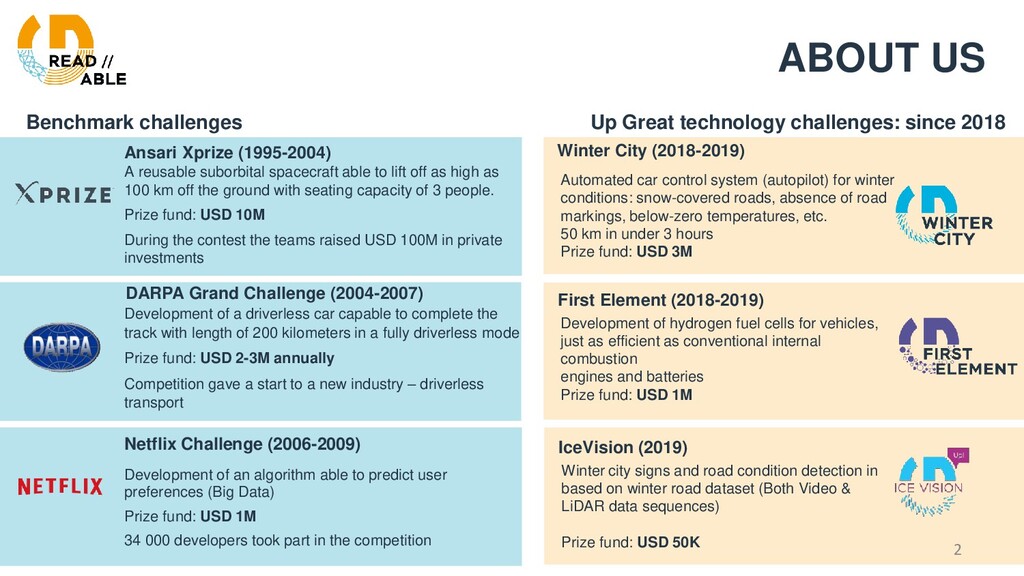
Ansari Xprize (1995-2004) A reusable suborbital spacecraft able to lift off as high as 100 km off the ground with seating capacity of 3 people. Prize fund: USD 10M During the contest the teams raised USD 100M in private investments Netflix Challenge (2006-2009) Development of an algorithm able to predict user preferences (Big Data) Prize fund: USD 1M 34 000 developers took part in the competition Automated car control system (autopilot) for winter conditions: snow-covered roads, absence of road markings, below-zero temperatures, etc. 50 km in under 3 hours Prize fund: USD 3M Winter City (2018-2019) DARPA Grand Challenge (2004-2007) Development of a driverless car capable to complete the track with length of 200 kilometers in a fully driverless mode Prize fund: USD 2-3M annually Competition gave a start to a new industry – driverless transport Development of hydrogen fuel cells for vehicles, just as efficient as conventional internal combustion engines and batteries Prize fund: USD 1M First Element (2018-2019) Winter city signs and road condition detection in based on winter road dataset (Both Video & LiDAR data sequences) Prize fund: USD 50K IceVision (2019) 2
annotation semantic mistakes in natural language on par with the control group human. Text type Text size Filetypes Time limit for AI Time limit for reference human Annotations Provided datasets Mistake categories Essays and papers of highschool and college students on any curriculum topic in literature, history and social studies <12 000 symbols .txt files with wiki-style markup 1 minute per essay 10 minutes per essay (estimated, depends on size and topic) Mistakes are classified by type and annotated accordingly • Thousands of high-quality essays verified by organizers • Tens of thousands of unsupervised quality essays - Logic - Facts - Irrelevant content - Bad structure, inappropriate comparisons and metaphors
unreleased marked essays • Week long trial • No time limits • All teams with at least one valid mistake pass • Automated results Stage 2. Main trial • Hundreds to thousands unreleased, unmarked essays • Short trial: 1 essay at a time, 1 minute to upload marked essay Stage 2.1. Evaluation • After the main trial essays are checked for mistakes by teachers • 2 types of markups: a) control. 1 teacher, 10 min/file b) perfect. 3 teachers, no time limit • 3 weeks long Stage 3. Results • Automated comparison of AI vs perfect markup • Automated comparison of control group markup vs perfect markup • Top 10 teams are audited • If a team excels the control group markup – the prize is awarded
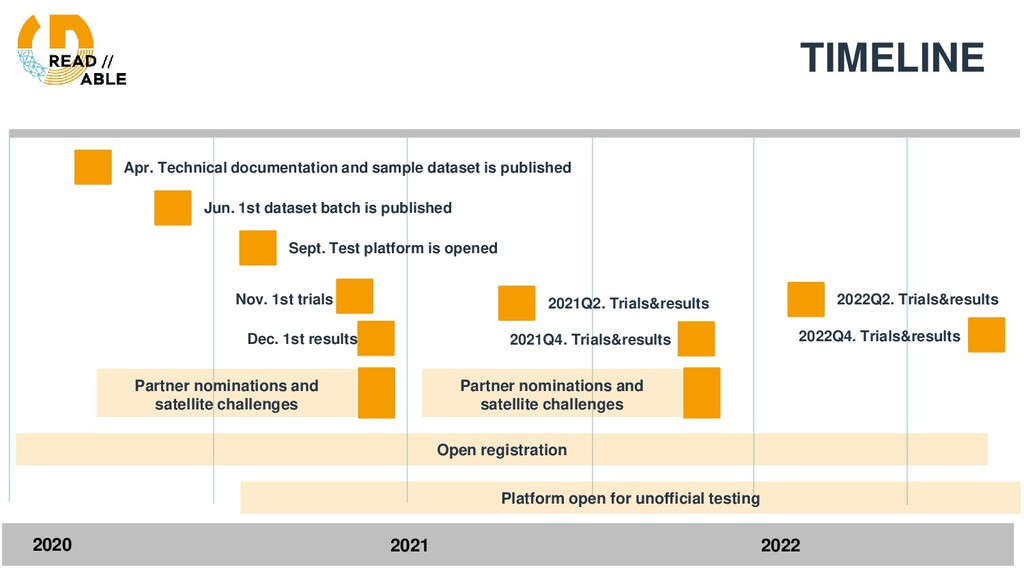
and sample dataset is published Jun. 1st dataset batch is published Sept. Test platform is opened Nov. 1st trials Dec. 1st results 2021Q2. Trials&results 2021Q4. Trials&results 2022Q2. Trials&results 2022Q4. Trials&results Partner nominations and satellite challenges Partner nominations and satellite challenges Platform open for unofficial testing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}