Chongqing, China 8D Magic City, Hot Pot 👨🎓 香 港中 文 大 学 / The Chinese University of Hong Kong Math, Information Engineering 👨💻 Software Engineer @ LY Corporation Streaming Data Pipeline, Spark, Iceberg ✨ Improving big data systems with Rust Hadoop Client, Hive Client, SASL / Kerberos, InnoFile, InnoTable
schema • Schema evolution is not well de f ined • Full data scanning is needed when • reading records with particular f ilters • deleting or updating certain records • Missing advanced features like ACID, Time Travel, etc.
schema explicitly • Support schema evolution • Accelerate querying by skipping unnecessary data f iles • Support other advanced features like ACID, Time Travel, etc.
Hive Metastore to support huge amount of partitions • Query optimization is limited to partition and bucket level • Missing advanced features like ACID, full schema evolution, etc.
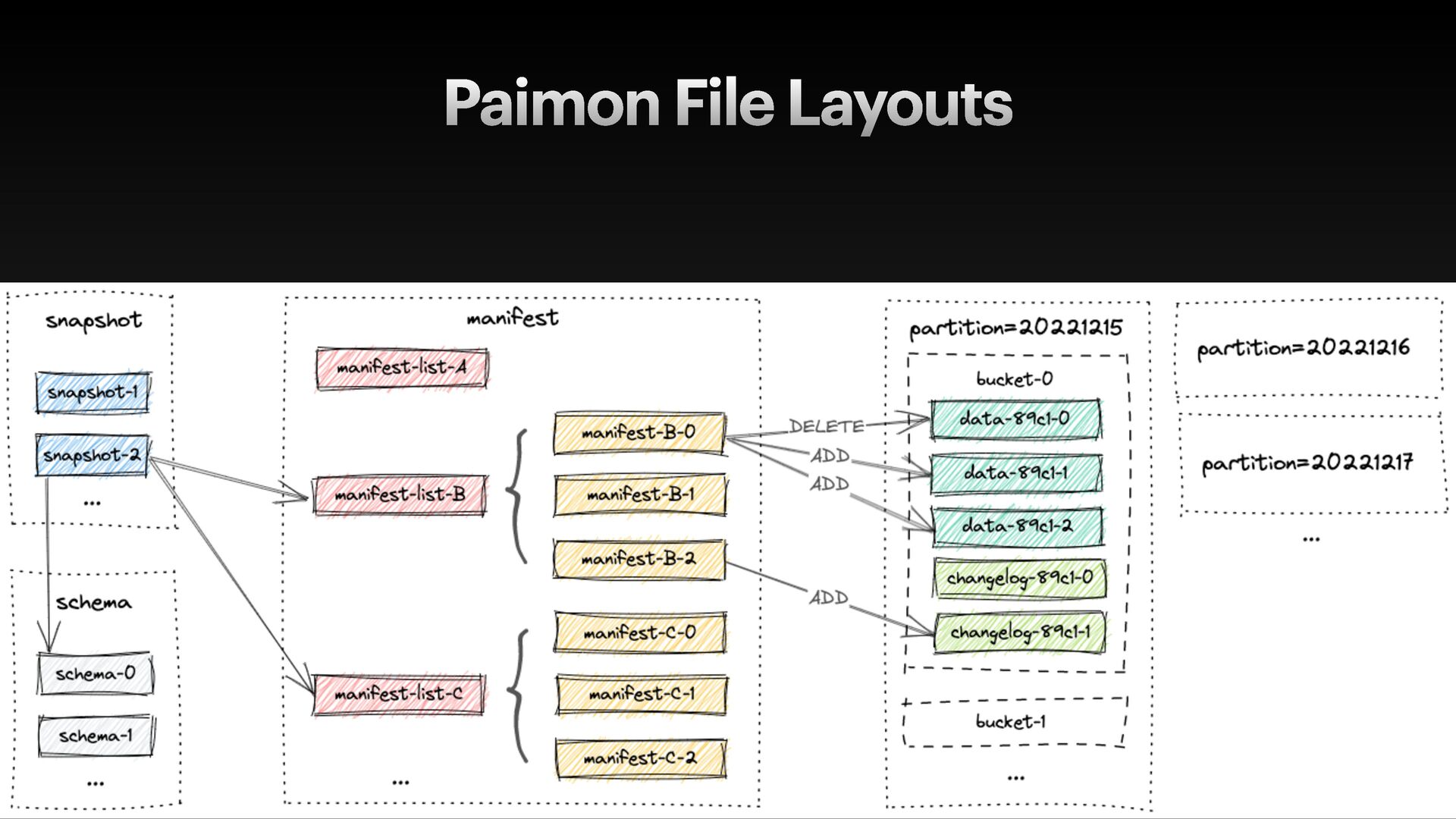
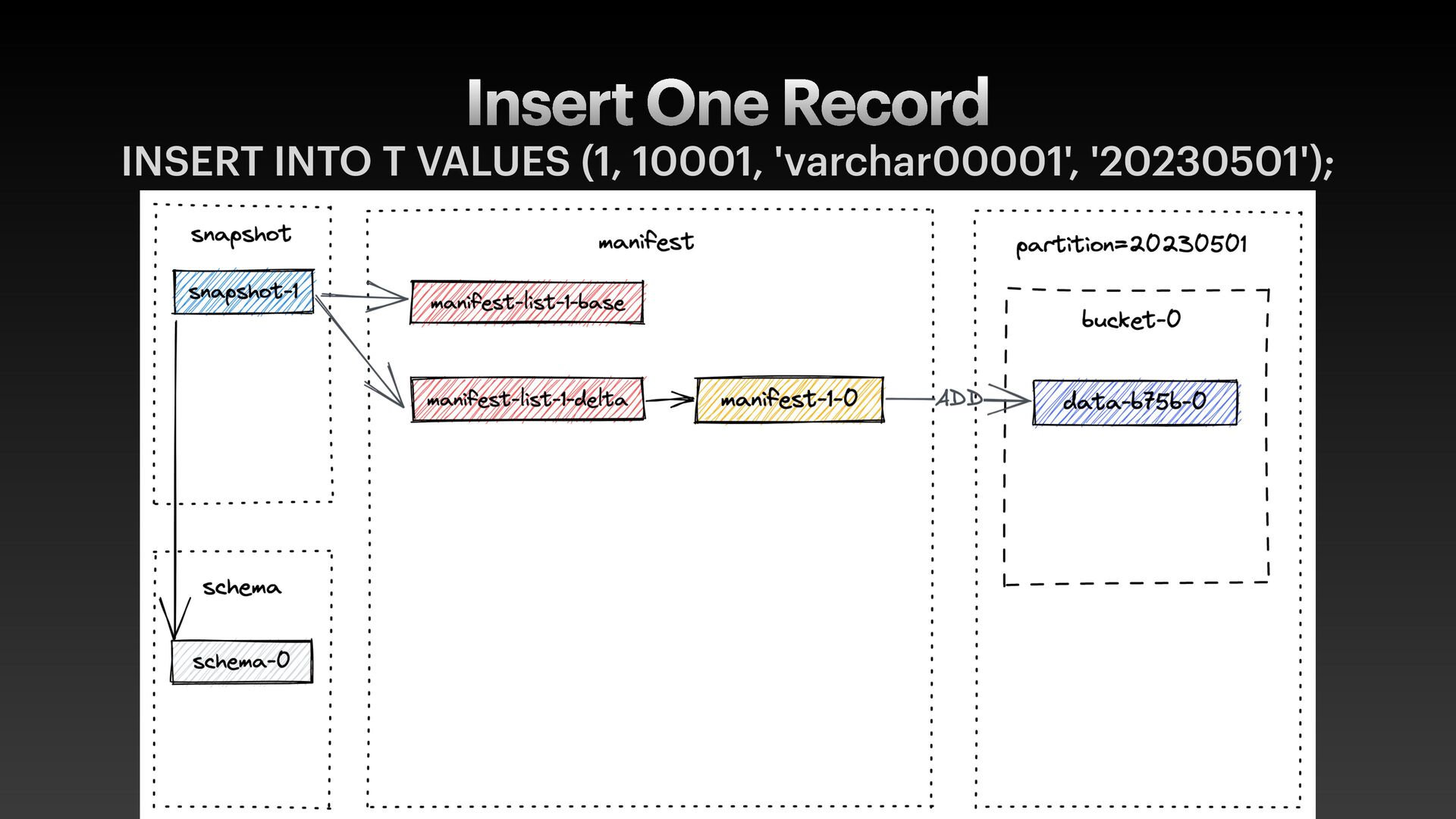
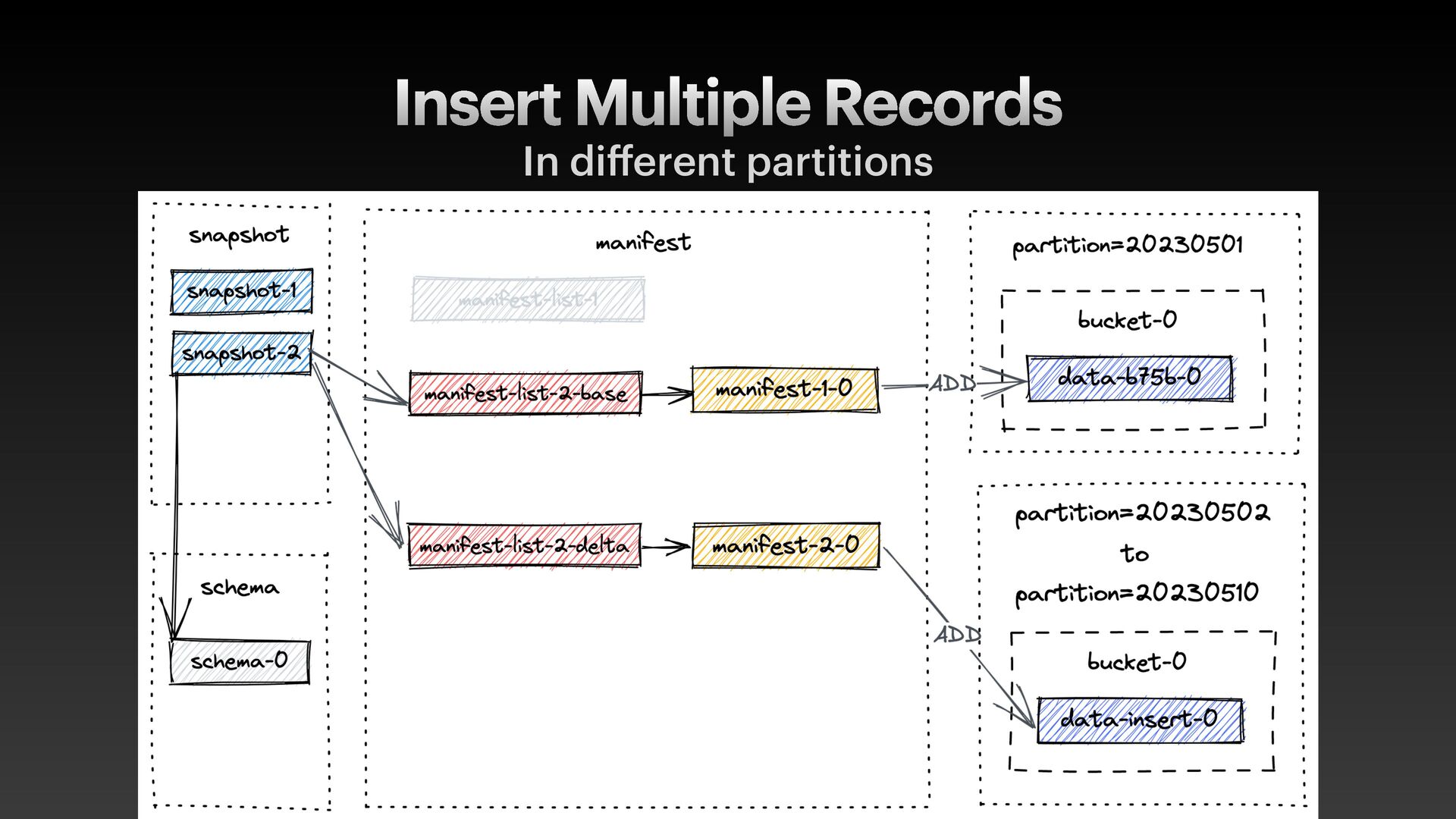
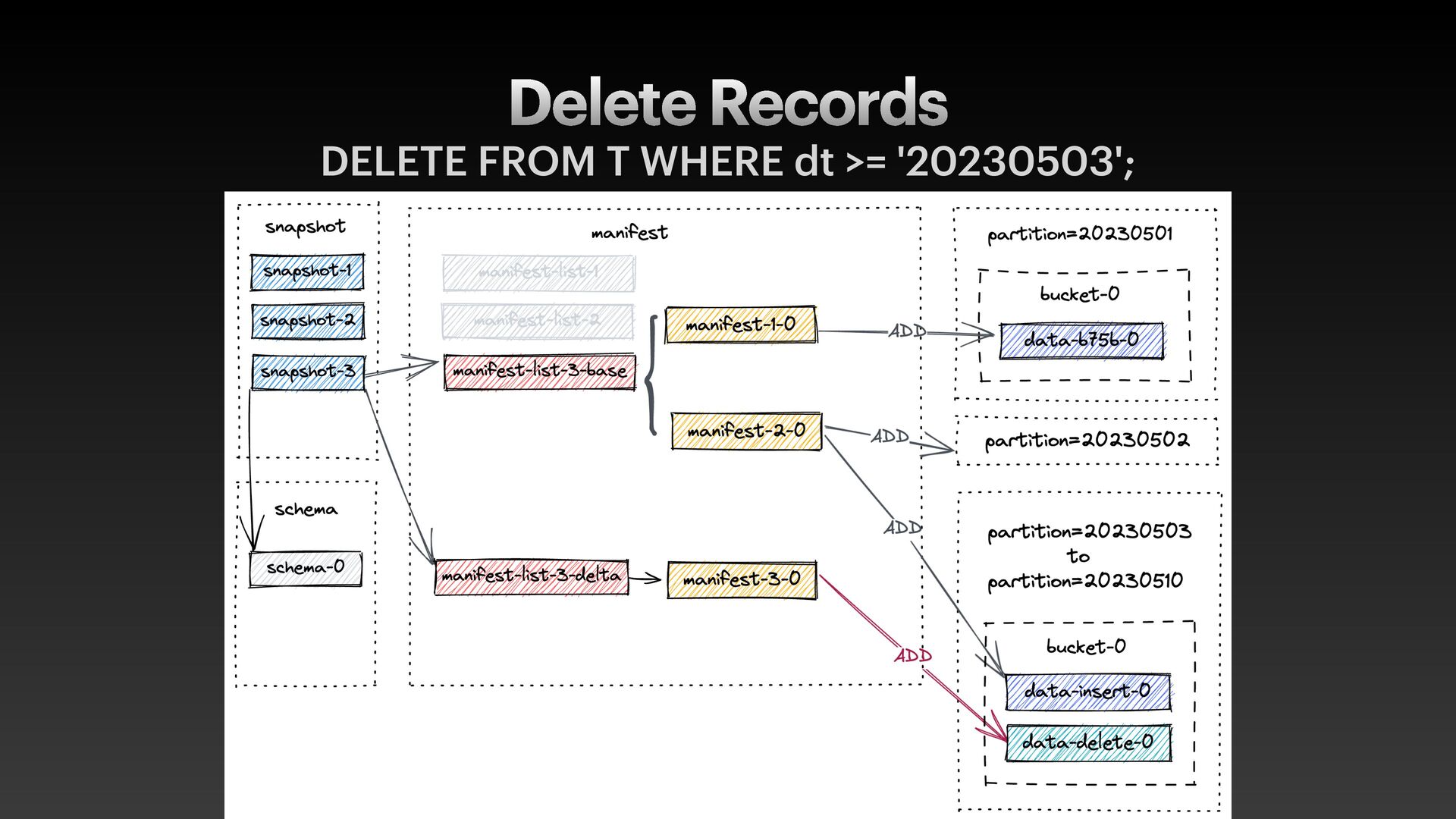
data f iles with metadata • metadata.json • manifest-list.avro (contains stats to skip manifest f iles) • manifest.avro (contains stats to skip data f iles) • data- f iles.parquet • Support advanced features like ACID, full schema evolution, etc.
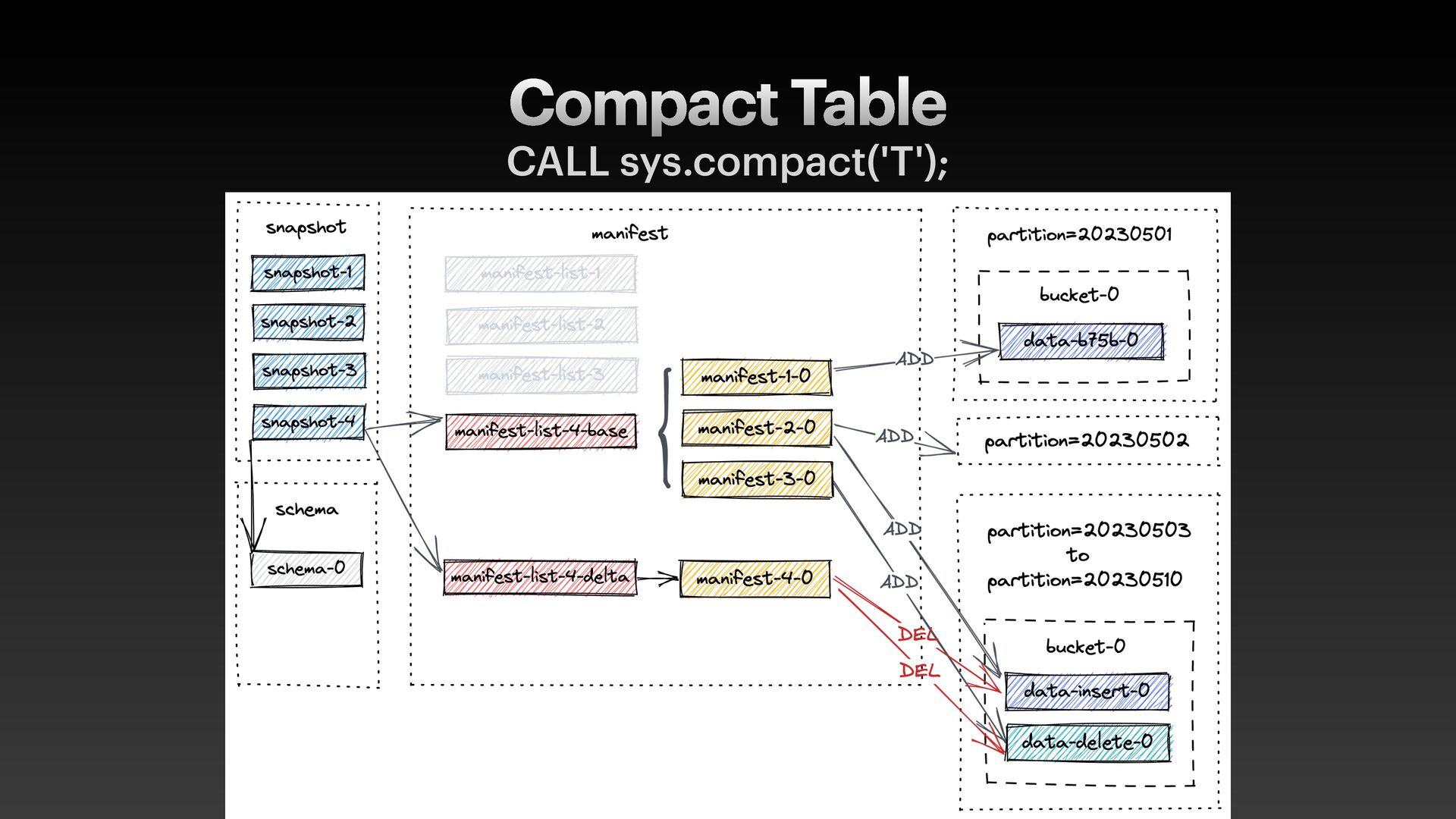
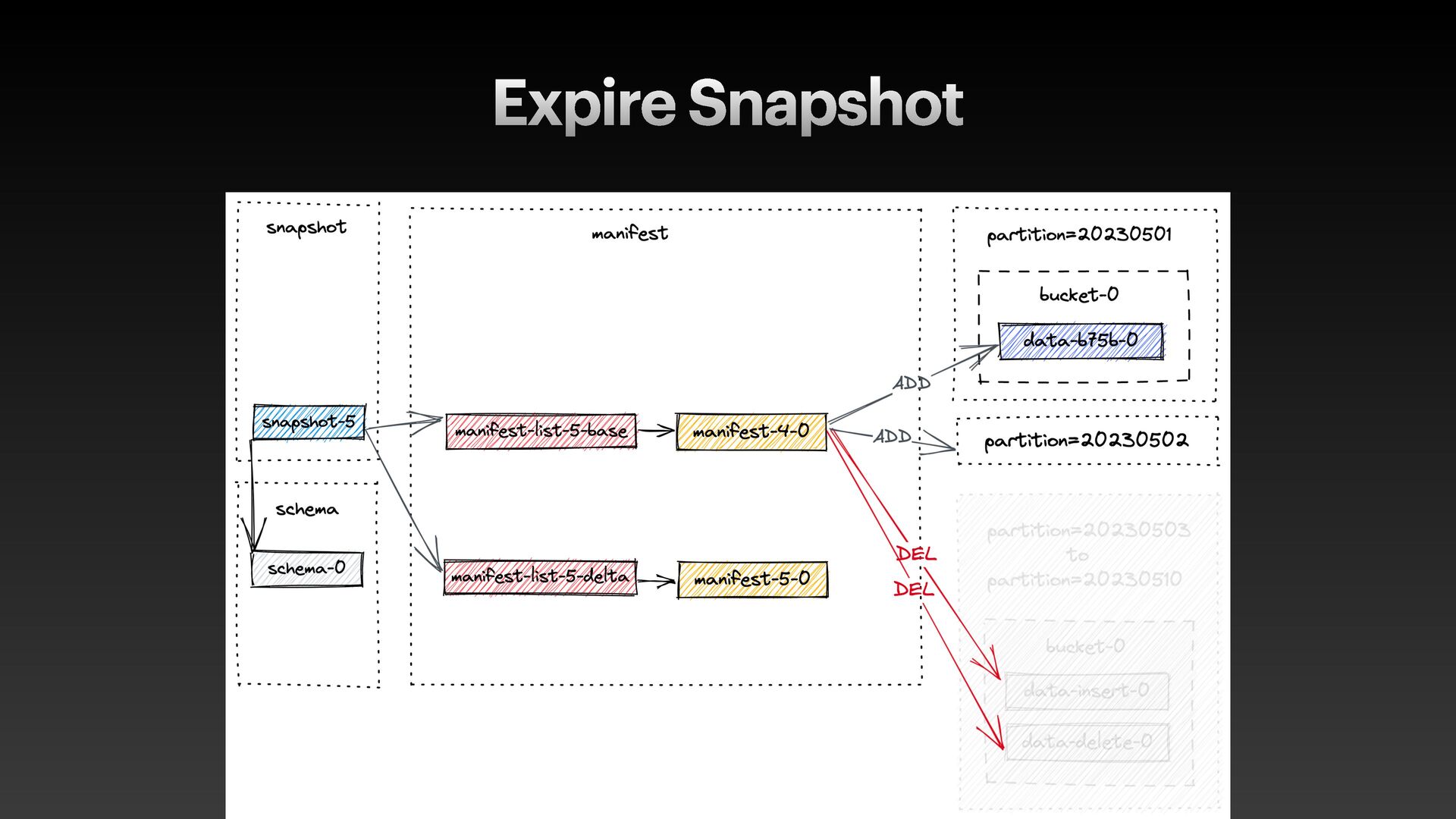
Iceberg • Commits are atomic and inef f icient for frequent writes • Delta Lake, Hudi • Update/delete relies on Merge-on-Read with expensive compaction
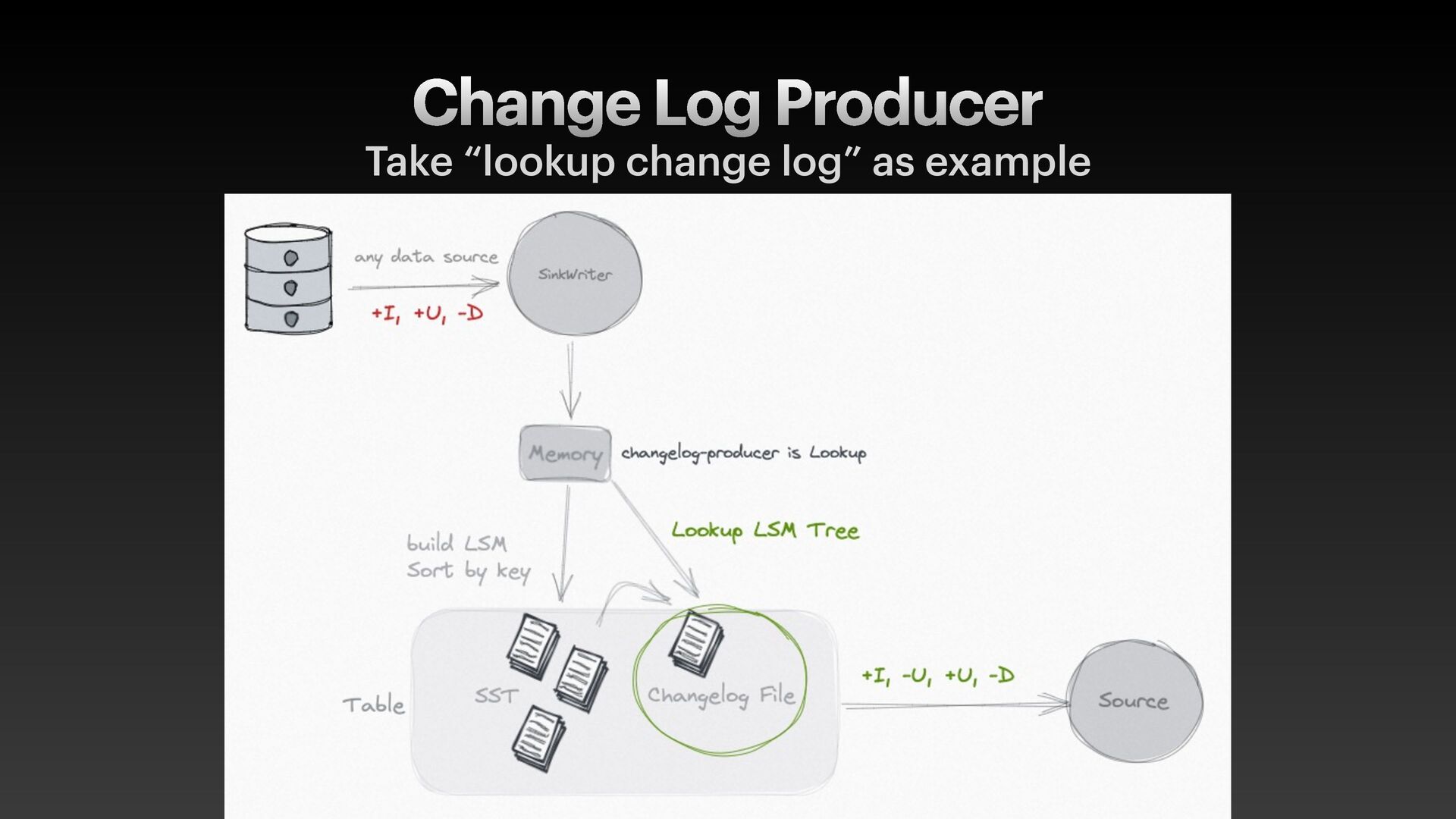
metadata (manifest, index f ile) • Support high-throughput streaming write and low latency read • with LSM Tree (log-structured merge-tree) storage model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}