it's a Highly available Container Orchestrator. Created at Google, originally named "Borg". Battle-tested at high scales, Google-level scale. it does "Container magic"...
applications, evolving around Containers and costainer orchestration. The core requirement is to have, at minimum, the following features: Scheduling Deployment Scaling Load balancing Health monitoring Resource allocating Redundancy
what's possible on Kubernetes using custom resources, to the point that you stop looking at container orchestration and look at this as a high-resilience environment. But that's a discussion for another time 😉
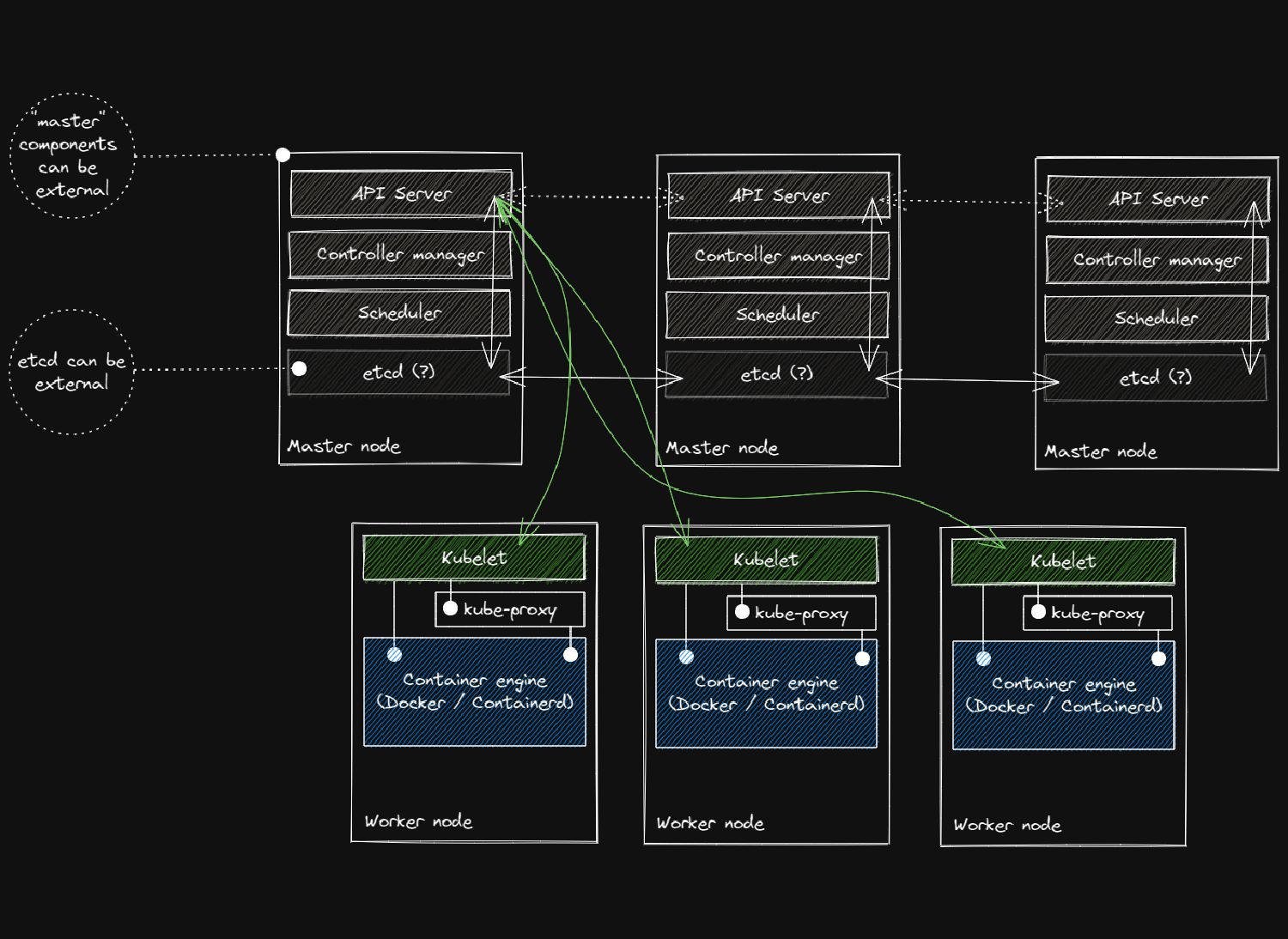
"control" side of Kubernetes: API Server Kube Controller manager Cloud controller manager Scheduler etcd The document database where all the Kubernetes data is stored. Written in Go, highly performant and RAM hungry. It's a "cluster" too on its own and as such needs consensus.
grouped depending on their capabilities. You can have CPU intensive nodes, or RAM intensive nodes. You can also have GPU-powered nodes for machine learning, or even Windows-powered nodes for Windows workloads. The main ingredient? The Kubelet.
brains of the operation. It coordinates all the efforts from all controllers. While controllers act, the API Server is the source of truth for them. We interact with the API server using kubectl. Kubectl is the tool that talks to the Kubernetes API to emit "orders/instructions."
Send instructions to Kubernetes using common HTTP verbs: GET to list POST to create PUT/PATCH to update DELETE to, well, delete Available for all platforms.
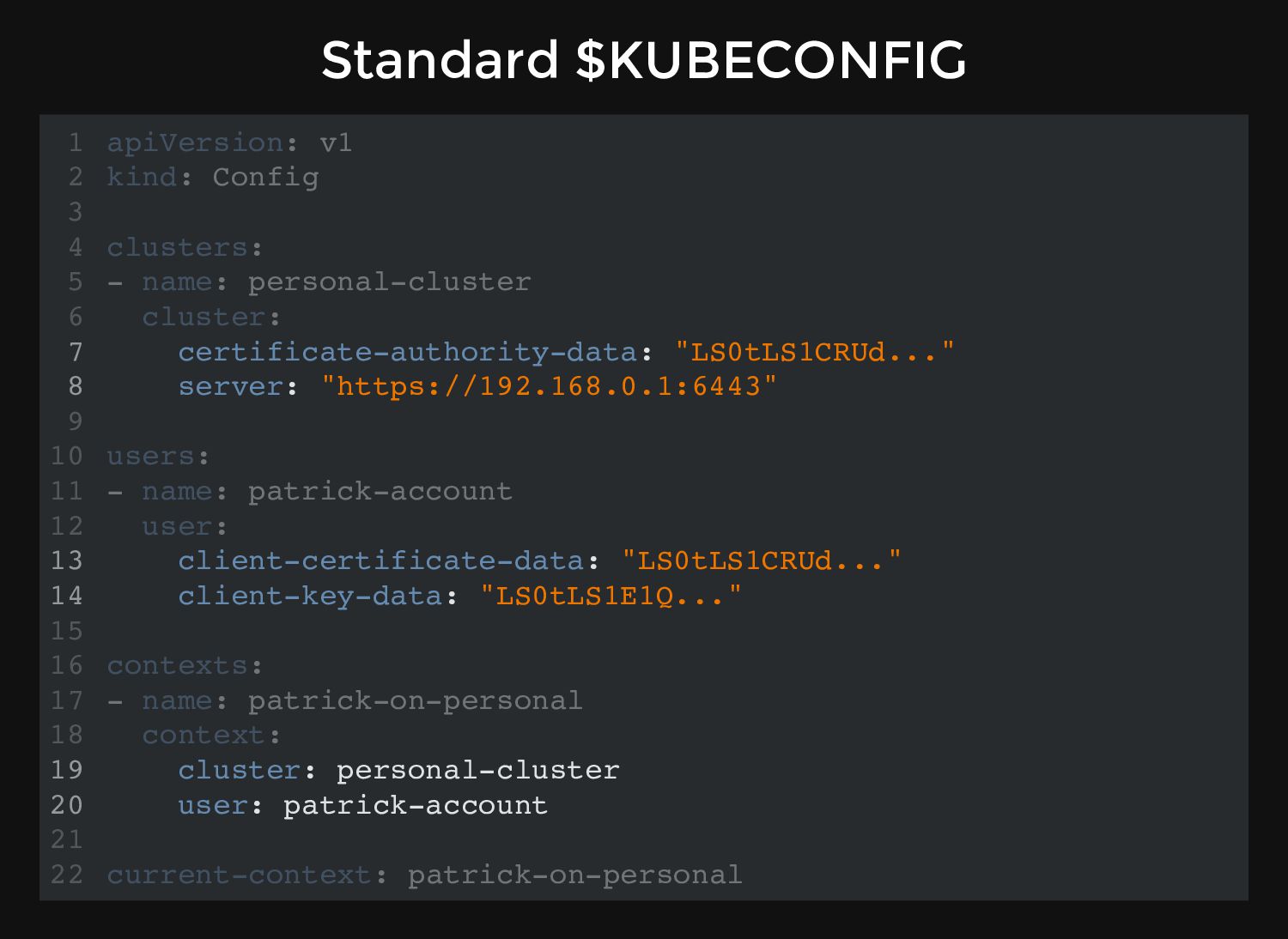
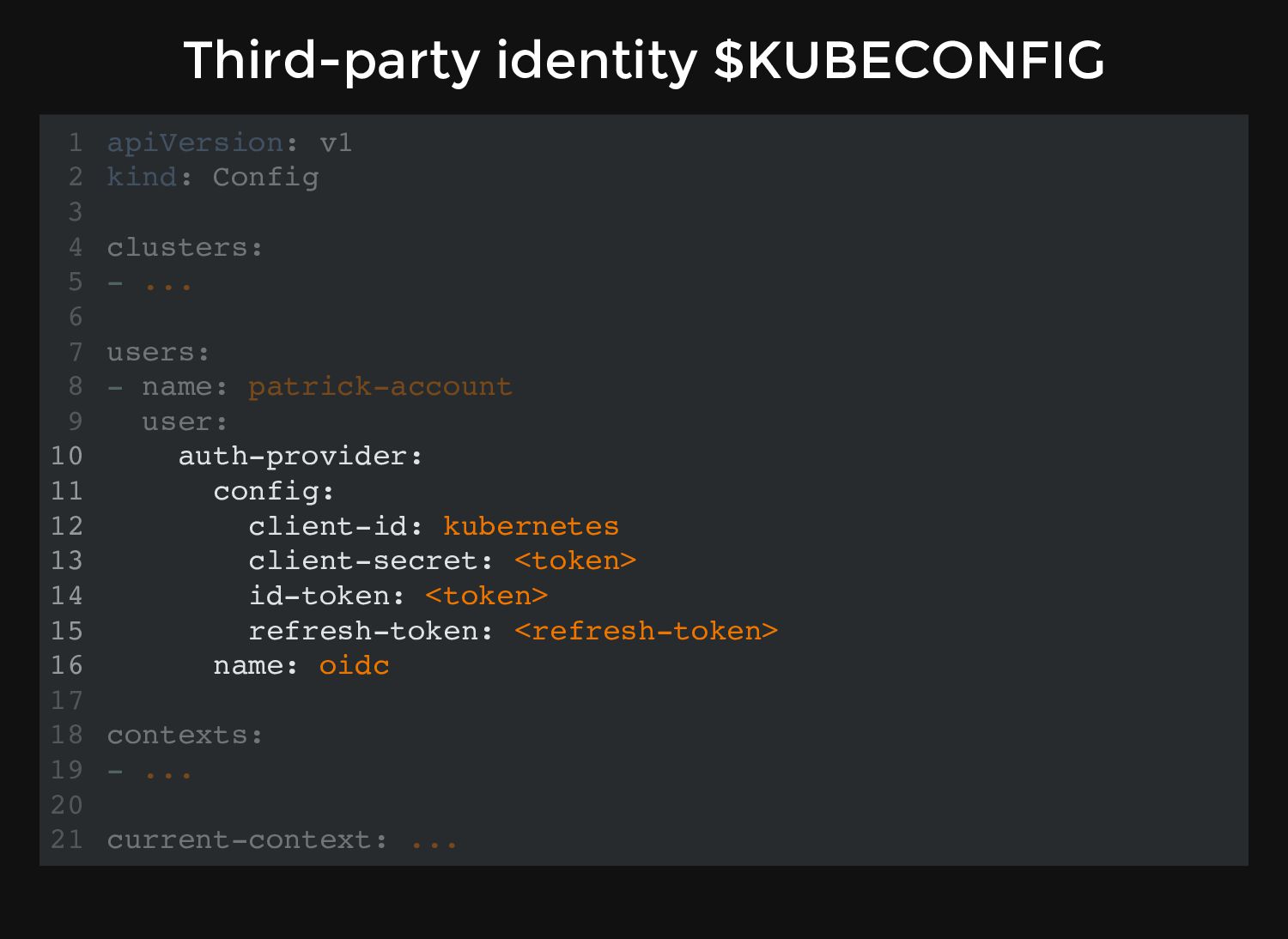
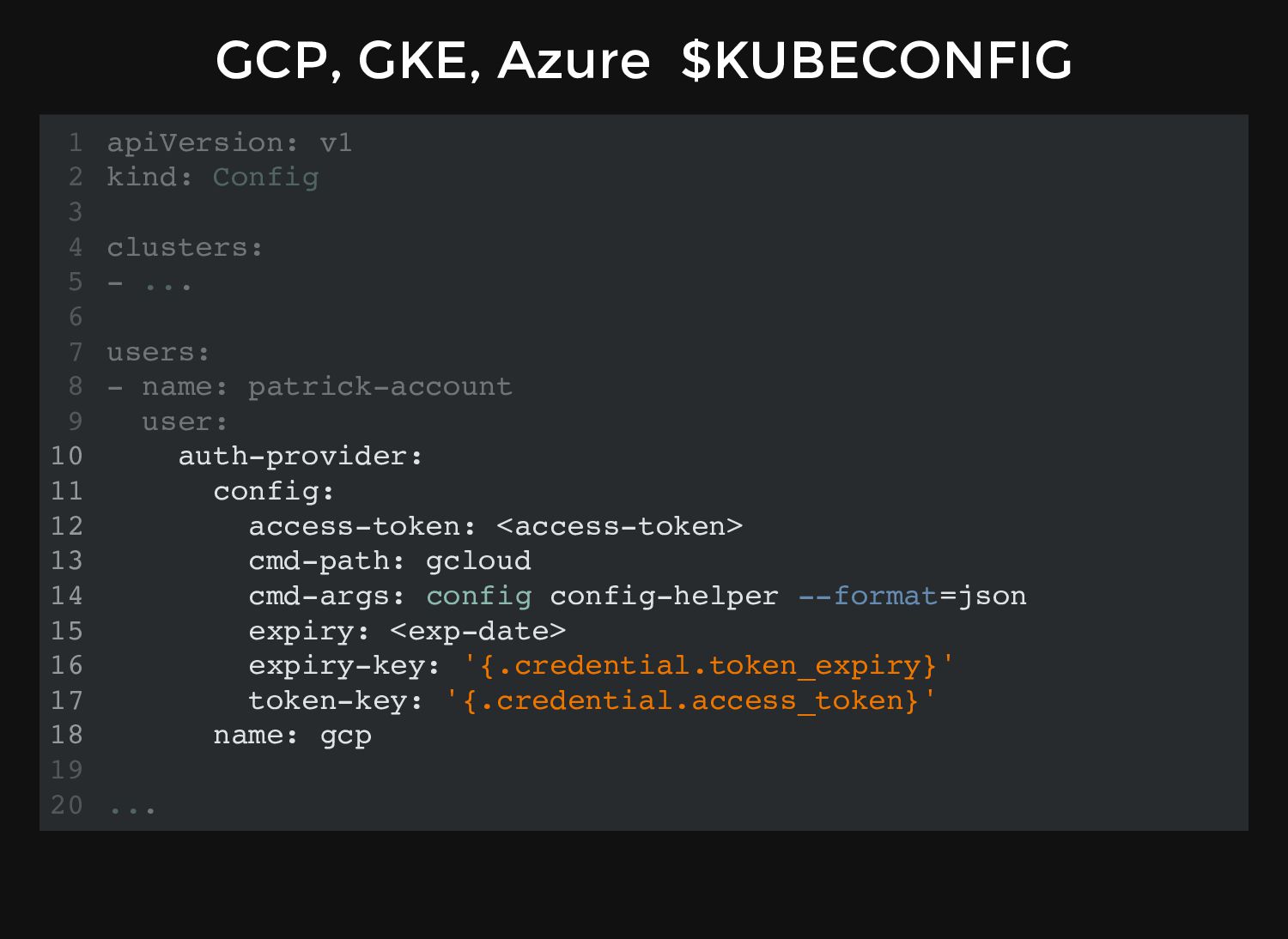
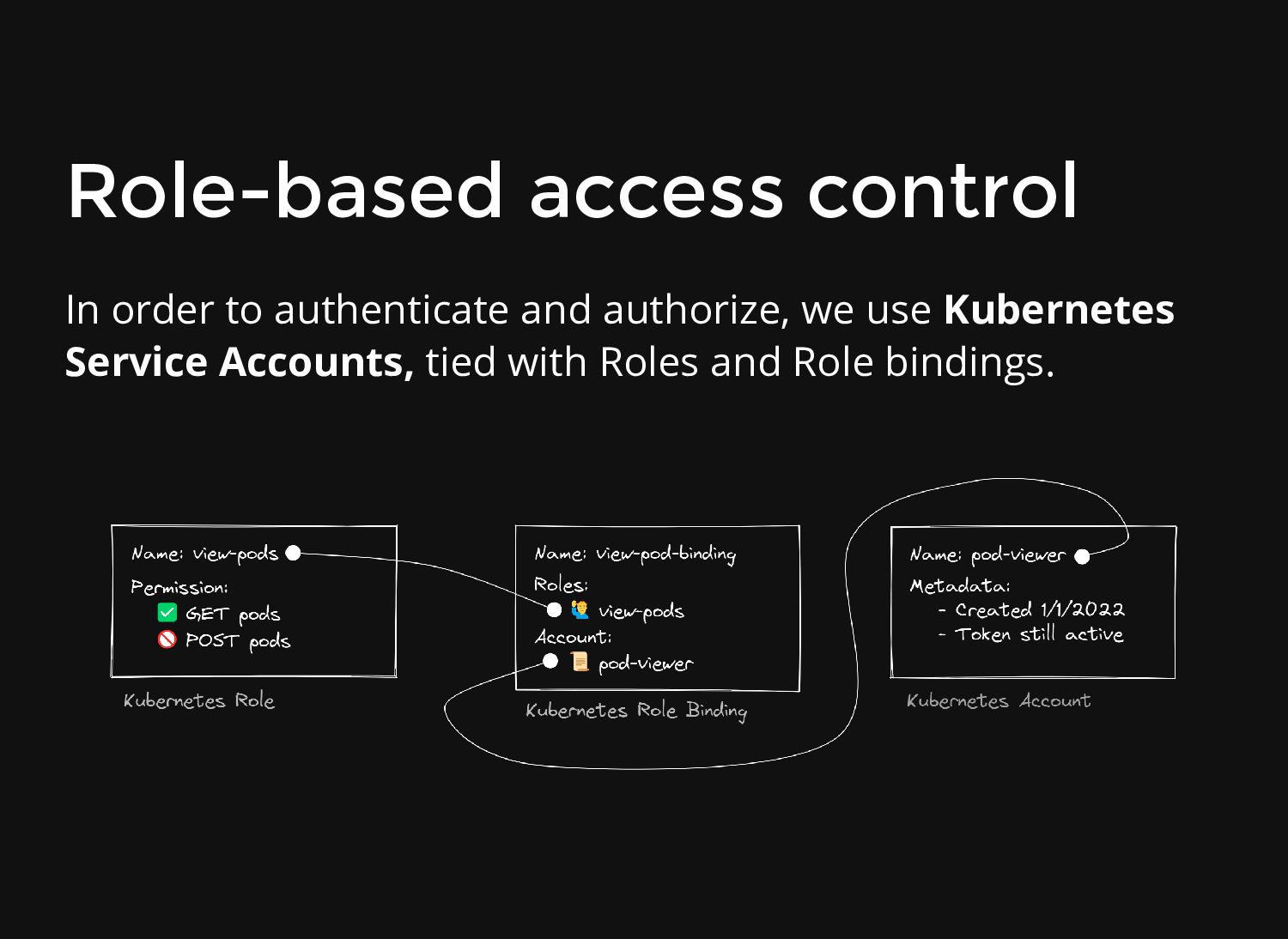
and what we can do, it needs our "credentials". Standard Kubernetes is very old-fashioned: uses Certificates and Tokens to authenticate users. Kubernetes-to-Kubernetes components also use TLS for communication.
Kubernetes pod can have multiple "containers" inside. These containers can have a specific behaviour: Initialization containers Normal containers Sidecars Pods are stateless unless they have a way to keep a state attached to them.
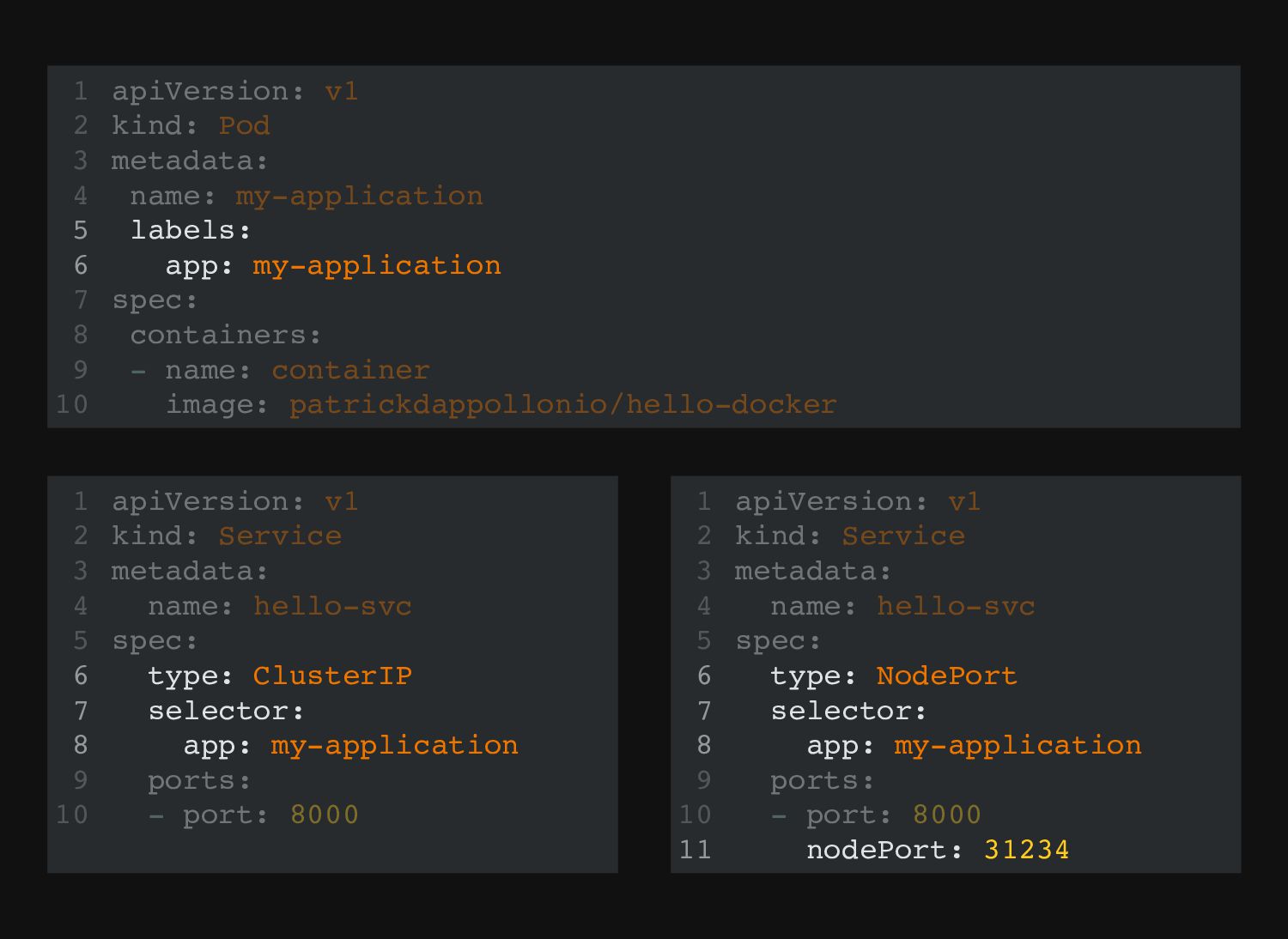
name: container image: patrickdappollonio/hello-docker 1 2 3 4 5 6 7 8 Example pod: this runs a single container inside the pod with the name "my-application"
name: container image: patrickdappollonio/hello-docker 1 2 3 4 5 6 7 8 apiVersion: v1 kind: Pod metadata: name: my-application spec: containers: - name: container image: patrickdappollonio/hello-docker 1 2 3 4 5 6 7 8 Example pod: this runs a single container inside the pod with the name "my-application"
network" (or software-defined network, made with either "iptables" or "ipvs" or third-party software). This network is based on conventions: The container name becomes the hostname, and it's exposed to all containers in the pod Routing between these containers is "exclusive" and it can't be disrupted* However, one of the containers in a pod can "own" the network and force all traffic to go through it. (topic for another talk)
only exists within the network space in itself -- unless other solutions like hostPort are used. To expose, we need to register it to the cluster-level now using a Kubernetes Service. Without going into detail, creating a Service for a pod means you have to "tie" the Pod to a Service using Labels. The Service then will give you a unique FQDN: ${name}.${namespace}.svc.cluster.local
to other parts of the Cluster, whether they're in the same namespace or a different one. There's two useable versions of Services: ClusterIP NodePort And other two used for custom behaviour: ExternalName and LoadBalancer.
the cluster, instead to just the Pod network. Very useful to prevent exposing "more that's necessary". NodePort A kind of Service that should be used for debugging or troubleshooting. Allows to "catch" a random port between 32000 and 32767 (by default, can be changed) and exposes the app on all nodes through that port. Kinds of Services
mixture between ClusterIP behaviour (exposed to the cluster) and NodePort (exposed in a random port). This uses the "Cloud Controller Manager" to provision an actual Load Balancer (either appliance or VM-based) and point the "members" of the Load Balancer either to the NodePort service or directly to the Pod. It's a local object to keep track of the "members" of the Service and update the Cloud LB accordingly. Kinds of Services
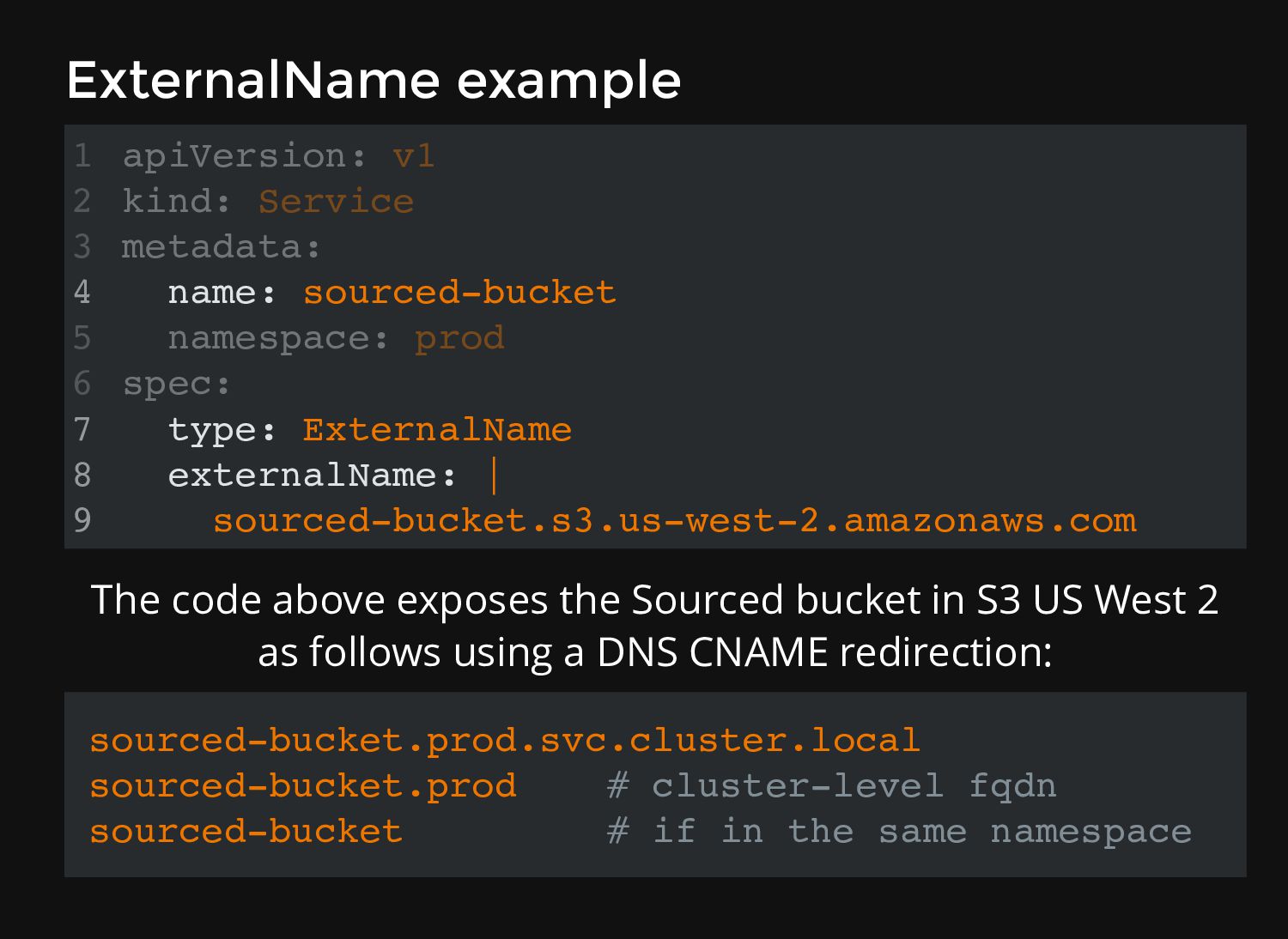
other pods of the container Services expose these pods as Services to the entire cluster What if the Application isn't running from inside the cluster, but we want the fancy FQDN for it and/or make it look it's internal to the cluster? ExternalName to the rescue! Kinds of Services
v1 1 kind: Service 2 metadata: 3 4 namespace: prod 5 spec: 6 7 8 9 The code above exposes the Sourced bucket in S3 US West 2 as follows using a DNS CNAME redirection: sourced-bucket.prod.svc.cluster.local sourced-bucket.prod # cluster-level fqdn sourced-bucket # if in the same namespace
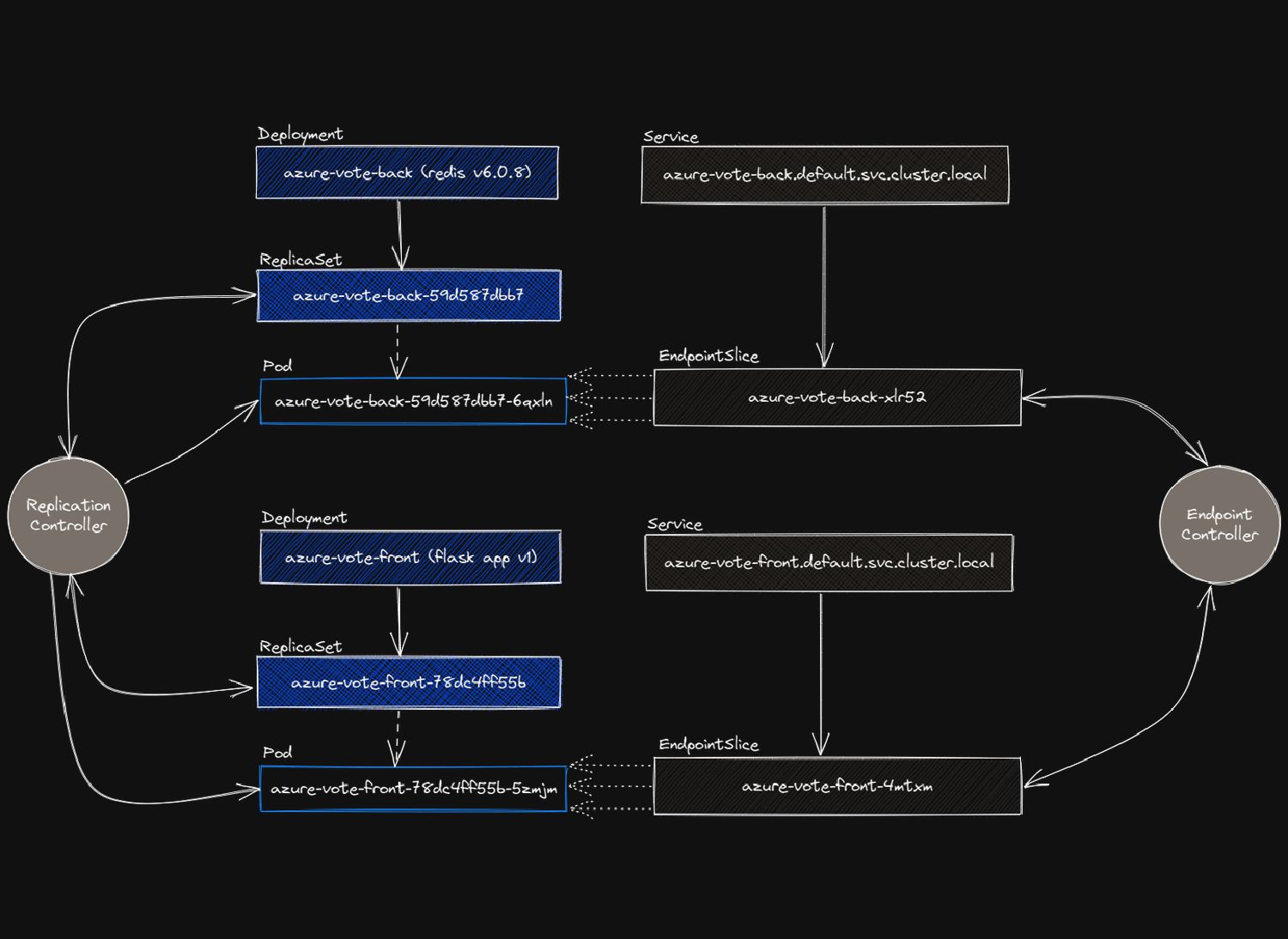
is not good for our HA: if it goes down, our application goes dow. For all stateless applications, Kubernetes offers: DEPLOYMENTS The fight for not having a single Pod
app, all running at the same time. With a Service, you can round-robin load balance all of them through kube-proxy Allows you to perform rollout releases with zero downtime (shoutout to the zero-downtime article again!) Allows a basic "template" of a Pod
a pod might not put the pod back in the same node where it originally was. Multiple reasons might require you do either get predictable names or remember where your pods are deployed. StatefulSets are the solution. DaemonSet If you have 8 nodes, and you launch 8 containers, chances are, they will all be randomly distributed through your 8 nodes, but you might have nodes with zero pods and nodes with more than one. DaemonSets allow you to evenly distribute one-pod- per-node.
applications (running, say, in VMs) to Kubernetes and the cloud. It requires less cloud-readiness to launch an application as StatefulSet than a Deployment. There's several features in place to help Pods maintain their "state" (except in-memory state) as much as possible. Use this to your customer's advantage!
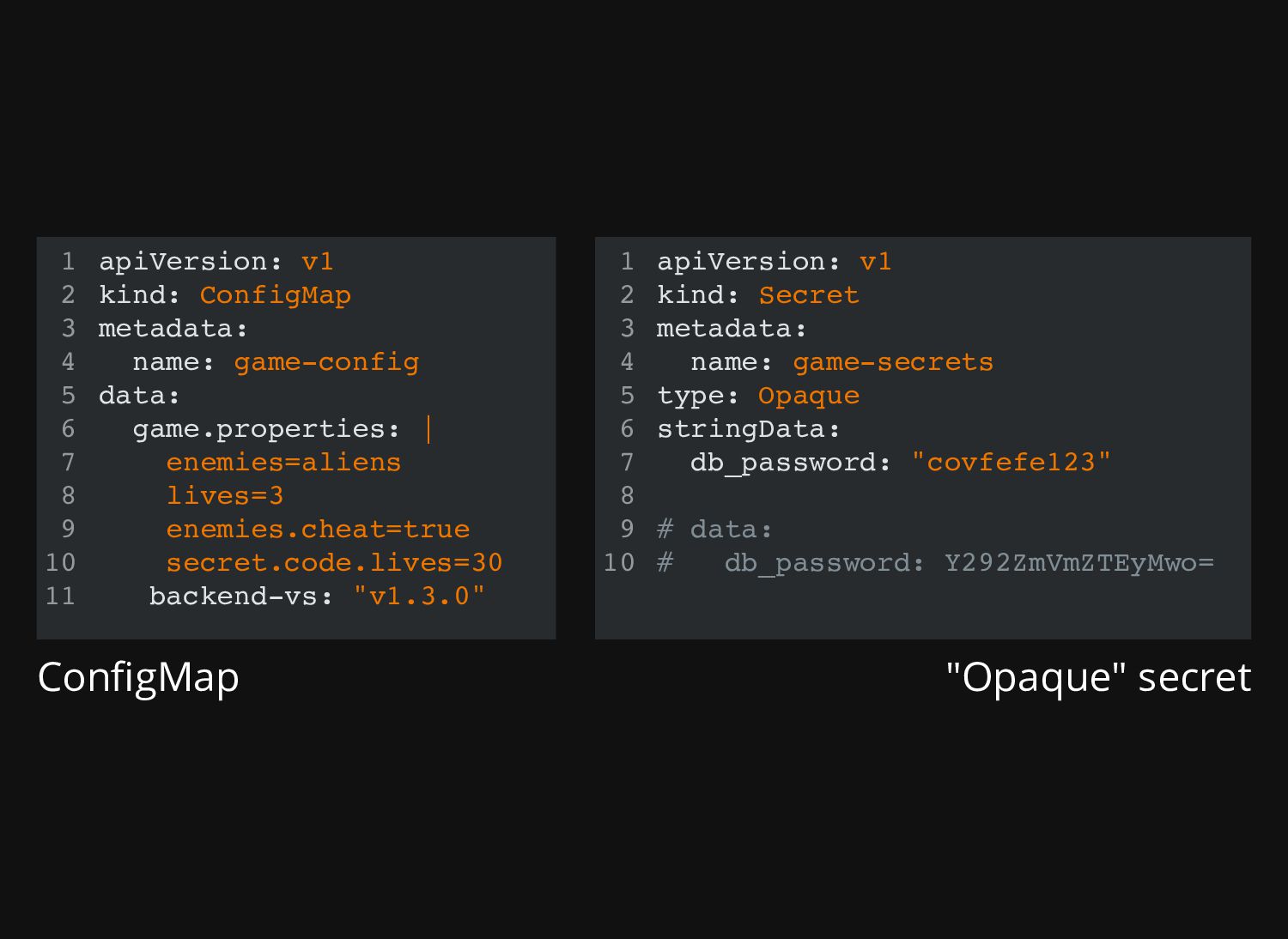
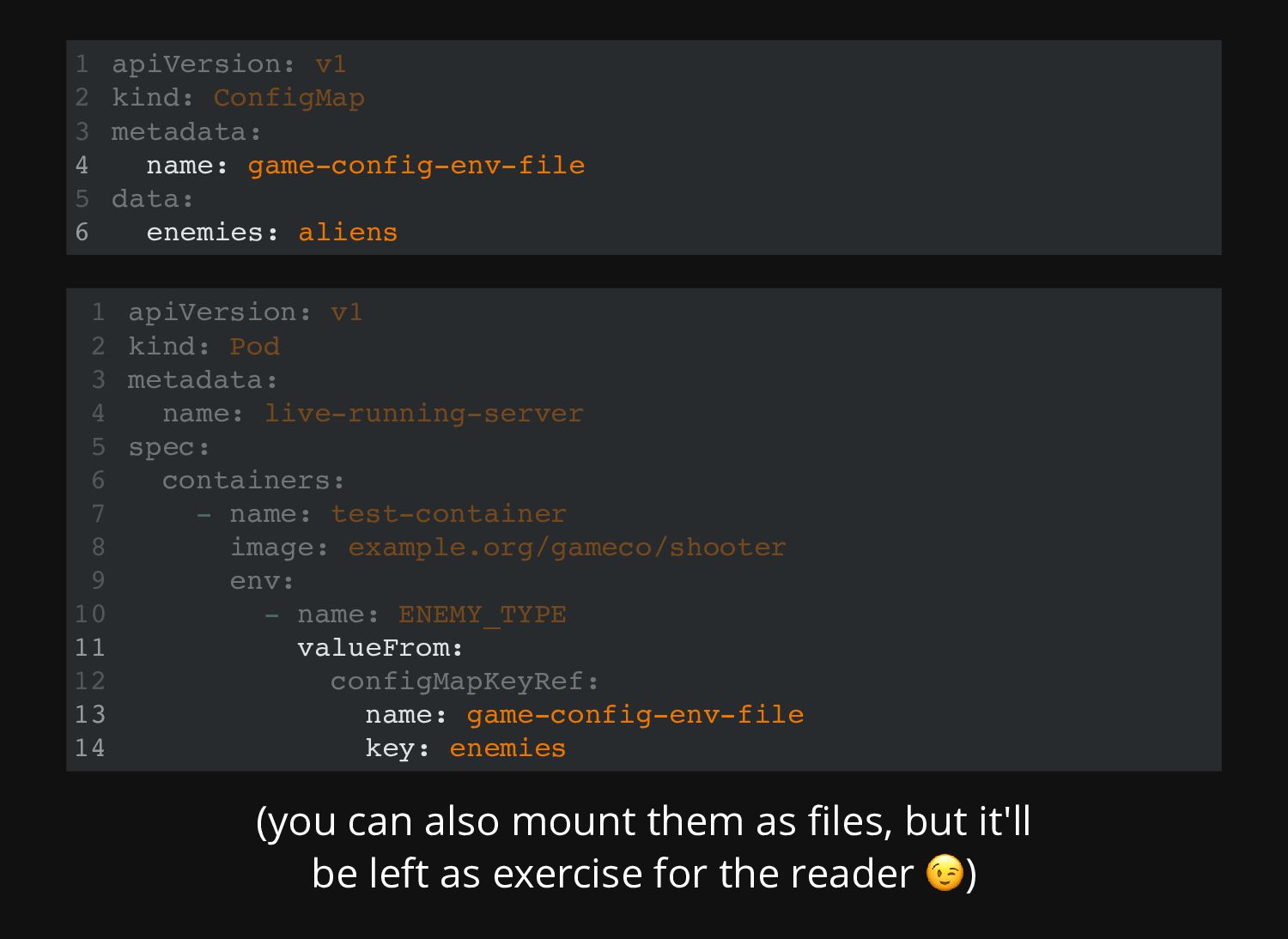
same way: Both allow you to mount their data either as "files" (volumes) or environment variables (whenever possible) Both hold non binary data -- although binary data can be converted to string via base64 The main difference here is: Secrets are encrypted... ... but ConfigMaps are not *
by Controllers (apps that can extend the Kubernetes functionality). However, adoption has been lacking, besides Kubernetes' own standards. The goal is that secrets could be handled differently depending on their type.
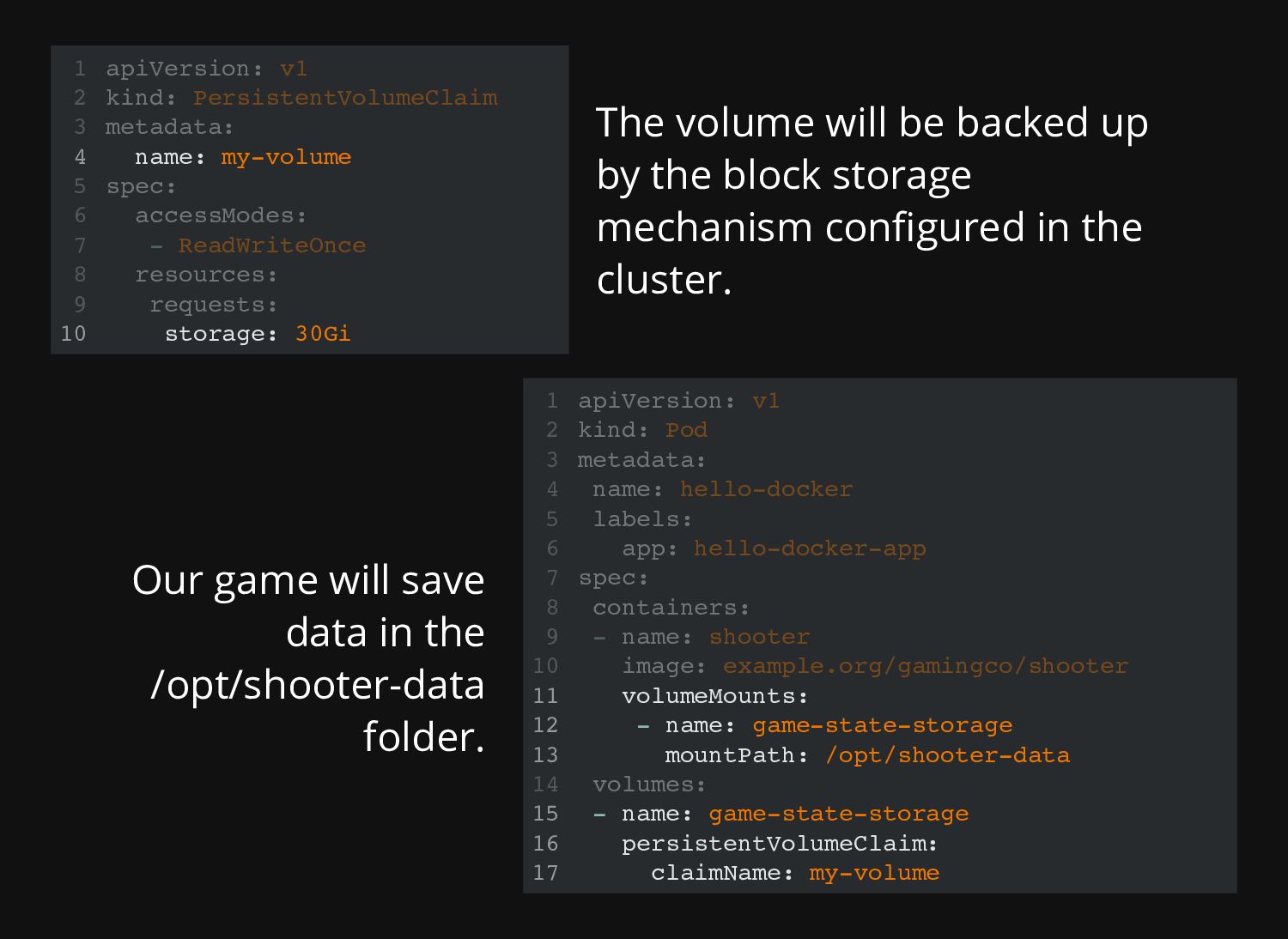
storage" from Kubernetes. Can be used to store data, logs, database backend information, etc. Think about it as any folder backed up by a storage engine somewhere.
Persistent Volumes (PVs) are a traditional way to mount a local-or-network classic volume for block storage. You can also host "cloud" block storage with this if there's a FileSystem implementation for it (like FUSE). In plain English: imagine the cluster is in your house, and you want to mount your USB volume as storage for your cluster. You'll configure it through a Persistent Volume.
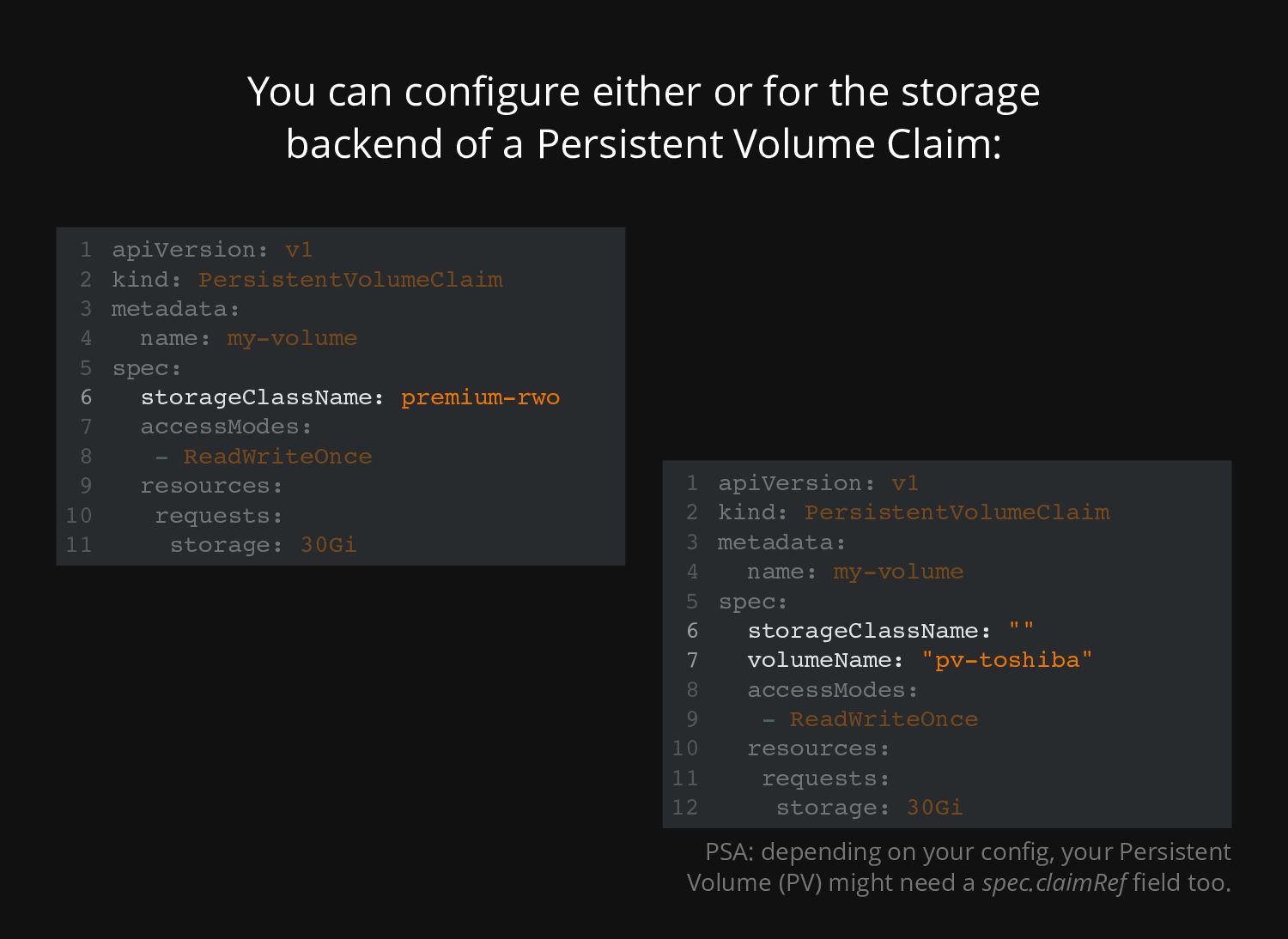
of Storage Classes (SC) mainly due to their cloud- ready behaviour. In other words, can I mount my good-old Toshiba external drive to 3 computers at once with the same USB? Probably no.
Volumes (PV). They allow to sell bulk block (or sometimes non-block) storage through Kubernetes. Often Persistent Volumes double-check if the amount of storage you're requesting is available in the destination. Storage Classes assume that since it's cloud based the "capacity" is infinite (as long as you keep paying 😉) Finally, it's quite common for PvCs bound to an SC to "expand" (contrary to my Toshiba that's still at 2 TB) Disclaimer: some SCs might still check for available capacity against "quotas"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}