a Web Developer for 13 years > Now in the process of building a business based on crawling / web data > @chrolear on 🐦 | 📖 otsch.codes | @[email protected] 🐘 @crwlrsoft @chrolear | @[email protected]
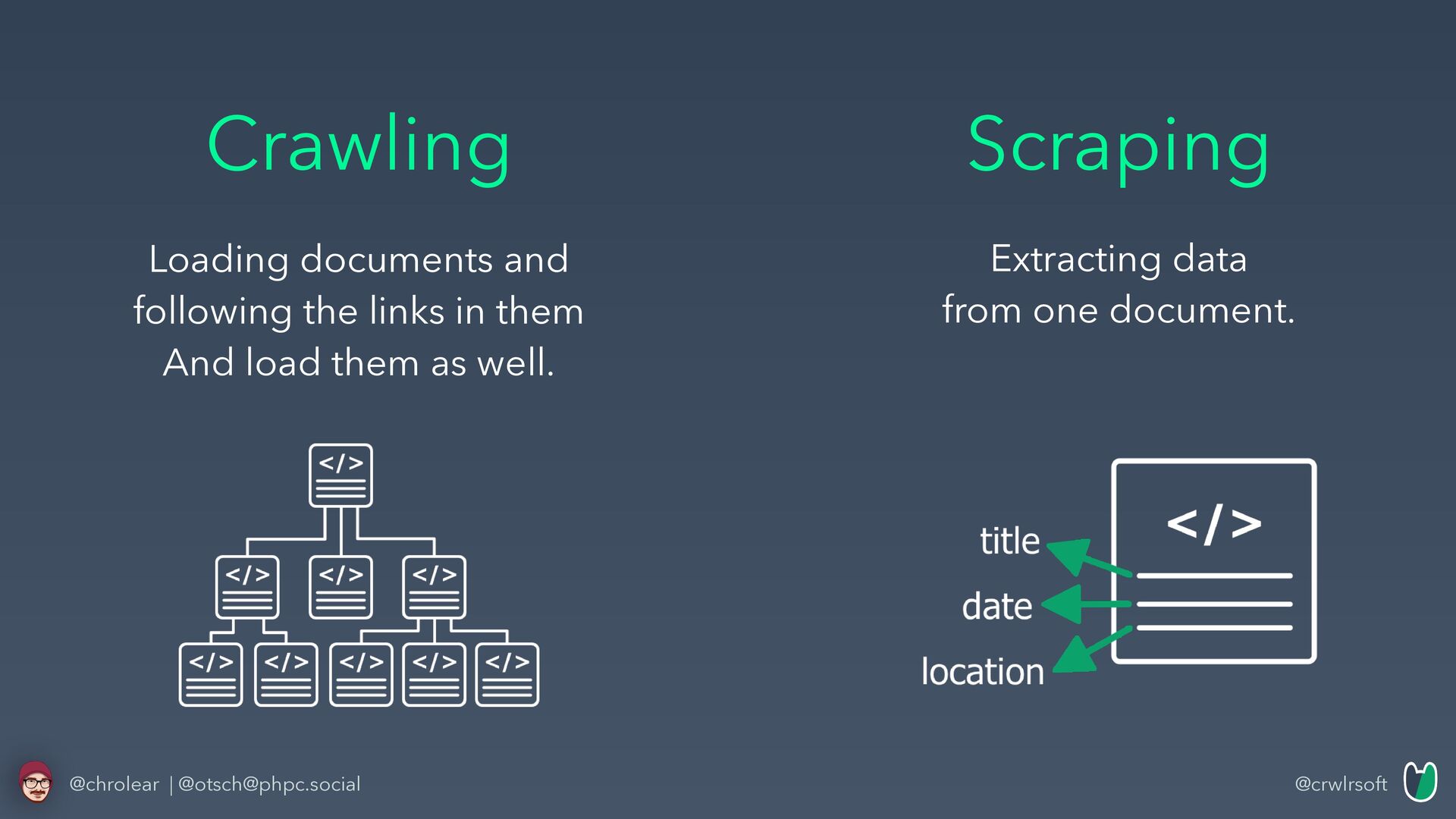
people actually do both in separated processes • Doing so you’re • Parsing documents twice • Unnecessarily using a lot of disk space or memory • From my experience a lot of people combine c&s • Instead of always saying „crawling & scraping“, I prefer the term crawling @chrolear | @[email protected]
crawlers since 2008 in my day job • Over time a lot of helping libraries have been released • Some mainly focused on crawling, some on scraping • Most only for HTTP and HTML • Basically no implementation of a polite Crawler/Bot @chrolear | @[email protected]
thought a bit too ambitious in the beginning • Wanted to build URL parser, HTTP client, DOM lib.,… • Started with the URL parser @chrolear | @[email protected]
access and modify all components separately • Works with IDN • Even tells you subdomain, domain, domain suf fi x using mozilla public suf fi x list • Resolve relative paths against a base URL • Advanced Query String API • … @chrolear | @[email protected]
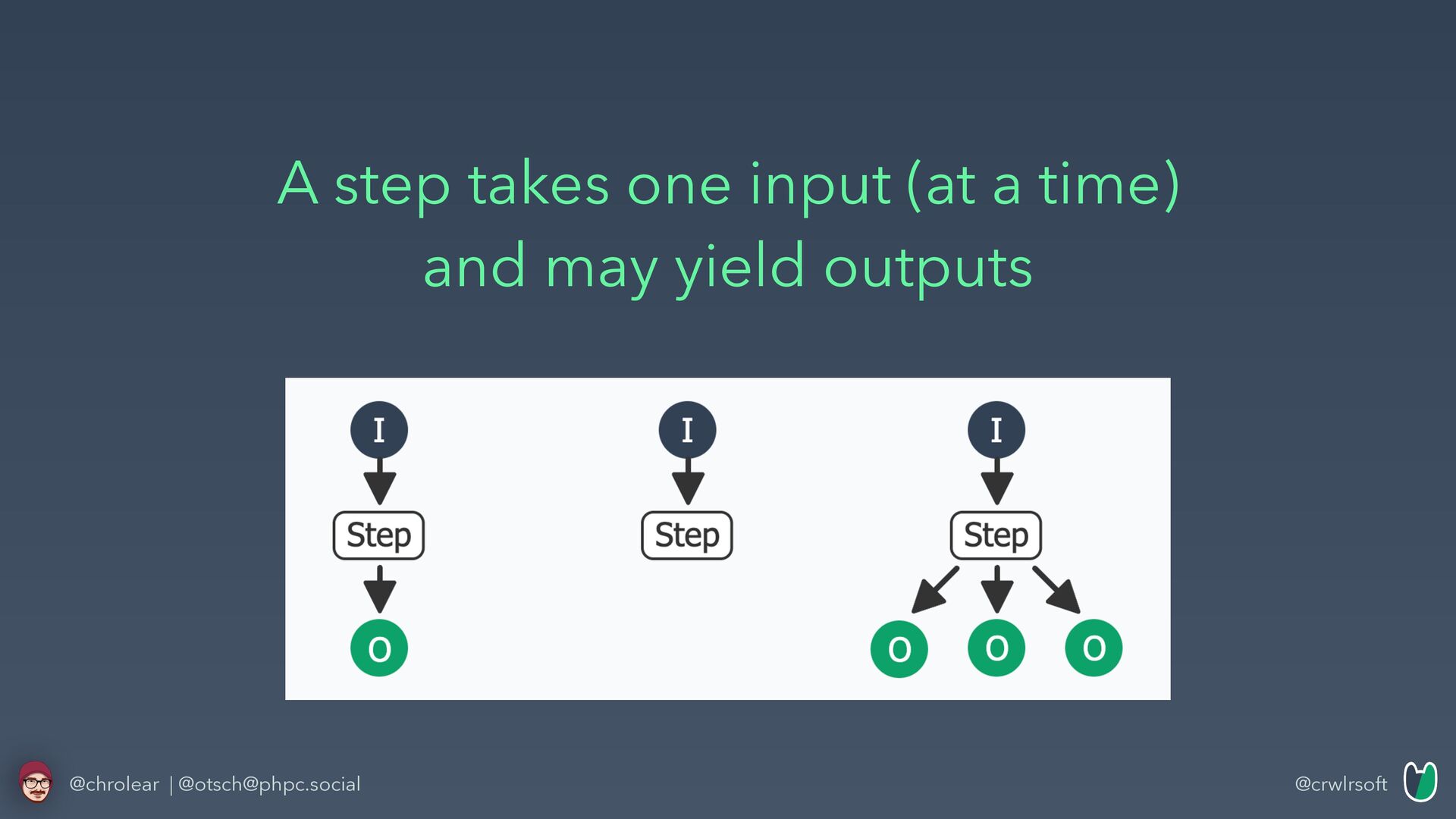
and also Extracting Data) • Steps have Input(s) and Output(s) just like a simple function • The lib provides a lot of common Steps • that can be arranged to build a Crawler @chrolear | @[email protected]
and memory consuming • Therefore steps have to return a Generator • Had a Crawler that previously went up to use more than 4 GB of memory => with Generators down to max. usage below 0,5 GB @chrolear | @[email protected]
return the whole array (all its elements) at once • Functions returning a Generator, yield element by element. So the fi rst returned element (output) can be processed further, before the program has even created the next element. @chrolear | @[email protected]
By default it loads pages using guzzle HTTP client • You can also switch to use a headless chrome (uses chrome- php/chrome composer package under the hood) • Is home to the politeness features, which also have some settings @chrolear | @[email protected]
to feed multiple steps with the same input. • You can also combine the outputs to one group output. • Example: You want to extract data from HTML and additionally from JSON-LD within a <script> tag in the same HTML document. @chrolear | @[email protected]
results are the last step’s outputs. • By using addKeysToResult() (array outputs) or setResultKey() (scalar outputs) a step adds data to the fi nal crawling result. • This way you can compose results with data coming from different steps. @chrolear | @[email protected]
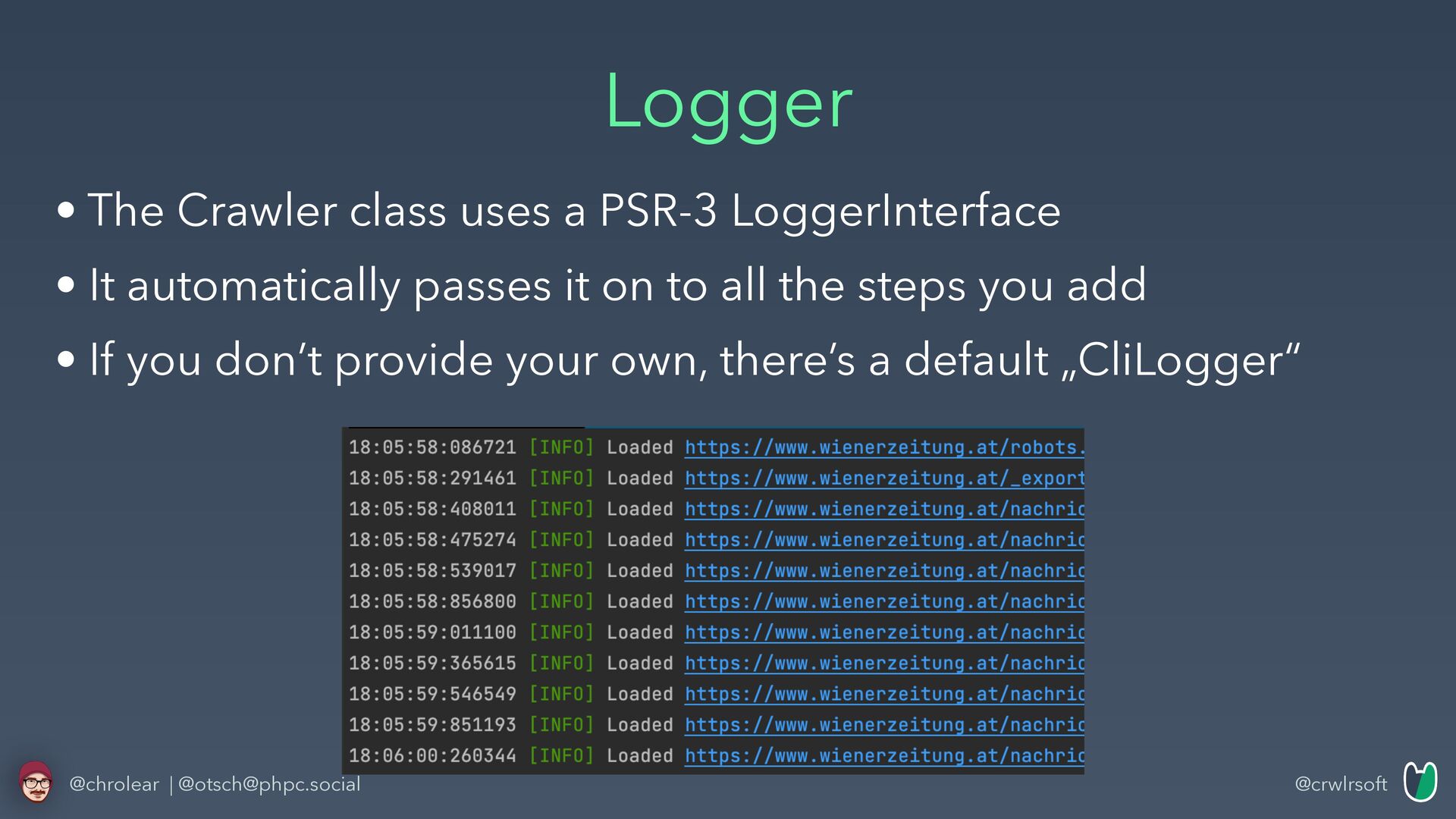
• Implement invoke() method • Optionally use validateAndSanitizeInput() • You can use the PSR-3 Logger via $this->logger @chrolear | @[email protected]
• loads robots.txt fi les and sticks to the rules (if you use a BotUserAgent) • Waits a little bit between requests. The wait time is based on how long responses take to be delivered. (Can also be set to 0 if you want) • Reacts to 429 (Too Many Requests) Responses (also checks Retry- After header) @chrolear | @[email protected]
twice with the same input • E.g. helpful if it could be possible in a pagination loop that a page link could be found twice. Method uniqueOutput() • Don’t return the same output twice Both can take a key as argument if I/O is array or object. @chrolear | @[email protected]
with a lot of nice features and improvements • There will presumably be some more 0.x tags. Planned features: • Improve composing results • Step to get data from RSS (and other) feeds • Further loaders (FTP, fi lesystem?) • … • Plan to tag v1.0 the next months @chrolear | @[email protected]
Or, of course also steps, if you have any ideas • Approach me anytime to discuss ideas • Later today • on twitter/mastodon • via crwlr.software @chrolear | @[email protected]
features that I haven’t mentioned yet • If you have any need or idea for crawling => try it! • If you do, please tell me what you think about it! 🙏 • Docs: crwlr.software @chrolear | @[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@crwlrsoft 💩 Craping @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![@crwlrsoft The actual crawling system @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_8.jpg){kind=link}
![@crwlrsoft @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@crwlrsoft What about Pagination? @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_18.jpg){kind=link}
![@crwlrsoft New Pagination Feature @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@crwlrsoft Demo Time @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention! @crwlrsoft @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_34.jpg){kind=link}
![Questions? @crwlrsoft @chrolear | @[email protected]](https://files.speakerdeck.com/presentations/1e1b203eb25e4b18a7efab54c40439a1/slide_35.jpg){kind=link}