIO.parse(fh, 'fasta')] >>> seqs ['GATTACA', 'TAGACCA', 'ATACA'] リスト内包表記で配列を取り出す >>> seqs = list(map(lambda rec: str(rec.seq), SeqIO.parse(fh, 'fasta'))) map()を使って取り出す
K-mersの取得 第9回で作ったfind_kmers() def find_kmers(seq: str, k: int) -> List[str]: """
Find k-mers in string """ n = len(seq) - k + 1 return [] if n < 1 else [seq[i:i + k] for i in range(n)] def test_find_kmers() -> None: """ Test find_kmers """ assert find_kmers('', 1) == [] assert find_kmers('ACTG', 1) == ['A', 'C', 'T', 'G'] assert find_kmers('ACTG', 2) == ['AC', 'CT', 'TG'] assert find_kmers('ACTG', 3) == ['ACT', 'CTG'] assert find_kmers('ACTG', 4) == ['ACTG'] assert find_kmers('ACTG', 5) == []
range()によるカウントダウン range()の第3引数でstepを-1にすればカウントダウンできる >>> shortest = min(map(len, seqs)) >>> shortest 5
最短の配列の長さを求める >>> list(range(shortest, 0, -1)) [5, 4, 3, 2, 1] カウントアップしてからreversed()しても同じ結果は得られる >>> list(reversed(range(1, shortest + 1))) [5, 4, 3, 2, 1]
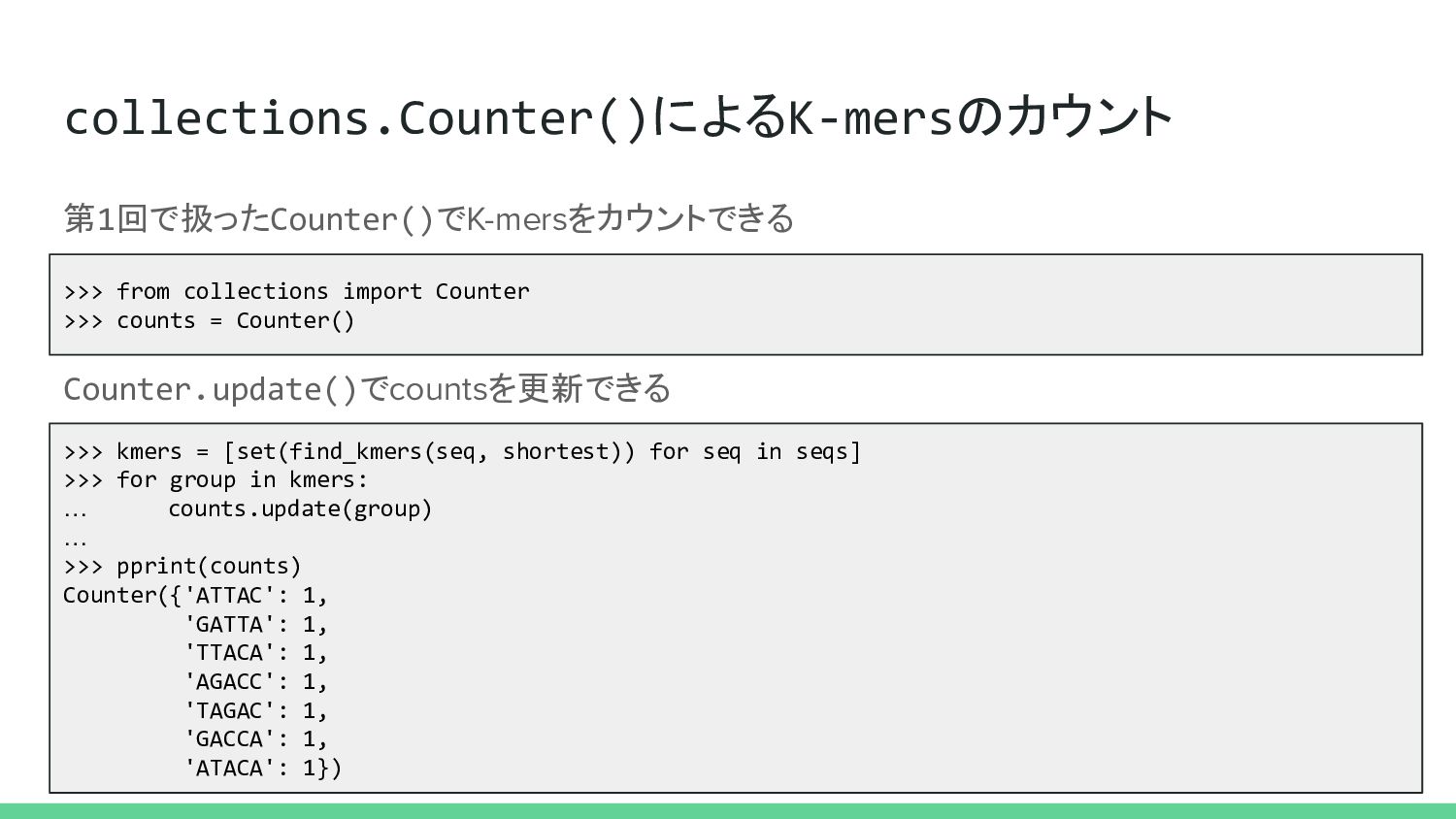
collections.Counter()によるK-mersのカウント >>> from collections import Counter >>> counts = Counter()
第1回で扱ったCounter()でK-mersをカウントできる >>> kmers = [set(find_kmers(seq, shortest)) for seq in seqs] >>> for group in kmers: … counts.update(group) … >>> pprint(counts) Counter({'ATTAC': 1, 'GATTA': 1, 'TTACA': 1, 'AGACC': 1, 'TAGAC': 1, 'GACCA': 1, 'ATACA': 1}) Counter.update()でcountsを更新できる
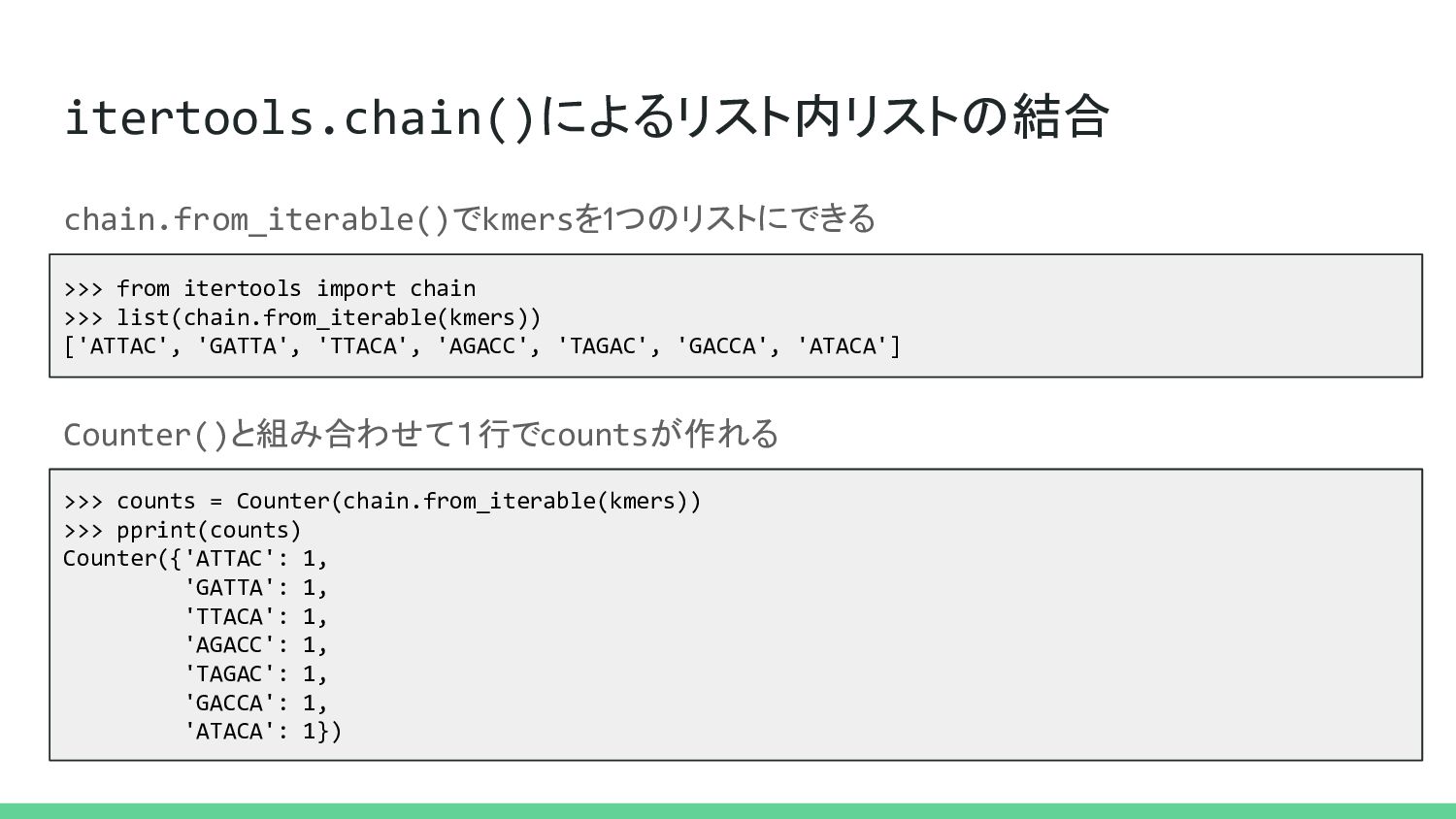
itertools.chain()によるリスト内リストの結合 >>> from itertools import chain >>> list(chain.from_iterable(kmers)) ['ATTAC', 'GATTA',
'TTACA', 'AGACC', 'TAGAC', 'GACCA', 'ATACA'] chain.from_iterable()でkmersを1つのリストにできる >>> counts = Counter(chain.from_iterable(kmers)) >>> pprint(counts) Counter({'ATTAC': 1, 'GATTA': 1, 'TTACA': 1, 'AGACC': 1, 'TAGAC': 1, 'GACCA': 1, 'ATACA': 1}) Counter()と組み合わせて1行でcountsが作れる
解法編
Solution 1: 線形探索 ①入力配列の中で最も短い配列の長さを求める ②最短の配列長からkをカウントダウンしていく ③common_kmers()で共通配列があったら終了する ① ② ③
(参考)二分探索 第4回で扱った再帰を使った方法 ①highがlowより小さくなったときを終了条件にする ②中間地点の値と探している値が同じ時にmidを返す ③中間地点の値が探している値より大きければhighをmid-1 にしてbinary_search()する ④中間地点の値が探している値より小さければlowをmid+1に してbinary_search()する ① ②
③ ④
Solution 2: 二分探索 今回の問題用に修正した二分探索 ①引数で受け取ったf()とlowとhighから共通k-mersのリスト hiとloを作る ②hiとloがどちらも共通k-mersが存在したらhighの位置を 返す ③共通k-mersがloにあってhiになければhighをmidにして binary_search()する
④hiもloも空の場合は-1を返す ① ② ③ ④ ④
Solution 2: 二分探索 ①lowを1にhighを最短の配列長で二分探索して開始位置を決 める ②開始位置から共通k-mersが見つからなくなるまでカウントアッ プして候補k-mersをcandidatesに追加していく ③max()のkeyオプションで最大長のk-merを出力する ① ②
③
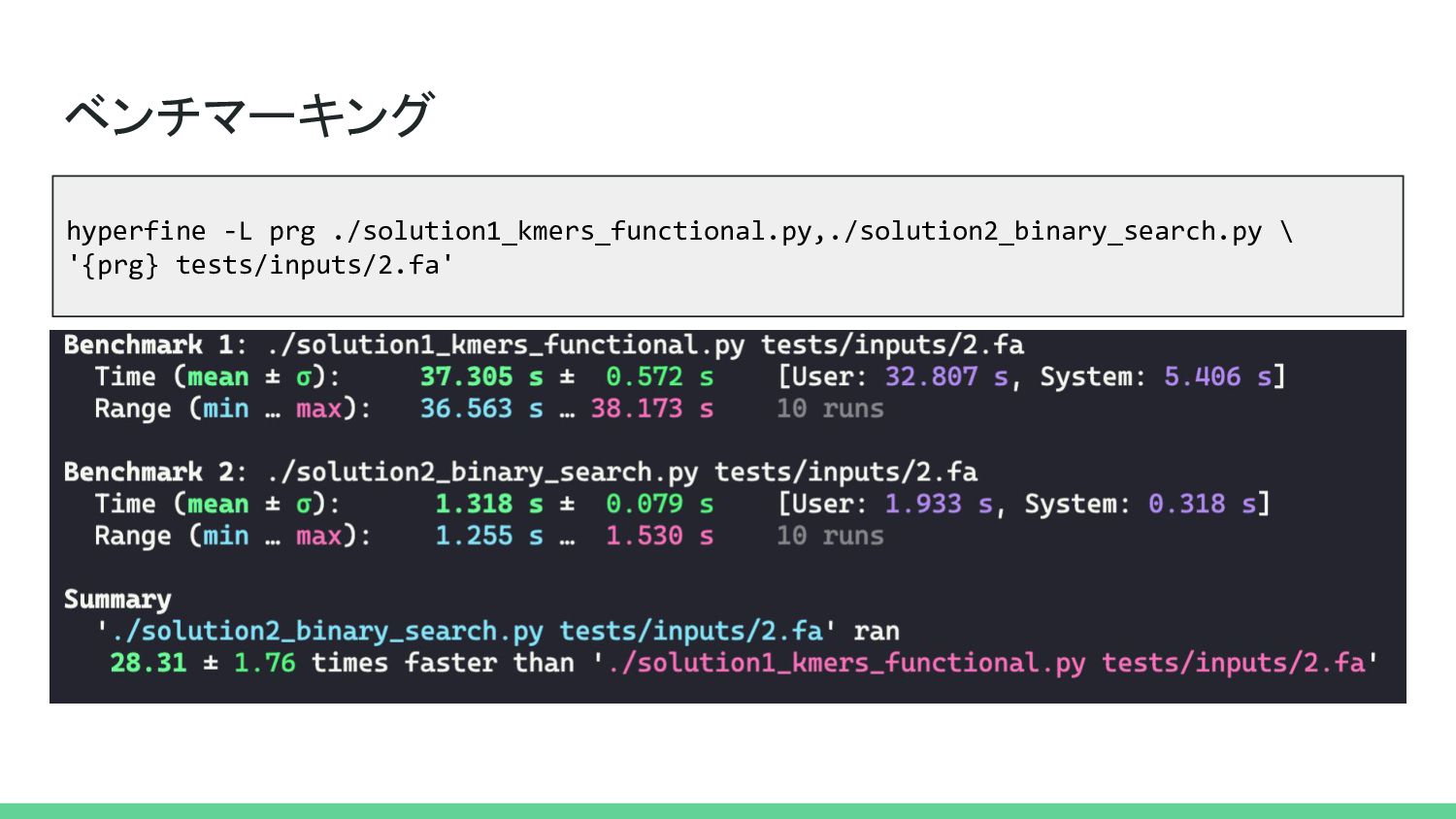
ベンチマーキング hyperfine -L prg ./solution1_kmers_functional.py,./solution2_binary_search.py \ '{prg} tests/inputs/2.fa'
本日学んだこと • K-mersによる共通配列の検索 • itertools.chain()によるリスト内リストの結合 • 二分探索による検索の効率化 • min()、max()のkeyオプション
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![K-mersの取得 第9回で作ったfind_kmers() def find_kmers(seq: str, k: int) -> List[str]: """](https://files.speakerdeck.com/presentations/8829fa02a57b4c3a8bec87d379315a5c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}