is based upon work supported by the U.S. Department of Energy Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics program under Award Number DE-SC-0011077. PAUL CONSTANTINE Ben L. Fryrear Assistant Professor Applied Mathematics & Statistics Colorado School of Mines activesubspaces.org! @DrPaulynomial! SLIDES: DISCLAIMER: These slides are meant to complement the oral presentation. Use out of context at your own risk. In collaboration with: RACHEL WARD UT Austin ARMIN EFTEKHARI UT Austin
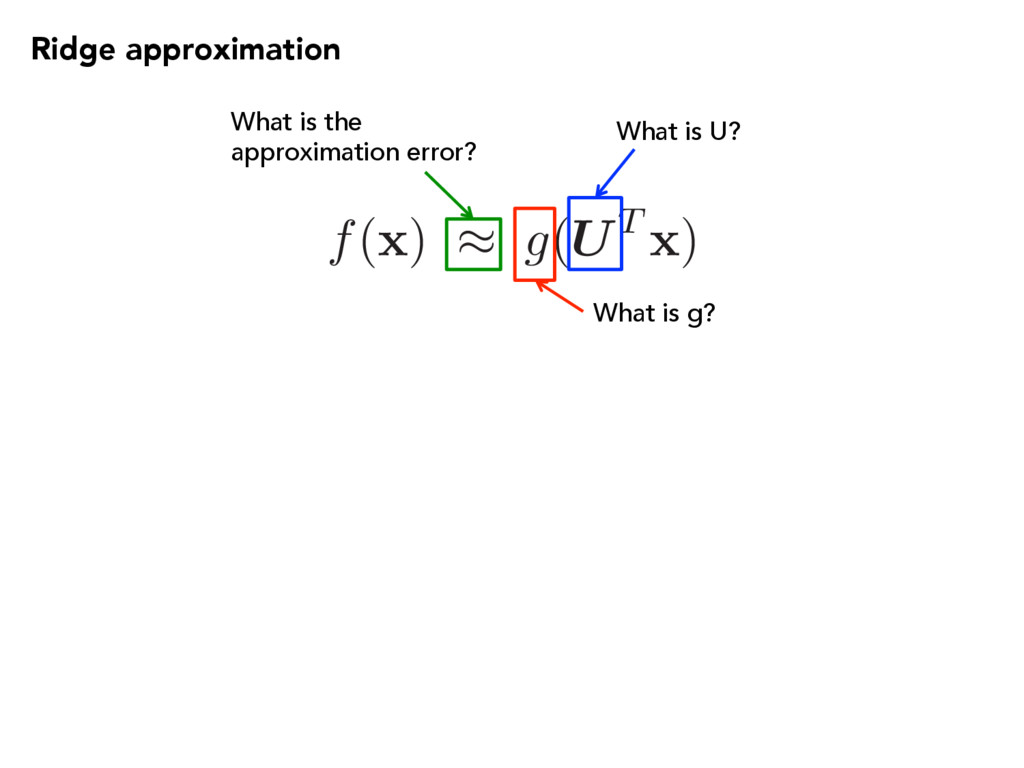
is the approximation error? f( x ) g(UT x ) L2(⇢) = ✓Z (f( x ) g(UT x ))2 ⇢( x ) d x ◆1 2 Use the weighted root-mean-squared error: Given weight function
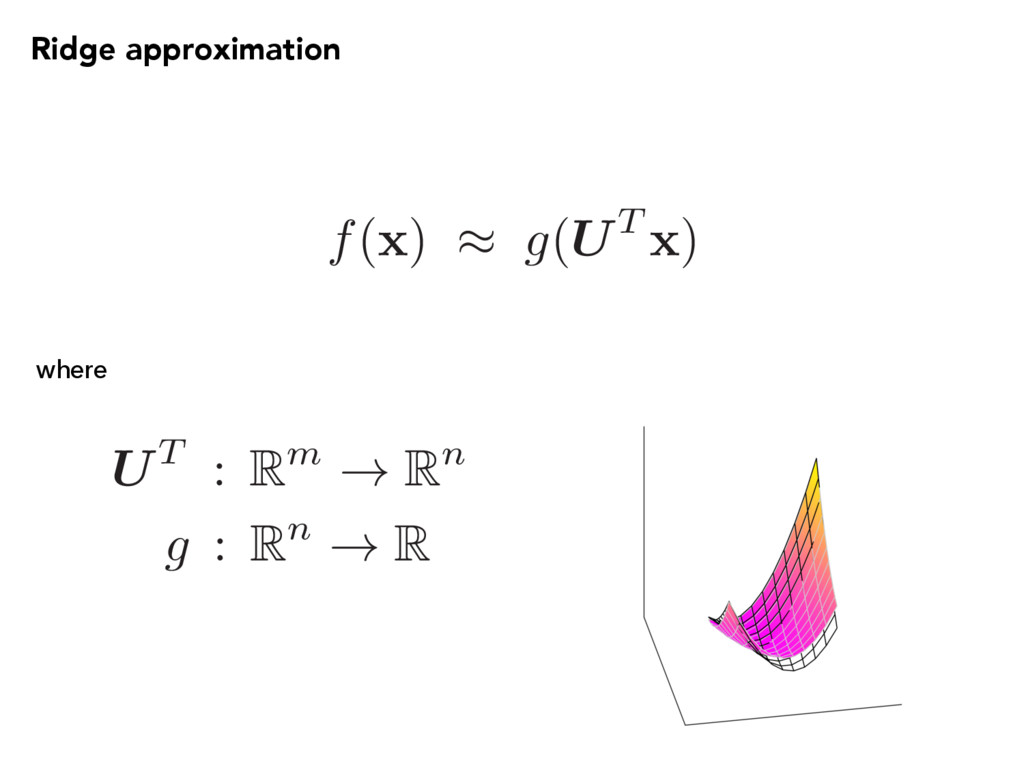
x ) ⇡ g(UT x ) Ridge approximation Use the conditional average: Subspace coordinates What is g? Complement subspace and coordinates Conditional density µ(UT x ) is the best approximation (Pinkus, 2015).
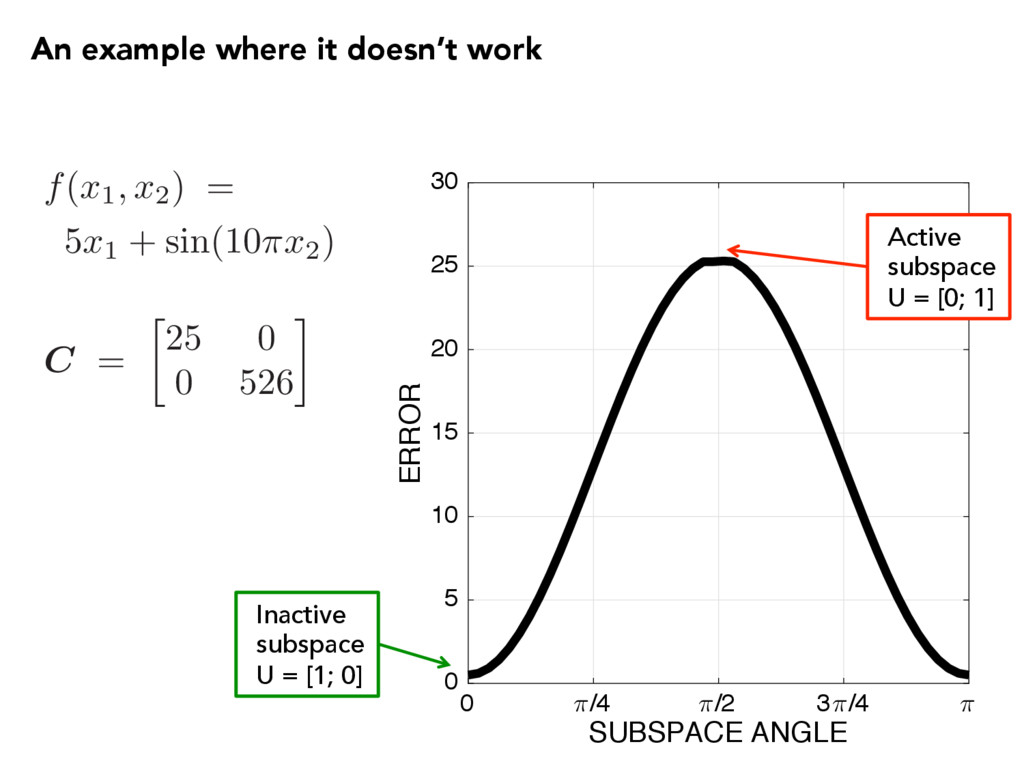
is U? Define the error function: R(U) = 1 2 Z (f( x ) µ(UT x ))2 ⇢( x ) d x Minimize the error: minimize U R ( U ) subject to U 2 G ( n, m ) Grassmann manifold of n-dimensional subspaces
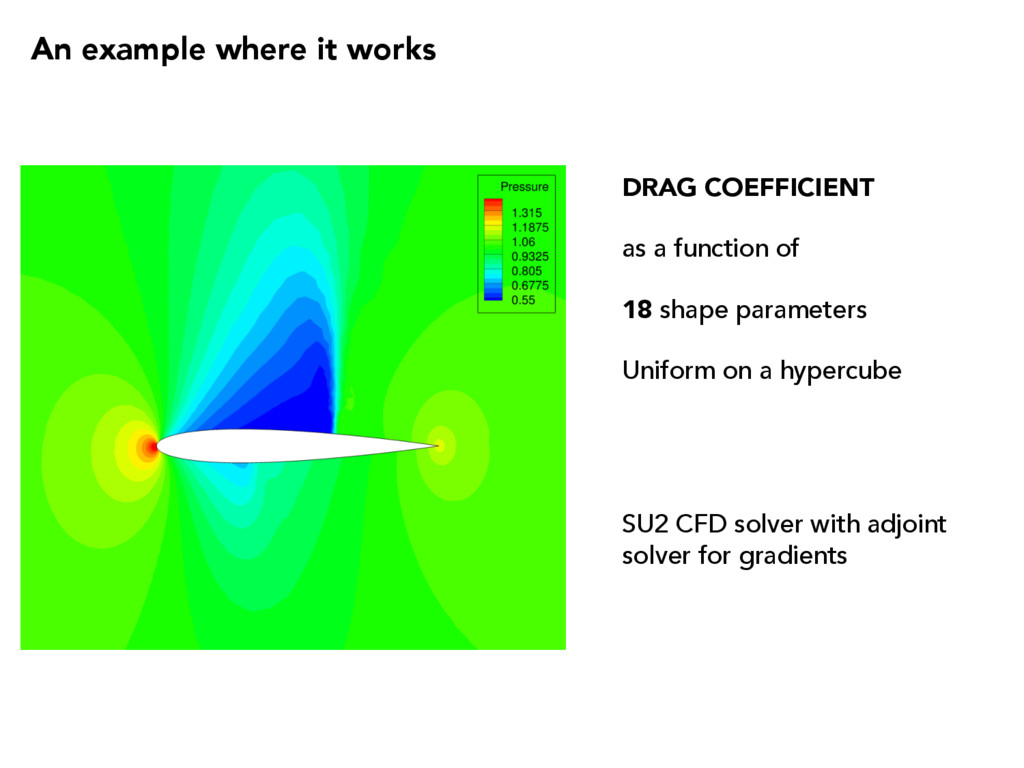
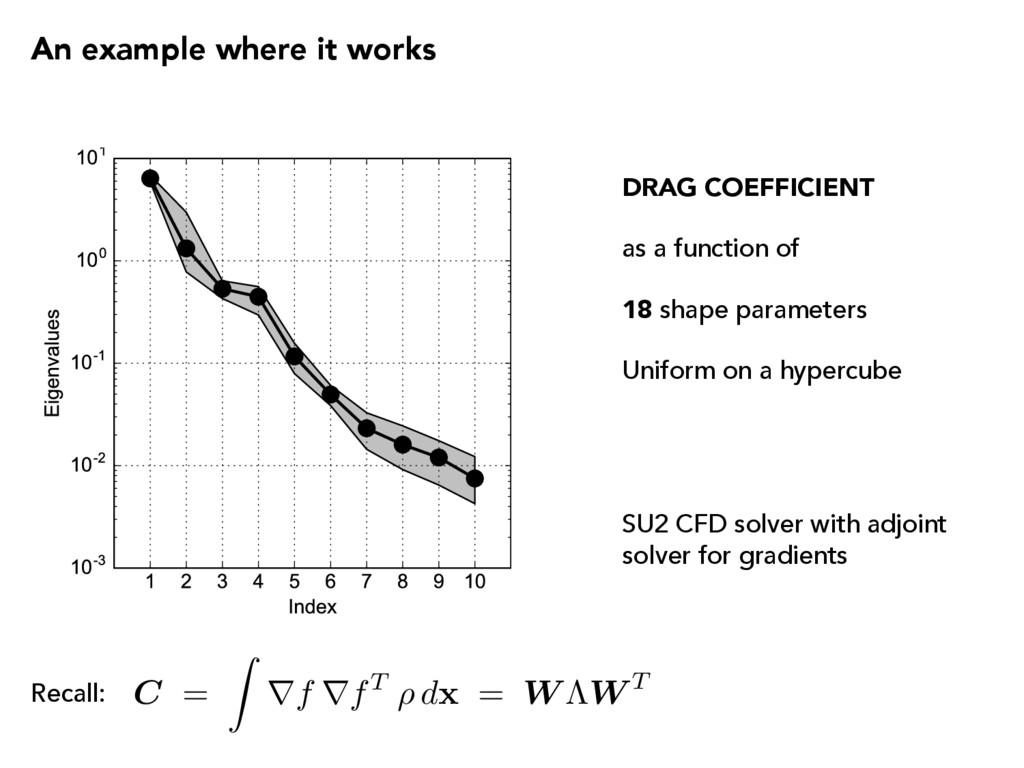
vector, The average outer product of the gradient and its eigendecomposition, Partition the eigendecomposition, Rotate and separate the coordinates, ⇤ = ⇤1 ⇤2 , W = ⇥ W 1 W 2 ⇤ , W 1 2 Rm⇥n x = W W T x = W 1W T 1 x + W 2W T 2 x = W 1y + W 2z active variables inactive variables f = f( x ), x 2 Rm, rf( x ) 2 Rm, ⇢ : Rm ! R + C = Z rf rfT ⇢ d x = W ⇤W T
i = 1, . . . , m The eigenpairs identify perturbations that change the function more, on average. LEMMA LEMMA Z (ryf)T (ryf) ⇢ d x = 1 + · · · + n Z (rzf)T (rzf) ⇢ d x = n+1 + · · · + m
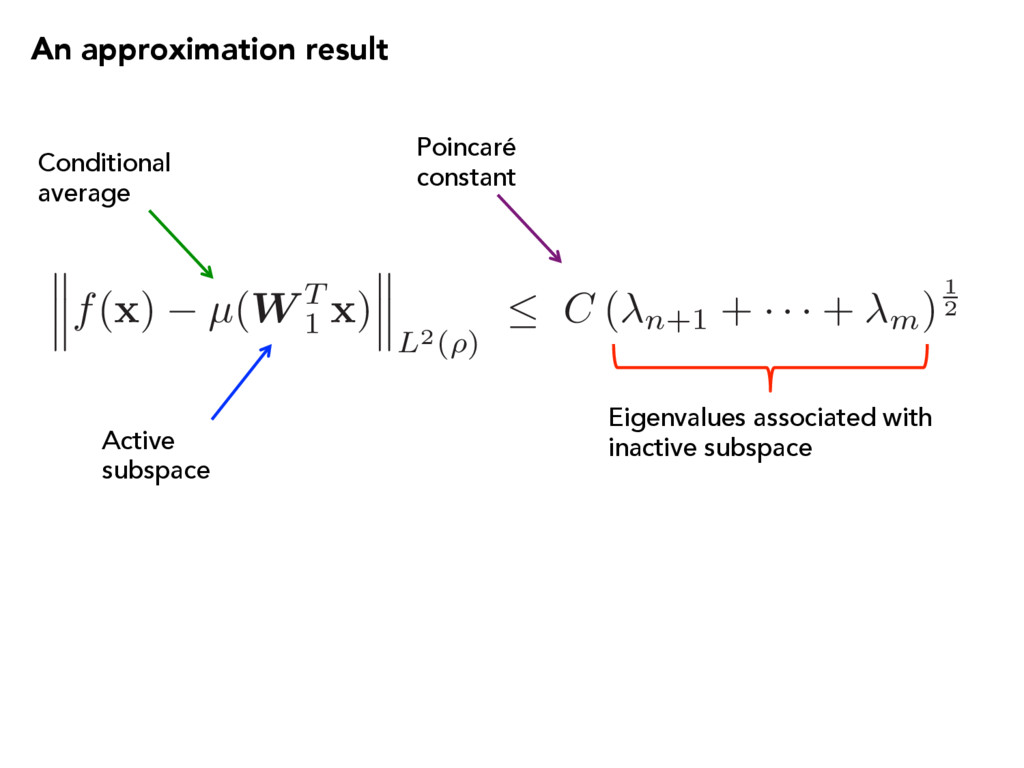
(m n)1 2 ⌘ ( n+1 + · · · + m)1 2 The active subspace is nearly stationary. R(U) = 1 2 Z (f( x ) µ(UT x ))2 ⇢( x ) d x Recall: Assume (1) Lipschitz continuous function (2) Gaussian density function Gradient on the Grassmann manifold Active subspace Frobenius norm Dimensions Lipschitz constant Eigenvalues associated with inactive subspace
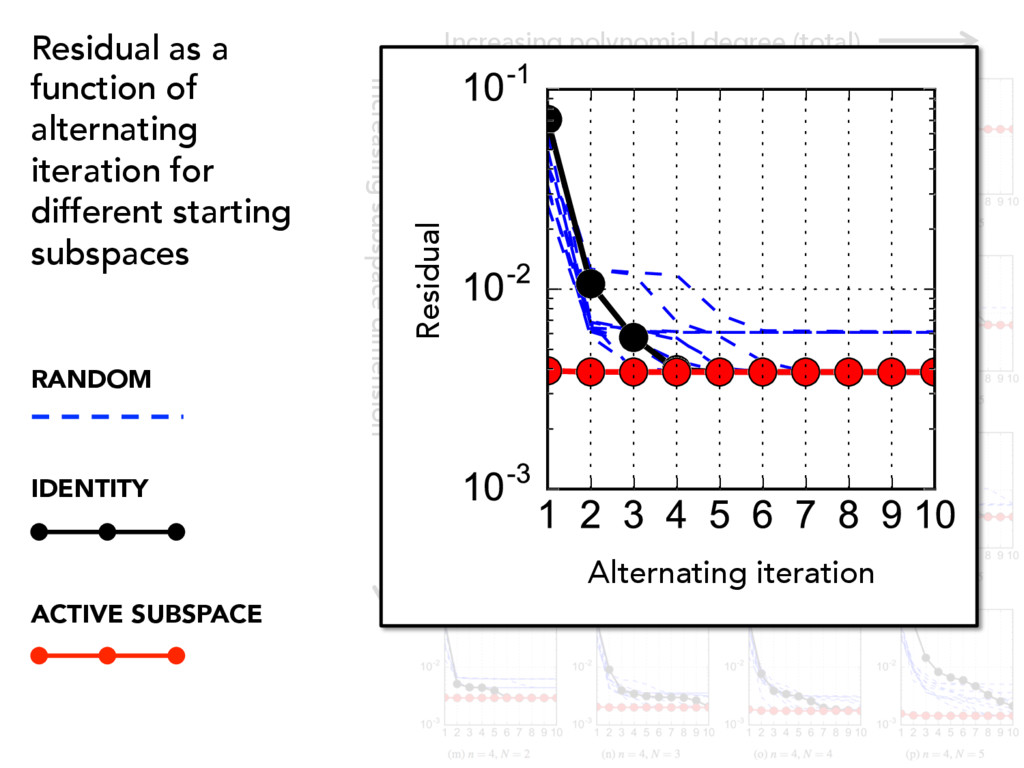
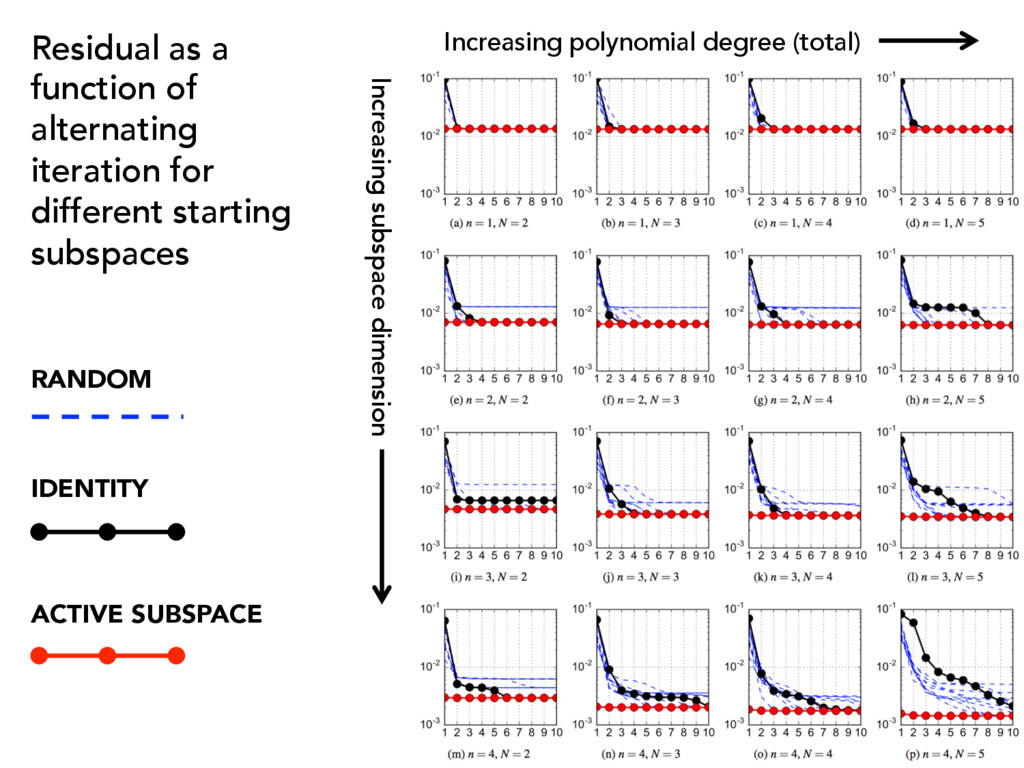
ridge approximation. U0 Given an initial subspace and samples (1) Compute (2) Fit a polynomial with the pairs (3) Minimize residual over subpsaces (4) Set and repeat { xi, f( xi)} { yi, f( xi)} pN (y, ✓) U⇤ = argmin U2G(n,m) X i ⇣ f( xi) p(UT xi, ✓⇤) ⌘2 ✓⇤ = argmin ✓ X i f( xi) p( yi, ✓) 2 yi = UT 0 xi U0 = U⇤
I don’t have gradients? What kinds of models does this work on? PAUL CONSTANTINE Ben L. Fryrear Assistant Professor Colorado School of Mines activesubspaces.org! @DrPaulynomial! QUESTIONS? Active Subspaces SIAM (2015)
{kind=link}
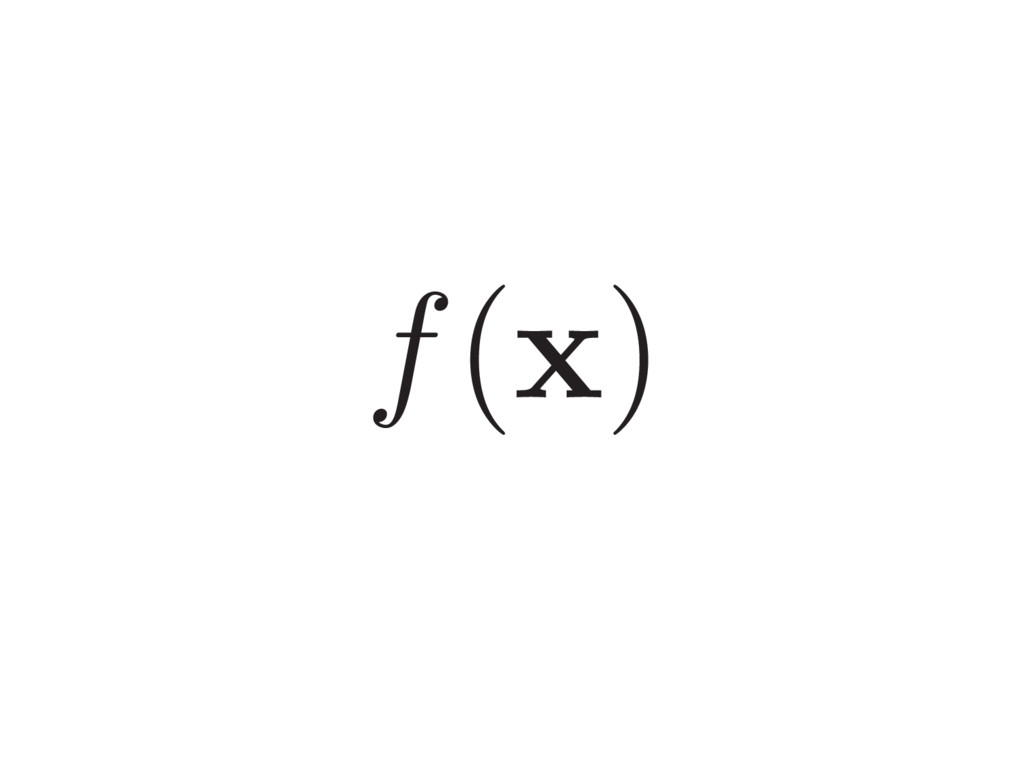{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![How do active subspaces relate to [insert method]? What if](https://files.speakerdeck.com/presentations/0a19735c379c4805b29de05bf1bb400a/slide_18.jpg){kind=link}