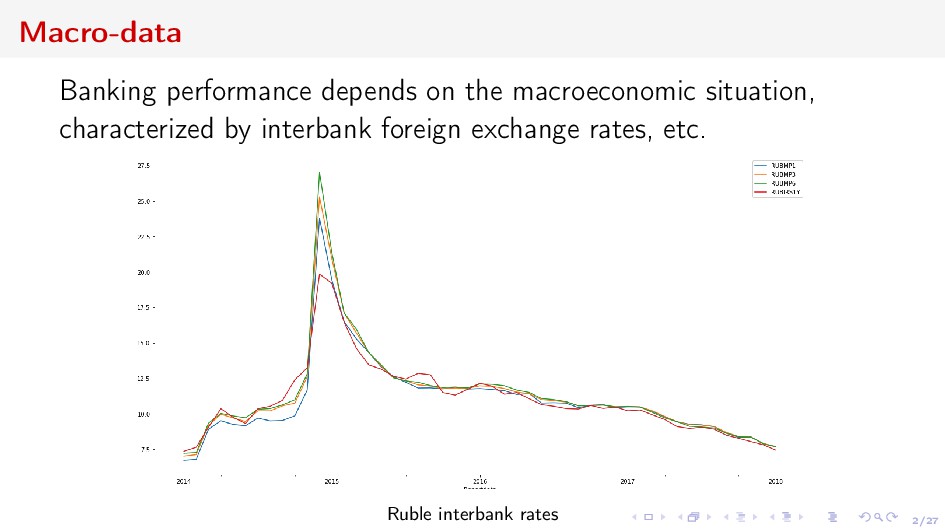
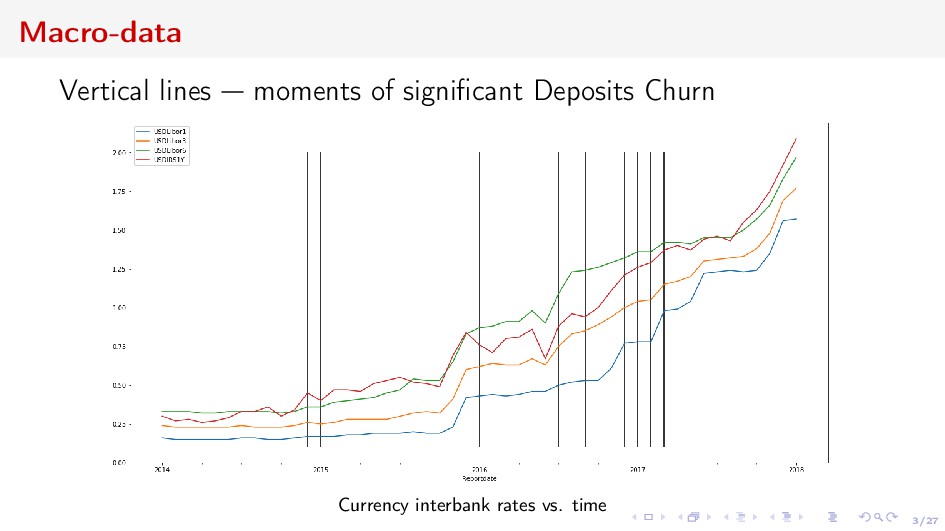
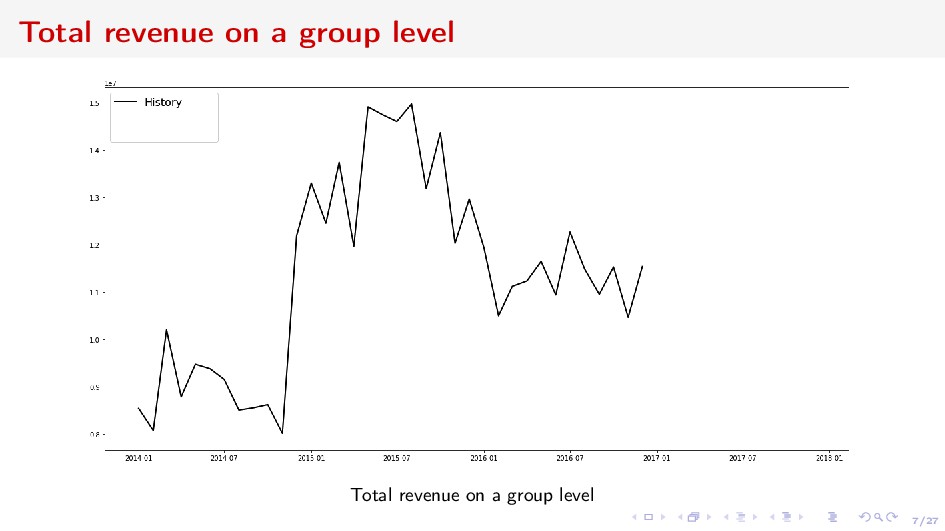
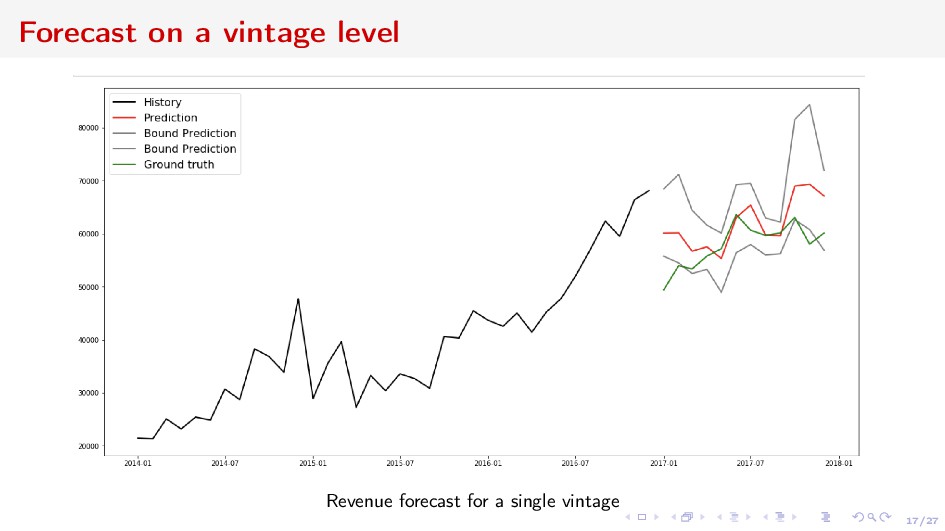
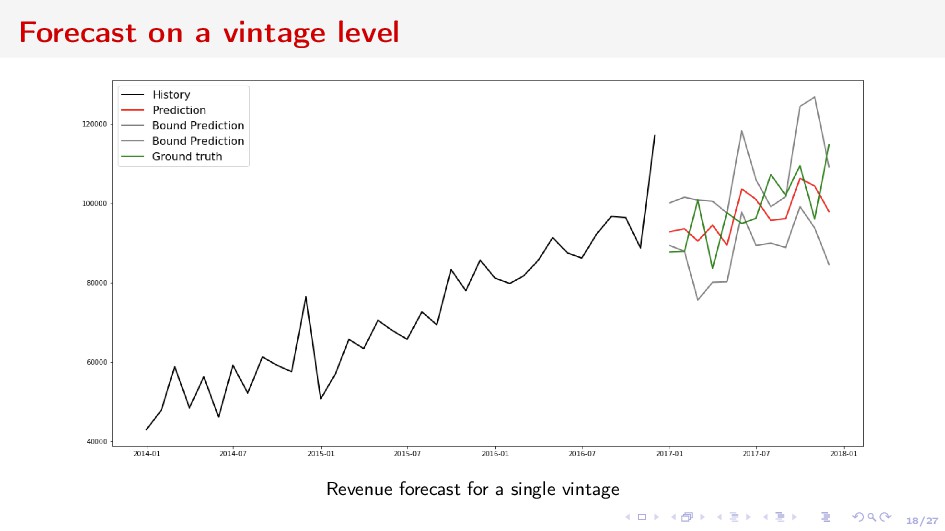
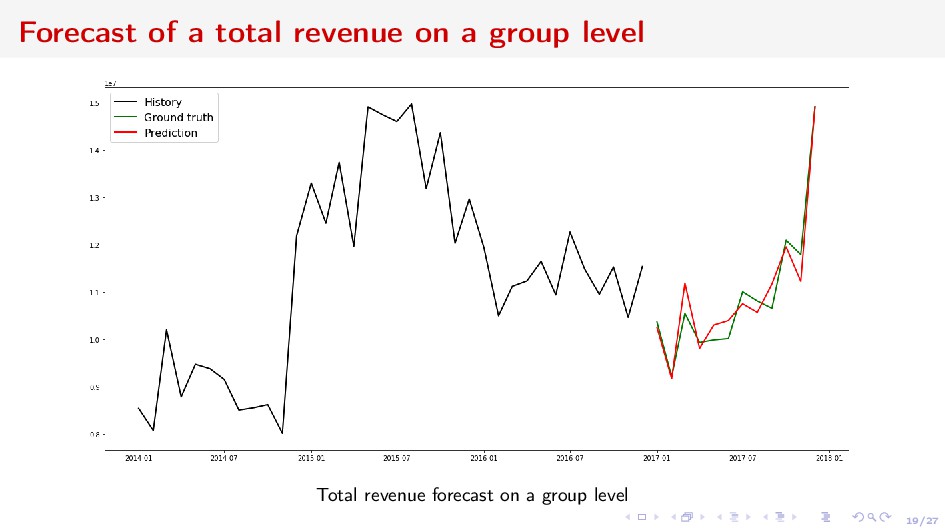
adequacy and liquidity risks ⇒ long-term forecasting Deposits Churn Net Revenue from Acquiring Vintage economic units grouped by some categorical characteristics and united by time interval Forecast the value of the vintage, or the sum w.r.t. some vintages
xt ∈ Rnx (nx > 7000 vintages) Time series are dependent due to territorial proximity and/or similar businesses Idea Time-series close in a latent space should have similar predictions The prediction model must be different for distant latent points Dynamics in latent space
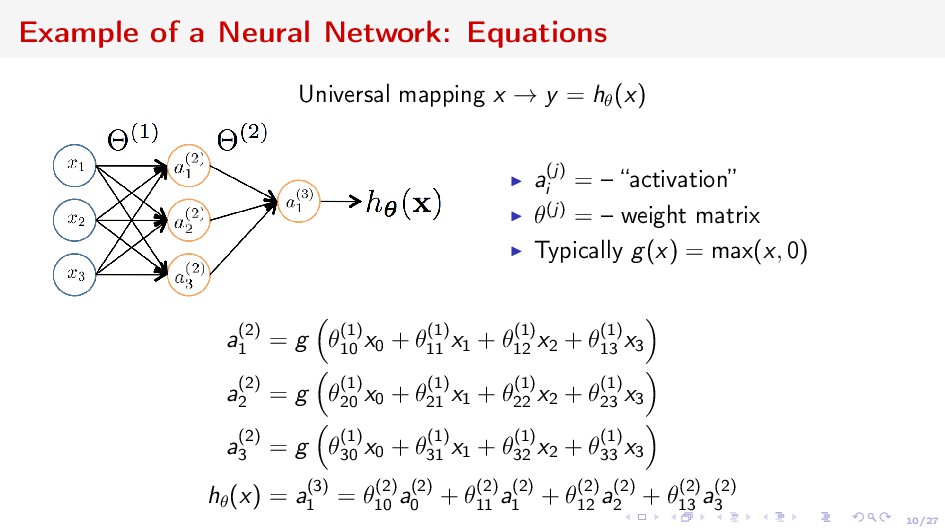
ut , xt+1 }T t=1 : xt ∈ Rnx , nx 1 time-series at moment t (revenue values in a vintage) ut control at time t (macro-data) Assumptions: Dynamics of xt is complex We can find a representation zt ∈ Rnz , nz nx , such that zt+1 = A(zt )zt + B(zt )ut + o(zt ) xt = f (zt ) ⇒ Neural network generalization of Kalman filter
Macroeconomic data) Autoencoding: xt is accurately recovered from zt Predicting latent trajectory: zt+1 is accurately predicted by zt Predicting next state: xt+1 is accurately predicted by zt Regularizer similar to L2 : KL(qφ (zt )|N(0, I))
of vintages Vintage j deposits with the same charac-s (vintage code): Date of opening of a Deposit Deposit currency, term of Deposit Segment of a deposit, sales channel, volume, type of a deposit Has a deposit been prolonged? Forecast monthly change in a volume of a vintage (churn rate) EARt j = V t j − V t−1 j V t−1 j ∈ [−1; 0] In total 103932 vintages, and we have only 48 time points
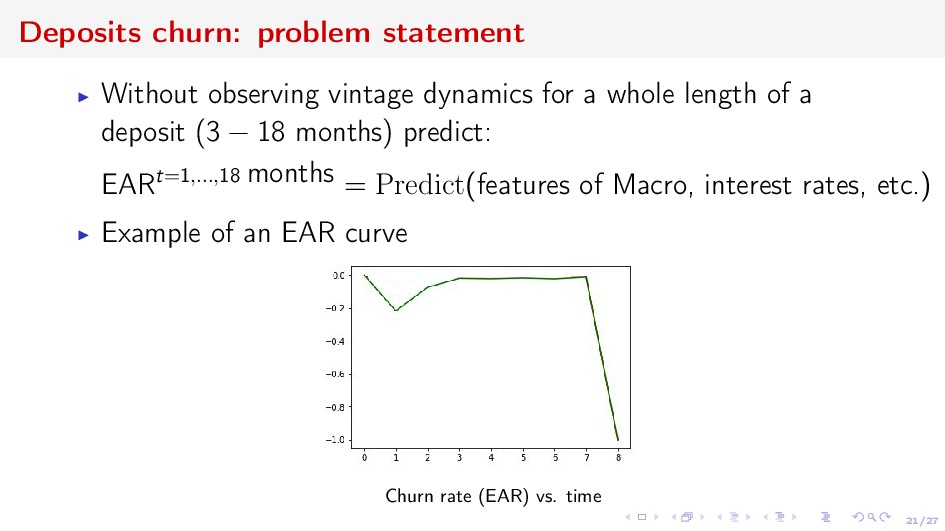
a whole length of a deposit (3 − 18 months) predict: EARt=1,...,18 months = Predict(features of Macro, interest rates, etc.) Example of an EAR curve Churn rate (EAR) vs. time
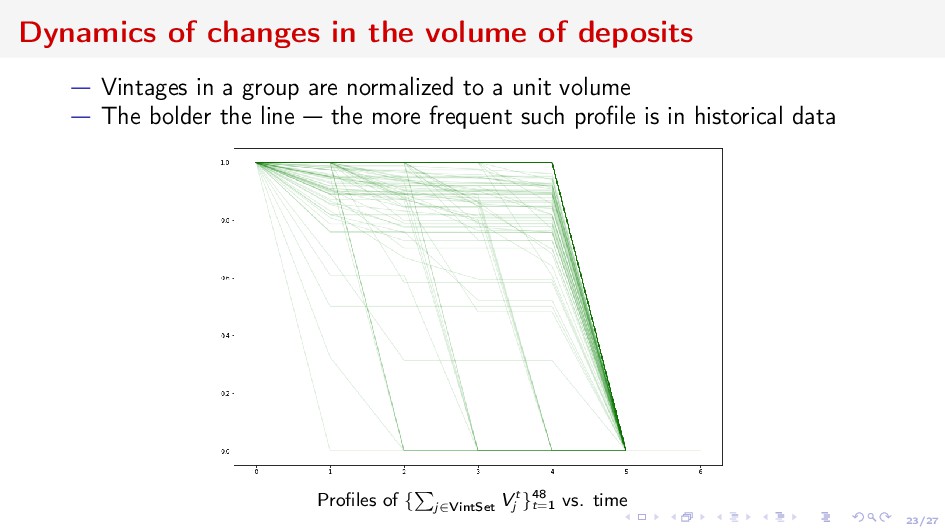
in a group are normalized to a unit volume The bolder the line the more frequent such profile is in historical data Profiles of { j∈VintSet V t j }48 t=1 vs. time
z )) Features X features from macro-data ’RUBMP1’, ’USDLibor1’, ... (log-returns, variances, etc.) features from interest rates Dependencies between EARt(X) for every t and X cov(EARt=i(X), EARt=r (X )) = (WW T)ir ⊗ k(X, X ) where k(X, X ) = exp(− X − X 2/σ2) RBF-kernel
K(z, z )) Given a sample D = {EARt=1,...,48(Xl ), l = 1, . . . , N} we optimize GP-based likelihood to estimate W and σ Prediction is given by Law(EARt=1,...,48(X)|D) = N(µ(X), σ2(X)) with explicitly given µ(X) and σ2(X)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}