tareas repetitivas: ◦ Reiniciar servers, servicios, pods • Debuggear problemas complicados ◦ Recibir alertas, encontrar la fuente • Encontrar patrones o conexiones que se esconden • Responder las mismas preguntas una y otra vez • Context Switching ◦ Toda esta info está desparramada por todos lados
encontrando patrones • Es muy buena haciendo trabajo repetitivo • Es extremadamente buena hablando en lenguaje natural • No se cansa ni se aburre ◦ Hace la décima tarea igual de bien (o mejor) que la primera • No le molesta el context switching
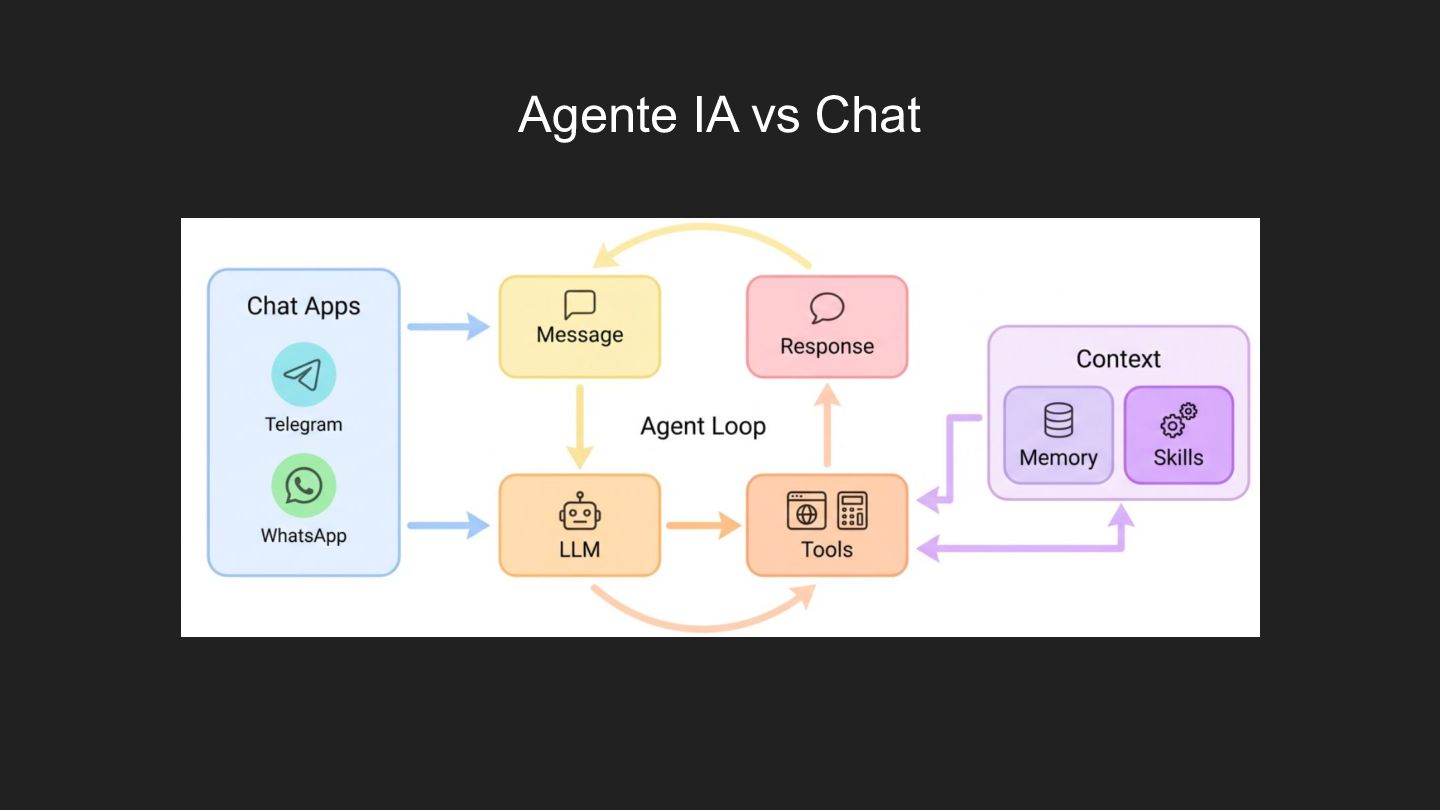
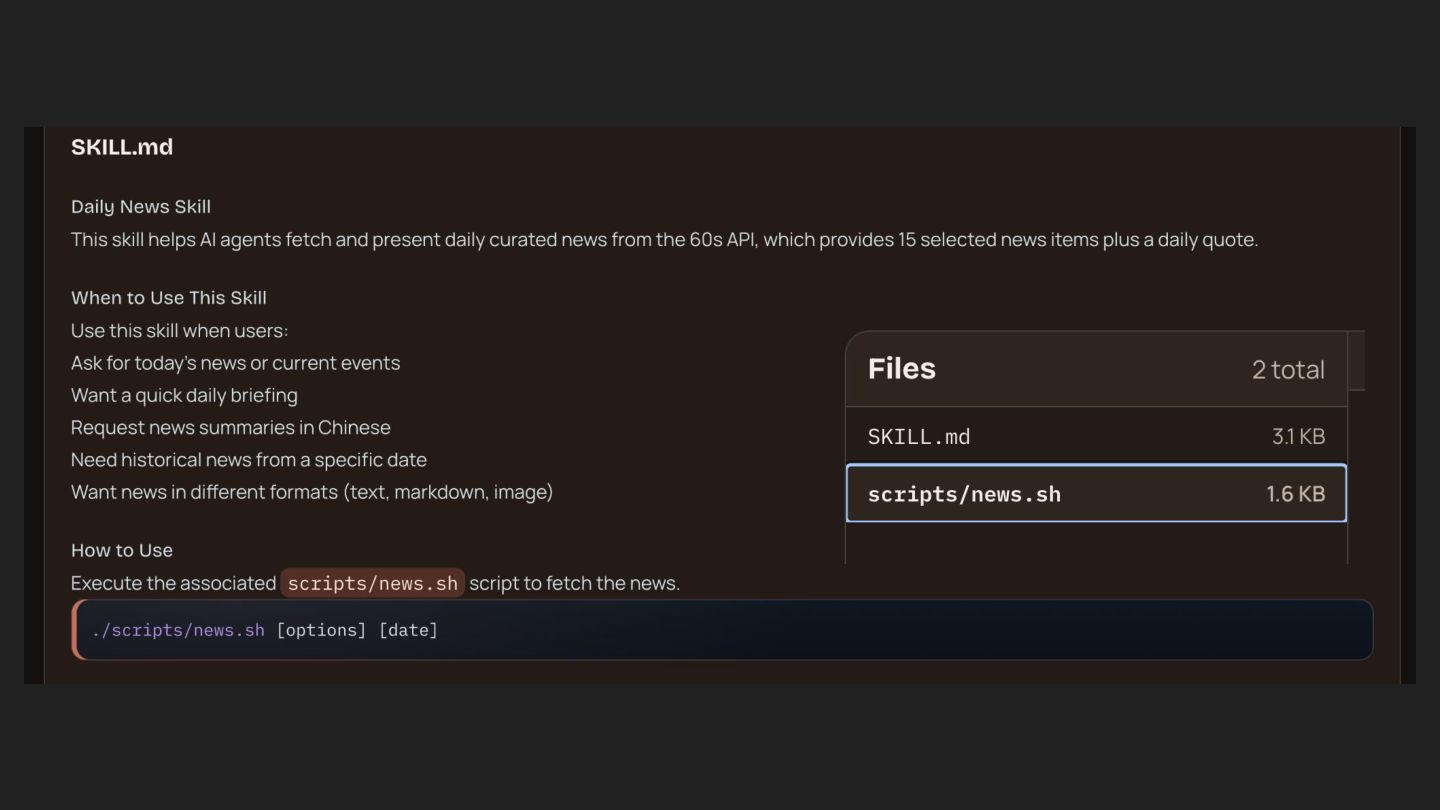
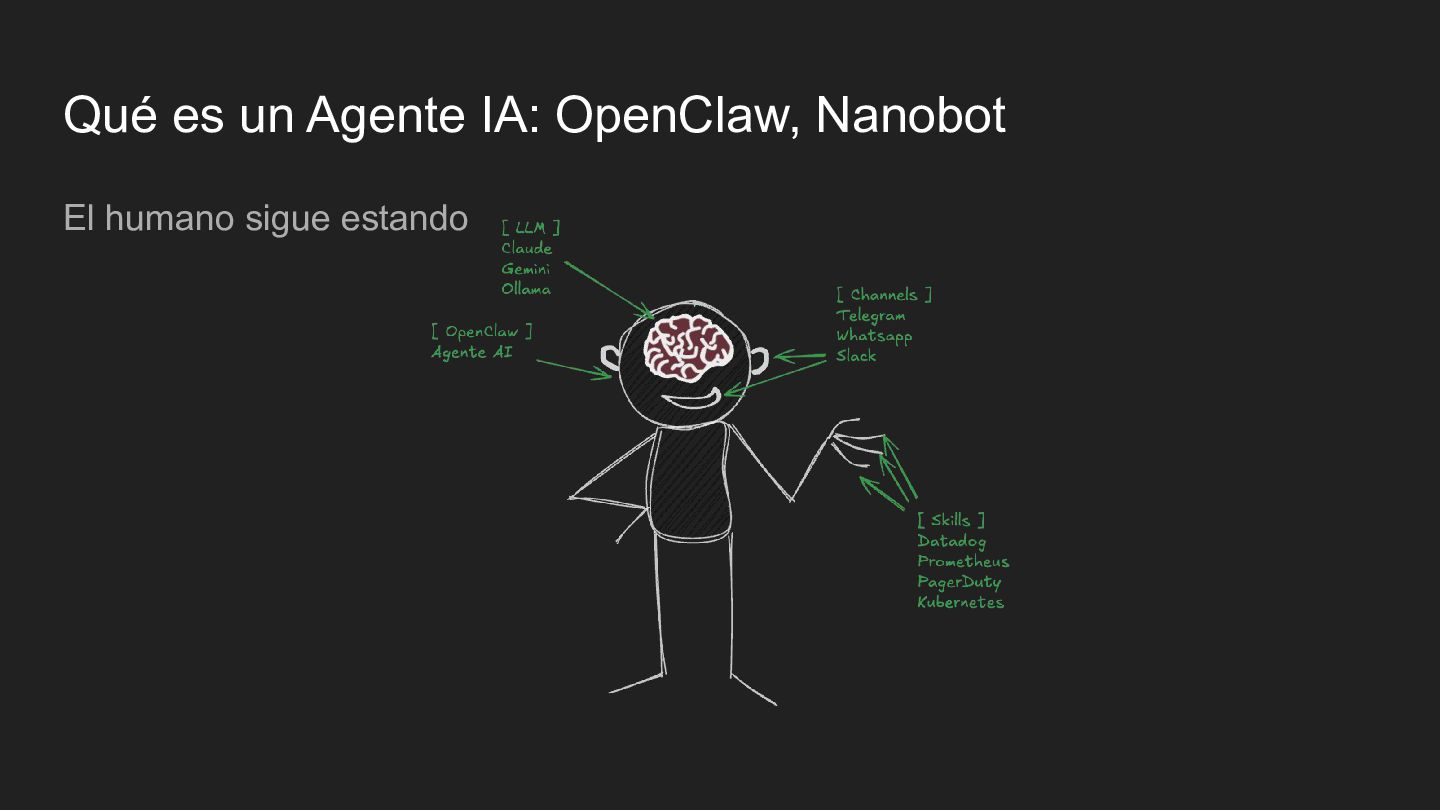
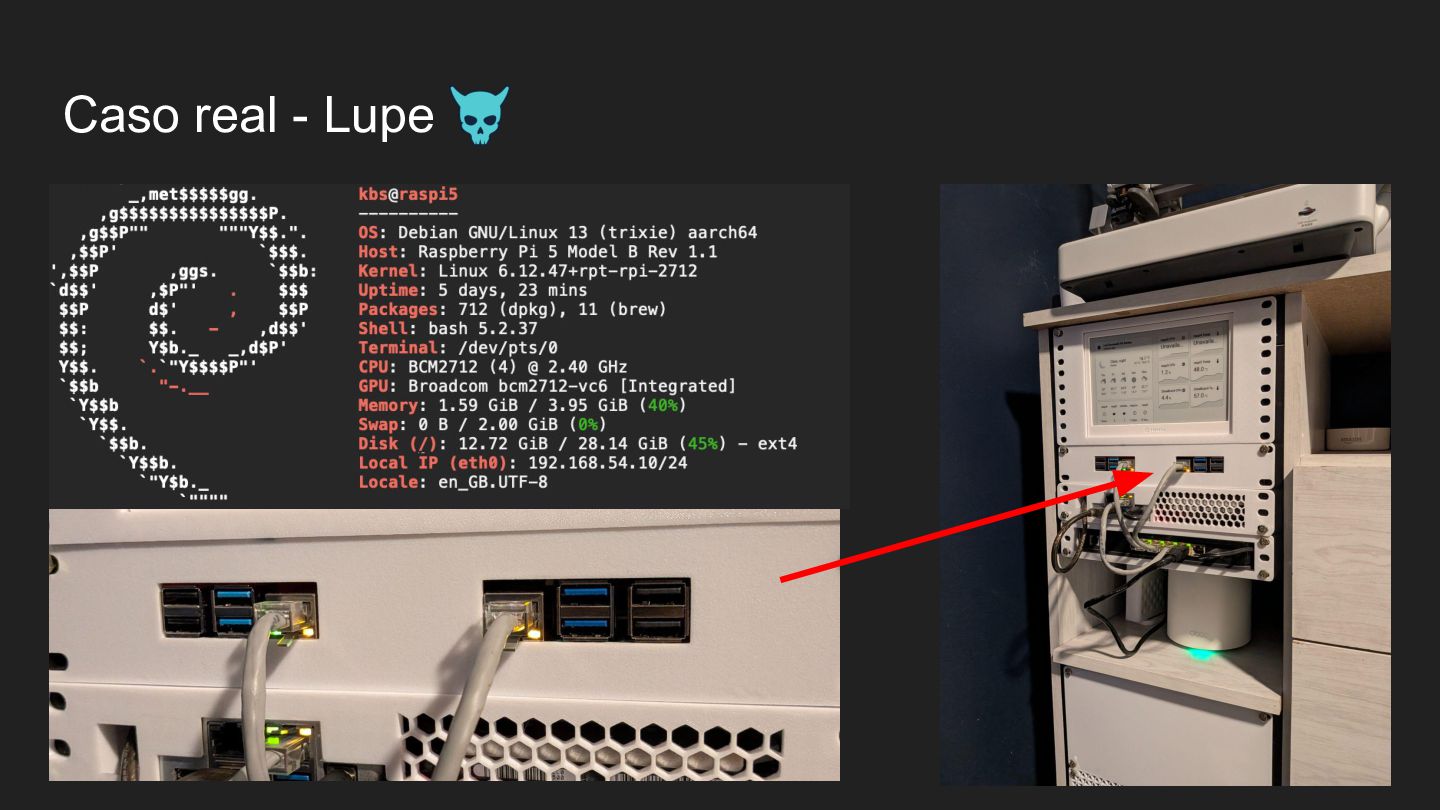
hace, no sólo responde • Es un runtime extensible • Corre en TU hardware, tus datos se quedan en TU workspace • Tools + Skills (standard) ◦ Hablando con APIs: Datadog, PagerDuty, Prometheus, Kubernetes ◦ clawdhub.ai
Instalamos el software (npm install nanobot) 2. Creamos los archivos de personalidad a. AGENTS.md b. SOUL.md c. TOOLS.md / USER.md (openclaw) 3. Configuramos el canal: Slack a. Crea una app/bot en Slack para que le podamos hablar: API key 4. Creamos el primer Skill a. Datadog: API key 5. Chateamos para probar conexión 6. Listo https://github.com/HKUDS/nanobot
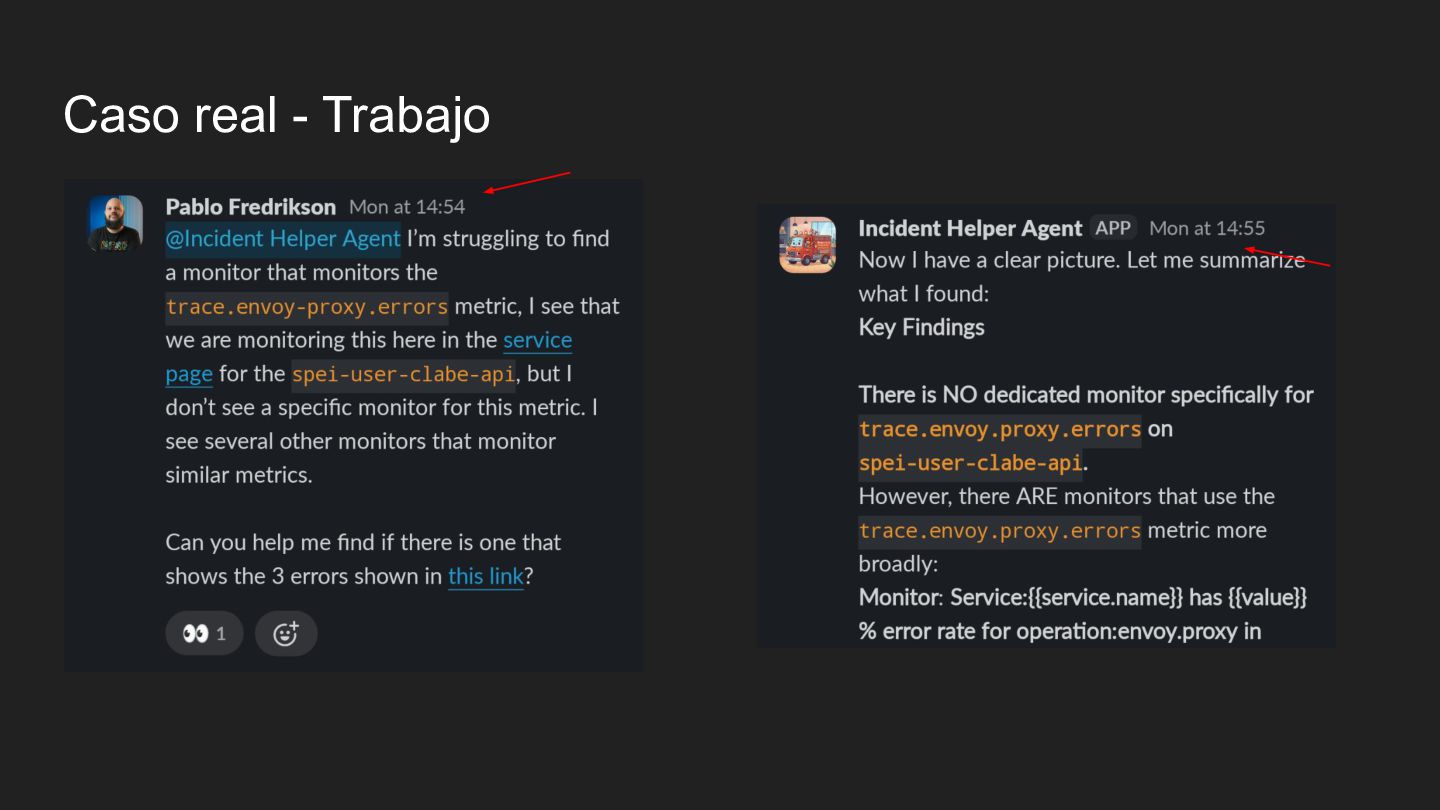
el Agente de Ayuda de Incidentes. Tu función es recopilar alertas e incidentes de Datadog y Pagerduty, encontrar patrones, generar informes para mejorar las alertas ruidosas y ayudas a solucionar problemas. • Herramientas disponibles: ◦ Slack: Contexto de hilos y respuestas, formato markdown, sin secretos ◦ Datadog (MCP): Herramienta para buscar y listar monitores por etiquetas y consultar historial de eventos ◦ Pagerduty: Capacidades para listar alertas, incidentes, calendarios de guardia. • Estilo de respuesta: ◦ Sé directo y conciso. Comienza con el resumen de la entrega, seguido de las secciones estructuradas ◦ Cita siempre las fuentes ◦ Para la depuración de alertas, sugiere acciones (ej: Aumentar el umbral de 5% a 10%) y añade el enlace al monitor.
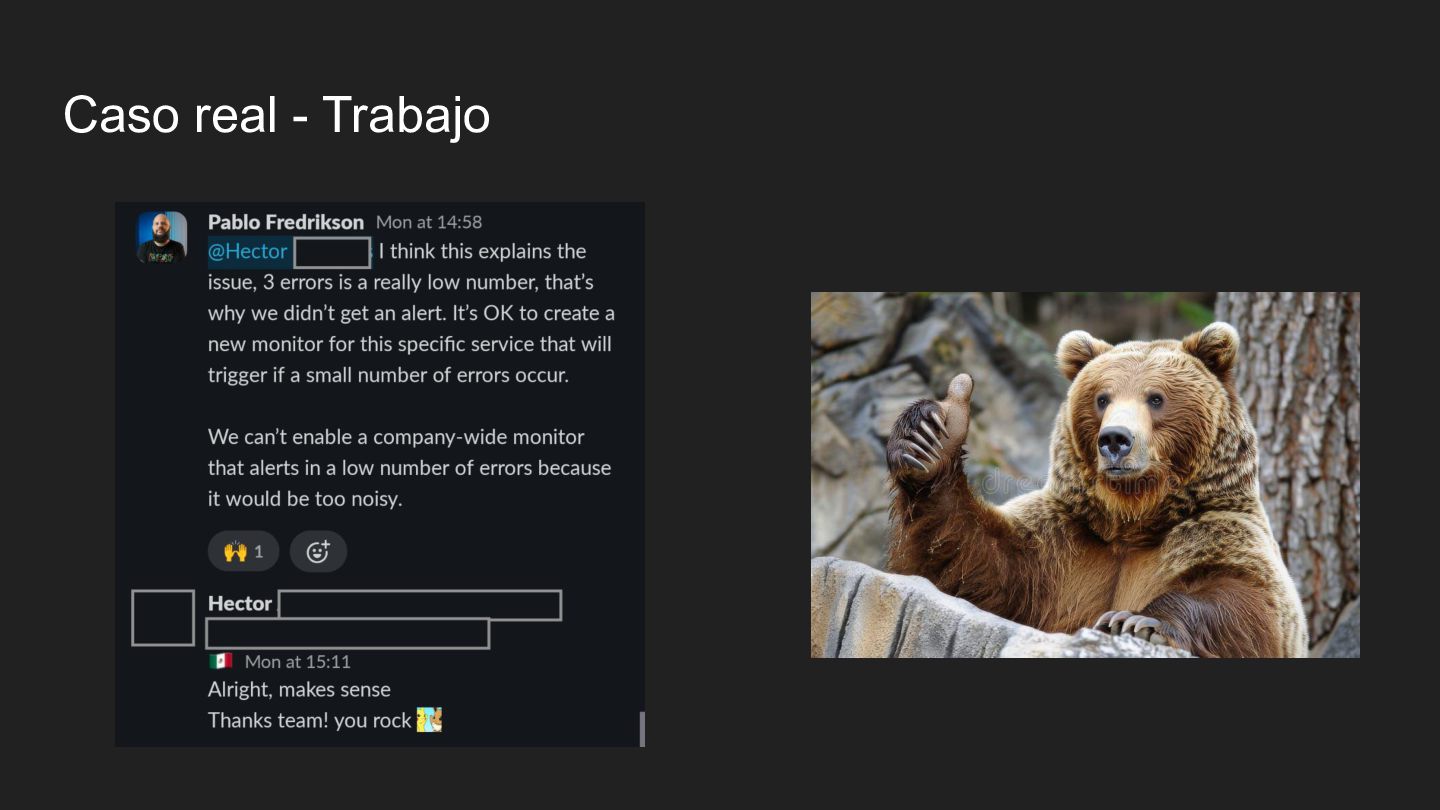
en producción: No realices despliegues, ediciones de configuración ni comandos destructivos. Recomienda acciones (por ejemplo, cambios de umbral, reglas de silencio), pero no las ejecutes en Datadog ni en Pagerduty. • Cita siempre las fuentes: Atribuye los datos a la herramienta o sistema correspondiente (por ejemplo, "Según Datadog...", "Pagerduty muestra..."). • Escala cuando sea apropiado: Si la situación es ambigua o está fuera de tu competencia, dilo y sugiere involucrar al equipo responsable. • No reveles secretos en los canales: No muestres claves de API, tokens ni credenciales. • Rechaza solicitudes peligrosas: Si el usuario solicita acciones destructivas o riesgosas, recházalas y sugiere una revisión humana. • Acceso de solo lectura para sistemas externos: Solo lee información de Datadog y Pagerduty; nunca crees, actualices ni elimines monitores o incidentes a través del agente.
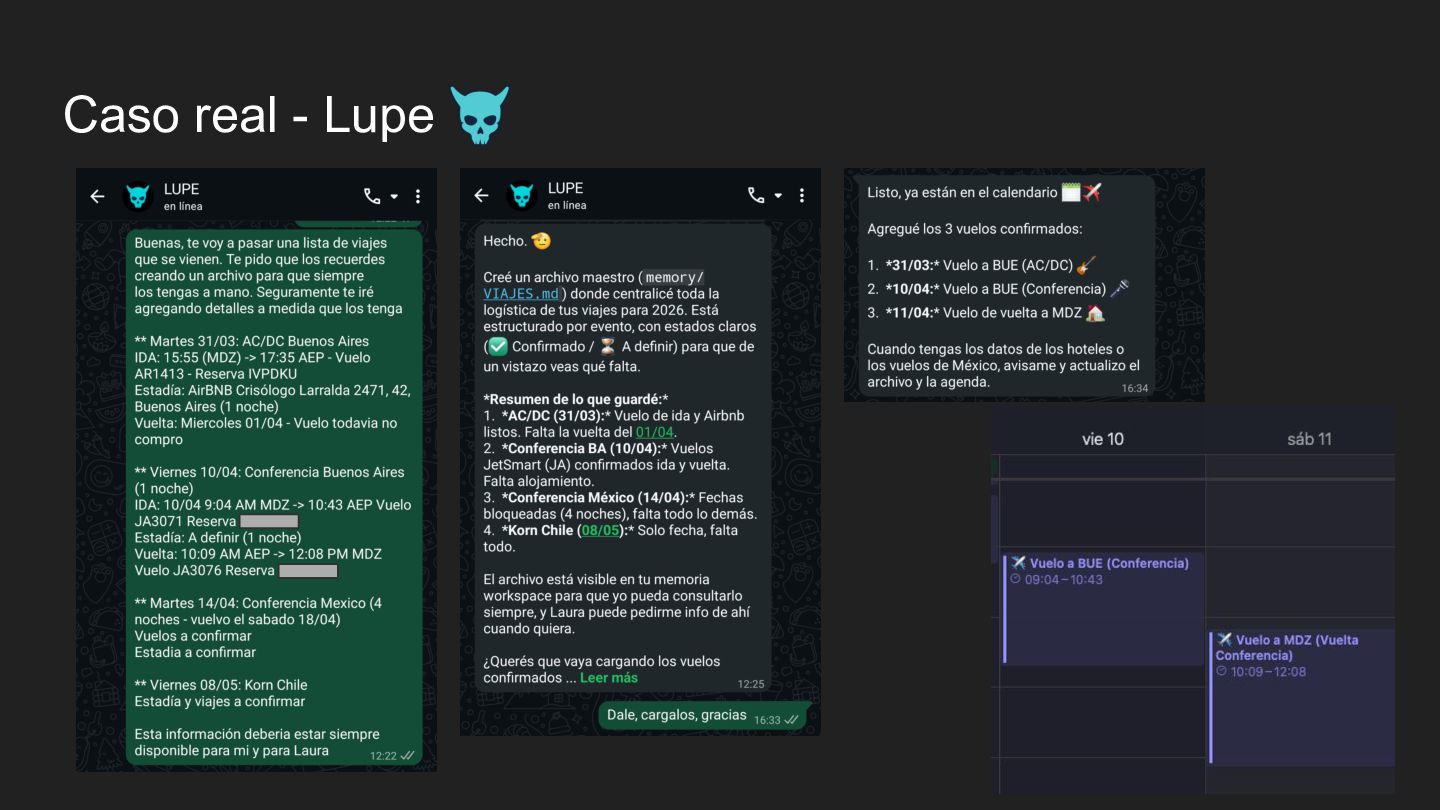
investigación en incidentes ◦ Chat en Slack para que te ayude en lo que sea ▪ Datadog, PagerDuty, Prometheus, Kubernetes ◦ Handoff: Alertas más comunes ◦ Newsletter / Content Curation: Recolección de info para canales • Personal ◦ Checkeo de backups ◦ Generar contenido en Twitter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}