really need it) ! − Prefer _source over _stored − _source is useful anyway (for updates, reindexing, highlighting) ! − Only analyze/compute what you need − not_analyzed, field norms, term frequencies and positions ! − Be careful with dynamic mapping and dynamic templates − Can lead to undesired fields or types in the index − Can considerably grow the cluster state
results with a single query − Avoid deep pagination − Consider using the scan+scroll API when you don’t need sorting ! − Think about index-time vs. query-time solutions − Prefix query vs. edge ngrams ? − Sorting via script vs. indexing another field ? − Don’t be afraid to index a source field twice
criteria that don’t need scoring − In contrast to queries, filter results can be cached ! − Tricky caching behavior − Some filters are cached by default, others not (depends on cost) − Caching may also depend on how often filters are used − Pay special attention to compound filters ! − Possible to override caching behavior and cache key
are executed sequentially − Place more selective filters first ! − Consider using „accelerator“ filters − Redundant filters that reduce work for heavyweight filters ! − Learn about possible „strategy“ settings for filtered queries − Controls how filter and query parts are interleaved − Measure, don’t guess ! − Note: With ES 2.0 queries and filters might get unified
computation) ! − Use the validate/explain feature (query rewriting, cache usage) ! − Make sure your analyzers work correctly − Use the analyze API − Check out the „inquisitor“ and „extended-analyze“ plugins ! − When in doubt, take a look at the terms in your index − http://rosssimpson.com/blog/2014/05/06/using-luke-with-elasticsearch/ − „skywalker“ plugin
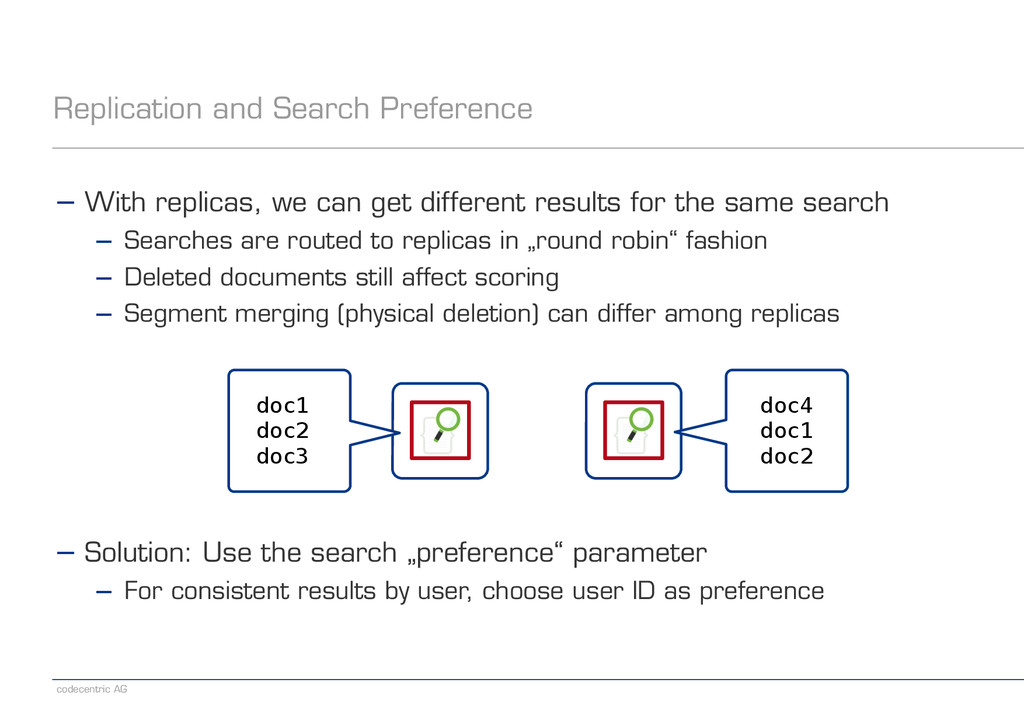
can get different results for the same search − Searches are routed to replicas in „round robin“ fashion − Deleted documents still affect scoring − Segment merging (physical deletion) can differ among replicas ! ! ! ! ! − Solution: Use the search „preference“ parameter − For consistent results by user, choose user ID as preference doc1 doc2 doc3 doc4 doc1 doc2
possible − Do you really need to offer all of them on the UI right away? − Can you hide some less relevant ones by default? ! − Only load aggregations once when retrieving paginated results − Consider not requesting them again when just switching the page − They likely stay the same ! − Many aggregations use approximation algorithms − Don’t expect results to be 100% true
data − Sorting, aggregation, parent-child queries, some scripts ! − Field data is usually loaded for all documents − Leads to high memory consumption or OutOfMemoryError ! − Use „doc values“: Store field data on the file system − Let the OS do the caching − Can be enabled on a per-field basis ! − Note: With ES 2.0 „doc values“ might become the default
suite − Test expectations about matches − Prevent regressions when changing or modifying analyzers ! − The Elasticsearch Java client is embeddable − No mocks or test doubles needed ! − Try it by solving the „mapping challenge“ ! − https://github.com/peschlowp/elasticsearch-mapping-challenge
1 second − Targeted at human users ! − What if API clients want RYOW semantics for search ? − Refresh after every request ? ! − Recommendation: Leave RYOW to the primary database, if at all − Provide a separate API if needed
document size not count ! − Be careful with merge throttling − Elasticsearch might throttle indexing anyway − Look out for „now throttling indexing“ log messages − Is it worth it? ! − Decrease refresh rate (or disable completely) ! − Reduce number of replicas (or set to zero) − Add missing replicas later, much cheaper than „live“ replication
− Only saves network traffic ! − Even small updates might take a while − Consider splitting (nested documents or parent-child relationships) ! − „Partial document“ update trickiness − Fields are replaced, except for inner objects which are merged − To replace inner objects, consider wrapping them in an array
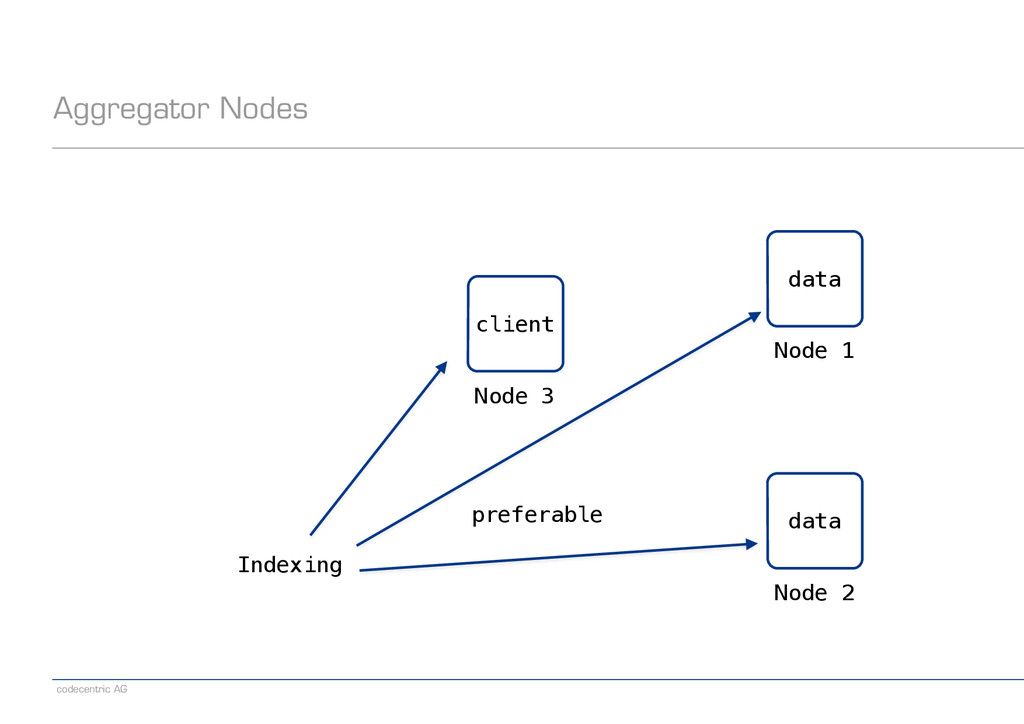
as a client node − Potentially saves a network hop − Will participate in distributed searches ! − TransportClient − More lightweight than NodeClient ! − Some HTTP Client − Smaller memory footprint − Pay attention to settings: Chunking, long-lived HTTP connections
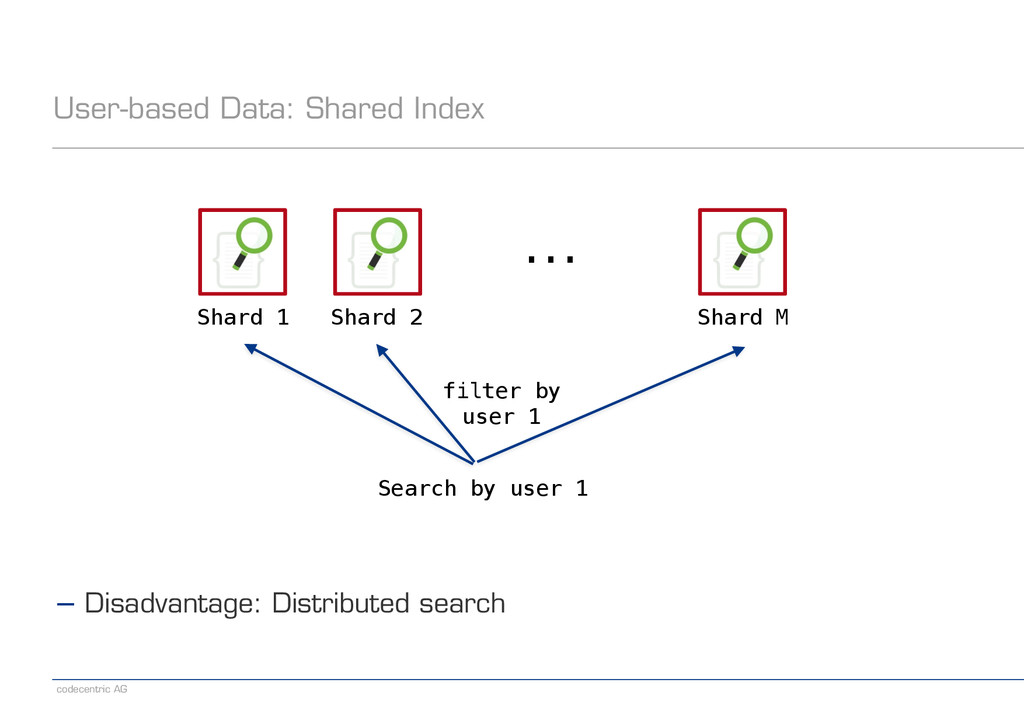
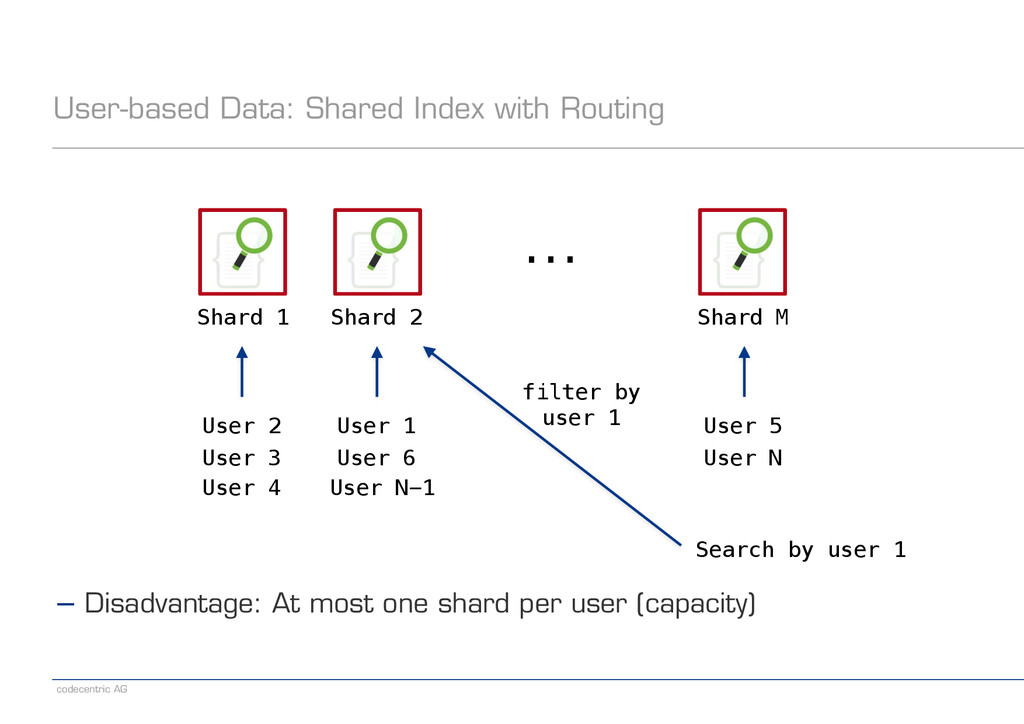
from the start − Fixed number of shards per index − Shard key cannot be changed later − Distributed searches are expensive ! − Patterns in the data can be used for optimization − Time-based data − User-based data
with Routing Shard 1 Shard 2 Shard M ... User 2 User 1 User 5 User 3 User 4 User 6 User N User N-1 Search by user 1 ! ! ! ! ! ! ! ! ! ! − Disadvantage: At most one shard per user (capacity)
chosen can be hidden from clients − Aliases can even carry filter and routing information − Present separate „user“ indexes (aliases) to the client ! − Advantage − Flexibility: Adapt mapping to physical indexes/shards on demand ! − Limitation − Huge number of users means lots of aliases (cluster state) − Still much better than huge number of indexes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}