Professor Department of Computer Science University of Colorado, Boulder activesubspaces.org! @DrPaulynomial! SLIDES AVAILABLE UPON REQUEST DISCLAIMER: These slides are meant to complement the oral presentation. Use out of context at your own risk.
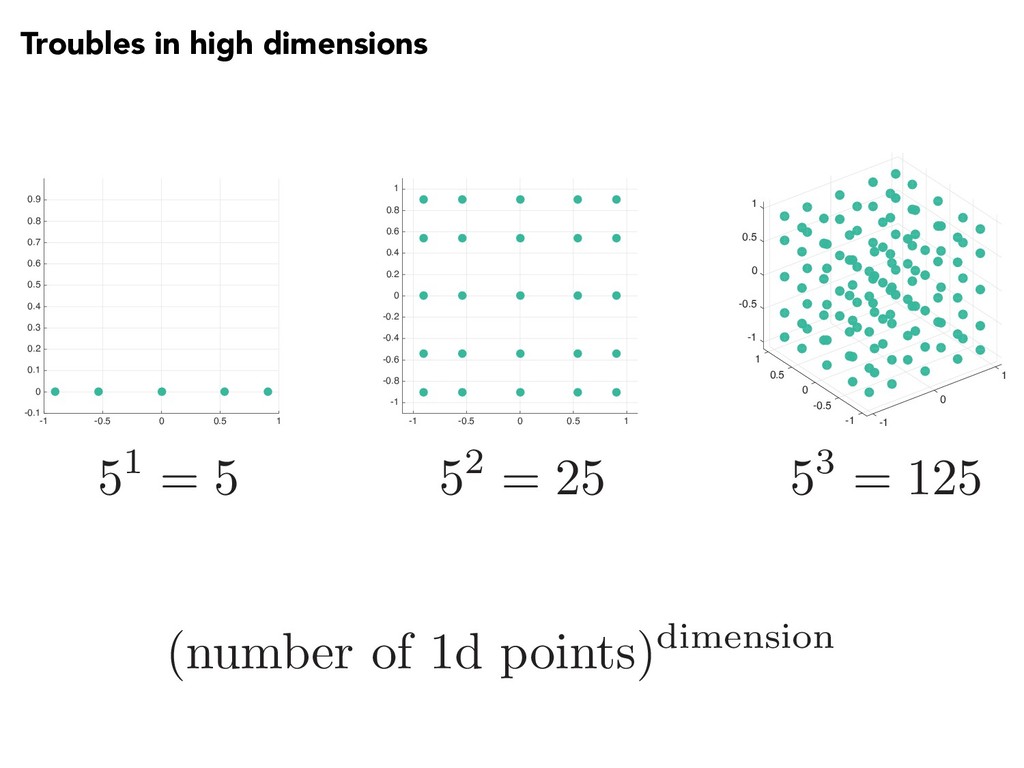
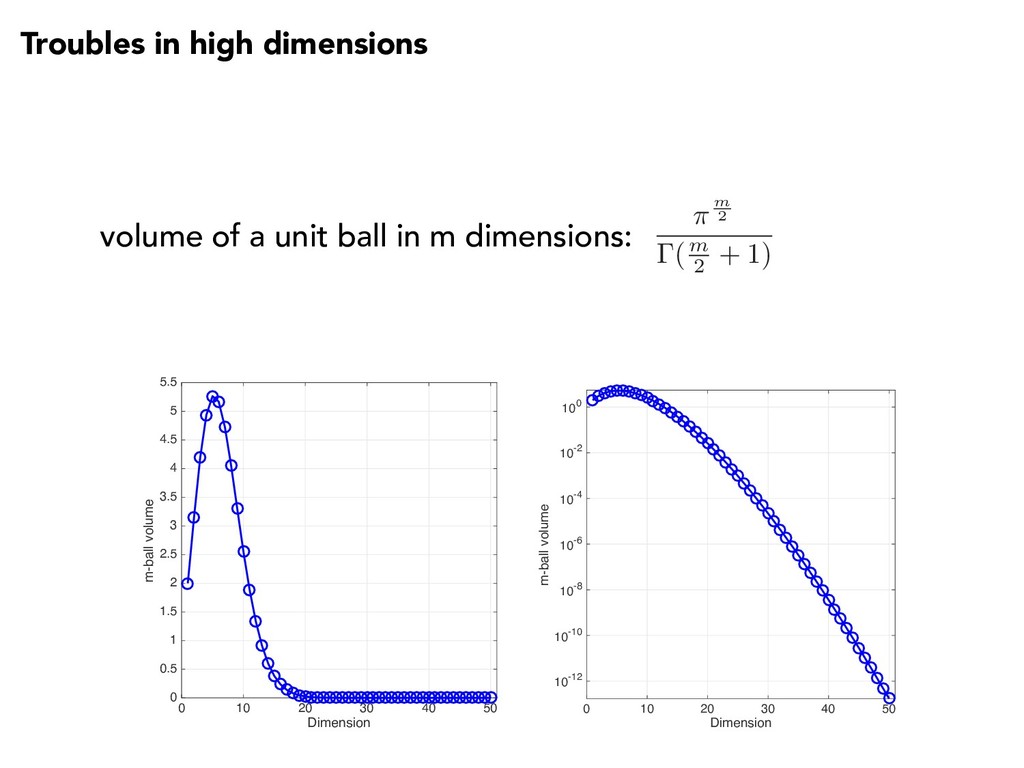
10 points per dimension) Time for parameter study (at 1 second per run) 1 10 10 sec 2 100 ~ 1.6 min 3 1,000 ~ 16 min 4 10,000 ~ 2.7 hours 5 100,000 ~ 1.1 days 6 1,000,000 ~ 1.6 weeks … … … 20 1e20 3 trillion years (240x age of the universe)
10 points per dimension) Time for parameter study (at 1 second per run) 1 10 10 sec 2 100 ~ 1.6 min 3 1,000 ~ 16 min 4 10,000 ~ 2.7 hours 5 100,000 ~ 1.1 days 6 1,000,000 ~ 1.6 weeks … … … 20 1e20 3 trillion years (240x age of the universe) REDUCED-ORDER MODELS or PARALLEL PROCESSING
10 points per dimension) Time for parameter study (at 1 second per run) 1 10 10 sec 2 100 ~ 1.6 min 3 1,000 ~ 16 min 4 10,000 ~ 2.7 hours 5 100,000 ~ 1.1 days 6 1,000,000 ~ 1.6 weeks … … … 20 1e20 3 trillion years (240x age of the universe) BETTER DESIGNS or ADAPTIVE SAMPLING
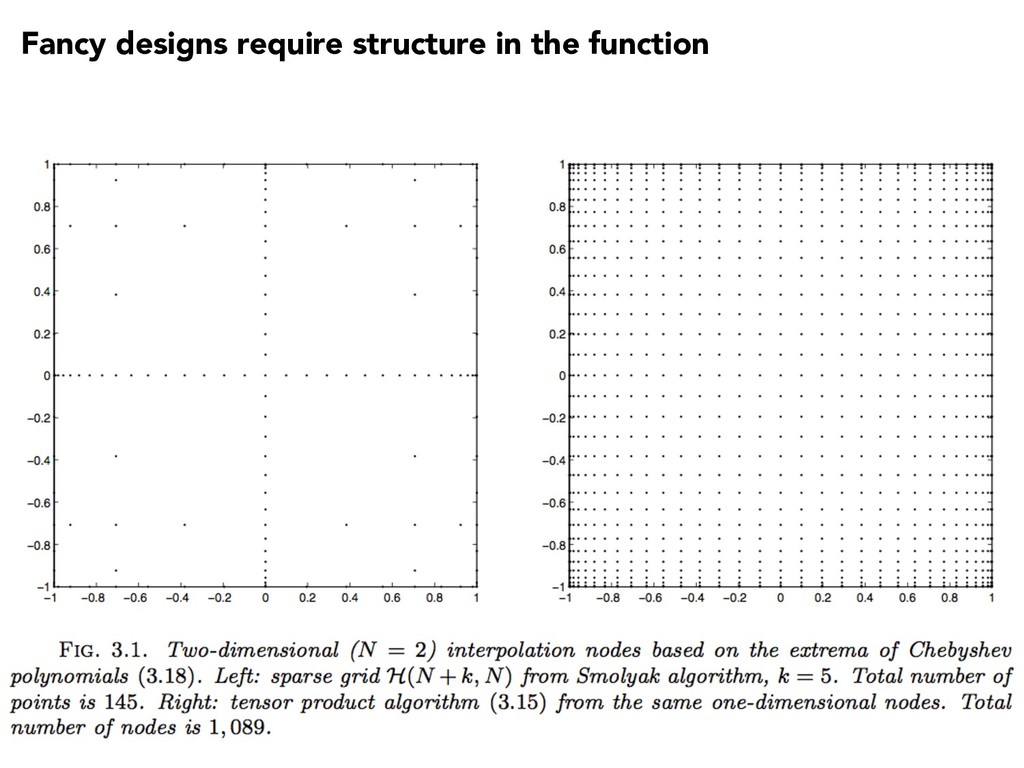
we can do to data only in terms of some set of very restrictive assumptions under which that thing is best possible—assumptions we know we CANNOT check in practice.” “Many algorithms … aim to diminish the ‘curse of dimensionality.’ Such algorithms take advantage of special properties of the functions being treated, such as alignment with the axes, but their authors do not always emphasize this aspect of their methods.”
the dimension. But what is dimension reduction? • dimensional analysis [Barrenblatt (1996)] • correlation-based reduction [Jolliffe (2002)] • sensitivity analysis [Saltelli et al. (2008)]
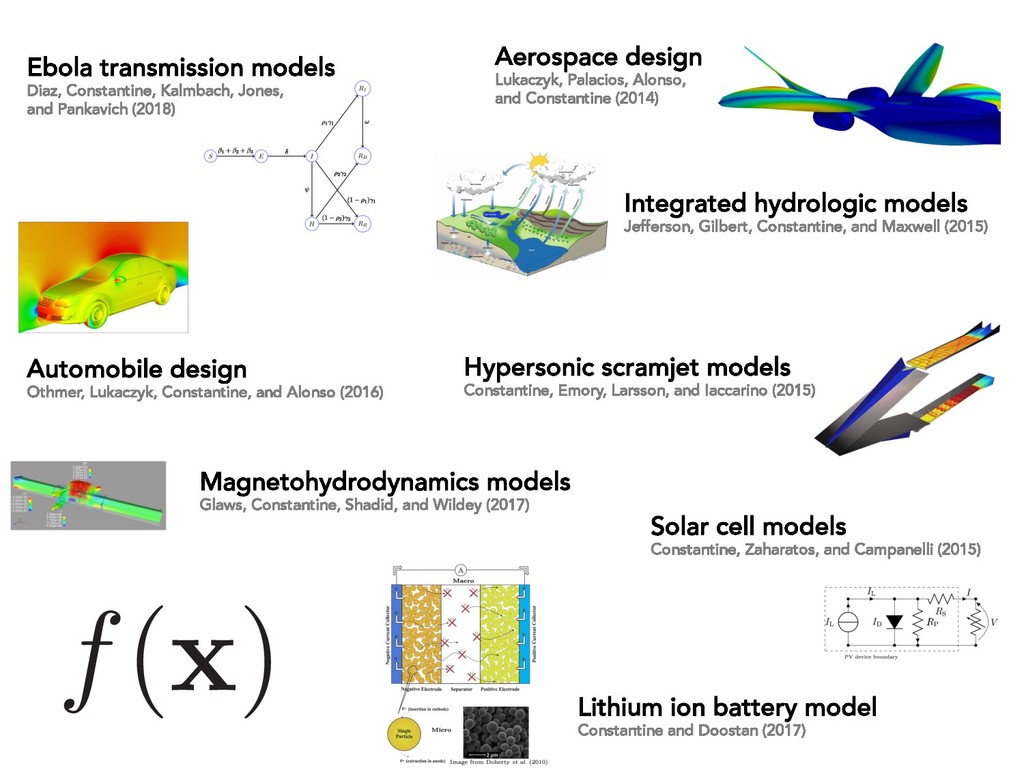
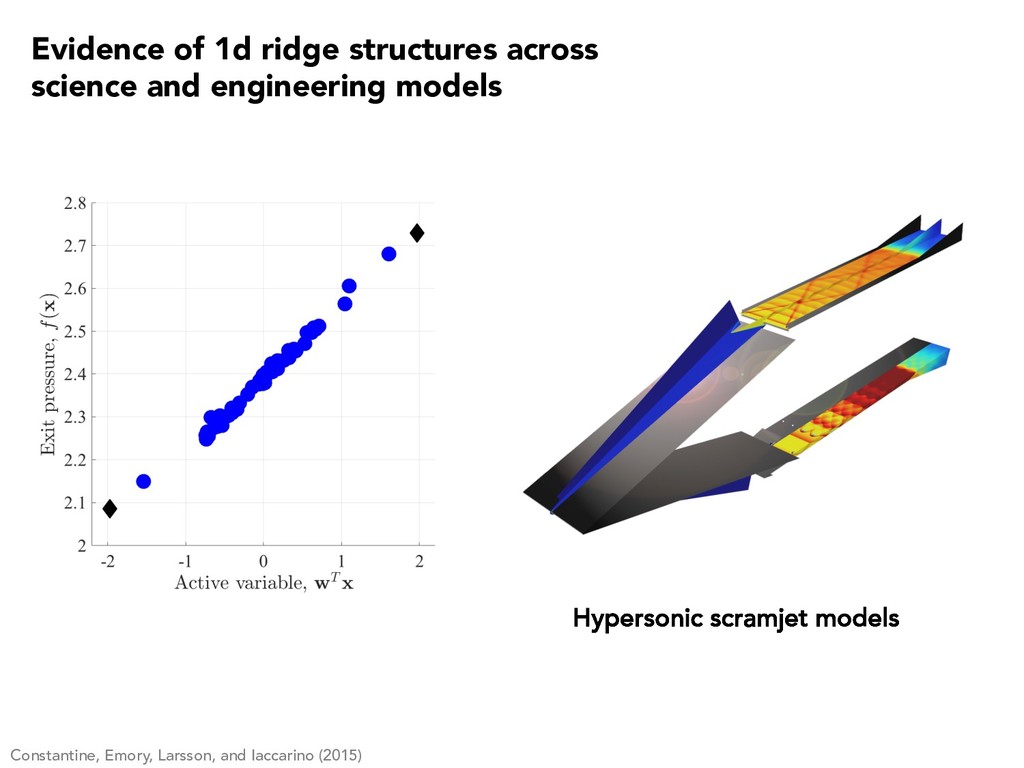
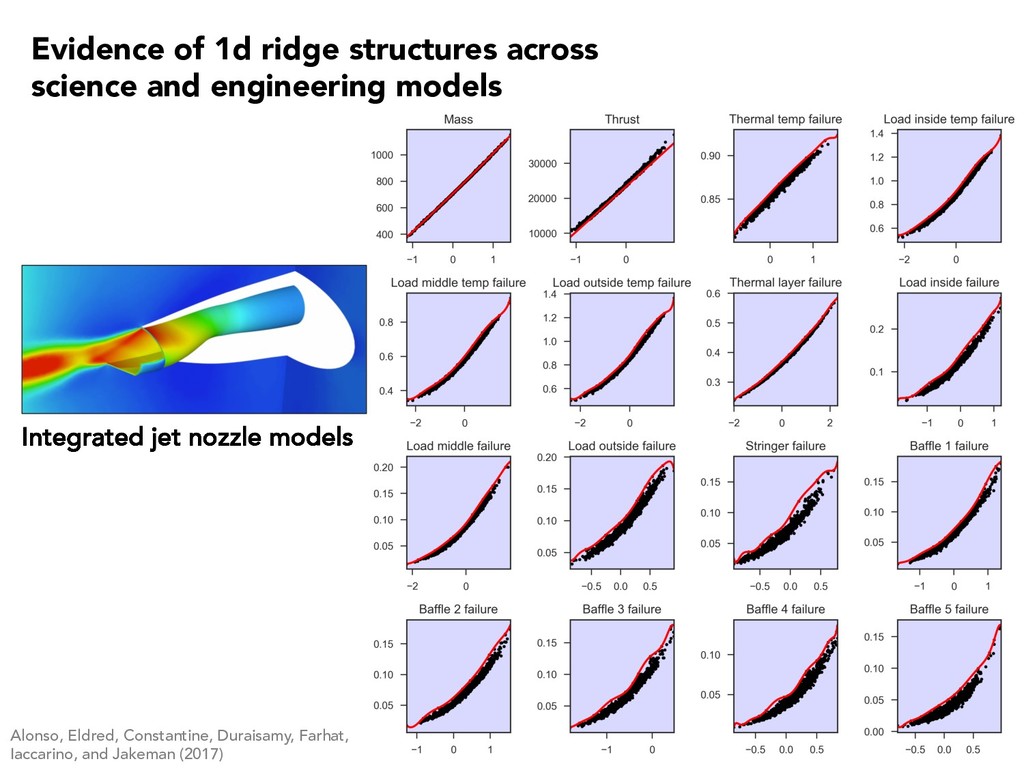
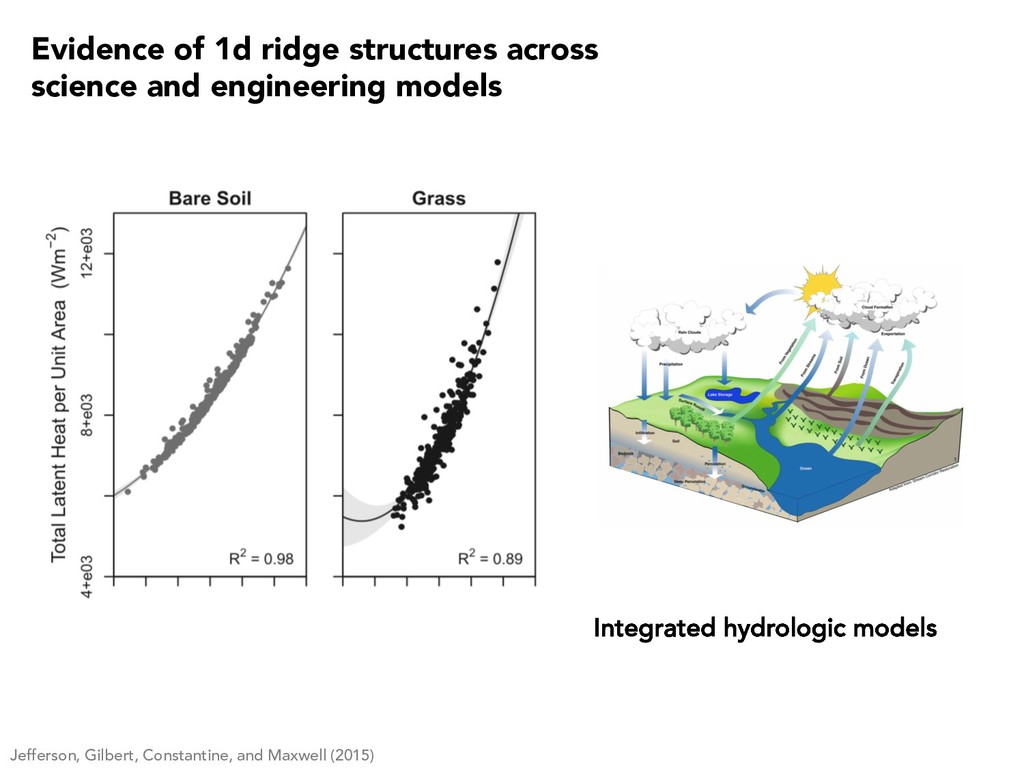
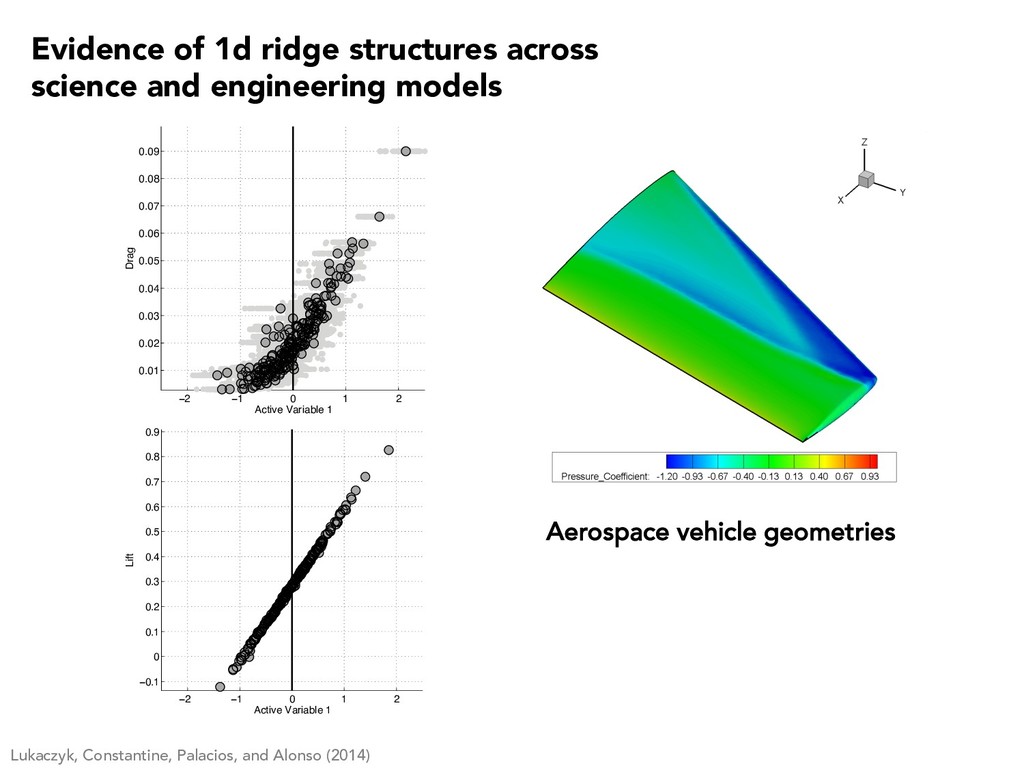
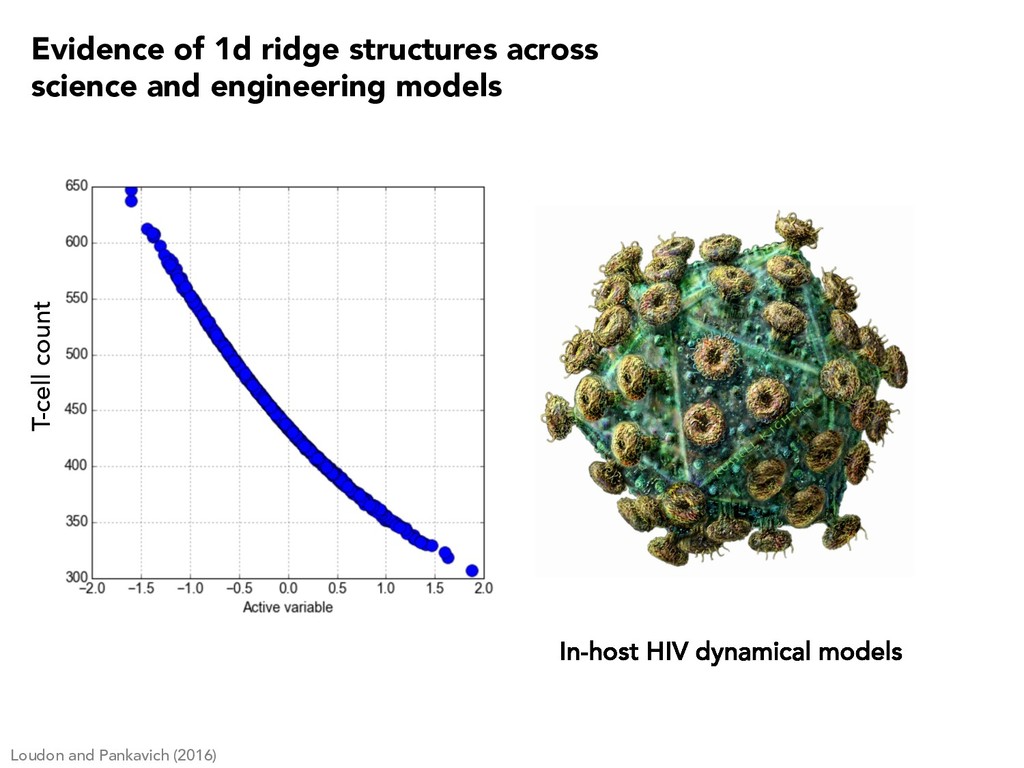
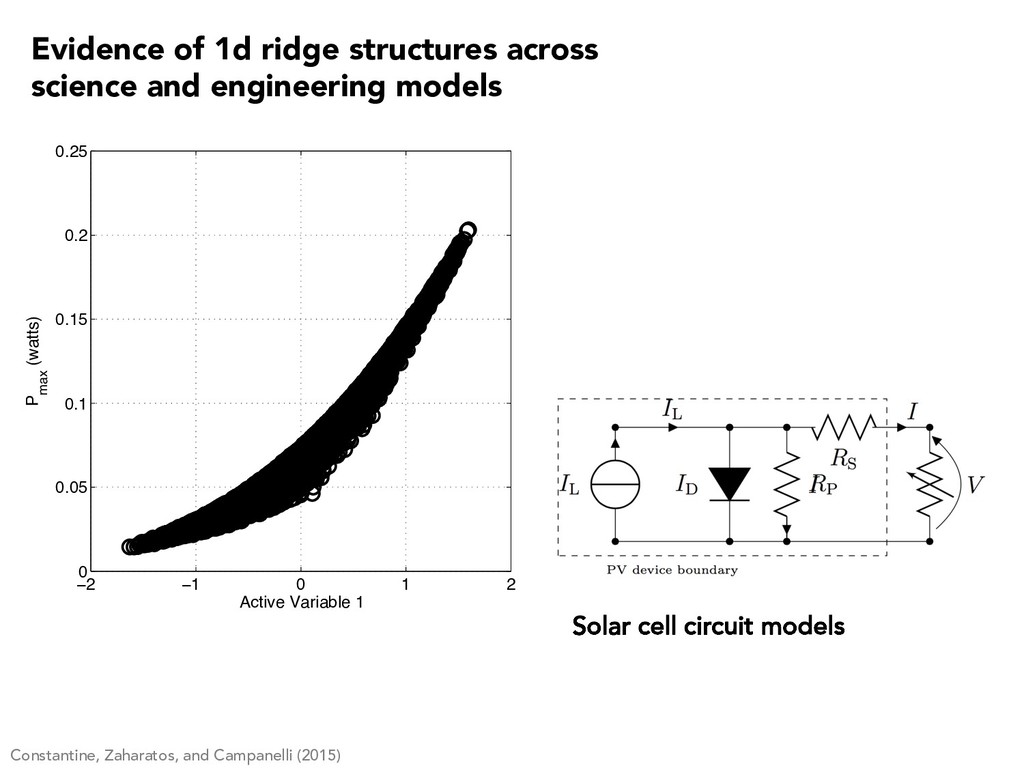
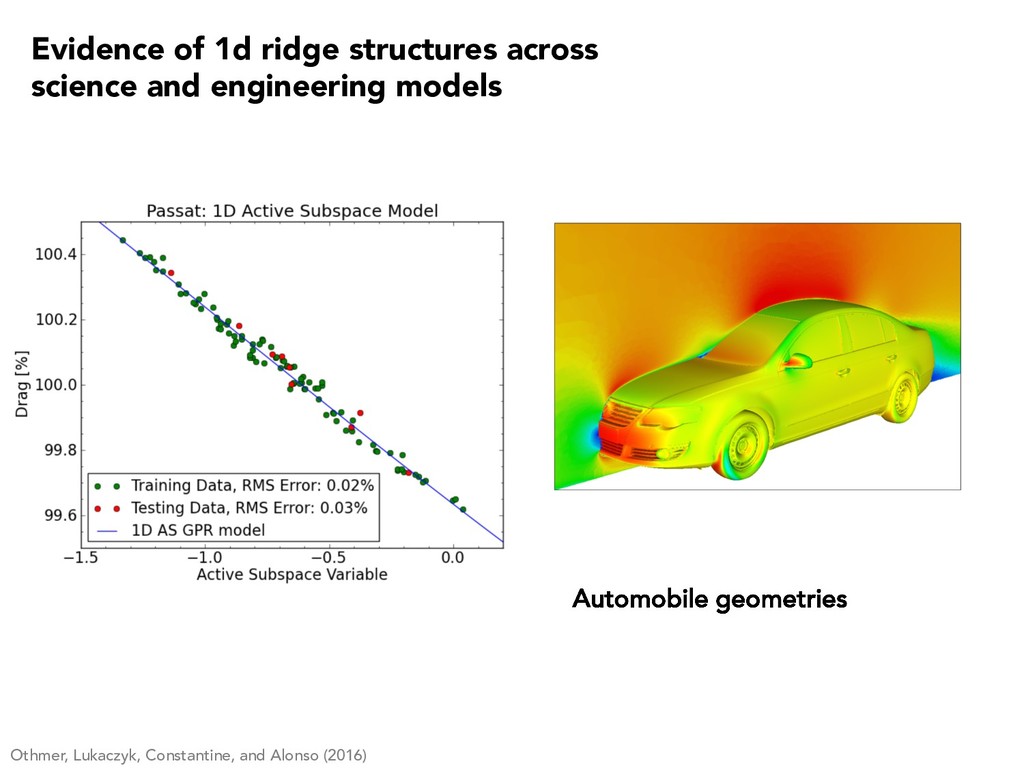
0.05 0.1 0.15 0.2 0.25 Active Variable 1 P max (watts) Constantine, Zaharatos, and Campanelli (2015) Evidence of 1d ridge structures across science and engineering models
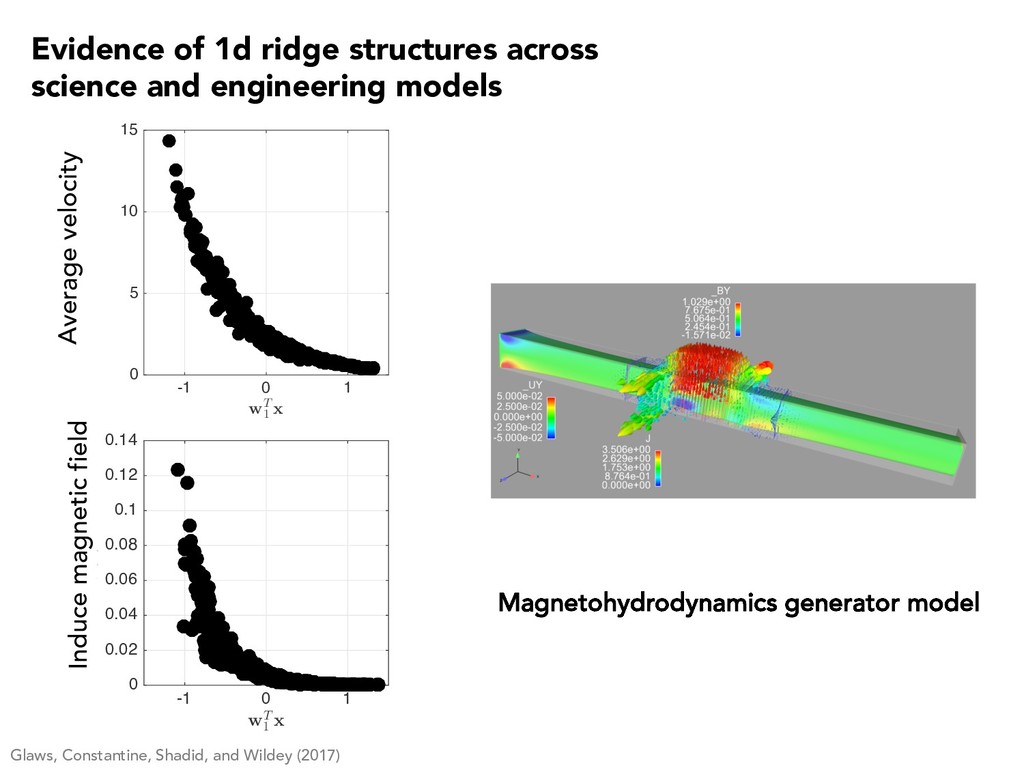
5 10 15 f(x) Average velocity Glaws, Constantine, Shadid, and Wildey (2017) -1 0 1 wT 1 x 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 f(x) Induce magnetic field Evidence of 1d ridge structures across science and engineering models
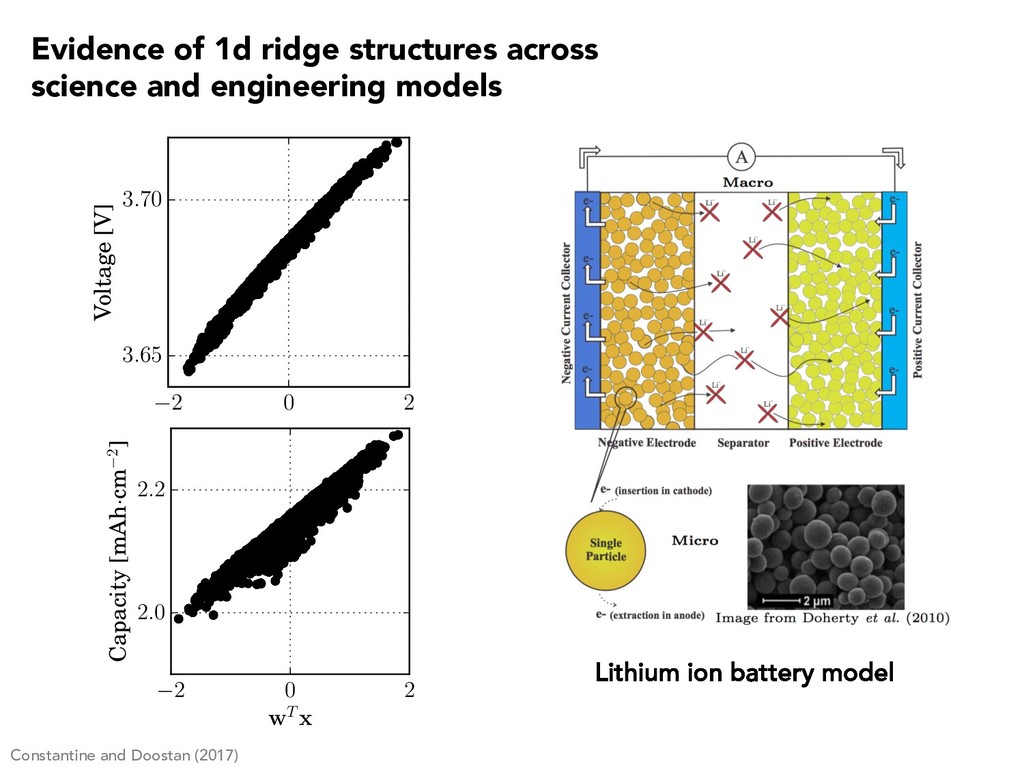
3.70 Voltage [V] Constantine and Doostan (2017) 2 0 2 wT x 2.0 2.2 Capacity [mAh·cm 2] Evidence of 1d ridge structures across science and engineering models
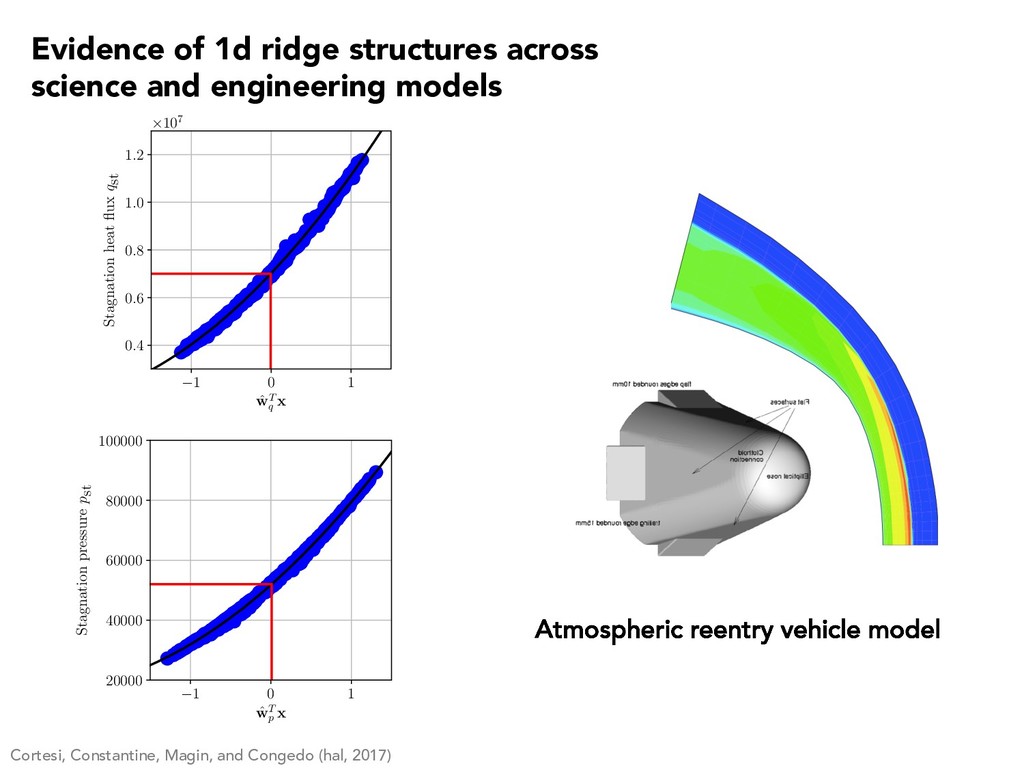
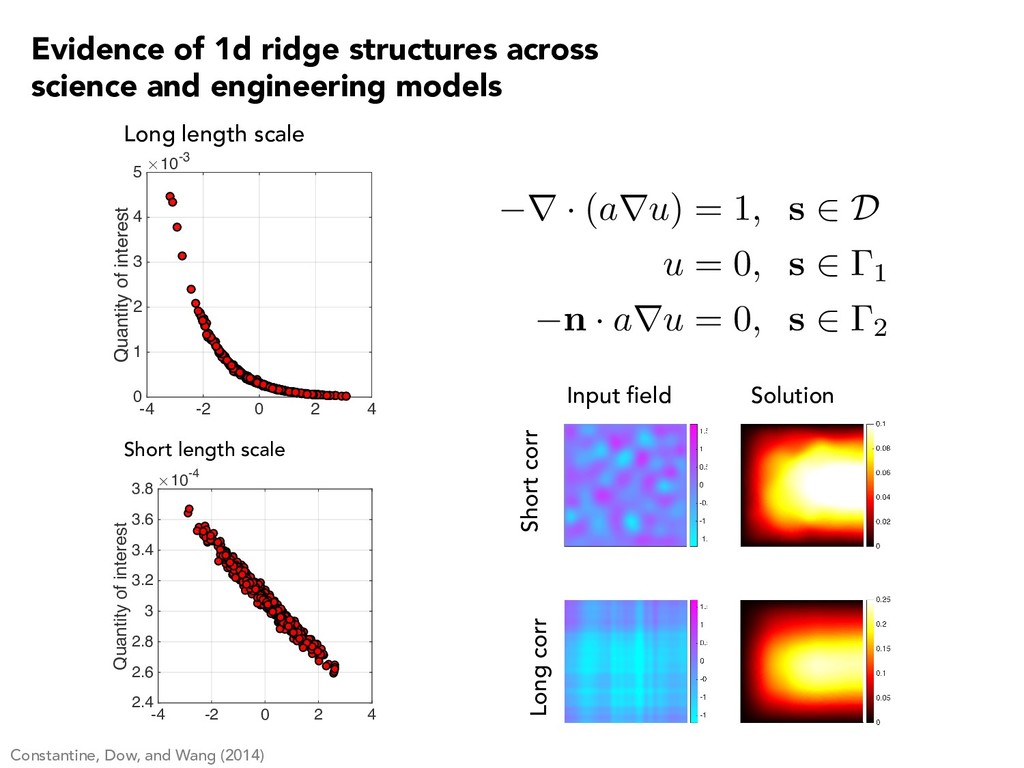
1 2 3 4 5 -4 -2 0 2 4 Quantity of interest #10-4 2.4 2.6 2.8 3 3.2 3.4 3.6 3.8 Long length scale Short length scale Constantine, Dow, and Wang (2014) r · (aru) = 1, s 2 D u = 0, s 2 1 n · aru = 0, s 2 2 Input field Solution Short corr Long corr Evidence of 1d ridge structures across science and engineering models
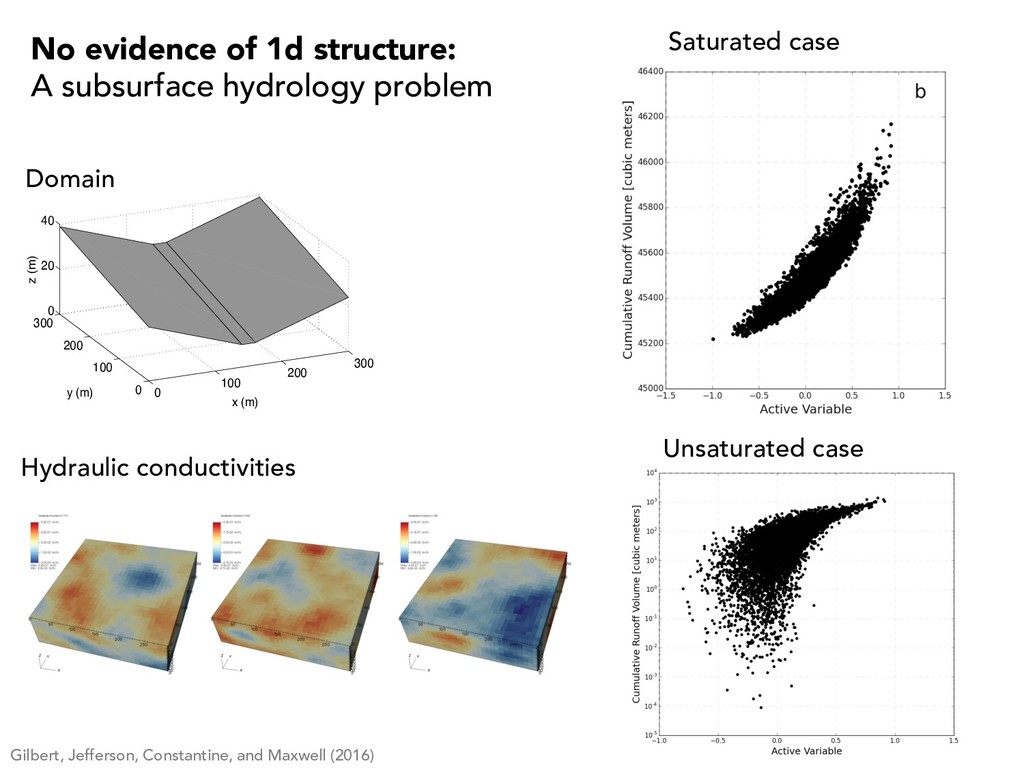
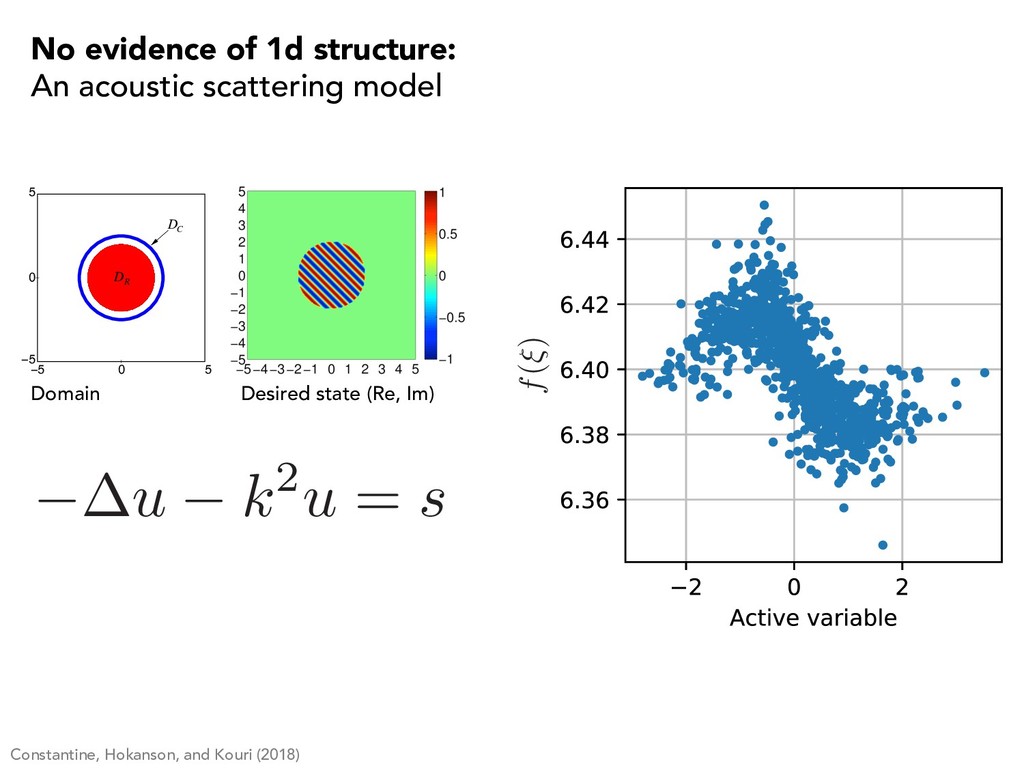
structure: A subsurface hydrology problem 0 100 200 300 0 100 200 300 0 20 40 x (m) y (m) z (m) Student Version of MATLAB Domain Hydraulic conductivities Unsaturated case Saturated case
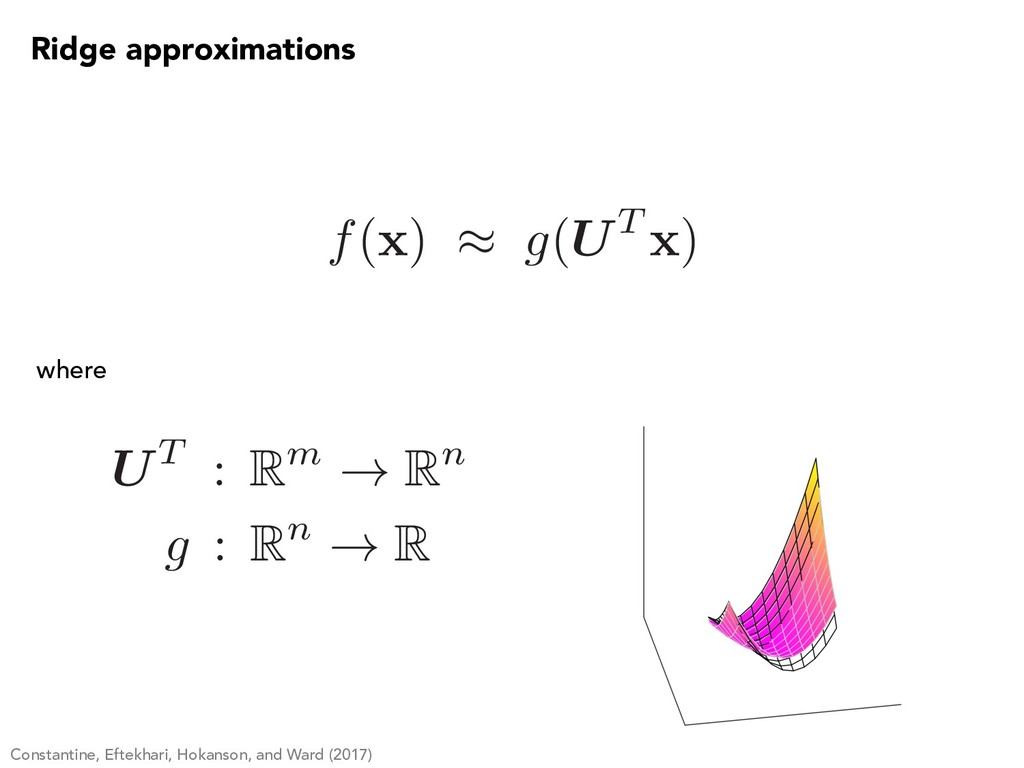
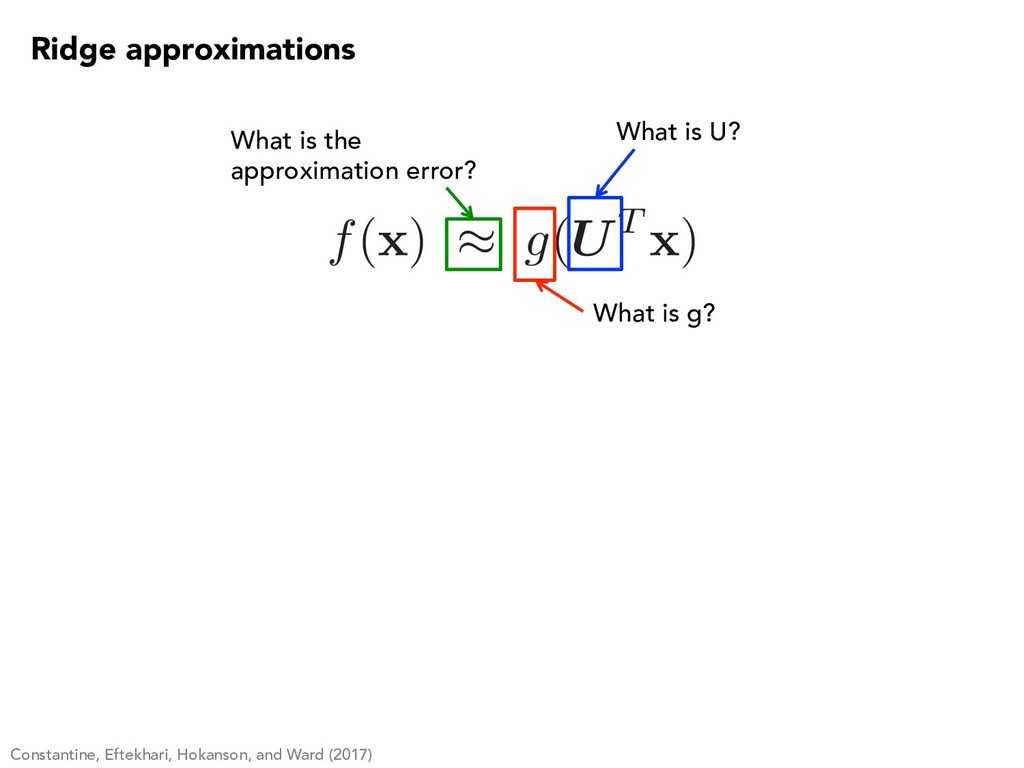
et al. (2015), Pinkus (2015), Diaconis and Shahshahani (1984), Donoho and Johnstone (1989) Compressed sensing: Fornasier et al. (2012), Cohen et al. (2012), Tyagi and Cevher (2014) Statistical regression: Friedman and Stuetzle (1981), Ichimura (1993), Hristache et al. (2001), Xia et al. (2002) Uncertainty quantification: Tipireddy and Ghanem (2014); Lei et al. (2015); Stoyanov and Webster (2015); Tripathy, Bilionis, and Gonzalez (2016); Li, Lin, and Li (2016); … f( x ) ⇡ g(UT x )
x ) d x = W ⇤W T Define the active subspace The average outer product of the gradient and its eigendecomposition, Partition the eigendecomposition, Rotate and separate the coordinates, ⇤ = ⇤1 ⇤2 , W = ⇥ W 1 W 2 ⇤ , W 1 2 Rm⇥n x = W W T x = W 1W T 1 x + W 2W T 2 x = W 1y + W 2z active variables inactive variables f = f( x ), x 2 Rm, rf( x ) 2 Rm, ⇢ : Rm ! R + Constantine, Dow, and Wang (2014) Some relevant literature Statistical regression: Samarov (1993), Hristache et al. (2001) Machine learning: Mukerjee, Wu, and Xiao (2010); Fukumizu and Leng (2014) Signal processing: van Trees (2001) The function, its gradient vector, and a given weight function:
x ) d x = W ⇤W T Define the active subspace The function, its gradient vector, and a given weight function: The average outer product of the gradient and its eigendecomposition: f = f( x ), x 2 Rm, rf( x ) 2 Rm, ⇢ : Rm ! R + Constantine, Dow, and Wang (2014) i = Z w T i rf( x ) 2 ⇢( x ) d x , i = 1, . . . , m average, squared, directional derivative along eigenvector eigenvalue Eigenvalues measure ridge structure with eigenvectors:
µ(W T 1 x ) L2(⇢) C ( n+1 + · · · + m)1 2 Constantine, Dow, and Wang (2014) The eigenvalues measure the approximation error conditional expectation first n eigenvectors (i.e., the active subspace)
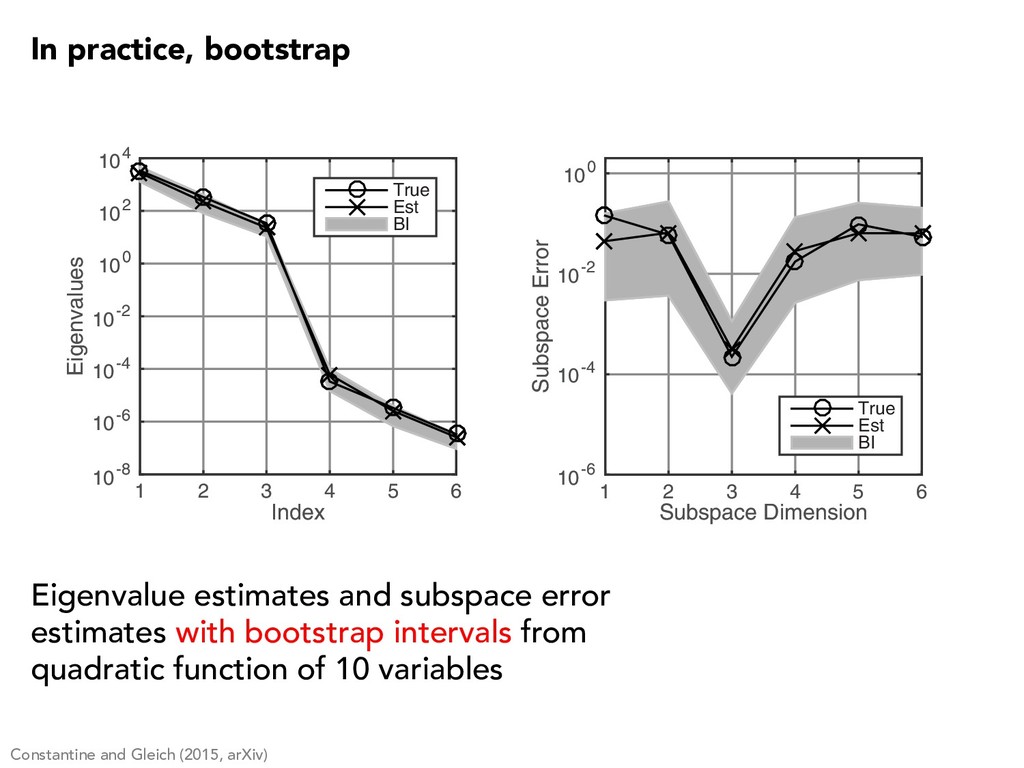
(3) Approximate with Monte Carlo, and compute eigendecomposition Equivalent to SVD of samples of the gradient Called an active subspace method in T. Russi’s 2010 Ph.D. thesis, Uncertainty Quantification with Experimental Data in Complex System Models C ⇡ 1 N N X j=1 rfj rfT j = ˆ W ˆ ⇤ ˆ W T 1 p N ⇥ rf1 · · · rfN ⇤ = ˆ W p ˆ ⇤ ˆ V T rfj = rf( xj) Constantine, Dow, and Wang (2014), Constantine and Gleich (2015, arXiv) xj ⇠ ⇢( x ) Estimate the active subspace with Monte Carlo
m ) ◆ = ) | k ˆk | k " How many gradient samples? number of samples eigenvalue error (w.h.p.) subspace error (w.h.p.) Constantine and Gleich (2015) via Gittens and Tropp (2011), Stewart (1973) N = ⌦ ✓ L2 1"2 log( m ) ◆ = ) dist( W 1, ˆ W 1) 4 1" n n+1 bound on gradient dimension number of samples bound on gradient dimension
⇡ ˆ W 1 q ˆ ⇤1 ˆ V T 1 Low-rank approximation of the collection of gradients: Low-dimensional linear approximation of the gradient: f( x ) ⇡ g ⇣ ˆ W T 1 x ⌘ Approximate a function of many variables by a function of a few linear combinations of the variables: ✔ ✖ ✖ Remember the problem to solve span ( ˆ W 1) ⇡ { rf( x ) : x 2 supp ⇢( x ) }
Define the error function: R(U) = 1 2 Z (f( x ) µ(UT x ))2 ⇢( x ) d x Minimize the error: minimize U R ( U ) subject to U 2 G ( n, m ) Grassmann manifold of n-dimensional subspaces Constantine, Eftekhari, Hokanson, and Ward (2017) Ridge approximations best approximation
Minimize the misfit Minimize over polynomials and subspaces Constantine, Eftekhari, Hokanson, and Ward (2017), Hokanson and Constantine (2018) xj ⇠ ⇢( x ) Estimate the optimal subspace with discrete least squares minimize g2P p(Rn) U2G(n,m) N X j=1 ⇣ fj g(UT xj) ⌘2 Come to my talk! Today @5pm, B110
exploring high-dimensional functions from computational science models Existing approaches cheap surrogate models, smart sampling, exploiting structure in function, dimension reduction (sensitivity analysis, PCA) Main idea finding important directions in parameter space Real applications evidence of off-axis important directions Definitons and methods two definitions and computational methods for finding important directions
x )T ⇢( x ) d x Derivative-based ideas: eigenvalues suggest structure, eigenvectors give directions Active subspaces [Constantine et al. (2014), Russi (2010)], Gradient outer product [Mukherjee et al. (2010)], Outer product of gradient [Hristache et al. (2001)] Z r2f( x ) ⇢( x ) d x Principal Hessian directions [Li (1992)], Likelihood-informed subspaces [Cui et al. (2014)] Ideas for approximating these without gradients: finite differences [Constantine & Gleich (2015), Lewis et al. (2016)], polynomial approximations [Yang et al (2016), Tippireddy & Ghanem (2014)], kernel approximations [Fukumizu & Leng (2014)] See Samarov’s average derivative functionals [Samarov (1993)]
suggest structure, eigenvectors give directions Sliced inverse regression [Li (1991), Glaws et al. (2018)] Sliced average variance estimation [Cook & Weisberg (1991), Glaws et al. (2018)] E ⇥ E[ x |f] E[ x |f]T ⇤ E h ( I Cov[x |f ]) 2 i E ⇥ ( x1 x2) ( x1 x2)T | |f( x1) f( x2)| ⇤ Contour regression [Li et al. (2005)] These are population metrics; data produces sample estimates.
ridge or near-ridge structure Optimization ideas: optimum residual suggests structure, optimizer gives directions Ridge approximation [Constantine et al. (2017, 2018)], Minimum average variance estimation [Xia et al. (2002)], Gaussian processes [Vivarelli & Wiliams (1999), Tripathy et al. (2016)] Projection pursuit regression [Friedman & Stuetzle (1981), Huber (1985)] Likelihood-based sufficient dimension reduction [Cook & Forzani (2009)] minimize gi, ui f( x ) X i gi( u T i x ) ! maximize U E [ k PU Cov[x |f ] PU k ⇤ ] All nonconvex optimizations. Some on Grassmann manifold of subspaces.
to each other? How do you construct the function of the active variables? f( x ) ⇡ g(UT x ) What is the cost trade-off between estimating subspaces versus solving the problem? How does this relate to standard sensitivity analysis? How do you exploit this important subspaces for integration / optimization? How might I gain insight into my system from important subspaces? Is there a way to classify problems that have such important subspaces? How do these ideas extend? Nonlinearity, manifolds, … How do we know the computational approximations are any good?
(2) Insights + which variables are important (3) Discoverable / checkable + eigenvalues + non-residual metrics: + plots in 1 and 2d E[ Var[ f | UT x ] ] Why I like ridge structure
to reduce the dimension! There are many notions of important subspaces; they arise in several applications. Important subspaces are discoverable and exploitable for answering science questions. TAKE HOMES
model doesn’t fit your setup? (no gradients, multiple outputs, correlated inputs, …) How does this help with surrogate modeling? PAUL CONSTANTINE Assistant Professor University of Colorado Boulder activesubspaces.org! @DrPaulynomial! QUESTIONS? Active Subspaces SIAM (2015)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}