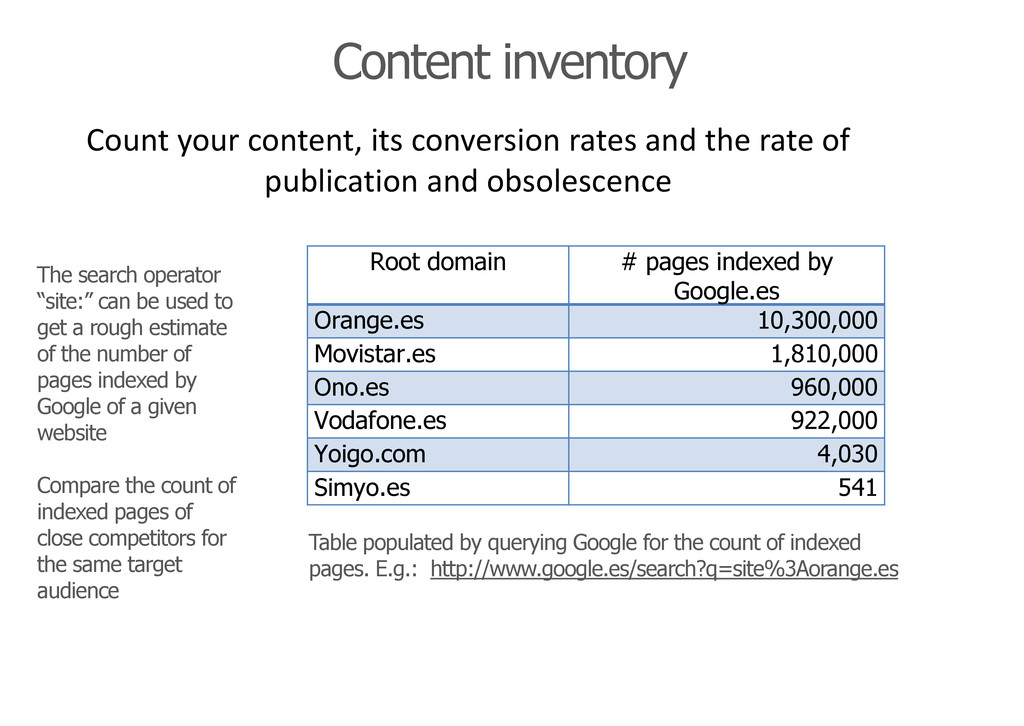
rough estimate of the number of pages indexed by Google of a given website Compare the count of indexed pages of close competitors for the same target audience Content inventory Root domain # pages indexed by Google.es Orange.es 10,300,000 Movistar.es 1,810,000 Ono.es 960,000 Vodafone.es 922,000 Yoigo.com 4,030 Simyo.es 541 Table populated by querying Google for the count of indexed pages. E.g.: http://www.google.es/search?q=site%3Aorange.es Count your content, its conversion rates and the rate of publication and obsolescence
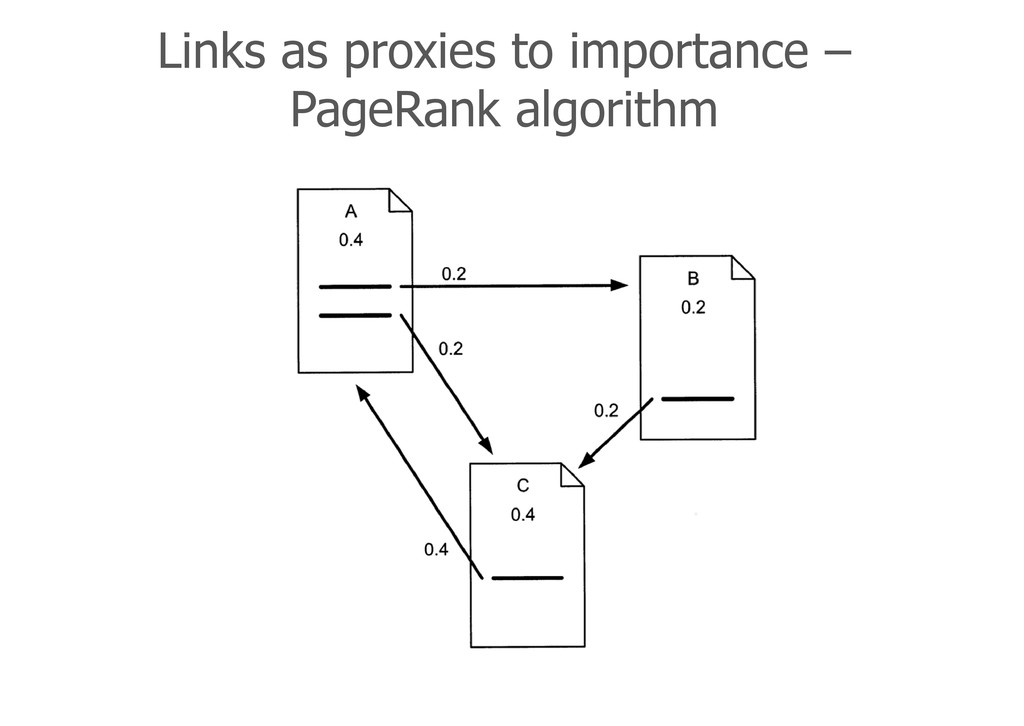
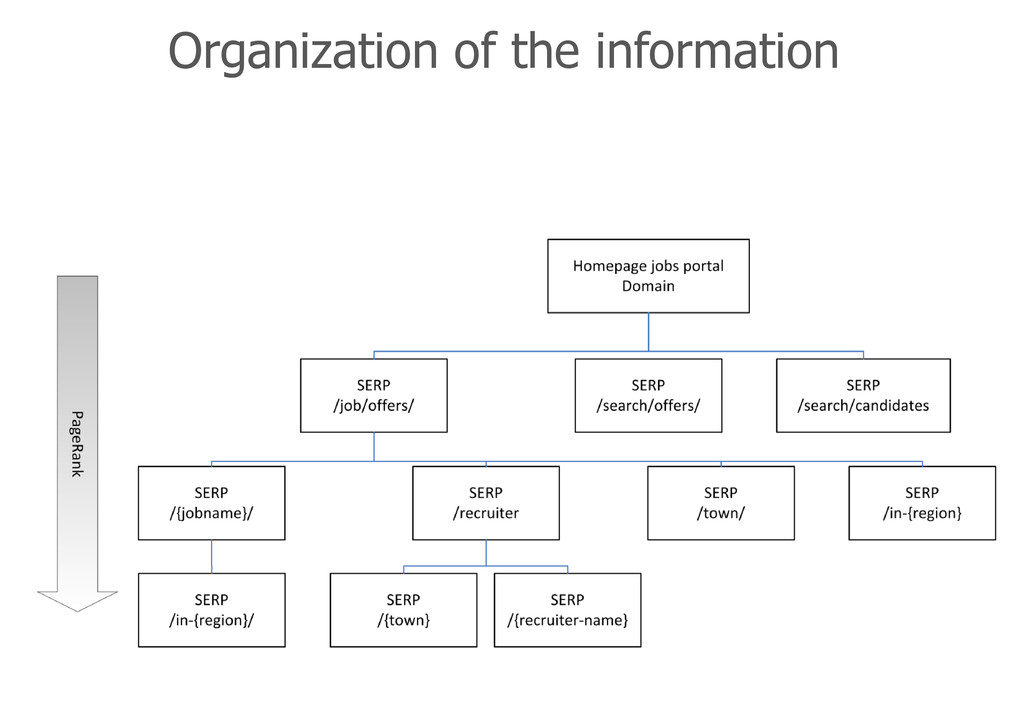
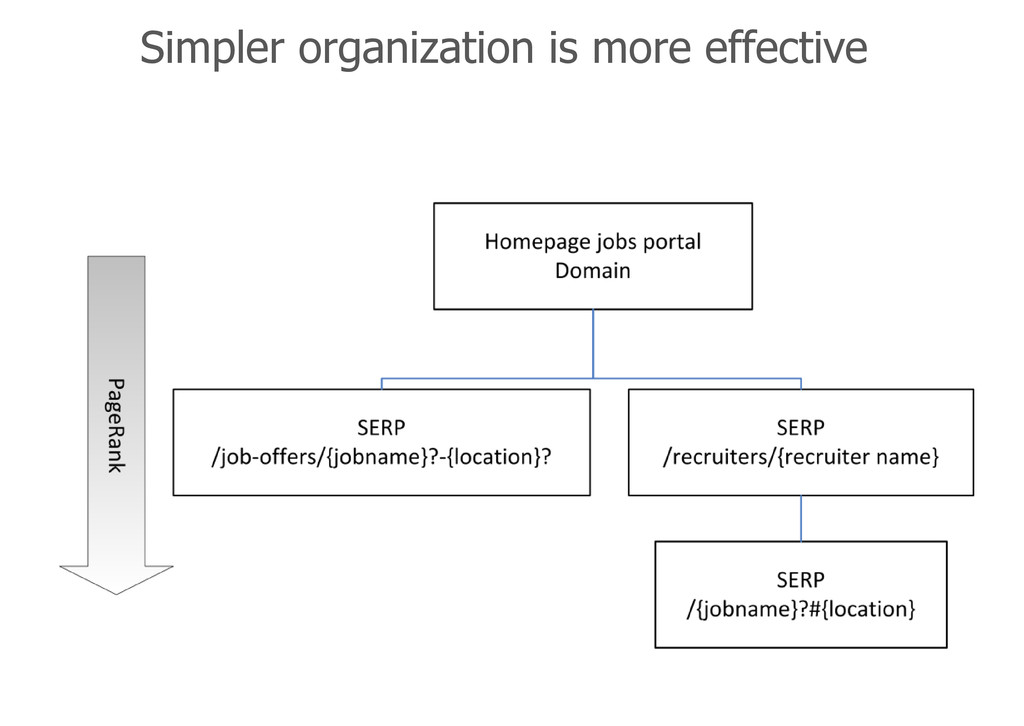
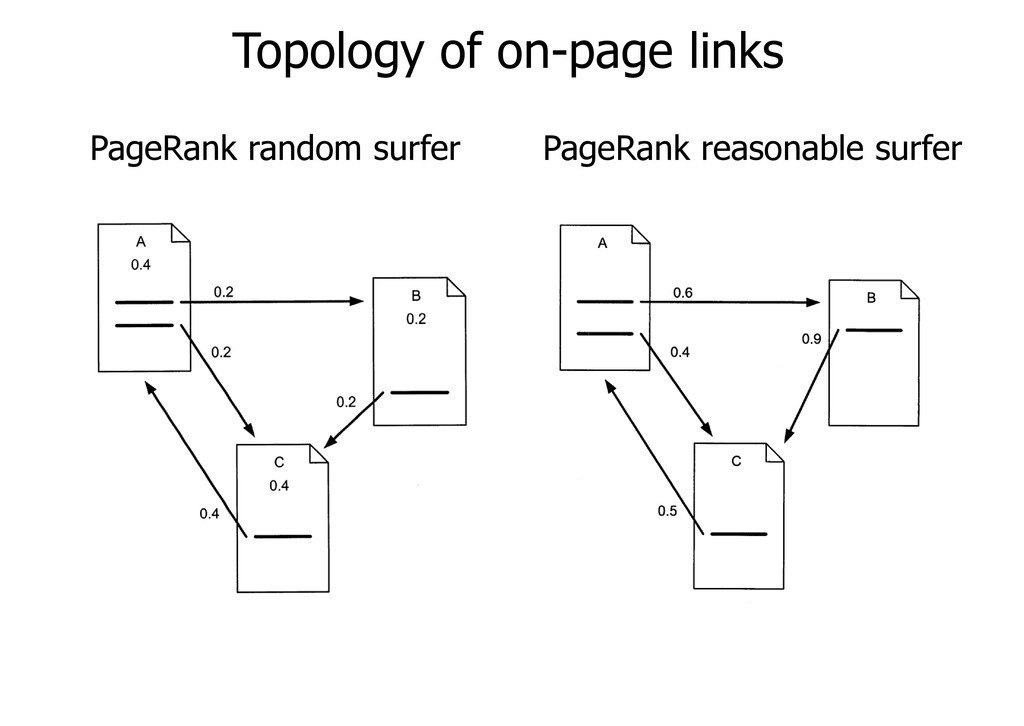
pN are the pages whose value we are determining, M (pj ) is the set of pages that link to pi L (pj ) is the number of outbound links on page pj N is the total number of pages
of your website Crawl with Xenu’s Link Sleuth (desktop application for Windows) Filter fields on a bash shell $ head crawl.txt $ cut -f1,2 crawl.txt | sed -e 's/http\:\/\/www\.{domain}\.{tld}//g' -e 's/\t/,/g' | grep -v "\.jpg\|http\:|\.css\|\.js" >filtered.csv $ head filtered.csv
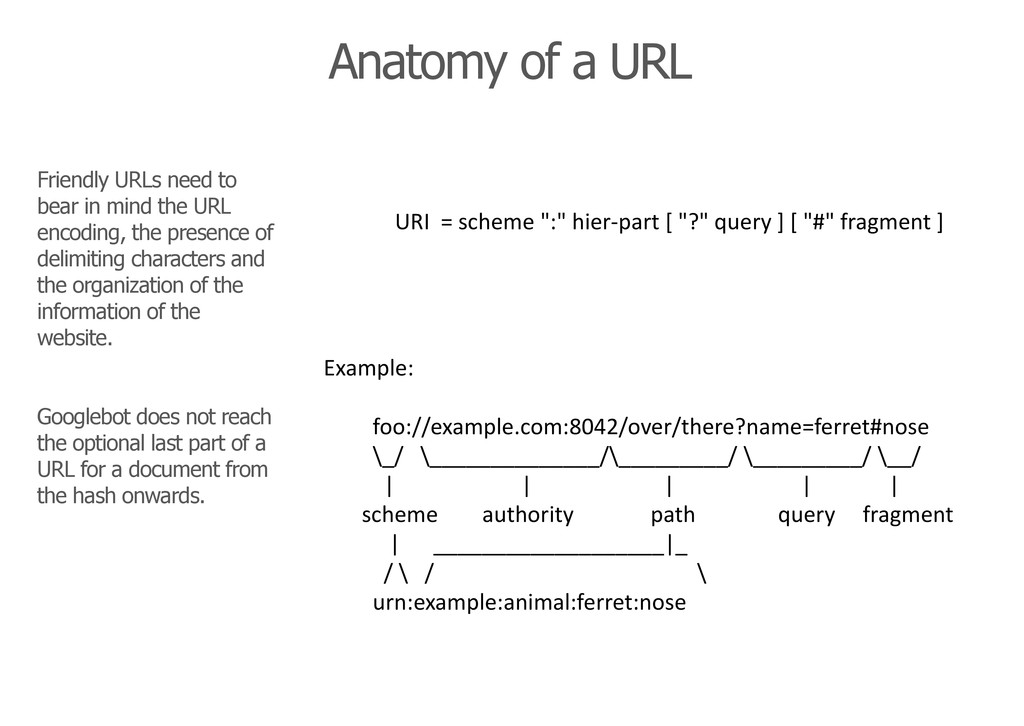
the presence of delimiting characters and the organization of the information of the website. Googlebot does not reach the optional last part of a URL for a document from the hash onwards. Anatomy of a URL URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ] Example: foo://example.com:8042/over/there?name=ferret#nose \_/ \______________/\_________/ \_________/ \__/ | | | | | scheme authority path query fragment | ___________________|_ / \ / \ urn:example:animal:ferret:nose
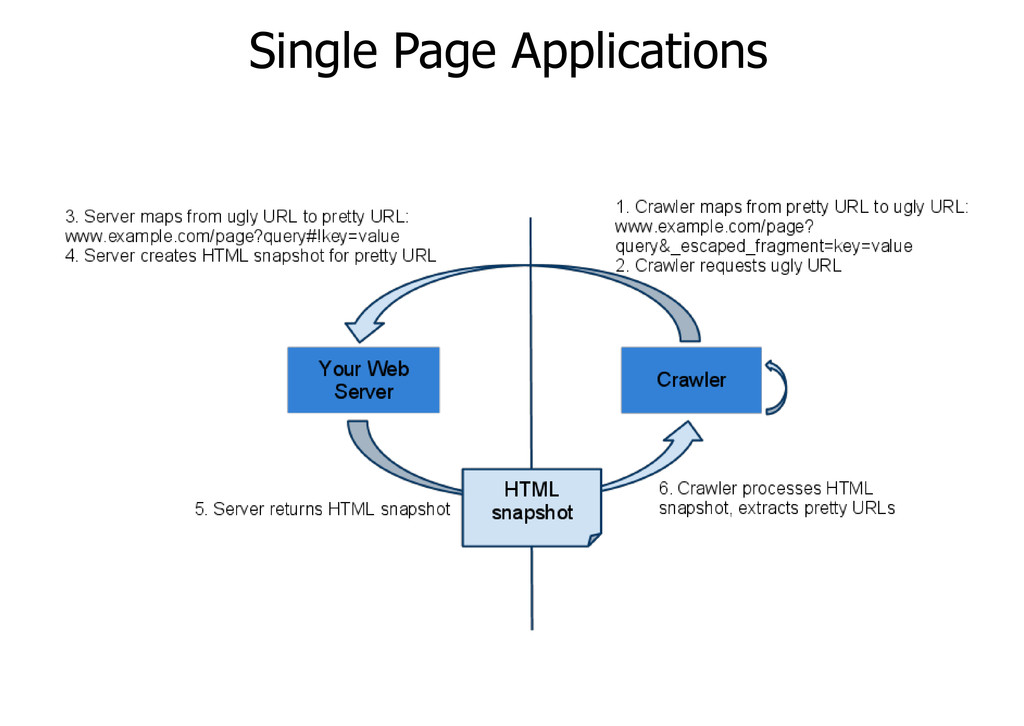
browsers from querying web servers. SAP are now growing in use thanks to AJAX and frameworks like backbone and angular.js. This is a major challenge for search engines because the fragments in the URLs prevent crawlers to scrape the content. Google are asking webmasters to make their AJAX-based websites crawlable
stateful AJAX pages http://example.com/page?query#!state Use a headless browser that outputs an HTML snapshot on your web server rather than a client machine Allow search engine crawlers to access these URLs by escaping the state http://example.com/page?query&_escaped_fragment_=state Show the original URL to users in the search results
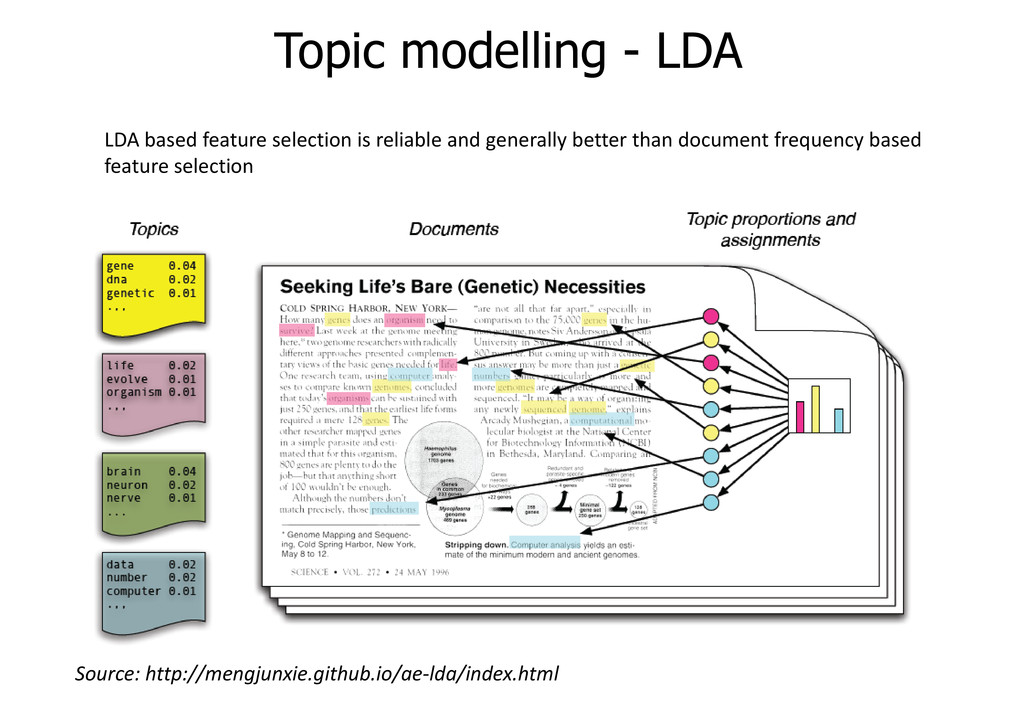
on Google.es Match keyword Search engine optimization - Wikipedia, the free encyclopedia en.wikipedia.org/wiki/Search_engine_optimization Search engine optimization (SEO) is the process of affecting the visibility of a website or a web page in a search engine's "natural" or un-paid ("organic") search SEO/BirdLife www.seo.org Se trata una federación de ámbito estatal de grupos territoriales, tiene como fines el estudio y la defensa de las aves y está integrada en la ONG mundial Co-ocurrence of keywords SEO <> search, search engine, website SEO <> aves, ONG TF*IDF (Term Frequency x Inverse Document Frequency) Topic modelling – Latent Dirichlet Allocation
and inverse document frequency With t the number of times that a term occurs in document d D the number of documents in the corpus denominator: number of documents where the term t appears
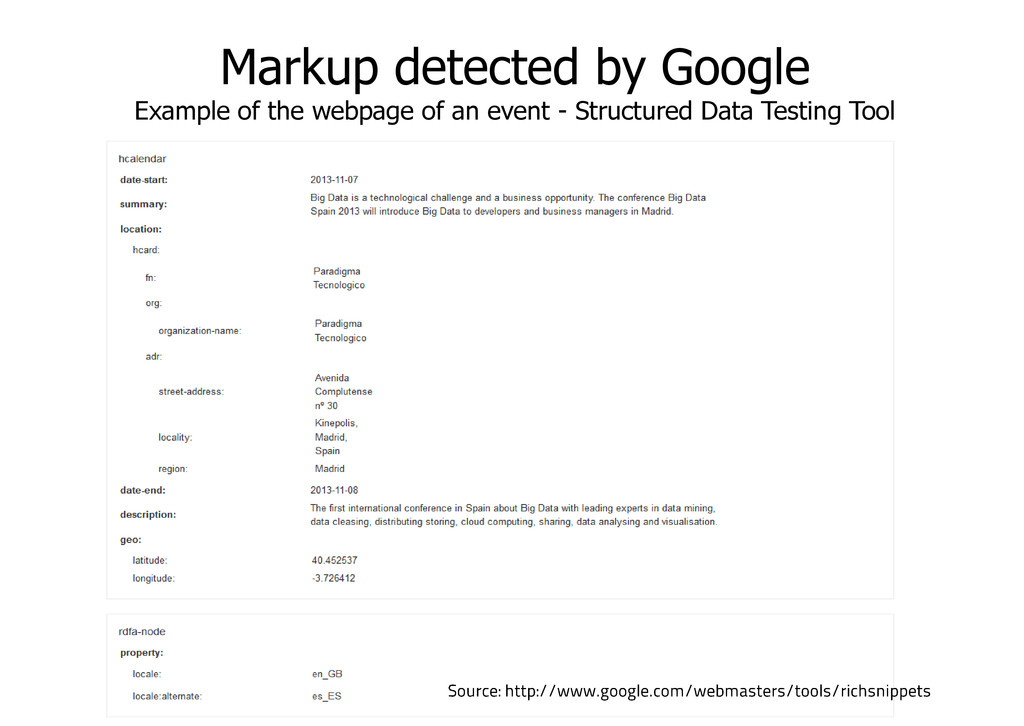
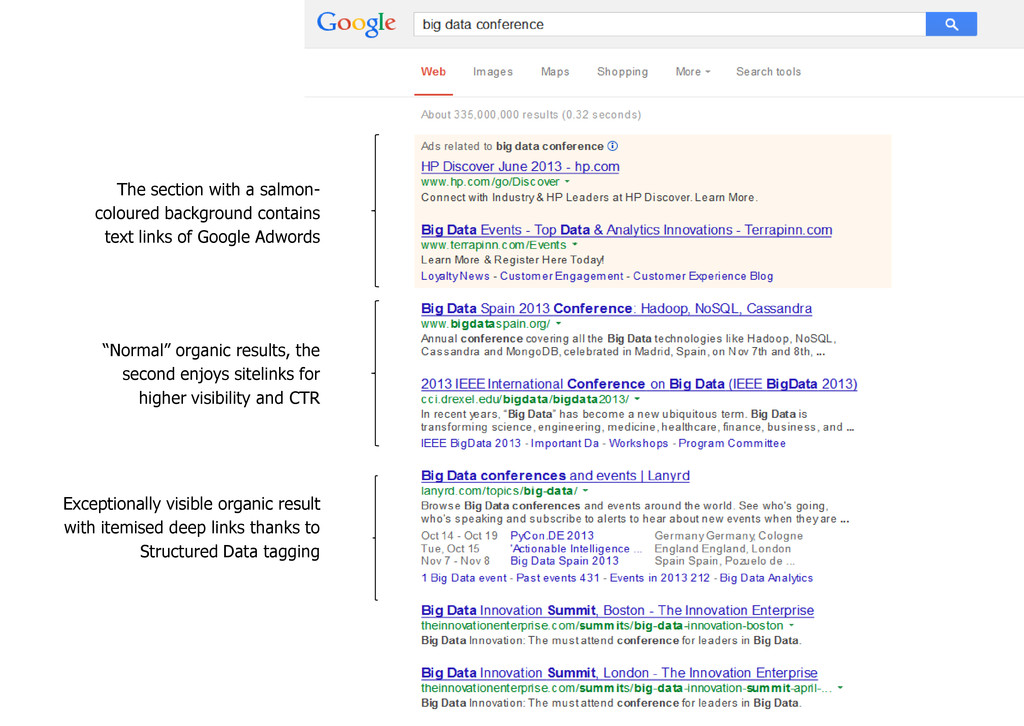
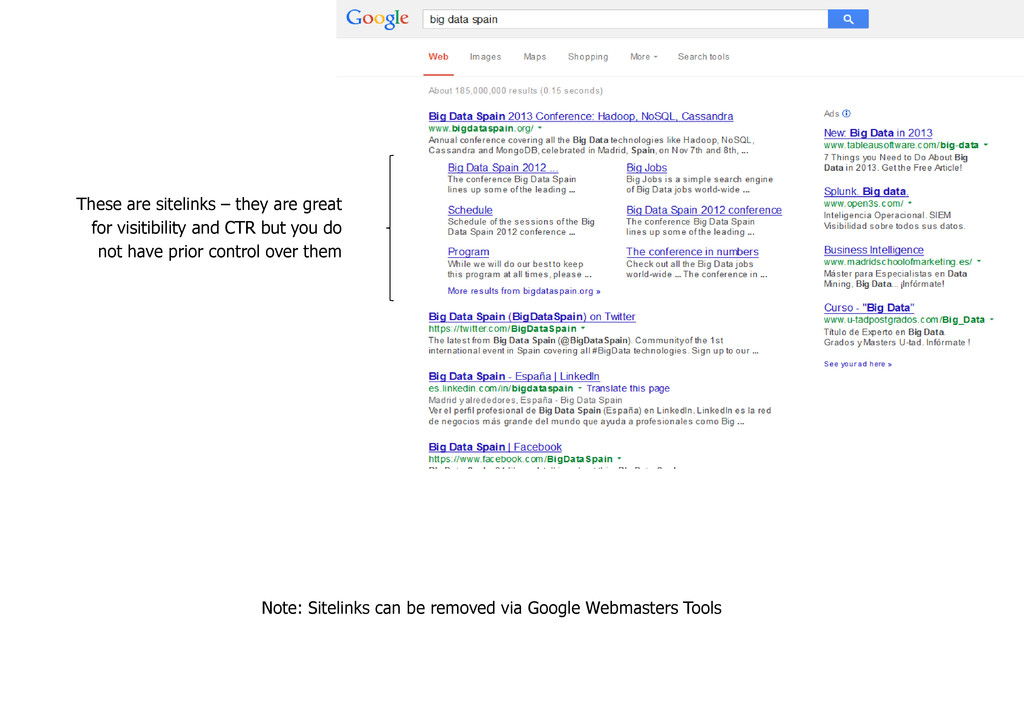
and CTR Exceptionally visible organic result with itemised deep links thanks to Structured Data tagging The section with a salmon- coloured background contains text links of Google Adwords
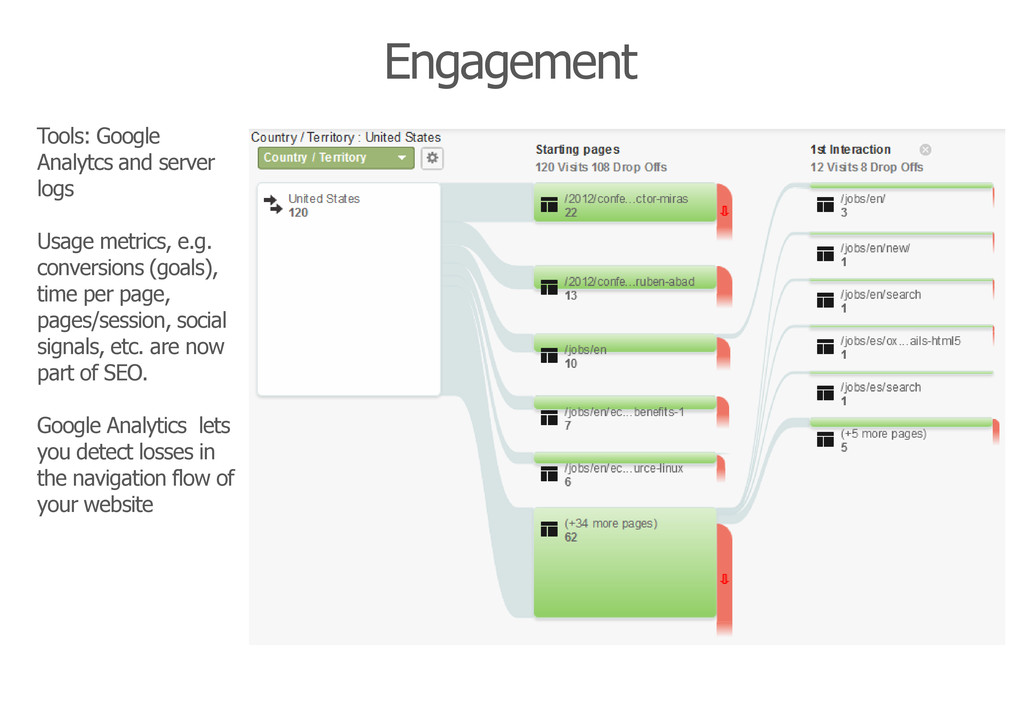
(goals), time per page, pages/session, social signals, etc. are now part of SEO. Google Analytics lets you detect losses in the navigation flow of your website Engagement
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}