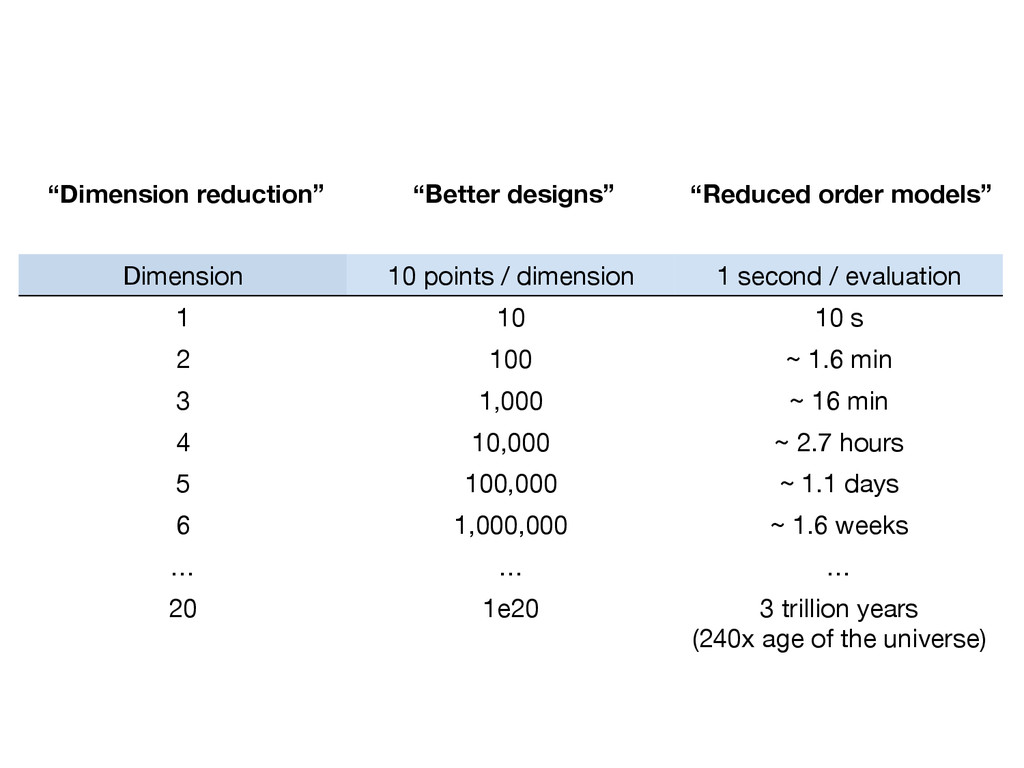
(MIT, AeroAstro) David Gleich (Purdue, CS) ACTIVE SUBSPACES Emerging ideas for dimension reduction in approximation, integration, and optimization DISCLAIMER: These slides are meant to complement the oral presentation. Use out of context at your own risk. This material is based upon work supported by the U.S. Department of Energy Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics program under Award Number DE-SC-0011077.
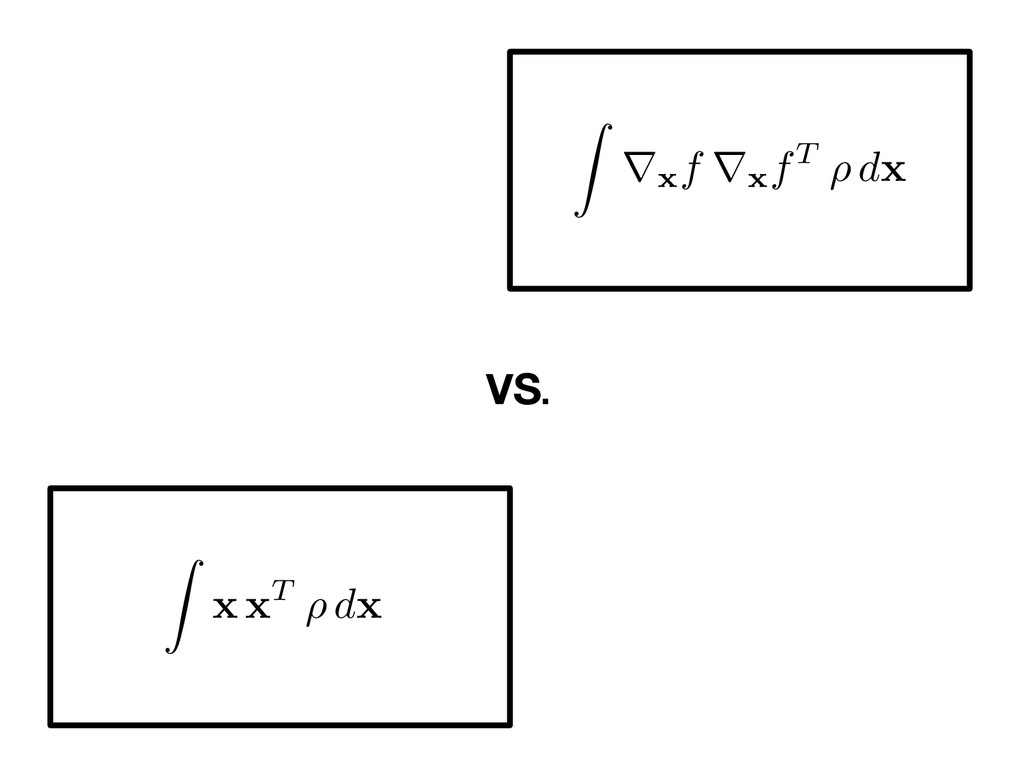
vector, The average outer product of the gradient and its eigendecomposition, Partition the eigendecomposition, Rotate and separate the coordinates, ⇤ = ⇤1 ⇤2 , W = ⇥ W 1 W 2 ⇤ , W 1 2 Rm⇥n x = W W T x = W 1W T 1 x + W 2W T 2 x = W 1y + W 2z active variables inactive variables C = Z (r x f)(r x f)T ⇢ d x = W ⇤W T f = f( x ), x 2 Rm, rf( x ) 2 Rm, ⇢ : Rm ! R +
f( xj) r x fj = r x f( xj) Approximate with Monte Carlo Equivalent to SVD of samples of the gradient. Called an active subspace method in T. Russi’s 2010 Ph.D. thesis, Uncertainty Quantification with Experimental Data in Complex System Models xj ⇠ ⇢ C ⇡ 1 N N X j=1 r x fj r x fT j = ˆ W ˆ ⇤ ˆ W T 1 p N ⇥ r x f1 · · · r x fN ⇤ = ˆ W p ˆ ⇤ ˆ V T
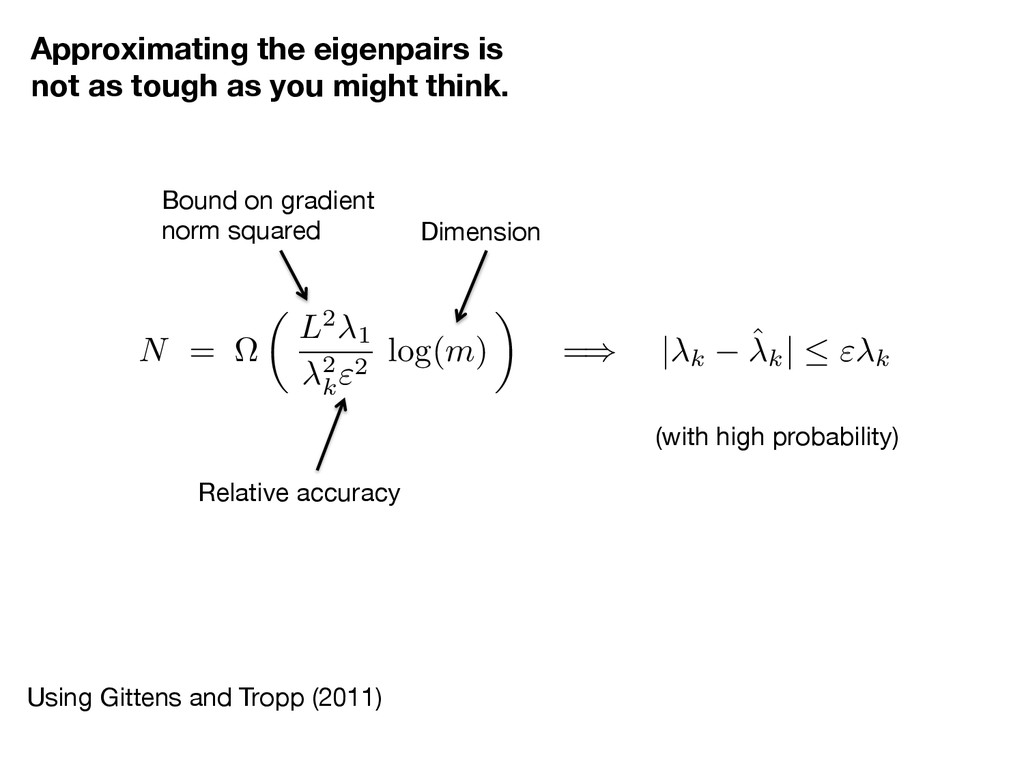
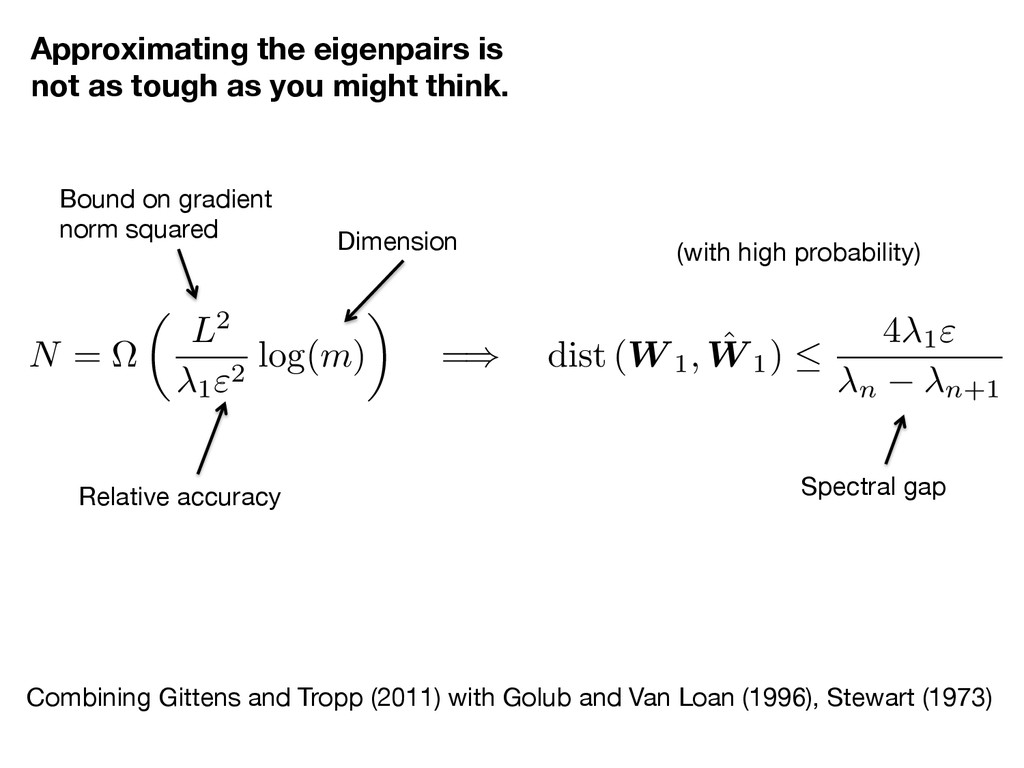
as tough as you might think. Bound on gradient norm squared Relative accuracy Dimension (with high probability) N = ⌦ ✓ L2 1 2 k "2 log( m ) ◆ = ) | k ˆk | " k
think. Combining Gittens and Tropp (2011) with Golub and Van Loan (1996), Stewart (1973) Bound on gradient norm squared Relative accuracy Dimension (with high probability) Spectral gap N = ⌦ ✓ L2 1"2 log( m ) ◆ = ) dist ( W 1, ˆ W 1) 4 1" n n+1
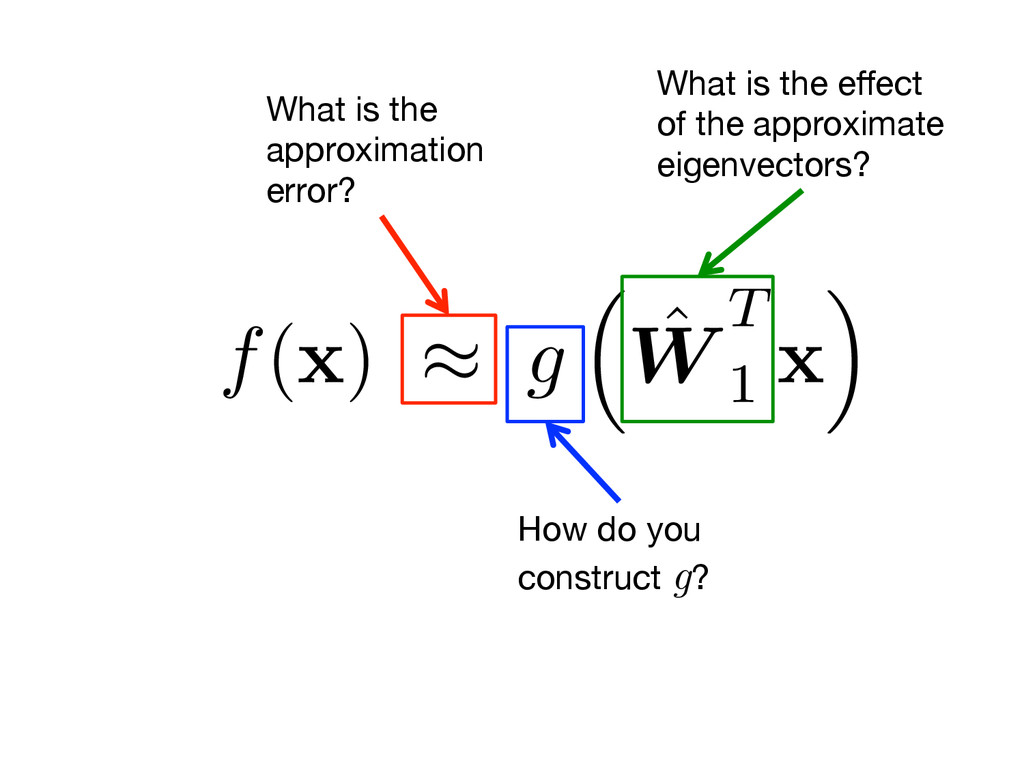
r x fN ⇤ ⇡ ˆ W 1 q ˆ ⇤1 ˆ V T 1 Low-rank approximation of the collection of gradients: Let’s be abundantly clear about the problem we are trying to solve. Low-dimensional linear approximation of the gradient: rf( x ) ⇡ ˆ W 1 a ( x ) f( x ) ⇡ g ⇣ ˆ W T 1 x ⌘ Approximate a function of many variables by a function of a few linear combinations of the variables: ✔ ✖ ✖
THEOREM: g( y ) = Z f(W 1y + W 2z ) ⇢( z | y ) d z , f( x ) ⇡ g(W T 1 x ) ˆ g(y) = 1 N N X i=1 f(W 1y + W 2zi), zi ⇠ ⇢(z|y) EXPLOIT active subspaces for response surfaces with conditional averaging. ✓Z ⇣ f( x ) g(W T 1 x ) ⌘2 ⇢ d x ◆1 2 CP ( n+1 + · · · + m)1 2 ✓Z ⇣ f( x ) ˆ g(W T 1 x ) ⌘2 ⇢ d x ◆1 2 CP ⇣ 1 + N 1 2 ⌘ ( n+1 + · · · + m)1 2
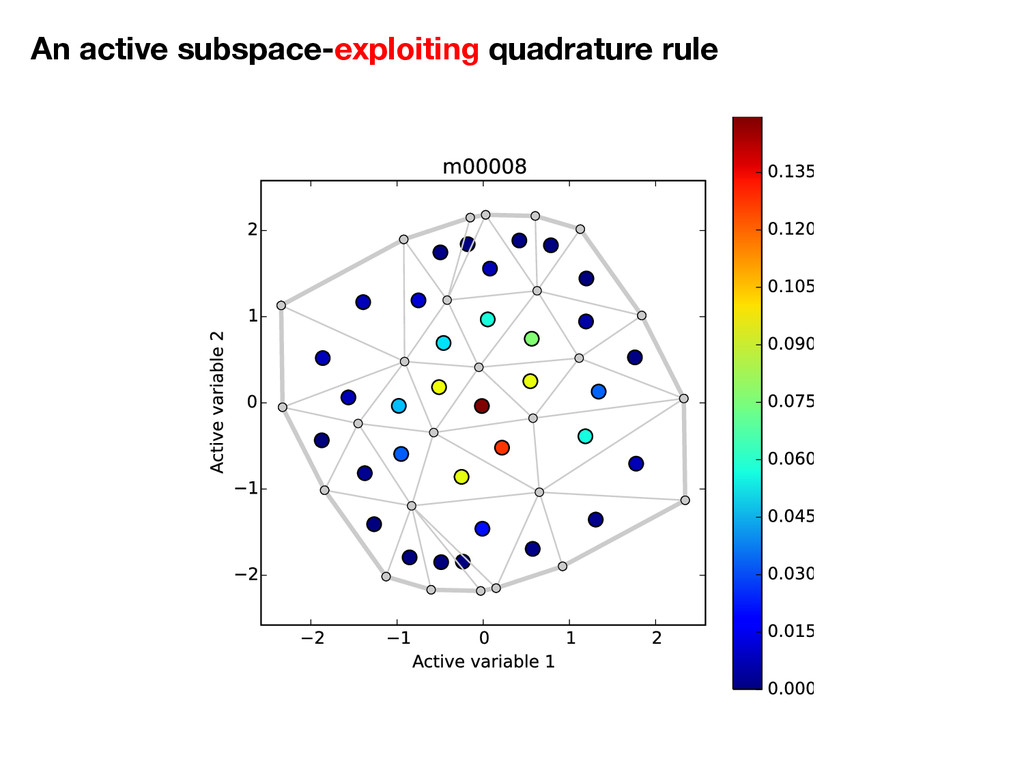
f(W 1y + W 2z ) ⇢( z | y ) d z | {z } = g(y) ⇢( y ) d y = Z g( y ) ⇢( y ) d y ⇡ N X i=1 g( yi) wi ⇡ N X i=1 ˆ g( yi) wi Integrate in active variables. Quadrature rule in active variables. Monte Carlo in inactive variables.
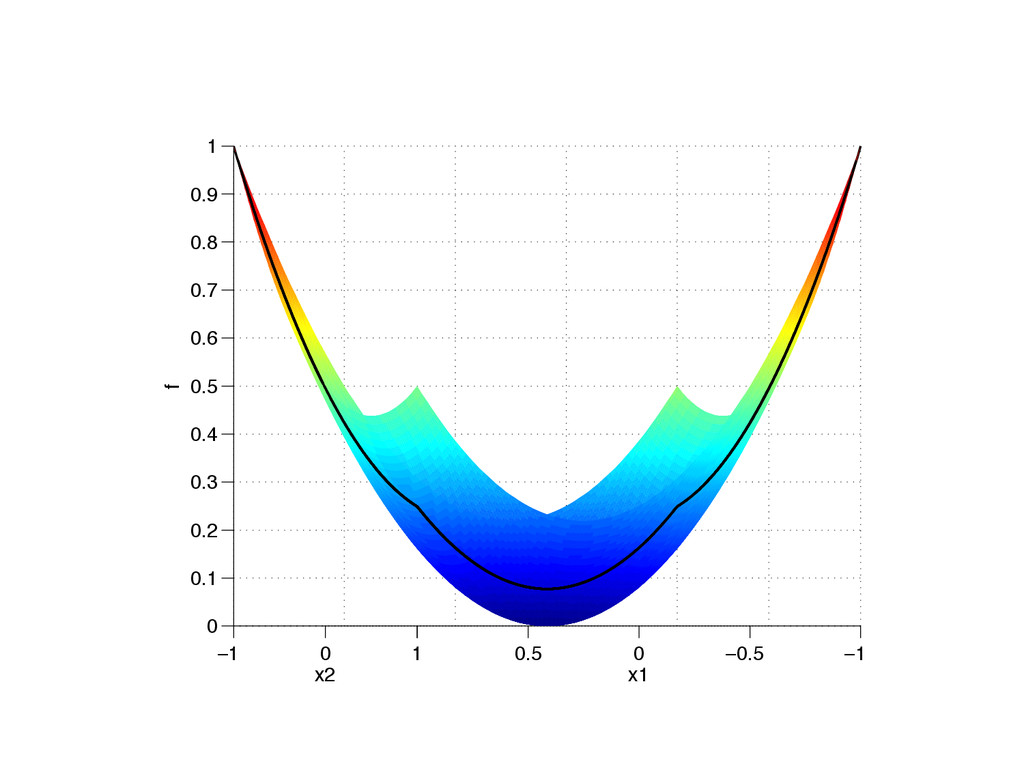
Z rf rfT ⇢ d x 1 N N X i=1 rfi rfT i GOAL Make intractable high-dimensional parameter studies tractable by discovering and exploiting low-dimensional structure. First n < m eigenvectors of f( x ) ⇡ g(W T 1 x ) Z f( x )⇢ d x minimize x f( x ) APPROXIMATION INTEGRATION OPTIMIZATION
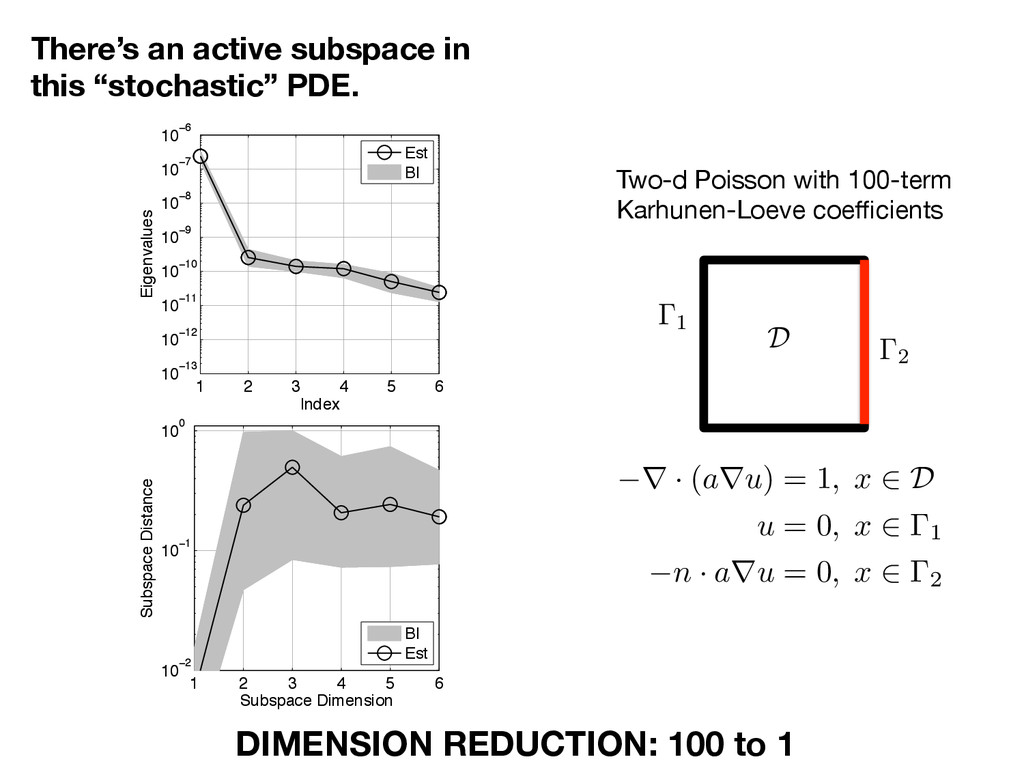
with 100-term Karhunen-Loeve coefficients 1 2 D r · ( a r u ) = 1 , x 2 D u = 0 , x 2 1 n · a r u = 0 , x 2 2 DIMENSION REDUCTION: 100 to 1 1 2 3 4 5 6 10−13 10−12 10−11 10−10 10−9 10−8 10−7 10−6 Index Eigenvalues Est BI 1 2 3 4 5 6 10−13 10−12 10−11 10−10 10−9 10−8 10−7 10−6 Index Eigenvalues 1 2 3 4 5 6 10−2 10−1 100 Subspace Dimension Subspace Distance BI Est 1 2 3 4 5 6 10−2 10−1 100 Subspace Dimension Subspace Distance
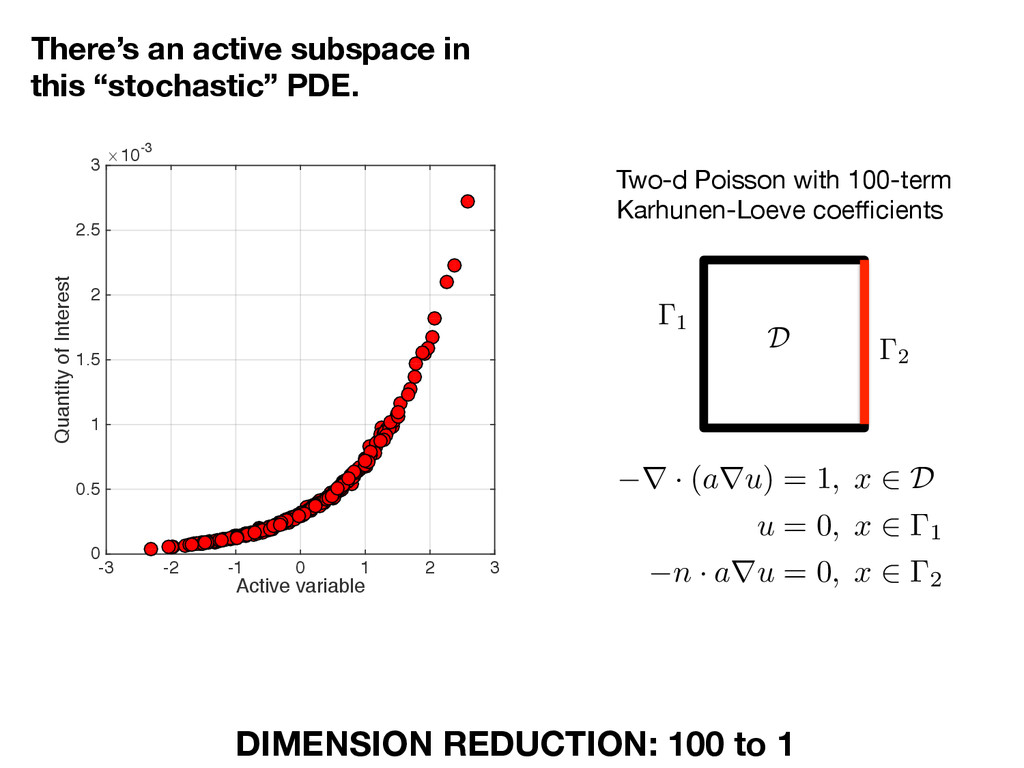
variable -3 -2 -1 0 1 2 3 Quantity of Interest #10-3 0 0.5 1 1.5 2 2.5 3 r · ( a r u ) = 1 , x 2 D u = 0 , x 2 1 n · a r u = 0 , x 2 2 There’s an active subspace in this “stochastic” PDE. DIMENSION REDUCTION: 100 to 1
many gradient samples do I need? • What if I don’t have gradients? • What kinds of models does this work on? • What about multiple quantities of interest? • How new is all this? Paul Constantine Colorado School of Mines activesubspaces.org @DrPaulynomial
{kind=link}
{kind=link}
![[ Show them that cool animation! ]](https://files.speakerdeck.com/presentations/f535d579d6d74c5c97fdf7c2e7d4a3b7/slide_2.jpg){kind=link}
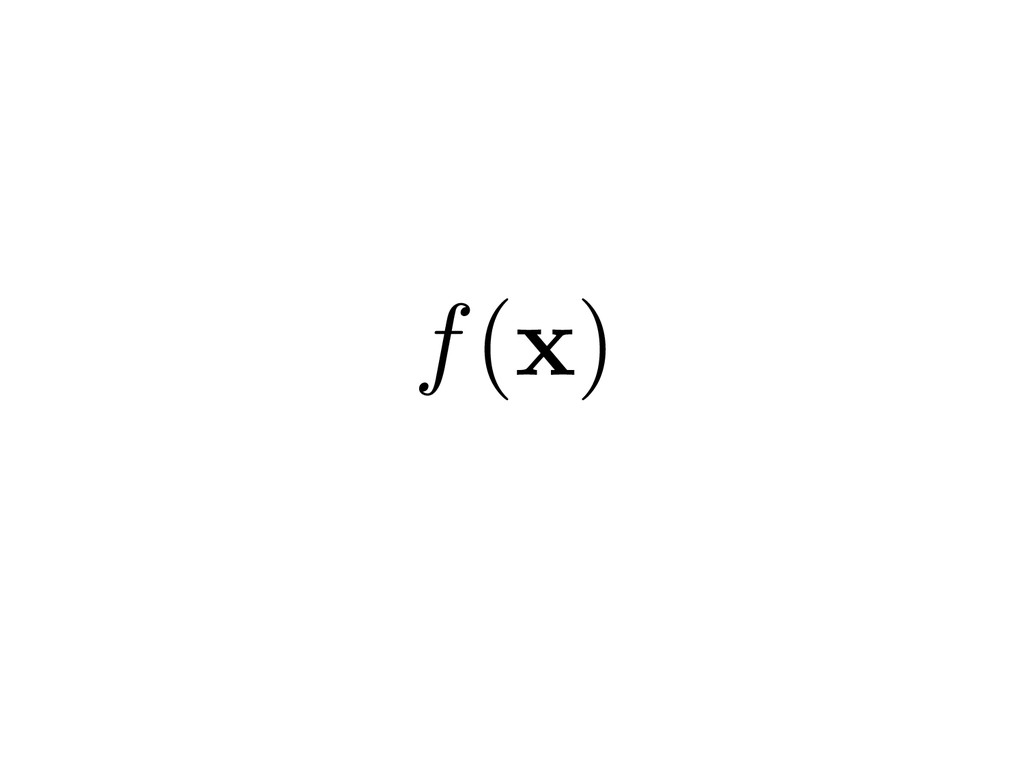{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
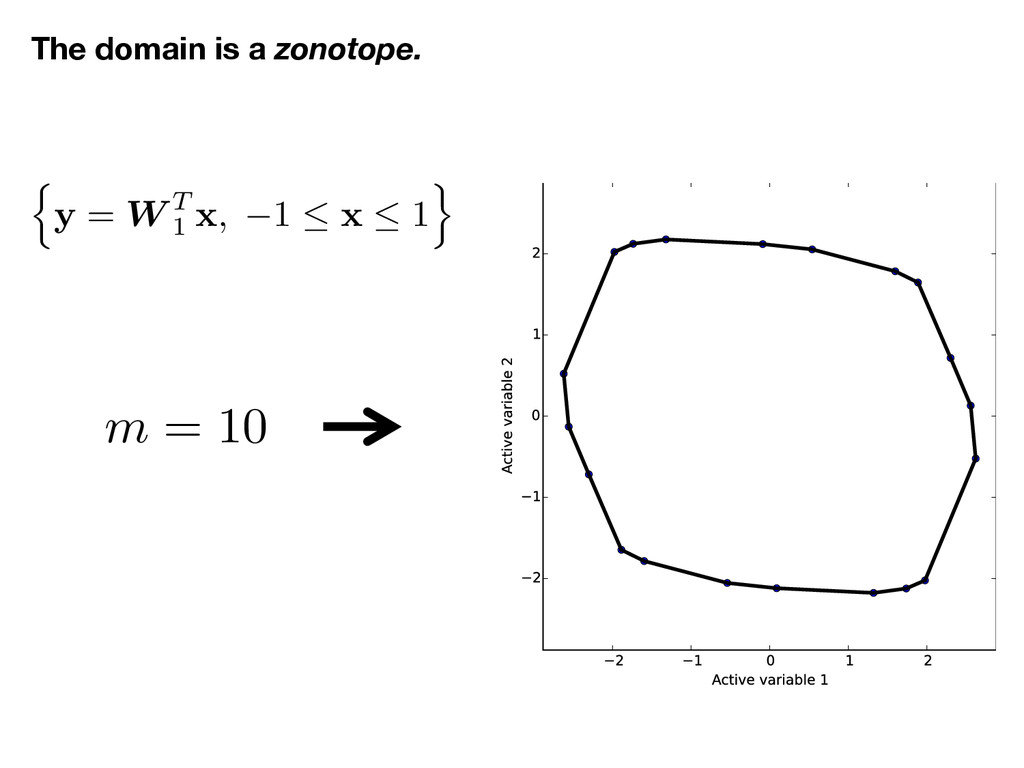
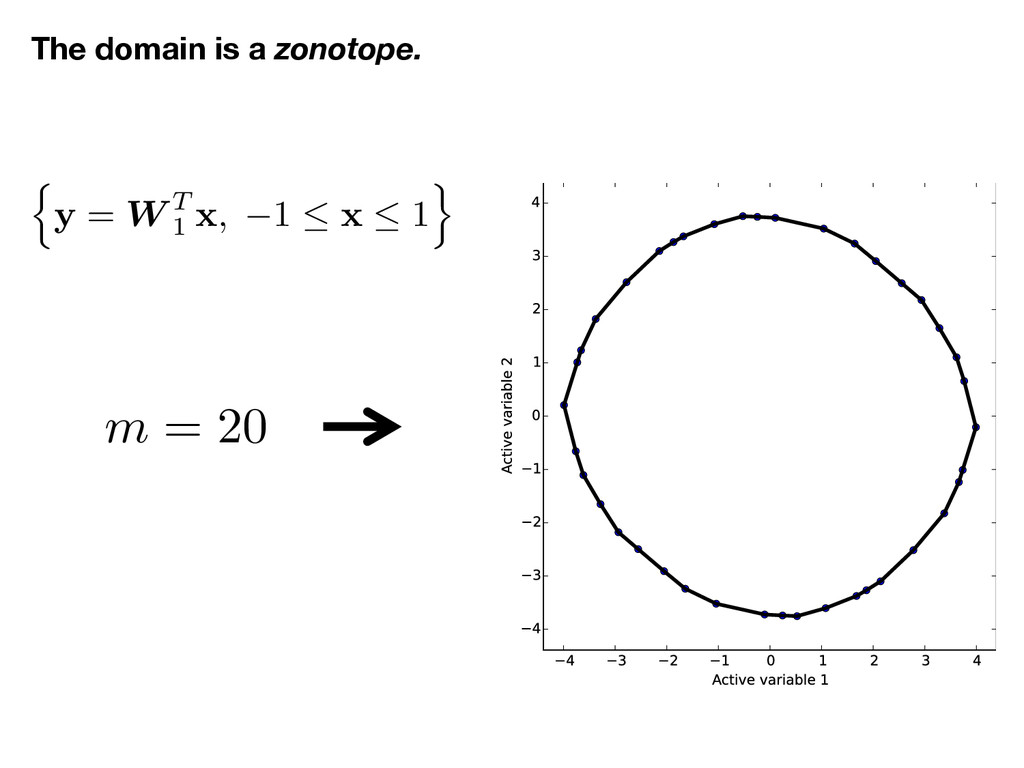
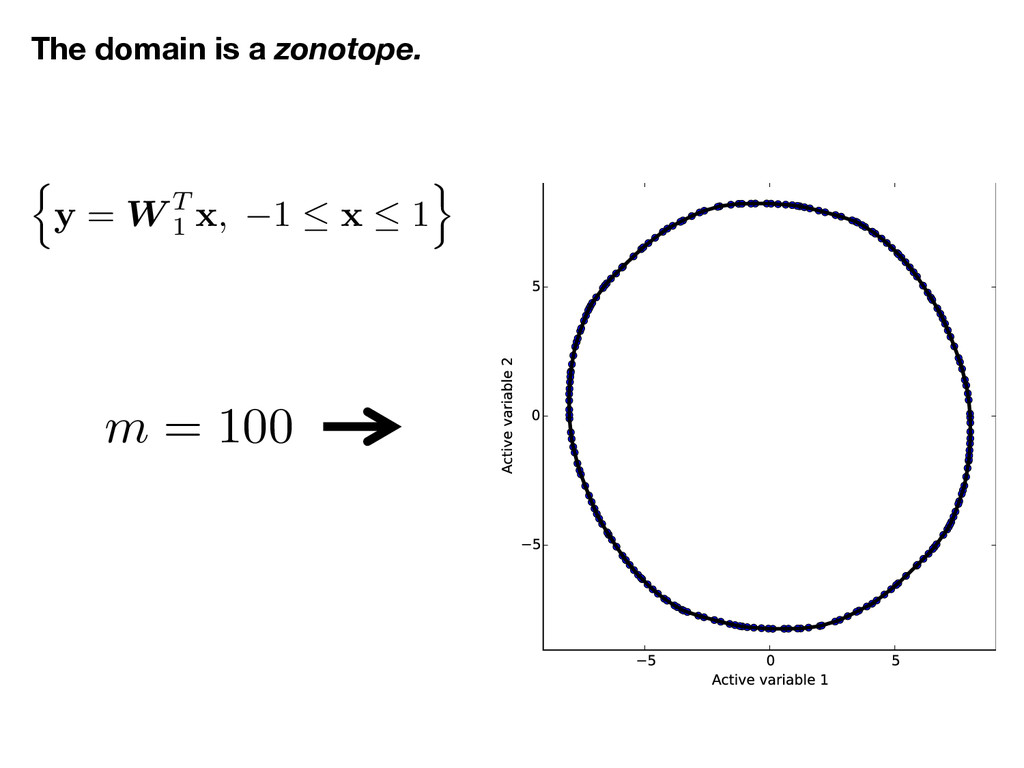
![x 2 [ 1 , 1] m, ⇢ (x) =](https://files.speakerdeck.com/presentations/f535d579d6d74c5c97fdf7c2e7d4a3b7/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}