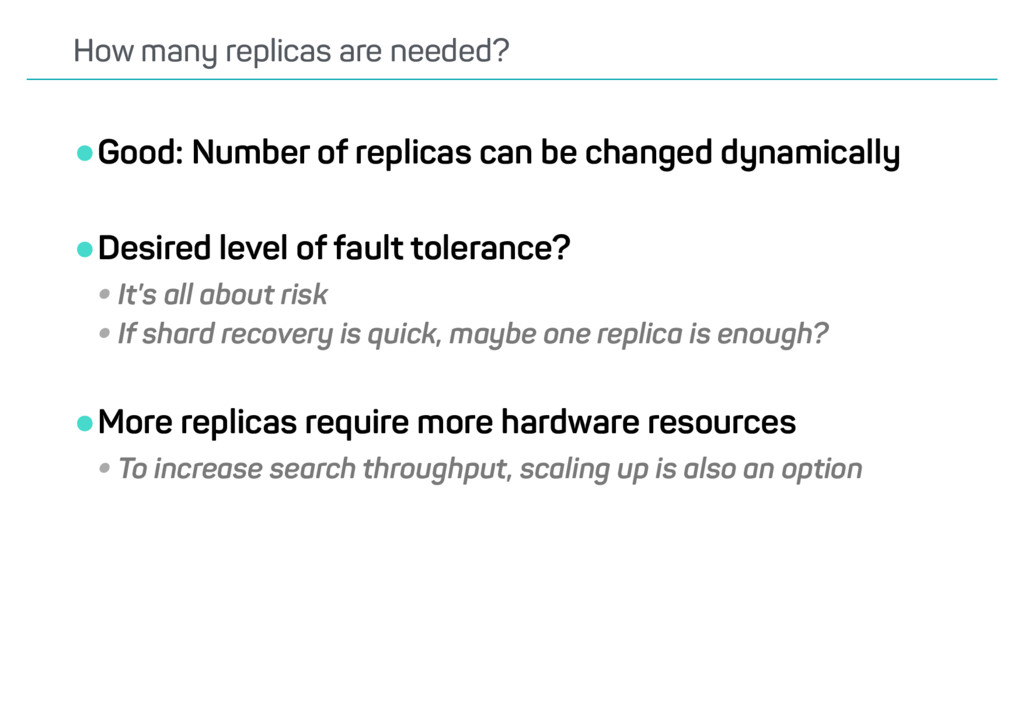
of fault tolerance? •It’s all about risk •If shard recovery is quick, maybe one replica is enough? •More replicas require more hardware resources •To increase search throughput, scaling up is also an option How many replicas are needed?
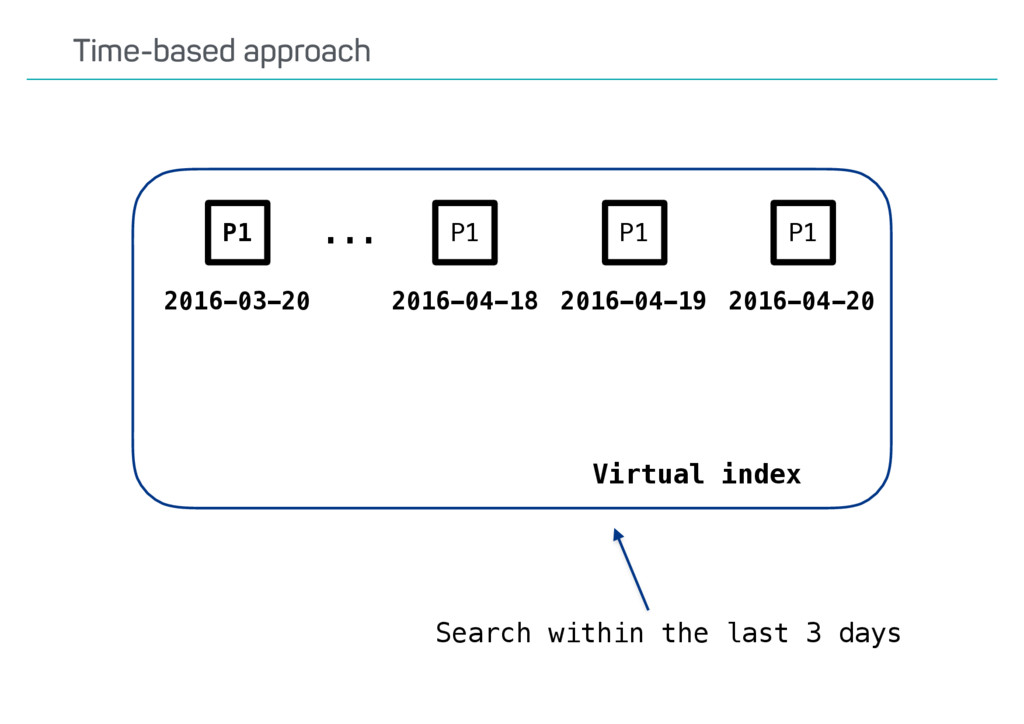
creation •Finding the right number requires some care •Formulate assumptions/expectations •Test and measure •Overallocate a little •Maximum shard size? •Often cited: 50 GB •Mainly a rule of thumb for quick recovery How many shards are needed?
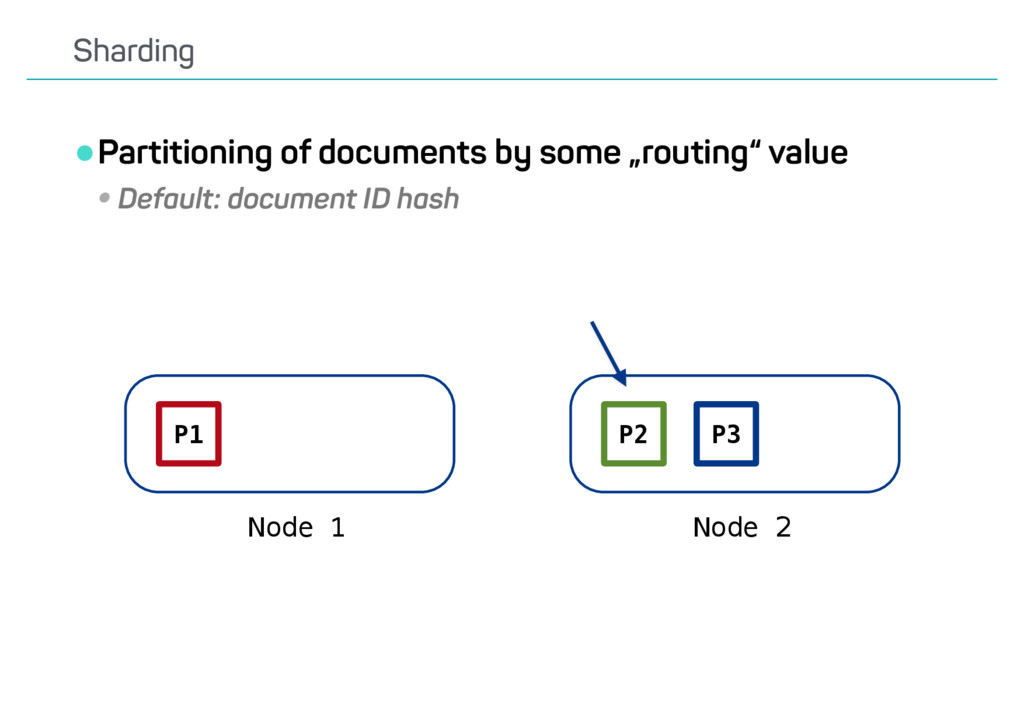
is easy •Indices are more flexible (e.g., creation, deletion) •But: Every index consumes certain resources •Cluster state, in-memory data structures •Recommendation: Shard an index if… •…you suspect that one shard might not be enough •…and there is no indicator for a „smarter“ approach When to shard?
e.g., Reindex API, Update API •Can you exclude some fields from the _source? •Do you need to store _source at all? •Disable _source and only store a few selected fields? Storing fields
just index it again •Reduces network traffic •Specify update as partial document or script •Update by ID or by query •Small updates might take a while •A single expensive field is enough Update API
bulk •Optimum bulk size depends on the document size •When in doubt, prefer smaller bulks •Still hitting a limit with bulk indexing? •The bottleneck might not be at the server •Try concurrent indexing with multiple clients Bulk indexing
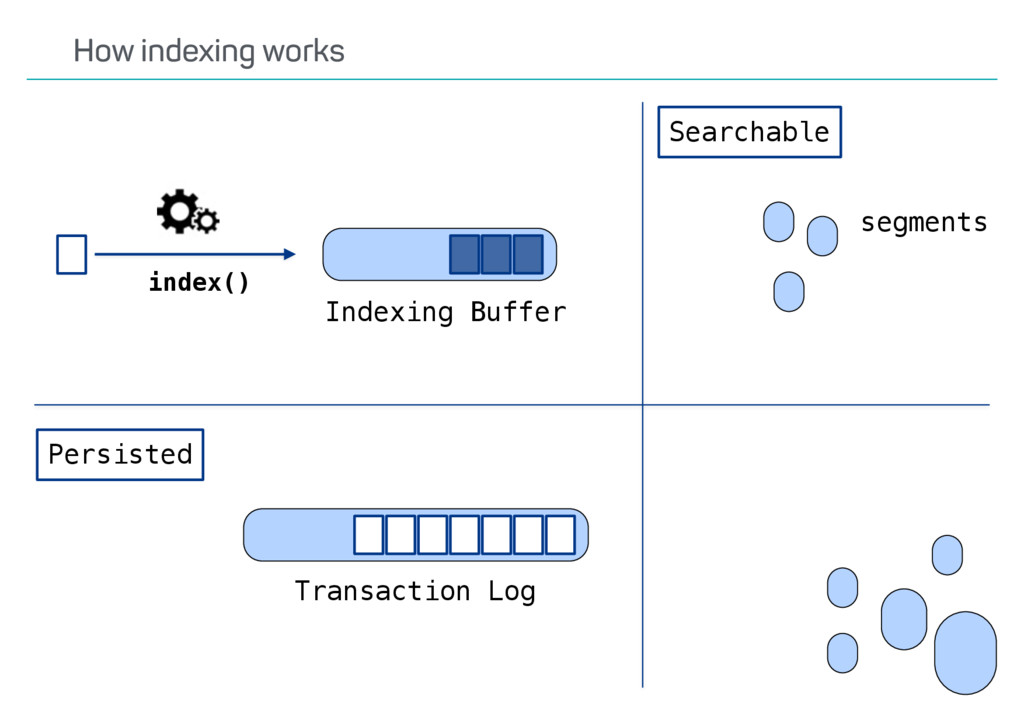
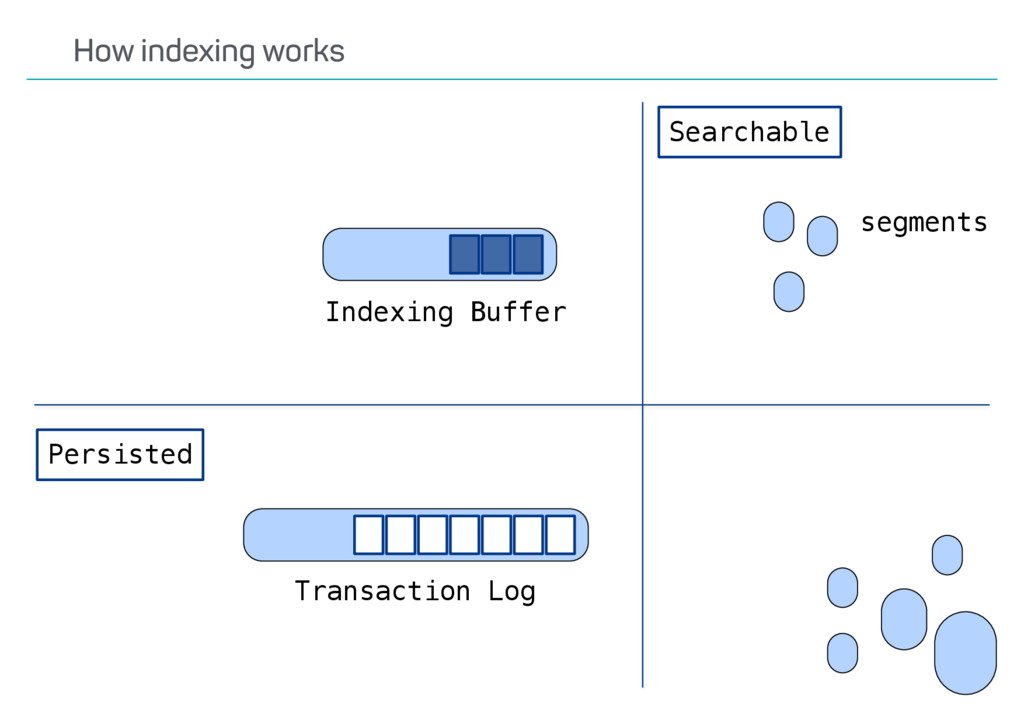
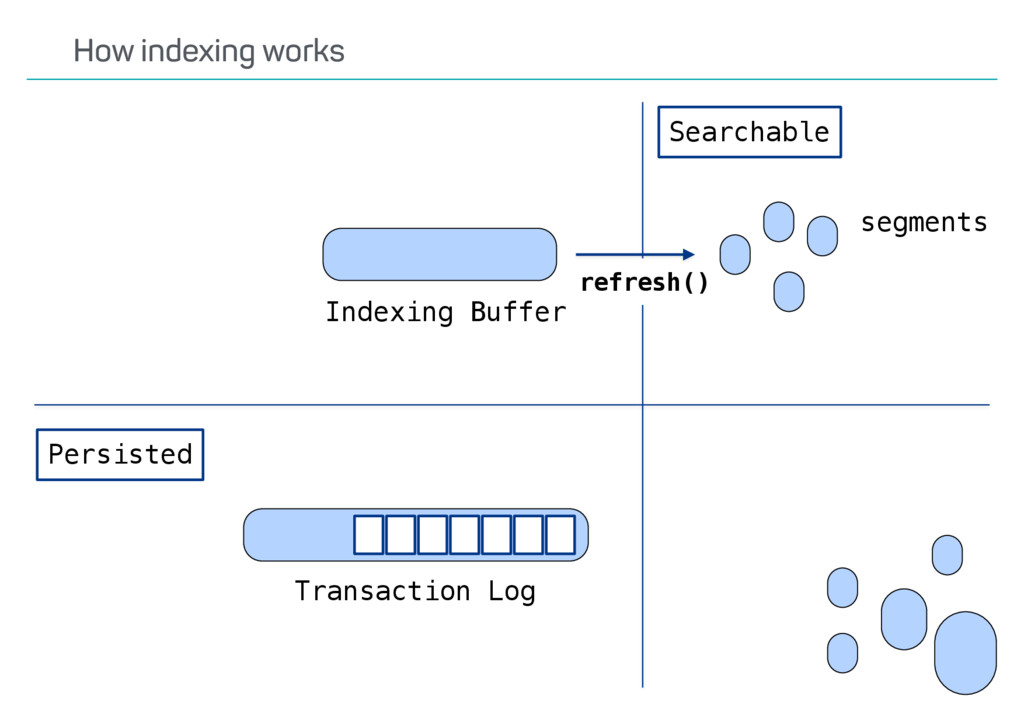
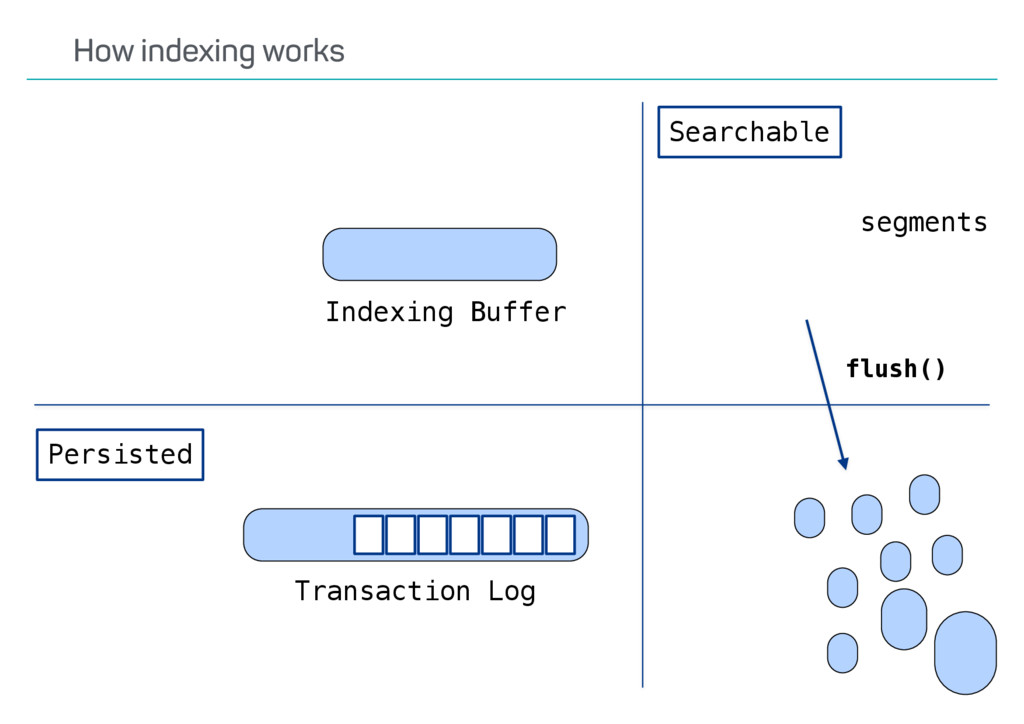
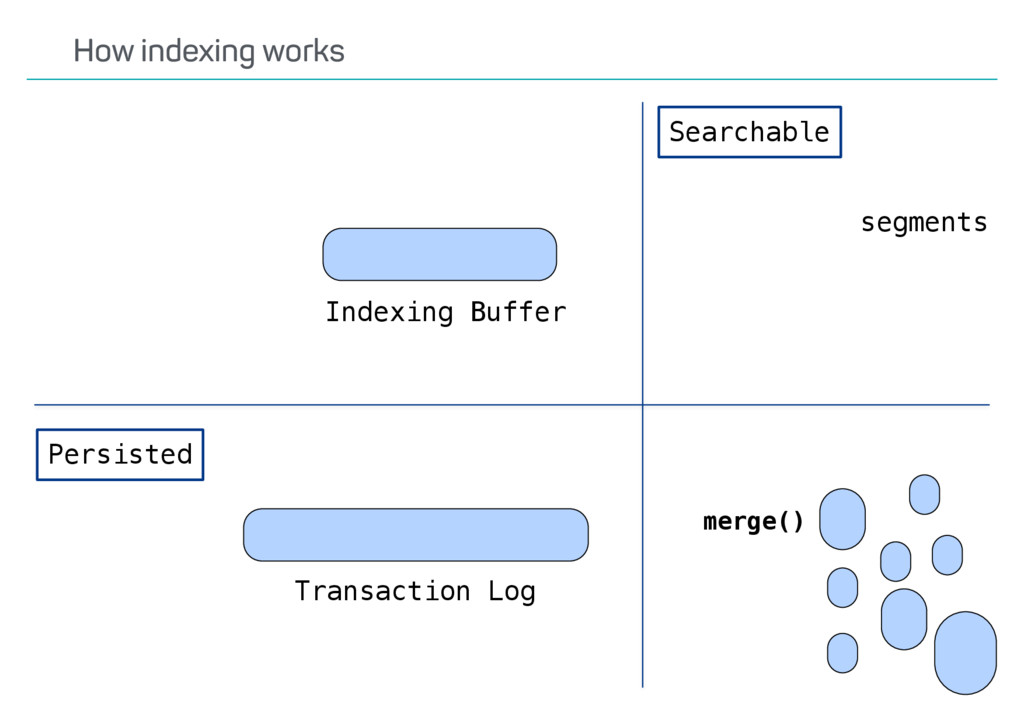
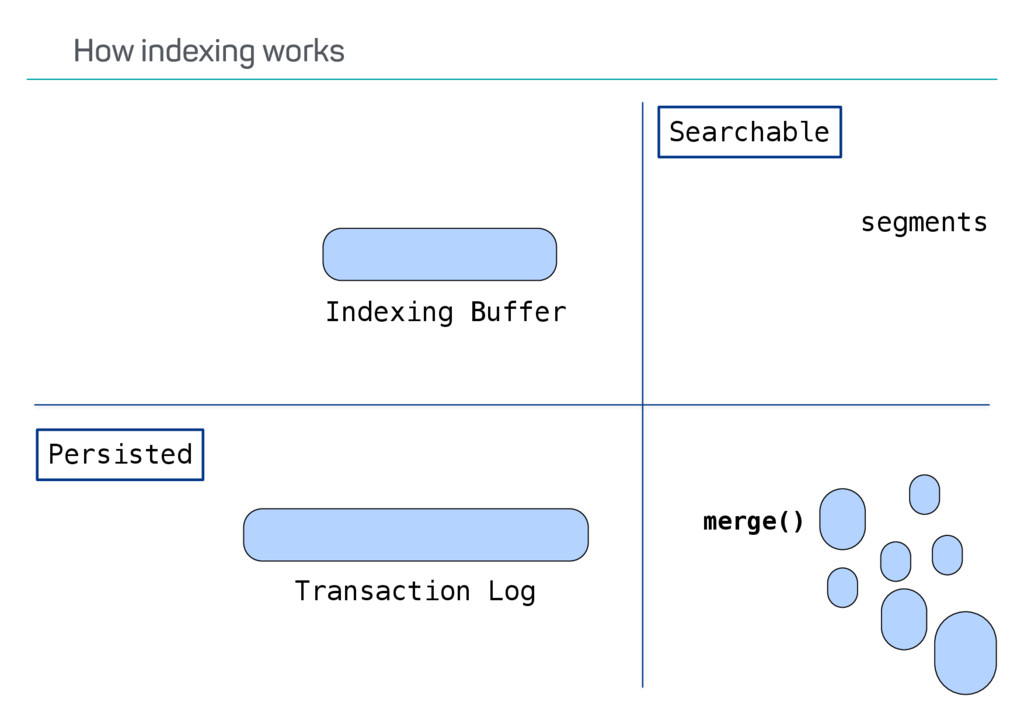
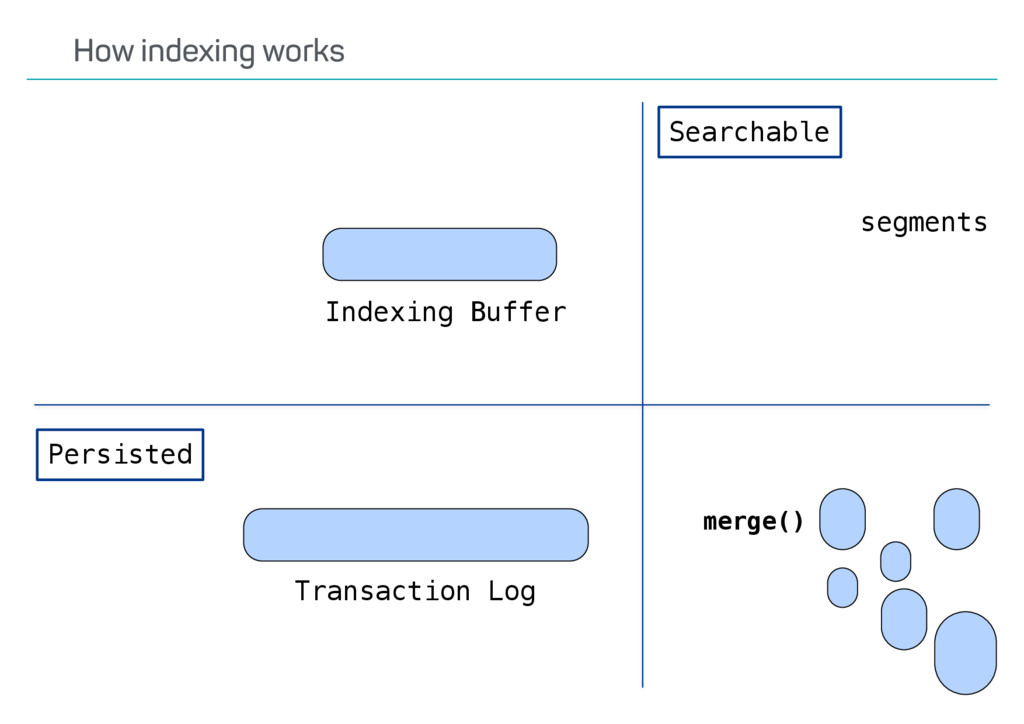
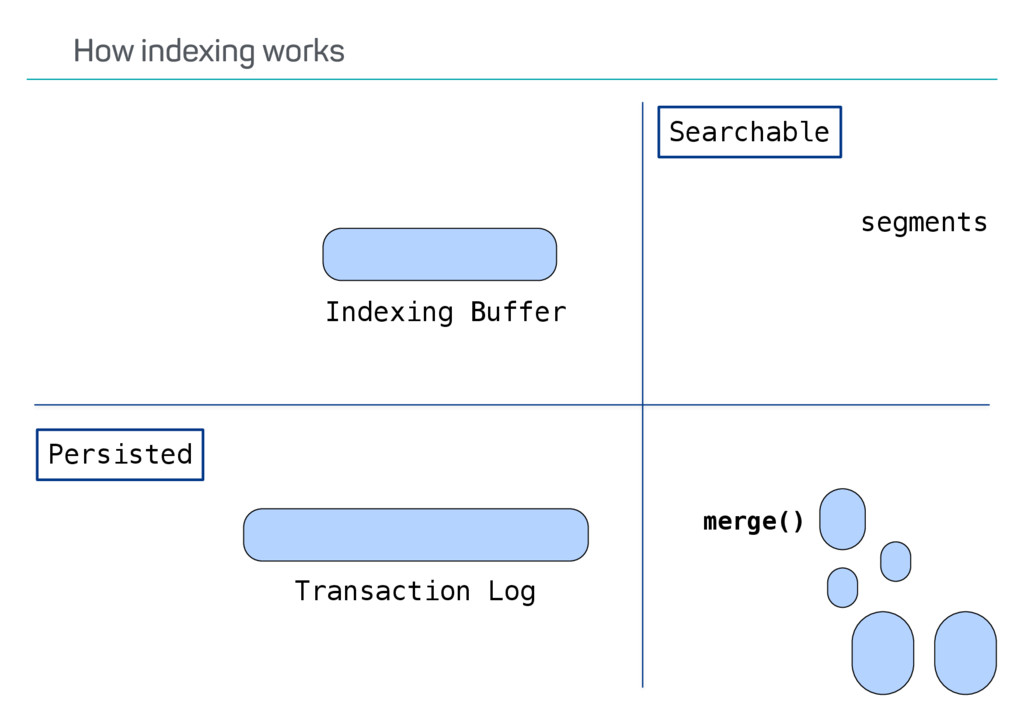
index? Update API usage? Versioning? Possible deletes? •Ways to speed up reindexing •Bulk indexing •Disable refresh •Decrease number of replicas •The Reindex API only covers some scenarios Reindexing
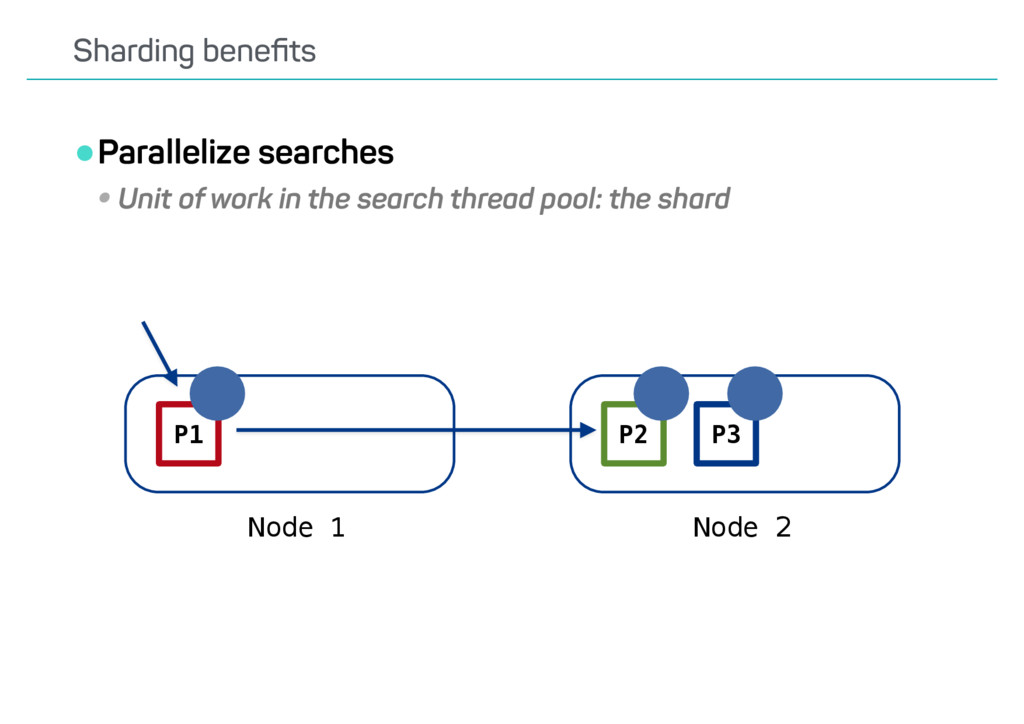
than needed •Don’t return fields not needed •Limit the amount of indexes/shards queried •Only query those where hits are possible •Request aggregations/facets only when needed •Might not have changed when requesting the next results page Reduce search overhead
to dfs_query_then_fetch •But: one more round trip •What is accurate scoring anyway? (e.g., deleted documents) •Need more accurate counts in aggregations? •Set shard_size higher than size •But: more work for each shard Accuracy vs. speed trade-offs with sharding
how much is needed •No more than roughly 30 GB (enables pointer compression) •Number of processors? •Set JVM options (defaults based on OS virtual processors) •Set the Elasticsearch processors configuration property JVM
performance •Disk: Local SSD is best •CPU: 8 cores are nice •Consider separating into hot and cold nodes •Set up allocation constraints Hardware resources
examples on the web •Configuration may differ between Elasticsearch versions •The official channels (GitHub, forum, documentation) are great •Outdated (mostly pre 2.x) topics •Field data without doc_values, filters vs. queries, scan+scroll, split brain, unnecessary recovery, cluster state without diffs There is more
(0) 212.23362854 fax: +49 (0) 212.23362879 [email protected] www.codecentric.de blog.codecentric.de Questions? Dr. Patrick Peschlow Head of Development - CenterDevice
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}