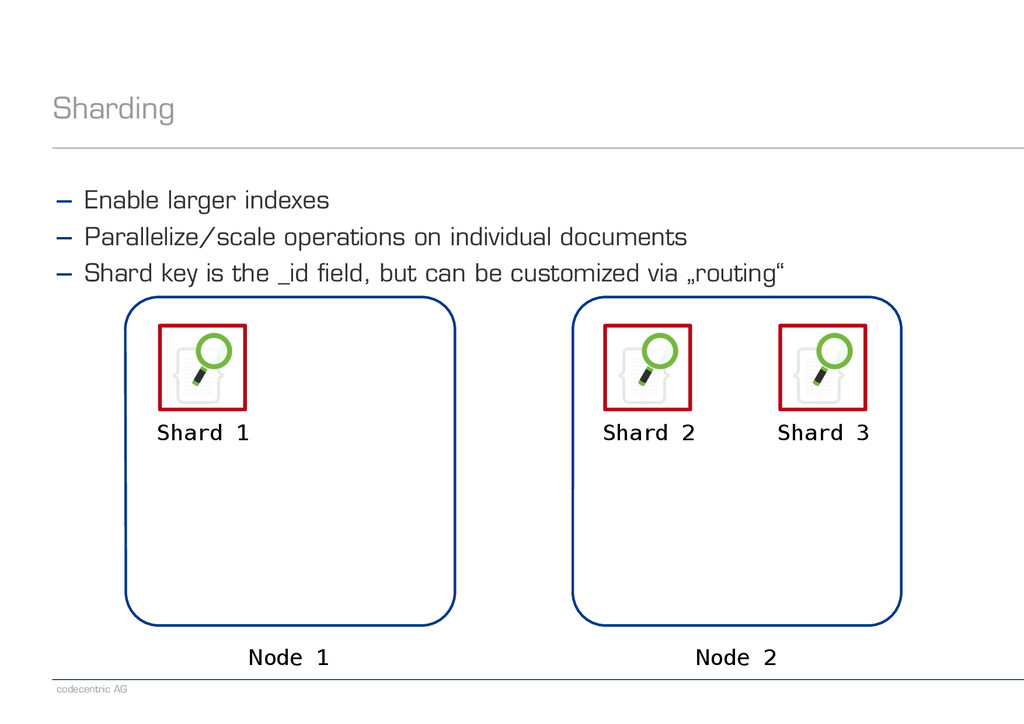
be chosen on index creation − No shard splitting later ! − How to determine the required number of shards for an index? − Measure the capacity limit of a single shard − Extrapolate the required number of shards and overallocate a little − Use realistic data and workloads − Use adequate metrics
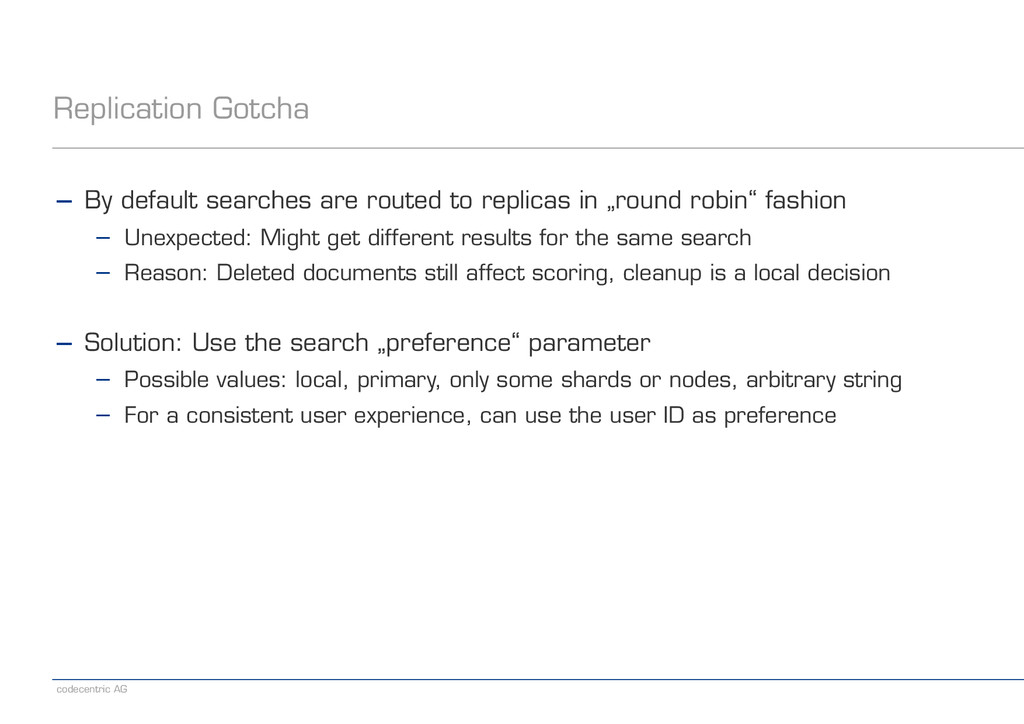
to replicas in „round robin“ fashion − Unexpected: Might get different results for the same search − Reason: Deleted documents still affect scoring, cleanup is a local decision ! − Solution: Use the search „preference“ parameter − Possible values: local, primary, only some shards or nodes, arbitrary string − For a consistent user experience, can use the user ID as preference
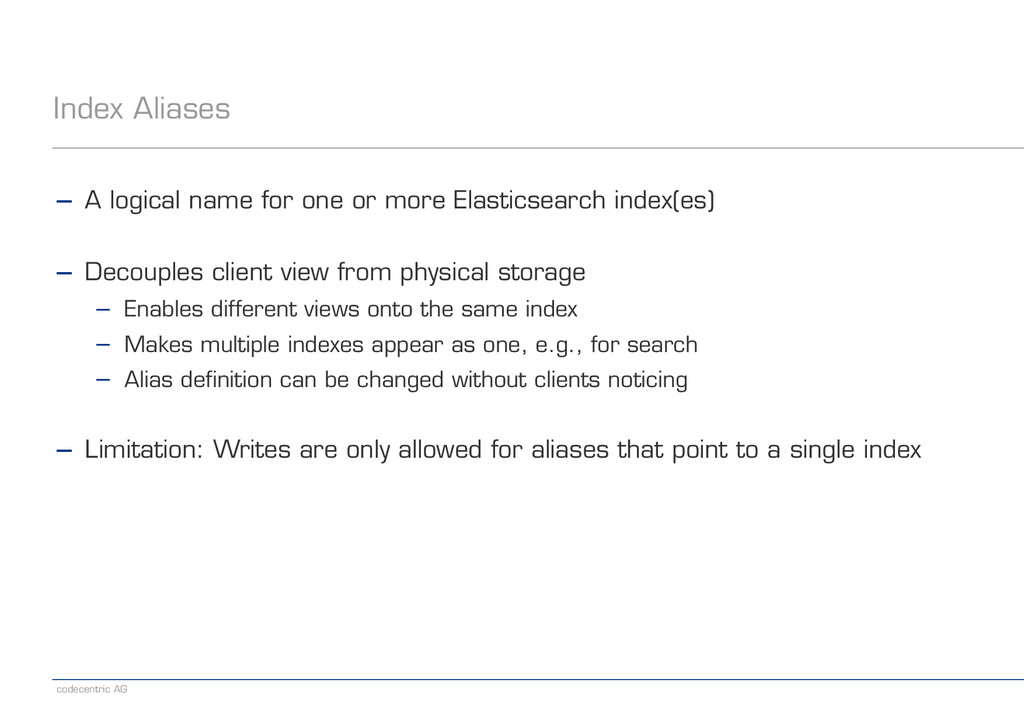
or more Elasticsearch index(es) ! − Decouples client view from physical storage − Enables different views onto the same index − Makes multiple indexes appear as one, e.g., for search − Alias definition can be changed without clients noticing ! − Limitation: Writes are only allowed for aliases that point to a single index
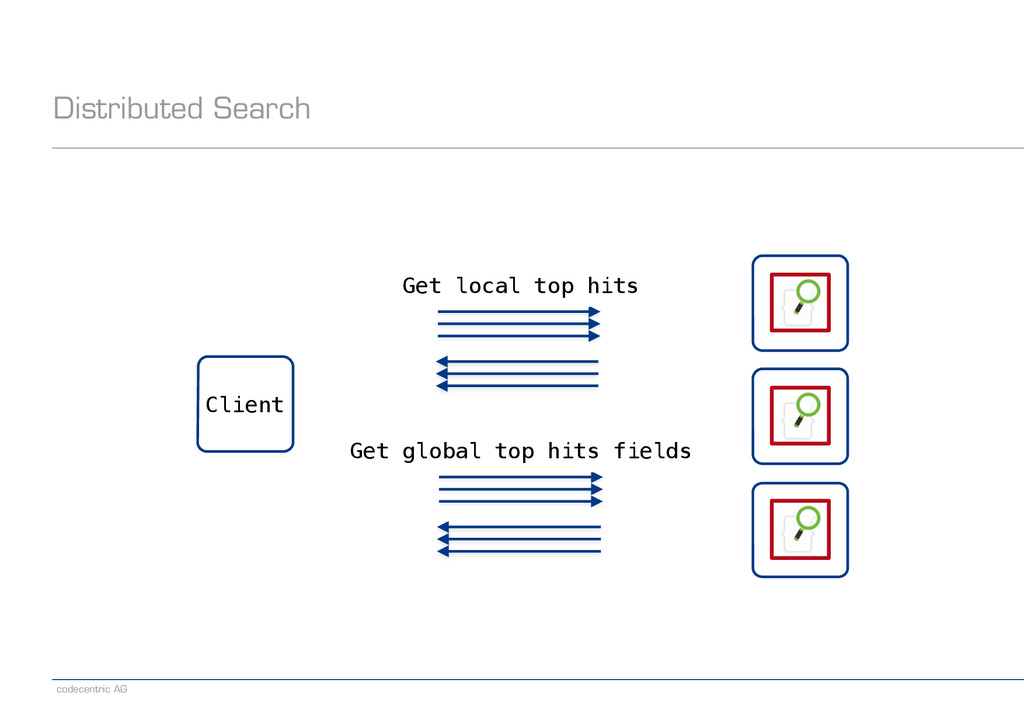
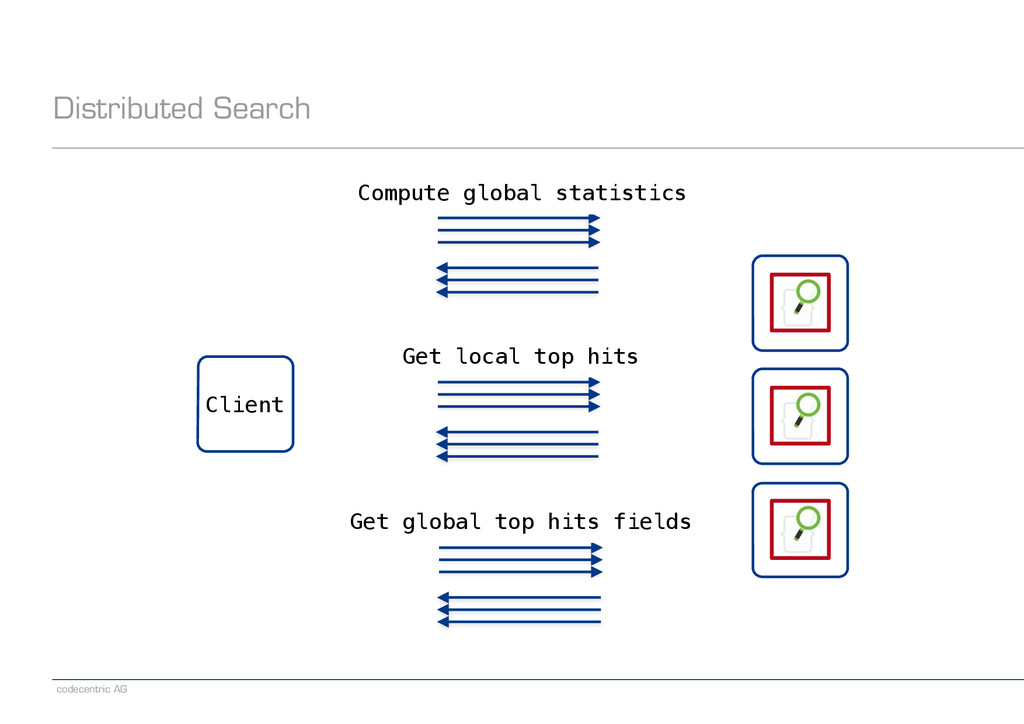
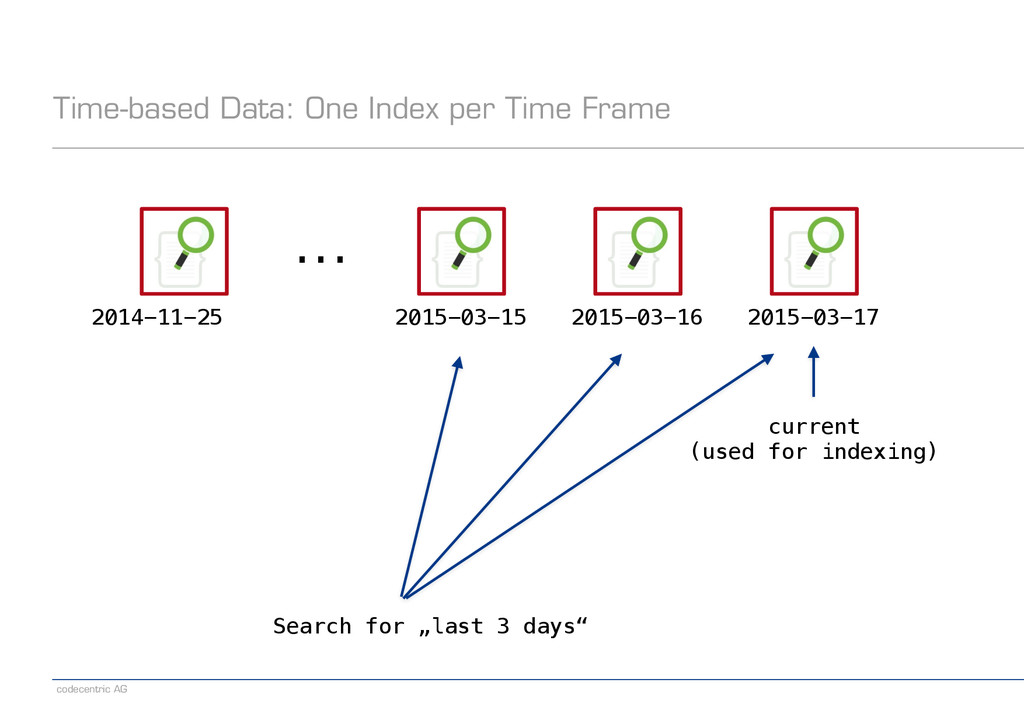
about scaling right from the start? − Fixed number of shards per index − Distributed searches are expensive ! − Patterns in the data can be used for optimization ! − Time-based data − Documents arrive with (close-to-real-time) timestamps − Examples: Log files, tweets ! − User-based data − Documents form disjoint partitions with respect to visibility − Examples: Unrelated users or tenants on the same platform
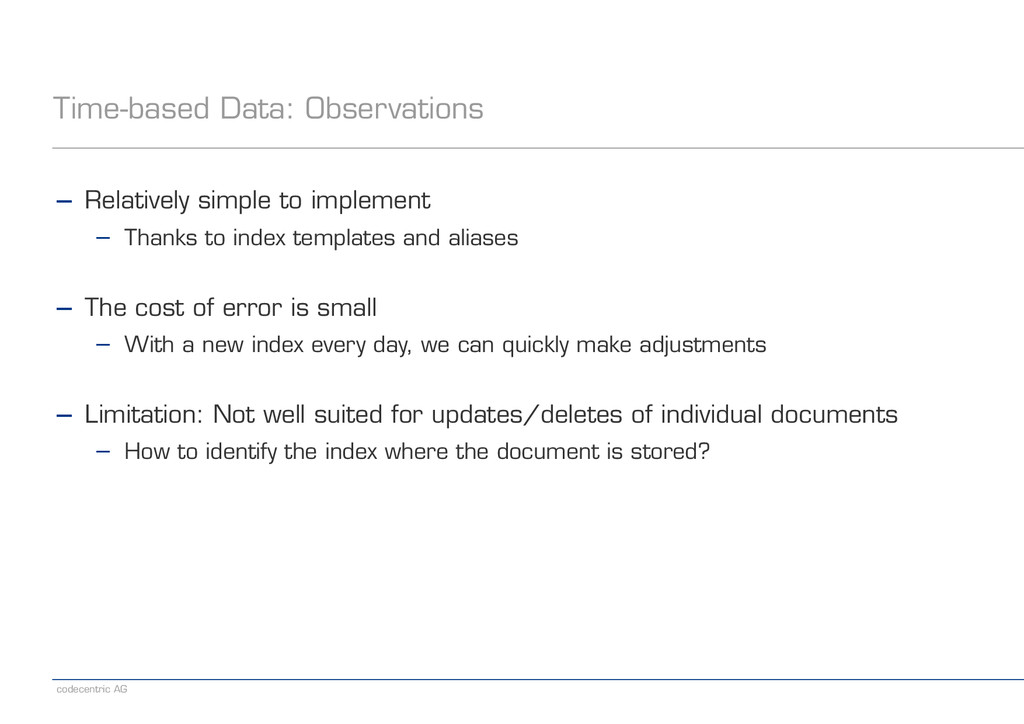
− Thanks to index templates and aliases ! − The cost of error is small − With a new index every day, we can quickly make adjustments ! − Limitation: Not well suited for updates/deletes of individual documents − How to identify the index where the document is stored?
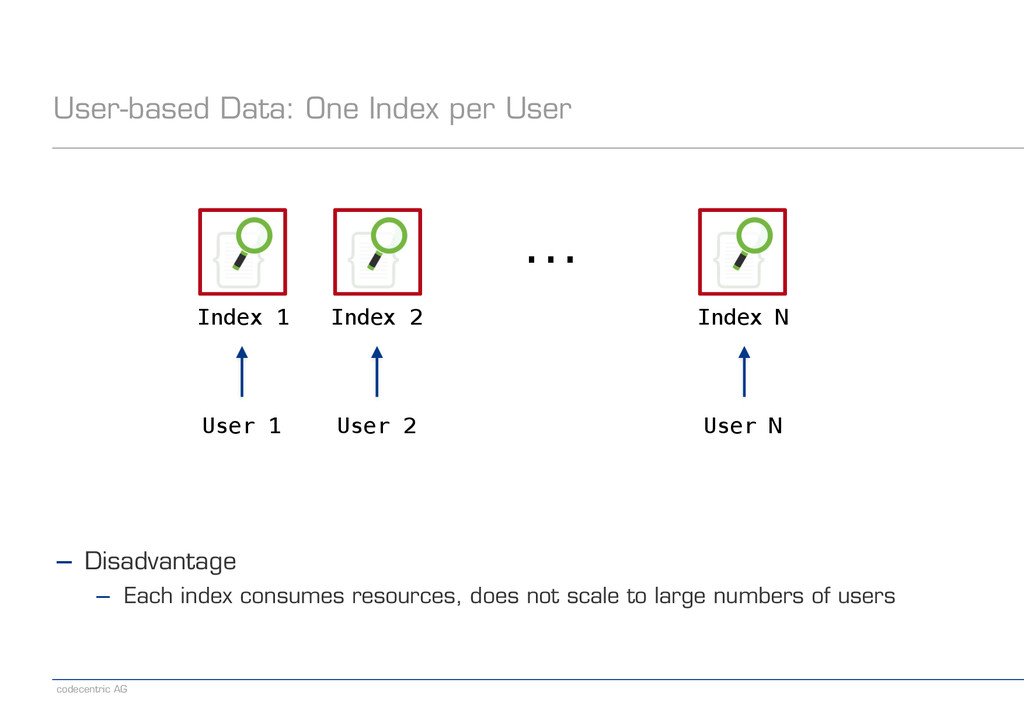
Index 2 Index N ... User 1 User 2 User N ! ! ! ! ! ! ! ! ! ! ! − Disadvantage − Each index consumes resources, does not scale to large numbers of users
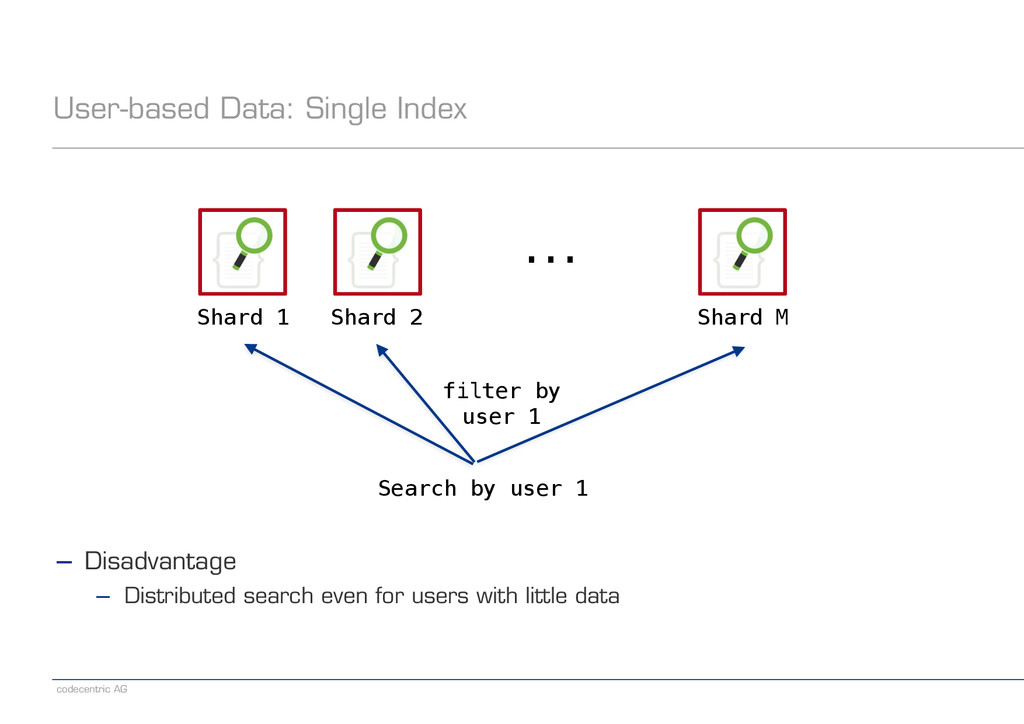
with Routing Shard 1 Shard 2 Shard M ... User 2 User 1 User 5 User 3 User 4 User 6 User N User N-1 Search by user 1 ! ! ! ! ! ! ! ! ! ! ! − Disadvantage − Some shards may become much bigger than others
to know the approach chosen − Aliases can be associated with filter and routing information − We can present separate „user“ indexes (aliases) to the client ! − It is possible to combine the approaches behind scenes − For example, start with „single index with routing“ − If needed, later migrate big users to dedicated indexes ! − Regardless of the approach chosen, we may always hit capacity limits − An index or a shard may become too large − Need to be prepared to extend an index
an index has reached its capacity? ! − Option 1: Extend the index by a second one − Not really nice, requires „manual“ sharding (which index to address?) ! − Option 2: Migrate to a new index with more shards − May require zero downtime migration
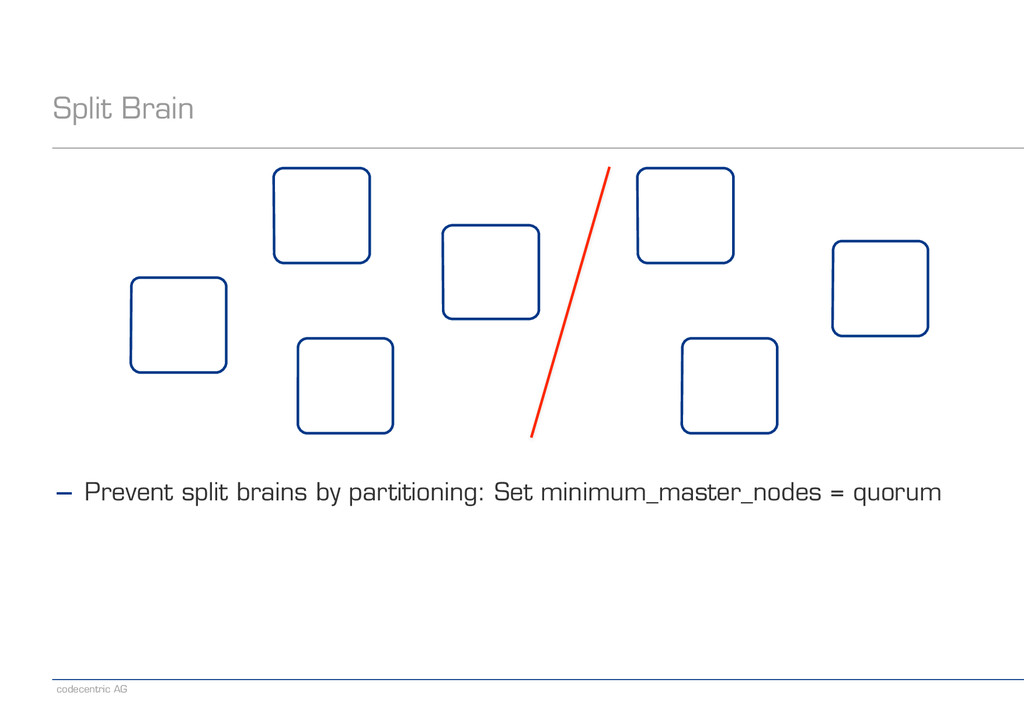
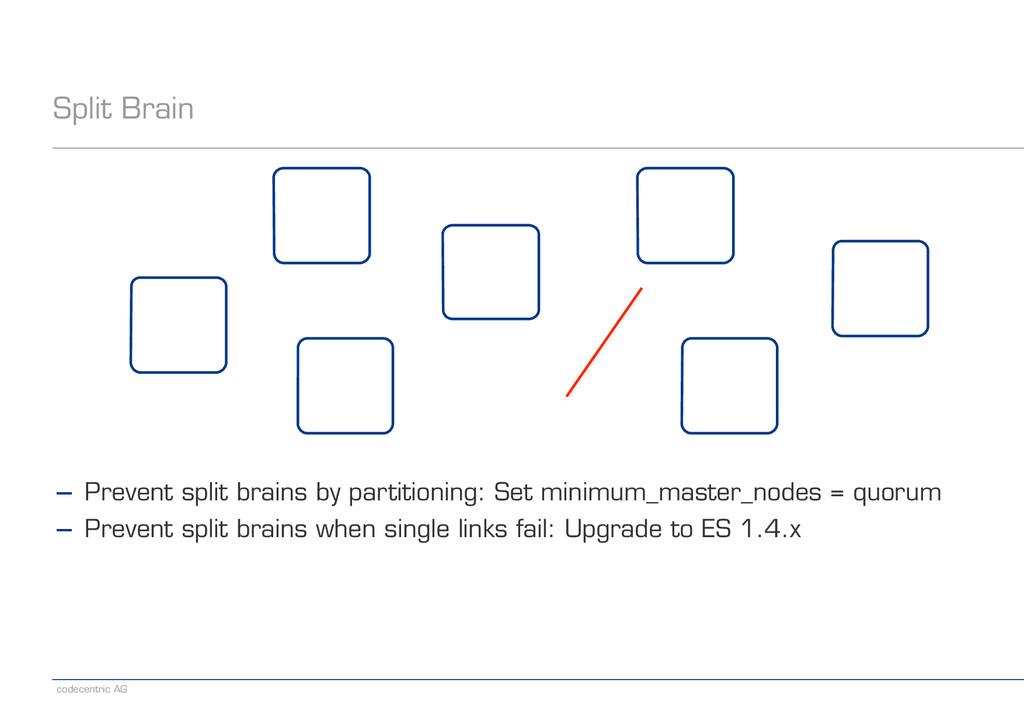
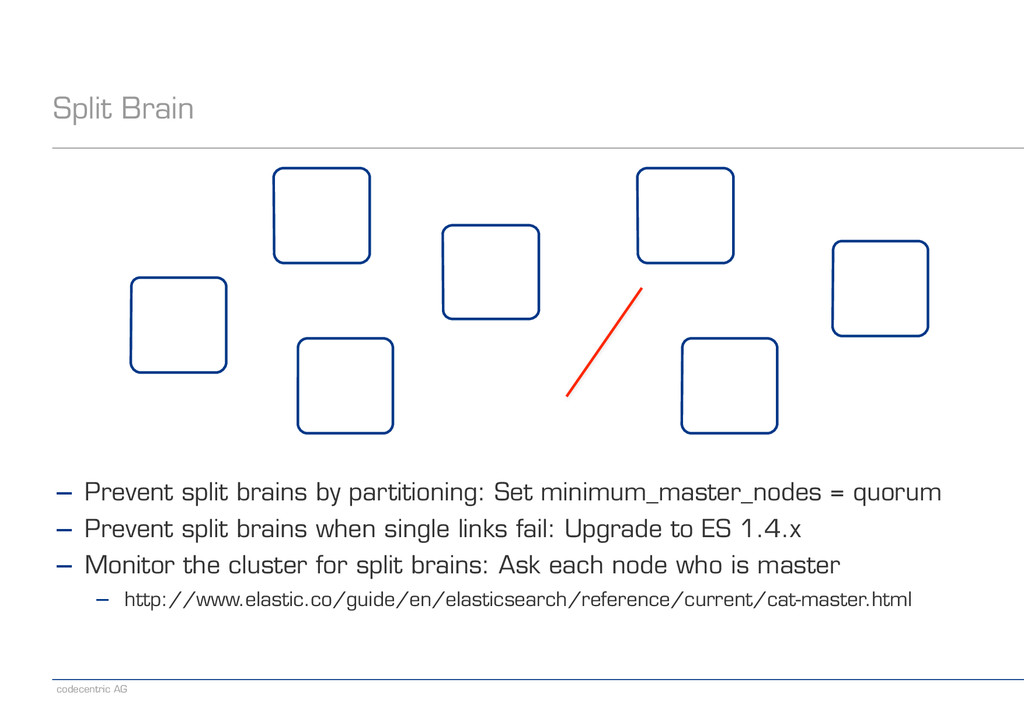
! ! − Prevent split brains by partitioning: Set minimum_master_nodes = quorum − Prevent split brains when single links fail: Upgrade to ES 1.4.x − Monitor the cluster for split brains: Ask each node who is master − http://www.elastic.co/guide/en/elasticsearch/reference/current/cat-master.html
document size instead of count ! − Throttle merging if needed − Note: Elasticsearch might still throttle indexing − Look out for „now throttling indexing“ log messages ! − Decrease refresh rate, if applicable − Or completely disable refresh and refresh manually when done indexing ! − Set number of replicas to zero − Add replicas when done indexing, cheaper than „live“ replication
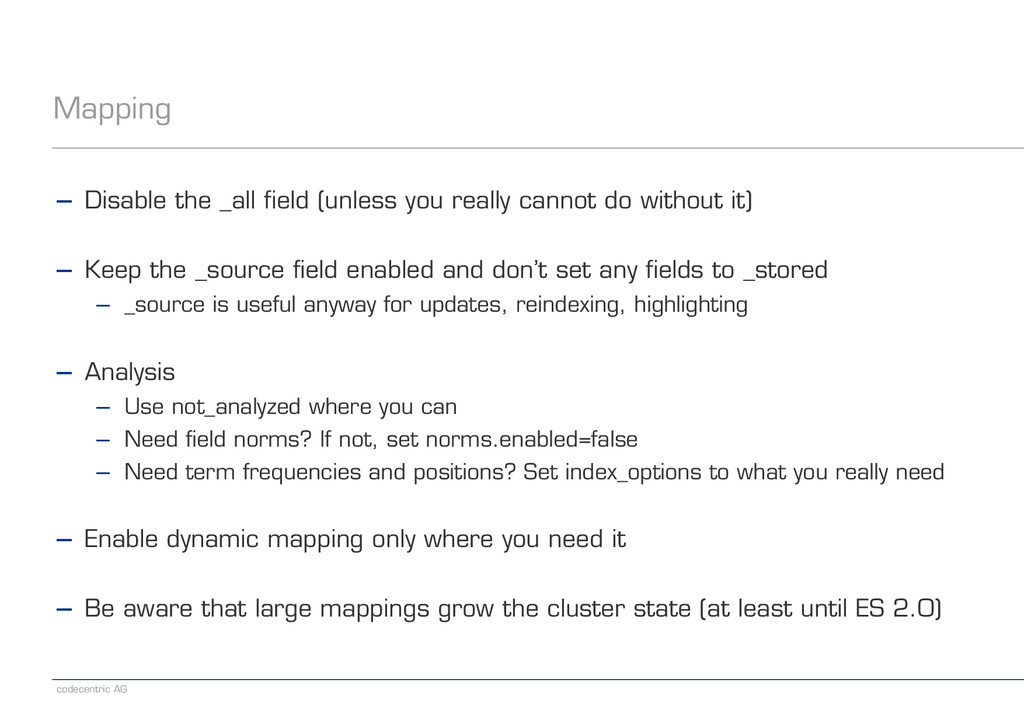
really cannot do without it) ! − Keep the _source field enabled and don’t set any fields to _stored − _source is useful anyway for updates, reindexing, highlighting ! − Analysis − Use not_analyzed where you can − Need field norms? If not, set norms.enabled=false − Need term frequencies and positions? Set index_options to what you really need ! − Enable dynamic mapping only where you need it ! − Be aware that large mappings grow the cluster state (at least until ES 2.0)
queries whenever you don’t need scoring − Filter results can be cached − Note: With ES 2.0 queries and filters may get unified ! − Tricky caching behavior − Some filters are cached by default, others not − Bool filters query the cache for their (sub-)filters, but and/or/not filters don’t ! − Elements of bool filters are executed sequentially − Place highly selective filters first
results with a single query − Avoid deep pagination − Consider using the scan+scroll API when you don’t need sorting ! − Try to replace heavyweight queries by additional index-time operations − For example, prefix query vs. edge ngrams − Might require indexing a source field twice − Consider using the „transform“ feature
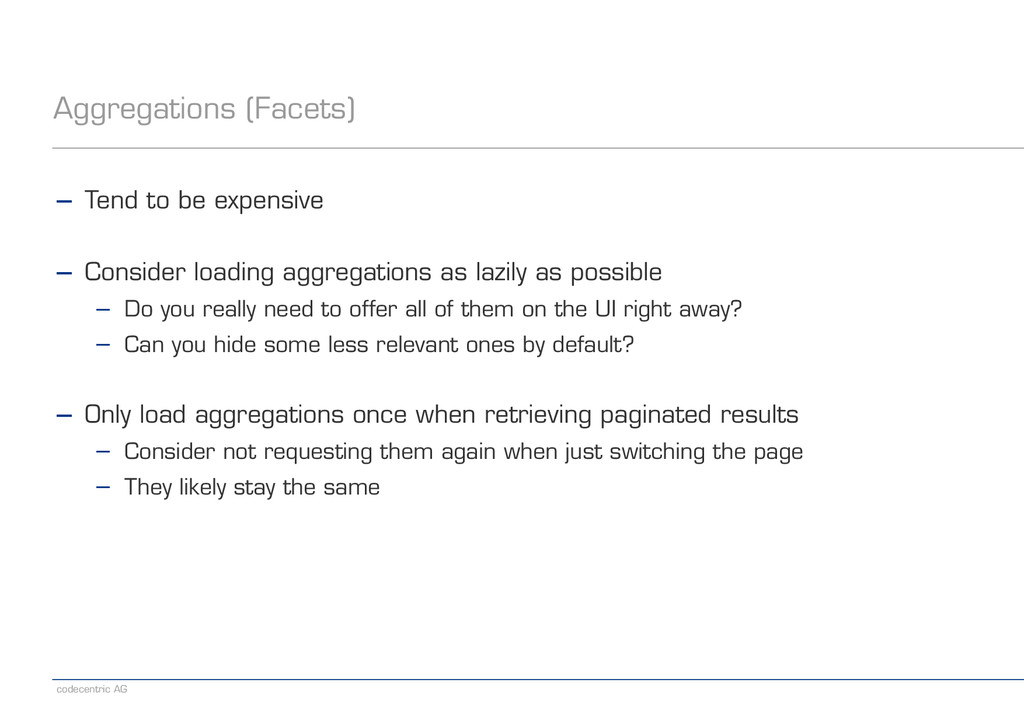
− Consider loading aggregations as lazily as possible − Do you really need to offer all of them on the UI right away? − Can you hide some less relevant ones by default? ! − Only load aggregations once when retrieving paginated results − Consider not requesting them again when just switching the page − They likely stay the same
original document field contents − Sorting, aggregation, and sometimes scripting ! − Field data is usually loaded (and cached) for all documents − Can consume lots of memory − Frequent cause of OutOfMemoryError ! − „Doc values“: Store field data on the file system − Let the OS do the caching − Much lower JVM memory requirements − Much fewer garbage collections − Can be enabled on a per-field basis
Delete + Add − Only saves network traffic − Do not use the update API to replace a whole document (just add it instead) ! − Even small updates might take a while − A single expensive field can prevent efficient update of a document
of inner objects are flattened, one-to-many relationships not possible ! − Nested objects − Stored as separate objects alongside the document − Loading/querying them does not cause much overhead − But cannot be updated on their own ! − Parent/child mapping − Child documents are separate documents on the same shard as their parent − Can be updated individually − Querying is more expensive (internally requires an in-memory join table)
− gateway.recover_after_nodes − gateway.recover_after_time − gateway.expected_nodes ! − Tune thread pool, buffer, cache sizes if needed ! − General advice: know the available options
− Avoid swapping and increase various limits − http://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration.html ! − JVM memory − Allocate at most half of the available memory to the Elasticsearch JVM − No more than 32 GB (pointer compression), and less when using doc values − Use a concurrent garbage collector (default is CMS) ! − JVM version − Stick to the Oracle JVM − Some JVMs may cause index corruption (e.g., Java 7 update 40)
virtualization − Possible conflicts with other services on the same physical node − Can you reliably reserve/isolate memory? ! − Storage − Use SSDs (if too expensive, maybe only for „hot“ data?) − Keep Elasticsearch data directories on local storage (beware NFS, etc.) ! − Memory − The more, the better ! − Prefer medium/large size machines over small ones
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}