потоками событий — Topic — способ группировки потоков сообщений в отдельную тему — Producer — издатель потоков сообщений — Consumer — подписчик на потоки сообщений — Partition — файл содержащий подмножества сообщений из topic — Offset — уникальный для тройки topic-consumer-partition номер сообщения
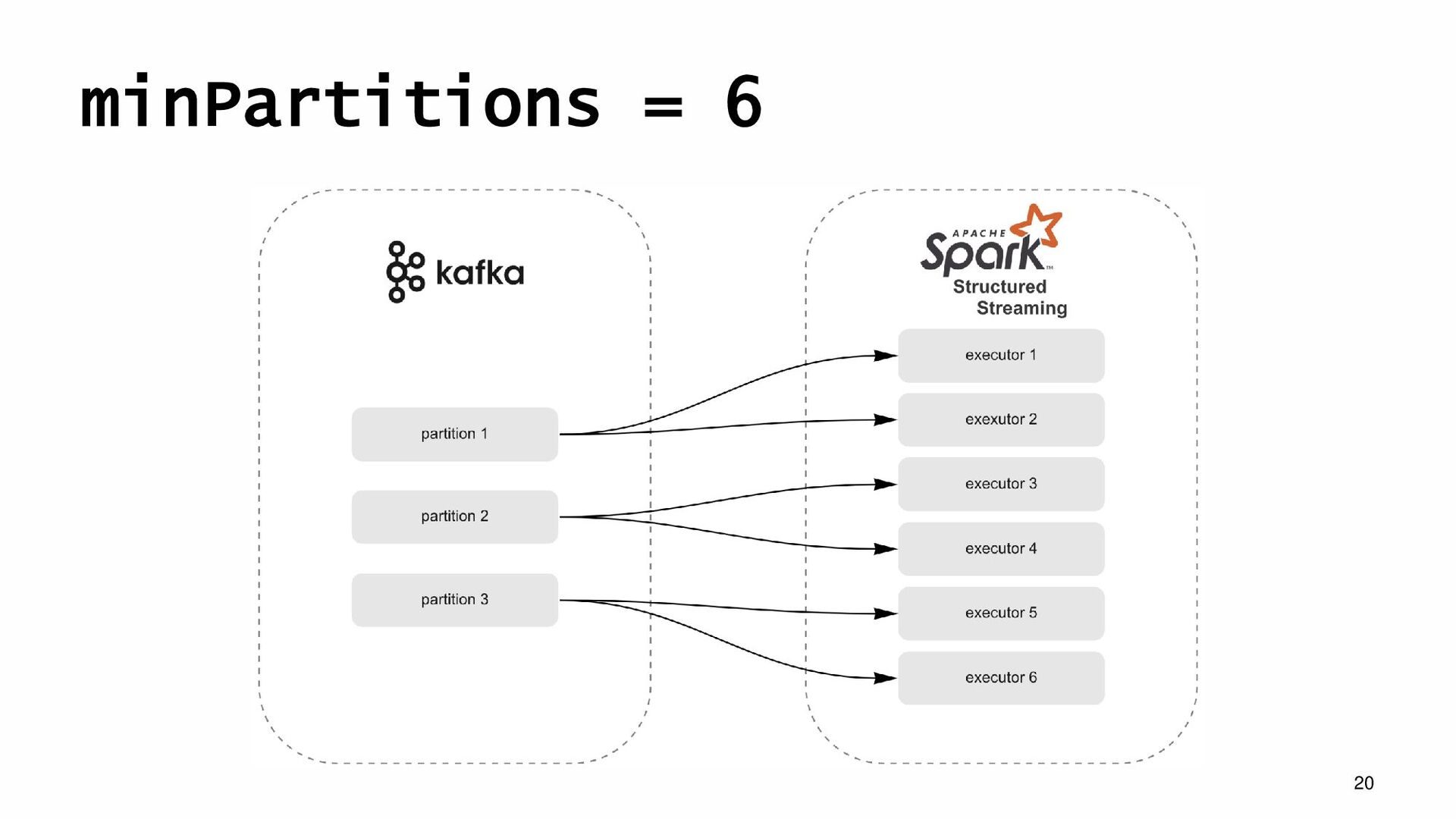
за интервал minPartitions — число Spark задач, на которое разбивается прочитанный батч из topic startingOffsets — точка старта в kafka-topic при первом запросе → https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
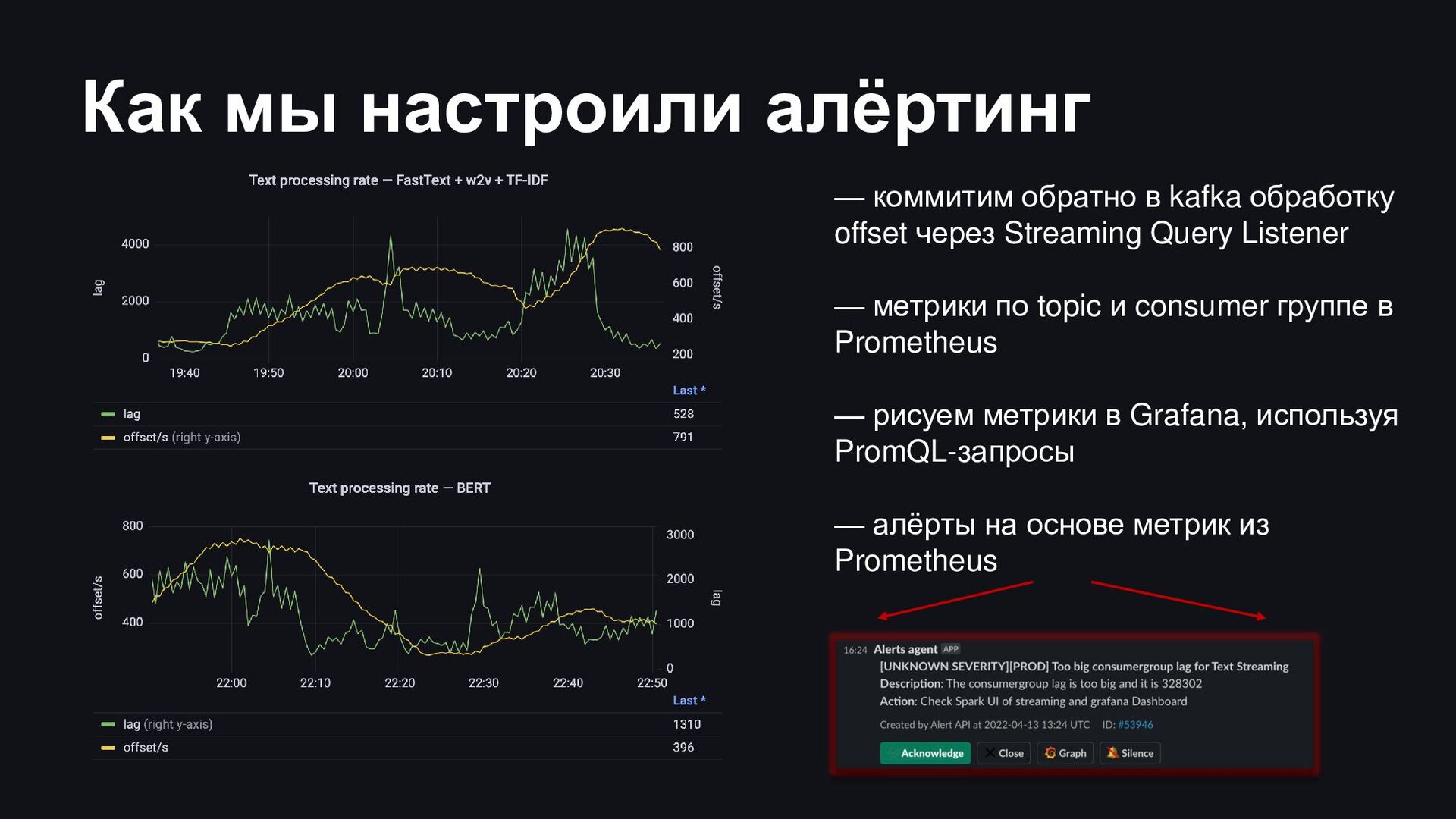
offset через Streaming Query Listener — метрики по topic и consumer группе в Prometheus — рисуем метрики в Grafana, используя PromQL-запросы — алёрты на основе метрик из Prometheus
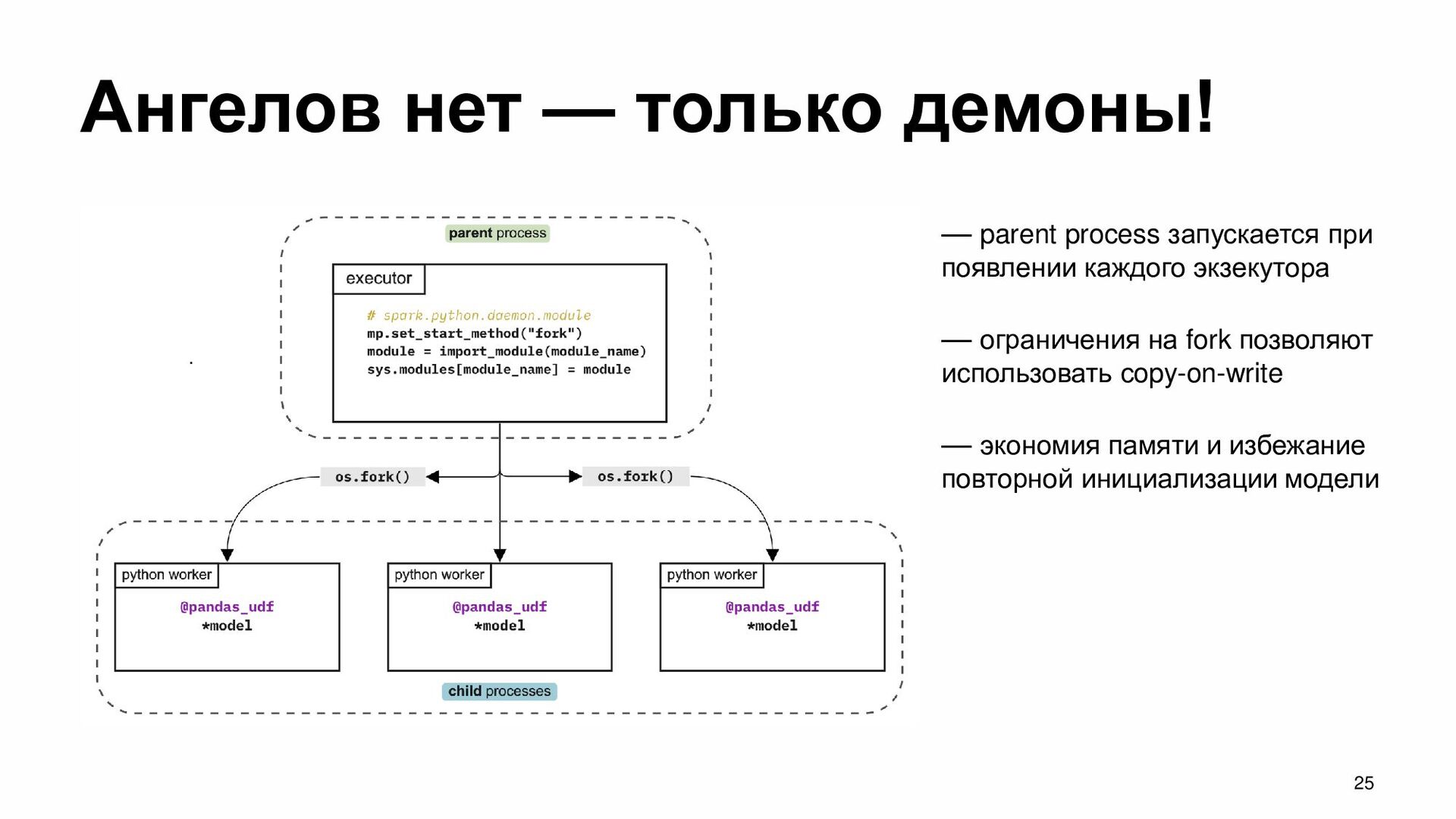
при появлении каждого экзекутора — ограничения на fork позволяют использовать сopy-on-write — экономия памяти и избежание повторной инициализации модели
эмб./с. — FastText 1x128: 1 CPU, 100 эмб./с. — *ResNet-50 1x128: 1CPU, 1.5-3 эмб./с. — **Prod2Vec 1x256: 1CPU, 1.5-3 эмб./с. * зависит от скорости скачивания картинки и от того, как они подаются на вход ** Prod2Vec (2xTinyBert + 1xResNet-34) — подробнее на Хабр переходите по QR-коду
{kind=link}
{kind=link}
{kind=link}
{kind=link}
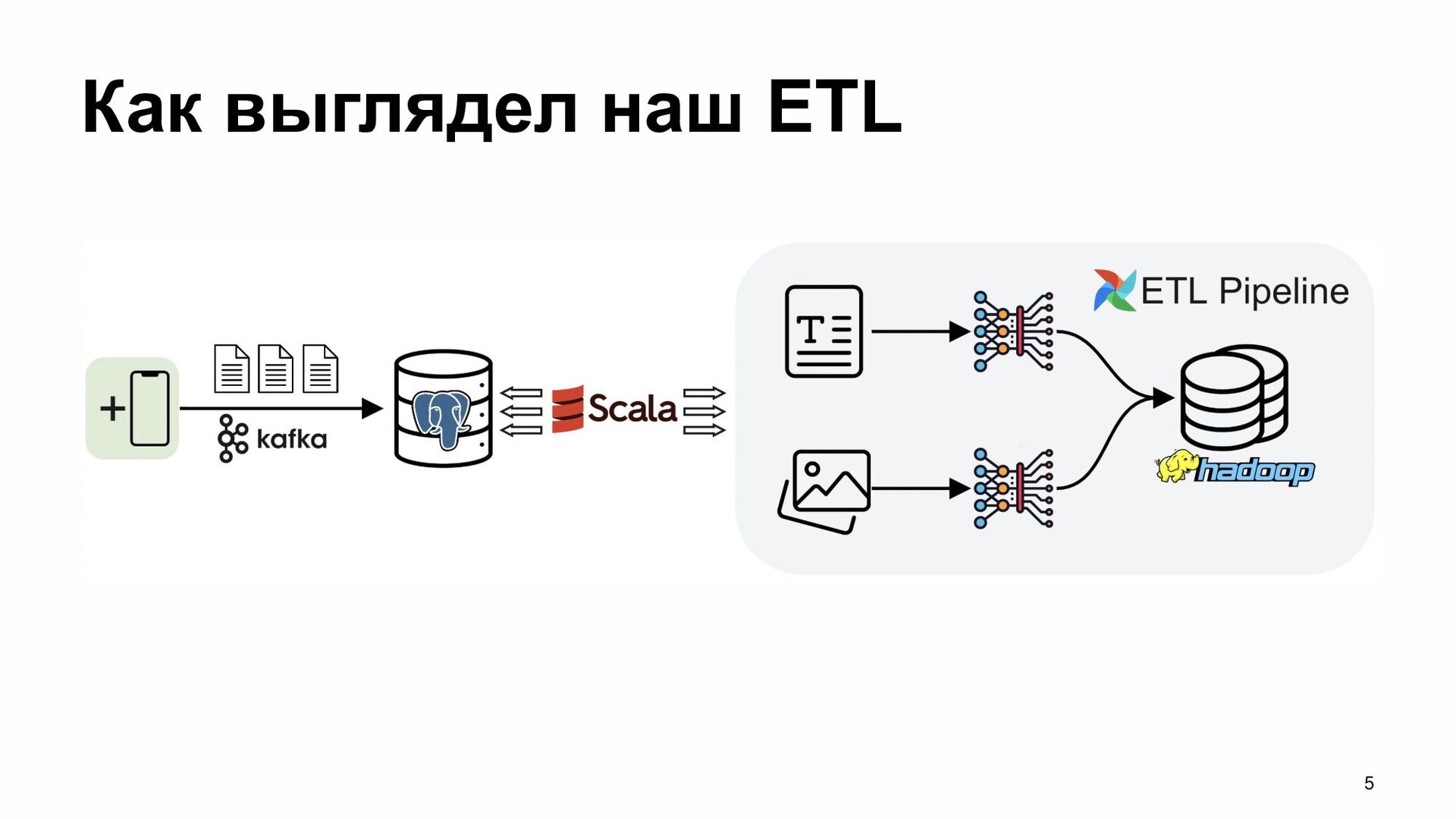{kind=link}
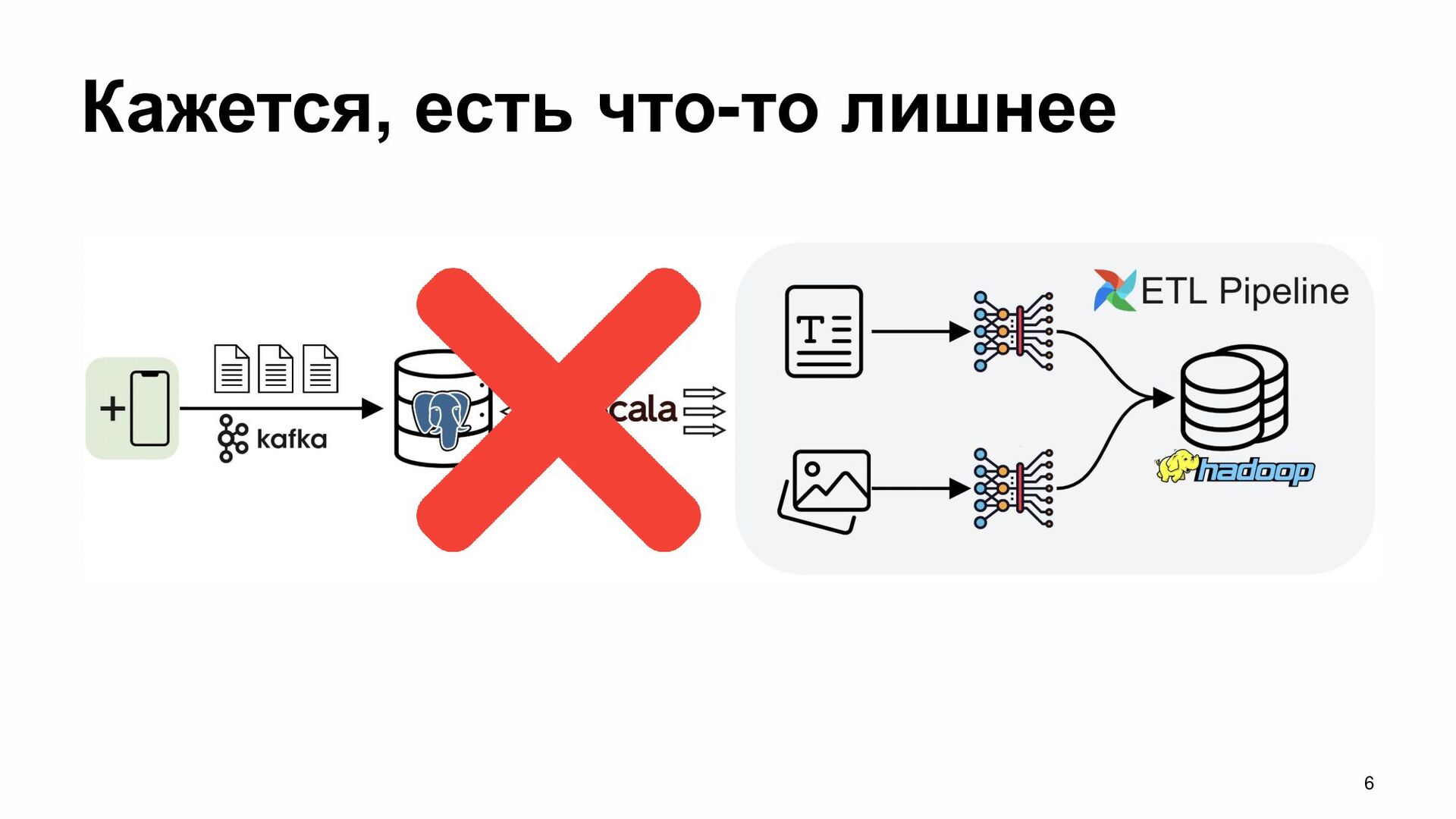{kind=link}
{kind=link}
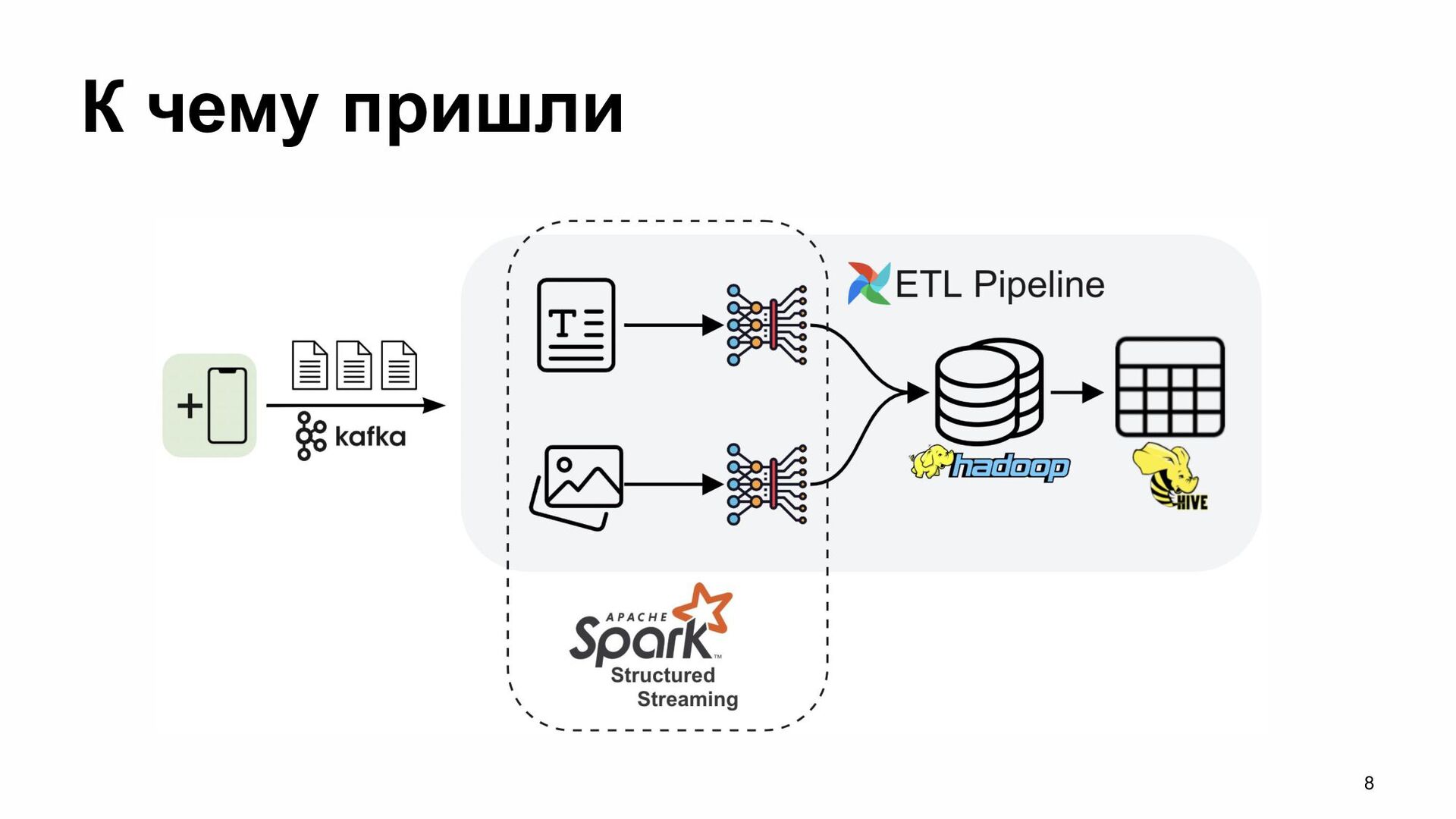{kind=link}
{kind=link}
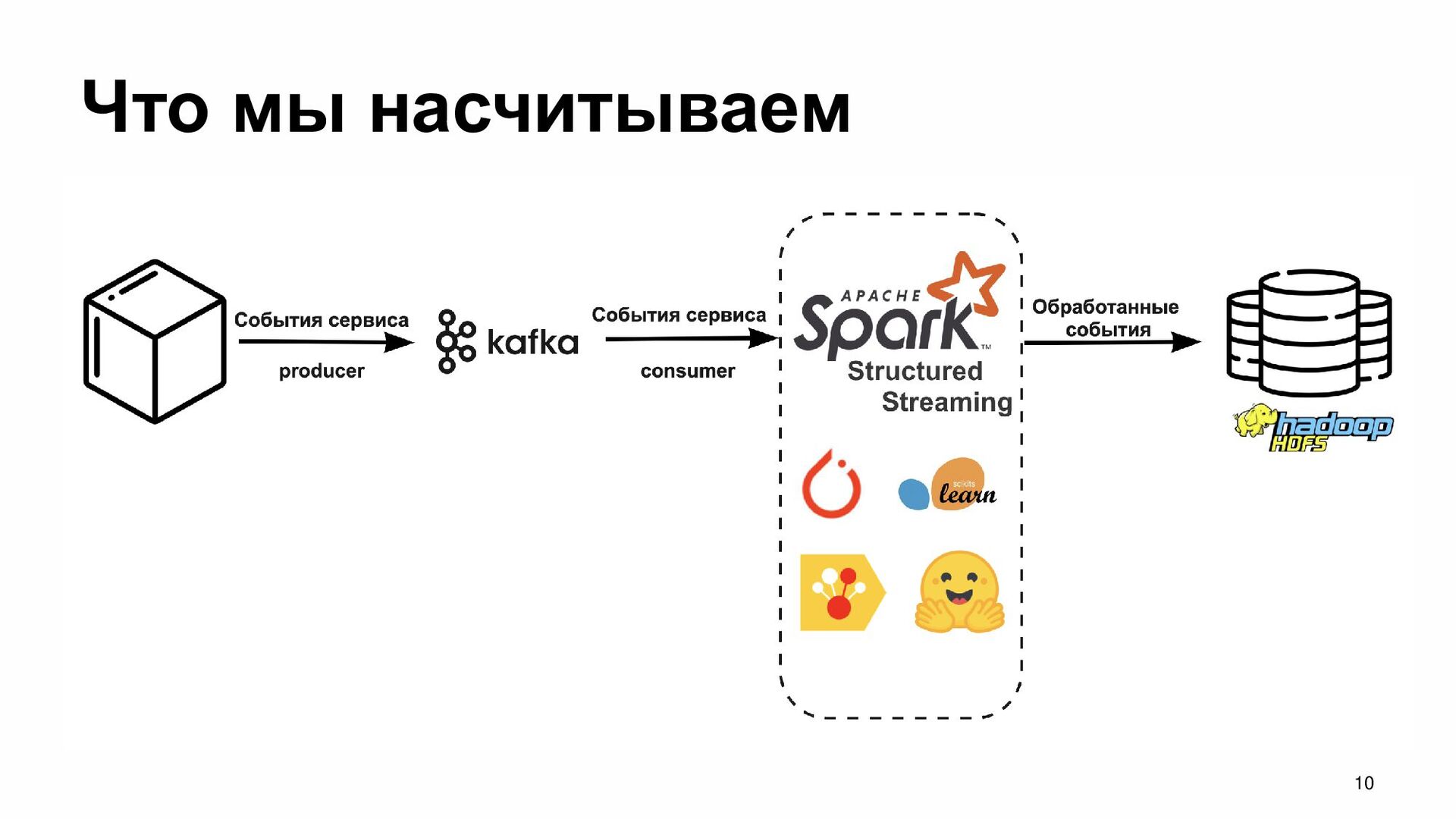{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ван Хачатрян Спасибо за внимание! [email protected]](https://files.speakerdeck.com/presentations/c7f1eb687f87406d91d209a8c0e6737f/slide_26.jpg){kind=link}
{kind=link}